Verwenden von Onlinetabellen für die Echtzeit-Featurebereitstellung
Wichtig
Onlinetabellen befinden sich in der öffentlichen Vorschau in den folgenden Regionen: westus, , eastus, eastus2, . northeuropewesteurope Preisinformationen finden Sie unter Onlinetabellen-Preise.
Eine Onlinetabelle ist eine schreibgeschützte Kopie einer Delta-Tabelle, die im zeilenorientierten Format gespeichert ist, das für den Onlinezugriff optimiert ist. Onlinetabellen sind vollständig serverlose Tabellen, welche die Durchsatzkapazität automatisch mit der Anforderungslast skalieren und geringe Wartezeit und hohen Durchsatz beim Zugriff auf Daten mit beliebiger Skalierung bieten. Onlinetabellen wurden für Mosaic AI Model Serving, Feature Serving und Retrieval-Augmented Generation (RAG)-Anwendungen entwickelt, in denen sie für schnelle Daten-Lookups verwendet werden.
Sie können Onlinetabellen auch in Abfragen mit Lakehouse Federation verwenden. Wenn Sie Lakehouse Federation verwenden, müssen Sie ein Serverless SQL Warehouse verwenden, um auf Onlinetabellen zuzugreifen. Nur Lesevorgänge (SELECT) werden unterstützt. Diese Funktion ist nur für interaktive oder Debuggingzwecke vorgesehen und sollte nicht für produktions- oder unternehmenskritische Workloads verwendet werden.
Das Erstellen einer Onlinetabelle mithilfe der Databricks-Benutzeroberfläche ist ein Einschrittprozess. Wählen Sie einfach die Delta-Tabelle im Katalog-Explorer aus und dann Onlinetabelle erstellen. Sie können auch die REST-API oder das Databricks-SDK verwenden, um Onlinetabellen zu erstellen und zu verwalten. Siehe Arbeiten mit Onlinetabellen mithilfe von APIs.
Anforderungen
- Der Arbeitsbereich muss für Unity Catalog aktiviert sein. Befolgen Sie die Dokumentation zum Erstellen und Aktivieren eines Unity Catalog-Metastores in einem Arbeitsbereich sowie zum Erstellen eines Katalogs.
- Ein Modell muss im Unity-Katalog registriert sein, um auf Onlinetabellen zugreifen zu können.
Arbeiten mit Onlinetabellen mithilfe der Benutzeroberfläche
In diesem Abschnitt wird beschrieben, wie Sie Onlinetabellen erstellen und löschen, wie Sie den Status überprüfen und Aktualisierungen von Onlinetabellen auslösen.
Erstellen einer Onlinetabelle mithilfe der Benutzeroberfläche
Sie erstellen mit dem Katalog-Explorer eine Onlinetabelle. Weitere Informationen zu den erforderlichen Berechtigungen finden Sie unter Benutzerberechtigungen.
Zum Erstellen einer Onlinetabelle muss die Delta-Quelltabelle über einen Primärschlüssel verfügen. Wenn die Delta-Tabelle, die Sie verwenden möchten, keinen Primärschlüssel aufweist, erstellen Sie einen anhand der folgenden Anleitung: Verwenden einer vorhandenen Delta-Tabelle als Featuretabelle in Unity Catalog.
Navigieren Sie im Katalog-Explorer zu der Quelltabelle, die Sie mit einer Onlinetabelle synchronisieren möchten. Wählen Sie im Menü Create (Erstellen) die Option Online table (Onlinetabelle) aus.
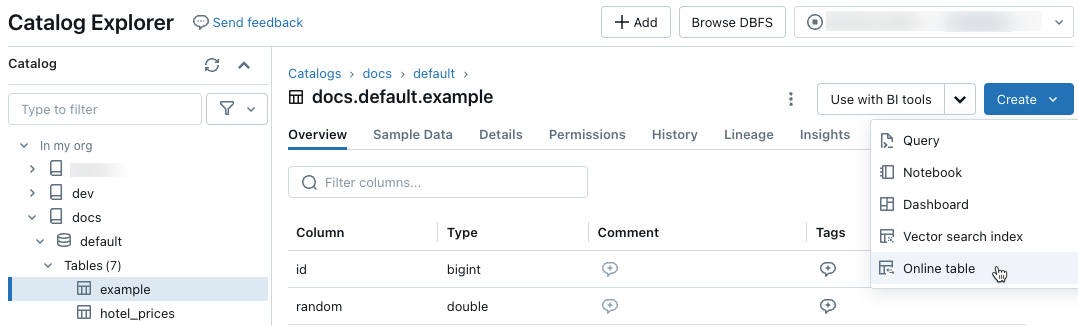
Verwenden Sie die Selektoren im Dialogfeld, um die Onlinetabelle zu konfigurieren.
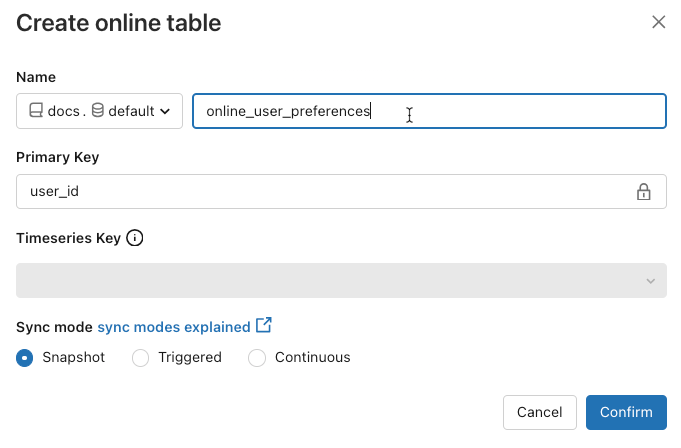
Name: Name, der für die Onlinetabelle in Unity Catalog verwendet werden soll
Primärschlüssel: Spalten in der Quelltabelle, die in der Onlinetabelle als Primärschlüssel verwendet werden sollen
Zeitreihenschlüssel: (Optional). Spalte in der Quelltabelle, die als Zeitreihenschlüssel verwendet werden soll. Wenn ein Wert angegeben wird, enthält die Onlinetabelle nur die Zeile mit dem neuesten Wert des Zeitreihenschlüssels für jeden Primärschlüssel.
Synchronisierungsmodus: Gibt an, wie die Synchronisierungspipeline die Onlinetabelle aktualisiert. Wählen Sie Momentaufnahme, Ausgelöst oder Fortlaufend aus.
Policy Beschreibung Snapshot Die Pipeline wird einmal ausgeführt, um eine Momentaufnahme der Quelltabelle zu erstellen und in die Onlinetabelle zu kopieren. Nachfolgende Änderungen an der Quelltabelle werden automatisch in der Onlinetabelle übernommen, indem eine neue Momentaufnahme der Quelle und eine neue Kopie erstellt werden. Der Inhalt der Onlinetabelle wird atomisch aktualisiert. Ausgelöst Die Pipeline wird einmal ausgeführt, um eine Anfangsmomentaufnahmekopie der Quelltabelle in der Onlinetabelle zu erstellen. Im Gegensatz zum Modus für die Momentaufnahmesynchronisierung werden beim Aktualisieren der Onlinetabelle nur Änderungen seit der letzten Pipelineausführung abgerufen und auf die Onlinetabelle angewendet. Die inkrementelle Aktualisierung kann manuell oder automatisch entsprechend einem Zeitplan ausgelöst werden. Fortlaufend Die Pipeline wird fortlaufend ausgeführt. Nachfolgende Änderungen an der Quelltabelle werden inkrementell auf die Onlinetabelle im Echtzeitstreamingmodus angewendet. Es ist keine manuelle Aktualisierung erforderlich.
Hinweis
Um den Synchronisierungsmodus Ausgelöst oder Fortlaufend zu unterstützen, muss für die Quelltabelle Datenfeed ändern aktiviert sein.
- Wenn Sie fertig sind, klicken Sie auf Bestätigen. Die Onlinetabellenseite wird angezeigt.
- Die neue Onlinetabelle wird unter dem Katalog, dem Schema und dem Namen erstellt, die im Dialogfeld für die Erstellung angegeben sind. Im Katalog-Explorer ist die Onlinetabelle durch
 angegeben.
angegeben.
Abrufen von Status und Auslösen von Updates mithilfe der Benutzeroberfläche
Um den Status der Onlinetabelle zu überprüfen, klicken Sie auf den Namen der Tabelle im Katalog, um sie zu öffnen. Die Onlinetabellenseite wird mit geöffneter Registerkarte Übersicht angezeigt. Im Abschnitt Datenerfassung wird der Status der neuesten Aktualisierung angezeigt. Klicken Sie zum Auslösen einer Aktualisierung auf Jetzt synchronisieren. Der Abschnitt Datenerfassung enthält zudem einen Link zur Delta Live Tables-Pipeline, die die Tabelle aktualisiert.
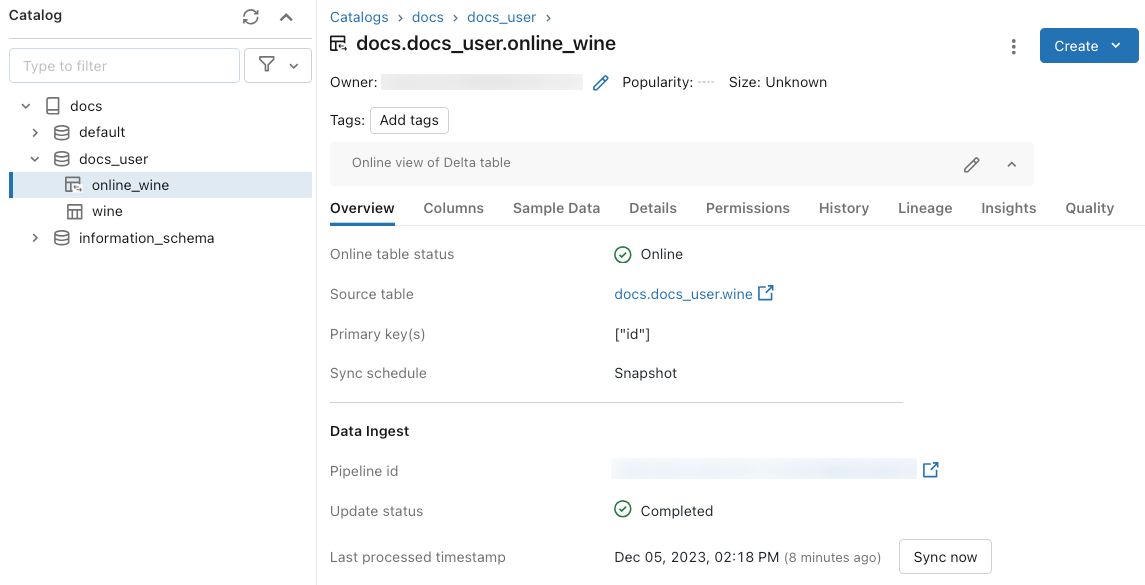
Planen regelmäßiger Updates
Bei Onlinetabellen mit Snapshot - oder Trigger-Synchronisierungsmodus können Sie automatische regelmäßige Updates planen. Der Aktualisierungszeitplan wird von der Delta Live Tables-Pipeline verwaltet, die die Tabelle aktualisiert.
- Navigieren Sie im Katalog-Explorer zur Onlinetabelle.
- Klicken Sie im Abschnitt "Datenaufnahme " auf den Link zur Pipeline.
- Klicken Sie in der oberen rechten Ecke auf "Zeitplan", und fügen Sie einen neuen Zeitplan hinzu, oder aktualisieren Sie vorhandene Zeitpläne.
Löschen einer Onlinetabelle mithilfe der Benutzeroberfläche
Wählen Sie auf der Onlinetabellenseite im Kebabmenü die Option ![]() Löschen aus.
Löschen aus.
Arbeiten mit Onlinetabellen mithilfe von APIs
Sie können auch das Databricks-SDK oder die REST-API verwenden, um Onlinetabellen zu erstellen und zu verwalten.
Referenzinformationen finden Sie in der Referenzdokumentation für das Databricks-SDK für Python oder die REST-API.
Anforderungen
Databricks-SDK Version 0.20 oder höher.
Erstellen einer Onlinetabelle mithilfe von APIs
Databricks SDK – Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
REST-API
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
Die Onlinetabelle beginnt nach der Erstellung automatisch mit der Synchronisierung.
Abrufen des Status und Auslösen von Aktualisierungen mithilfe von APIs
Sie können den Status und die Spezifikation der Onlinetabelle nach dem folgenden Beispiel anzeigen. Wenn Ihre Onlinetabelle nicht fortlaufend ist und Sie eine manuelle Aktualisierung der Daten auslösen möchten, können Sie dazu die Pipeline-API verwenden.
Verwenden Sie die Pipeline-ID, die der Onlinetabelle in der Onlinetabellenspezifikation zugeordnet ist, und starten Sie ein neues Update für die Pipeline, um die Aktualisierung auszulösen. Dies entspricht dem Klicken auf Jetzt synchronisieren in der Benutzeroberfläche der Onlinetabelle im Katalog-Explorer.
Databricks SDK – Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
REST-API
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
Löschen einer Onlinetabelle mithilfe von APIs
Databricks SDK – Python
w.online_tables.delete('main.default.my_online_table')
REST-API
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
Durch das Löschen der Onlinetabelle werden alle laufenden Datensynchronisierungen beendet und alle zugehörigen Ressourcen freigegeben.
Bereitstellen von Onlinetabellendaten mithilfe eines Featurebereitstellungsendpunkts
Für Modelle und Anwendungen, die außerhalb von Databricks gehostet werden, können Sie einen Featurebereitstellungsendpunkt erstellen, um Features aus Onlinetabellen bereitzustellen. Der Endpunkt stellt Features mit geringer Wartezeit mithilfe einer REST-API zur Verfügung.
Erstellen Sie eine Featurespezifikation.
Wenn Sie eine Featurespezifikation erstellen, geben Sie die Delta-Quelltabelle an. Dadurch kann die Featurespezifikation sowohl in Offline- als auch in Onlineszenarien verwendet werden. Bei der Onlinesuche verwendet der Bereitstellungsendpunkt automatisch die Onlinetabelle, um latenzarme Featuresuchvorgänge durchzuführen.
Die Delta-Quelltabelle und die Onlinetabelle müssen denselben Primärschlüssel verwenden.
Die Featurespezifikation kann im Katalog-Explorer auf der Registerkarte Funktion angezeigt werden.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )Erstellen Sie einen Featurebereitstellungsendpunkt.
In diesem Schritt wird davon ausgegangen, dass Sie eine Onlinetabelle mit dem Namen
user_preferences_online_tableerstellt haben, die Daten aus der Delta-Tabelleuser_preferencessynchronisiert. Verwenden Sie die Featurespezifikation, um einen Featurebereitstellungsendpunkt zu erstellen. Der Endpunkt stellt Daten über eine REST-API mithilfe der zugeordneten Onlinetabelle zur Verfügung.Hinweis
Benutzer*innen, die diesen Vorgang ausführen, müssen Besitzer*innen der Offlinetabelle und der Onlinetabelle sein.
Databricks SDK – Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )Python-API
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )Rufen Sie Daten vom Endpunkt für die Featurebereitstellung ab.
Um auf den API-Endpunkt zuzugreifen, senden Sie eine HTTP-GET Anforderung an die Endpunkt-URL. Das Beispiel veranschaulicht dies mithilfe von Python-APIs. Für andere Sprachen und Tools, siehe Feature Serving.
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
Verwenden von Onlinetabellen mit RAG-Anwendungen
RAG-Anwendungen sind ein gängiger Anwendungsfall für Onlinetabellen. Sie erstellen eine Onlinetabelle für die strukturierten Daten, die die RAG-Anwendung benötigt, und hosten sie auf einem Featurebereitstellundsendpunkt. Die RAG-Anwendung verwendet den Featurebereitstellungendpunkt, um relevante Daten aus der Onlinetabelle nachzuschlagen.
Folgende typische Schritte werden ausgeführt:
- Erstellen Sie einen Featurebereitstellungsendpunkt.
- Erstellen Sie ein Tool mithilfe von LangChain oder einem ähnlichen Paket, das den Endpunkt zum Nachschlagen relevanter Daten verwendet.
- Verwenden Sie das Tool in einem LangChain-Agent oder einem ähnlichen Agent, um relevante Daten abzurufen.
- Erstellen Sie einen Model Serving-Endpunkt zum Hosten der Anwendung.
Ausführliche Anleitungen und ein Beispielnotebook finden Sie unter Feature Engineering-Beispiel: strukturierte RAG-Anwendung.
Notebook-Beispiele
Das folgende Notebook veranschaulicht, wie Features in Onlinetabellen veröffentlicht werden, um die Echtzeitbereitstellung zu ermöglichen und automatisierte Featuresuche zu erstellen.
Demonotebook für Onlinetabellen
Verwenden von Onlinetabellen mit Mosaic AI Model Serving
Sie können Onlinetabellen verwenden, um Features für Mosaic AI Model Serving zu suchen. Beim Synchronisieren einer Featuretabelle mit einer Onlinetabelle schlagen Modelle, die mithilfe von Features aus dieser Featuretabelle trainiert wurden, des Rückschlusses automatisch Featurewerte aus der Onlinetabelle nach. Es ist keine zusätzliche Konfiguration erforderlich.
Verwenden Sie
FeatureLookupzum Trainieren des Modells.Verwenden Sie für das Modelltraining Features aus der Offlinefeaturetabelle im Modelltrainingssatz, wie im folgenden Beispiel gezeigt:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Stellen Sie das Modell mit Mosaic AI Model Serving bereit. Das Modell sucht automatisch Features aus der Onlinetabelle. Ausführliche Informationen finden Sie unter Automatische Featuresuche mit Databricks Model Serving.
Benutzerberechtigungen
Sie benötigen die folgenden Berechtigungen, um eine Onlinetabelle zu erstellen:
SELECT-Berechtigung für die QuelltabelleUSE_CATALOG-Berechtigungen für den ZielkatalogUSE_SCHEMA- undCREATE_TABLE-Berechtigungen für das Zielschema
Um die Datensynchronisierungspipeline einer Onlinetabelle zu verwalten, müssen Sie entweder der Besitzer der Onlinetabelle sein oder die REFRESH-Berechtigung für die Onlinetabelle erteilt bekommen. Benutzer*innen, die nicht über die Berechtigungen USE_CATALOG und USE_SCHEMA für den Katalog verfügen, wird die Onlinetabelle im Katalog-Explorer nicht angezeigt.
Der Unity Catalog-Metastore muss über die Version 1.0 des Berechtigungsmodells verfügen.
Endpunktberechtigungsmodell
Ein eindeutiger Dienstprinzipal wird automatisch für einen Featurebereitstellungs- oder Modellbereitstellungsendpunkt mit eingeschränkten Berechtigungen erstellt, die zum Abfragen von Daten und aus Onlinetabellen erforderlich sind. Dieser Dienstprinzipal ermöglicht Endpunkten den Zugriff auf Daten unabhängig vom Benutzer oder von der Benutzerin, der bzw. die die Ressource erstellt hat, und stellt sicher, dass der Endpunkt weiterhin funktionieren kann, wenn der*die Ersteller*in den Arbeitsbereich verlässt.
Die Lebensdauer dieses Dienstprinzipals ist die Lebensdauer des Endpunkts. Überwachungsprotokolle können auf vom System generierte Datensätze für den Besitzer oder die Besitzerin des Unity Catalog-Katalogs hinweisen, die diesem Dienstprinzipal erforderliche Berechtigungen gewähren.
Begrenzungen
- Pro Quelltabelle wird nur eine Onlinetabelle unterstützt.
- Eine Onlinetabelle und die zugehörige Quelltabelle können höchstens 1.000 Spalten enthalten.
- Spalten mit dem Datentyp ARRAY, MAP oder STRUCT können nicht als Primärschlüssel in der Onlinetabelle verwendet werden.
- Wenn eine Spalte als Primärschlüssel in der Onlinetabelle verwendet wird, werden alle Zeilen in der Quelltabelle, in der die Spalte NULL-Werte enthält, ignoriert.
- Fremd-, System- und interne Tabellen werden nicht als Quelltabellen unterstützt.
- Quelltabellen ohne aktivierten Delta-Änderungsdatenfeed unterstützen nur den Synchronisierungsmodus Momentaufnahme.
- Delta Sharing-Tabellen werden nur im Synchronisierungsmodus Momentaufnahme unterstützt.
- Katalog-, Schema- und Tabellennamen der Online-Tabelle dürfen nur alphanumerische Zeichen und Unterstriche enthalten und dürfen nicht mit Zahlen beginnen. Bindestriche (
-) sind nicht zulässig. - Spalten des Zeichenfolgentyps sind auf 64 KB begrenzt.
- Spaltennamen sind auf 64 Zeichen beschränkt.
- Die maximale Größe der Zeile beträgt 2 MB.
- Alle Onlinetabellen in einem Unity Catalog-Metastore können während der öffentlichen Vorschau zusammen 2 TB an unkomprimierten Benutzerdaten enthalten.
- Die maximale Anzahl von Abfragen pro Sekunde (QPS) beträgt 12.000. Wenden Sie sich an Ihr Databricks-Kontoteam, um den Grenzwert zu erhöhen.
Problembehandlung
Die Option Onlinetabelle erstellen wird nicht angezeigt.
Die Ursache ist in der Regel, dass die Tabelle, aus der Sie synchronisieren möchten (die Quelltabelle), kein unterstützter Typ ist. Stellen Sie sicher, dass als sicherungsfähiger Typ der Quelltabelle (im Katalog-Explorer auf der Registerkarte Details) eine der folgenden unterstützten Optionen verwendet wird:
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
Ich kann beim Erstellen einer Onlinetabelle weder Ausgelöst noch Fortlaufend auswählen.
Dies geschieht, wenn die Quelltabelle keinen Delta-Änderungsdatenfeed aktiviert hat oder wenn es sich um eine Ansicht oder eine materialisierte Ansicht handelt. Wenn Sie den Synchronisierungsmodus Inkrementell verwenden möchten, aktivieren Sie entweder den Änderungsdatenfeed für die Quelltabelle, oder verwenden Sie eine Tabelle ohne Sicht.
Onlinetabellenaktualisierung schlägt fehl oder Status wird offline angezeigt
Um mit der Problembehandlung dieses Fehlers zu beginnen, klicken Sie auf die Pipeline-ID, die auf der Registerkarte Übersicht der Onlinetabelle im Katalog-Explorer angezeigt wird.
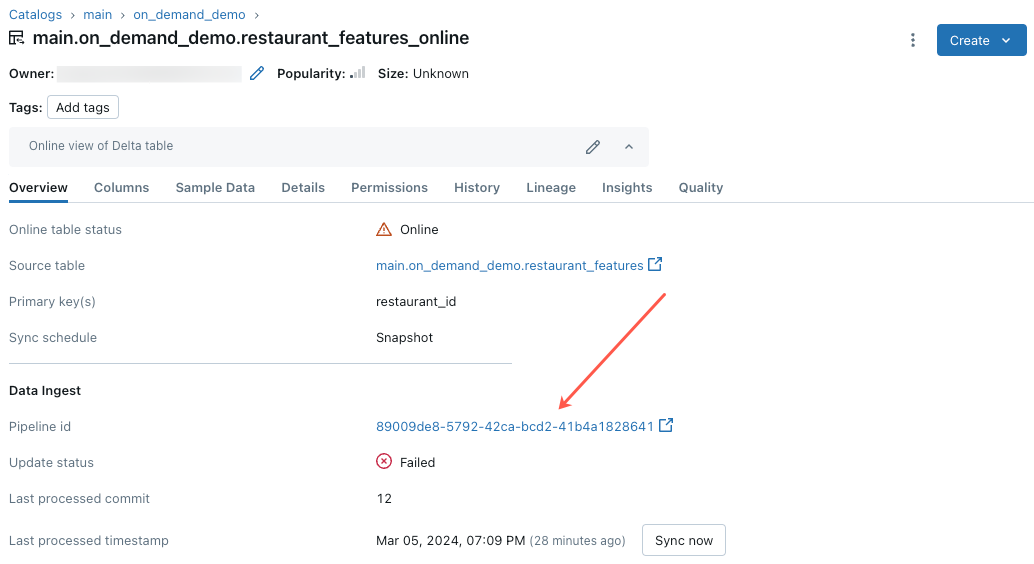
Klicken Sie auf der daraufhin angezeigten Pipeline-Benutzeroberflächenseite auf den Eintrag mit der Meldung „Fehler beim Auflösen des Flows__online_table“.
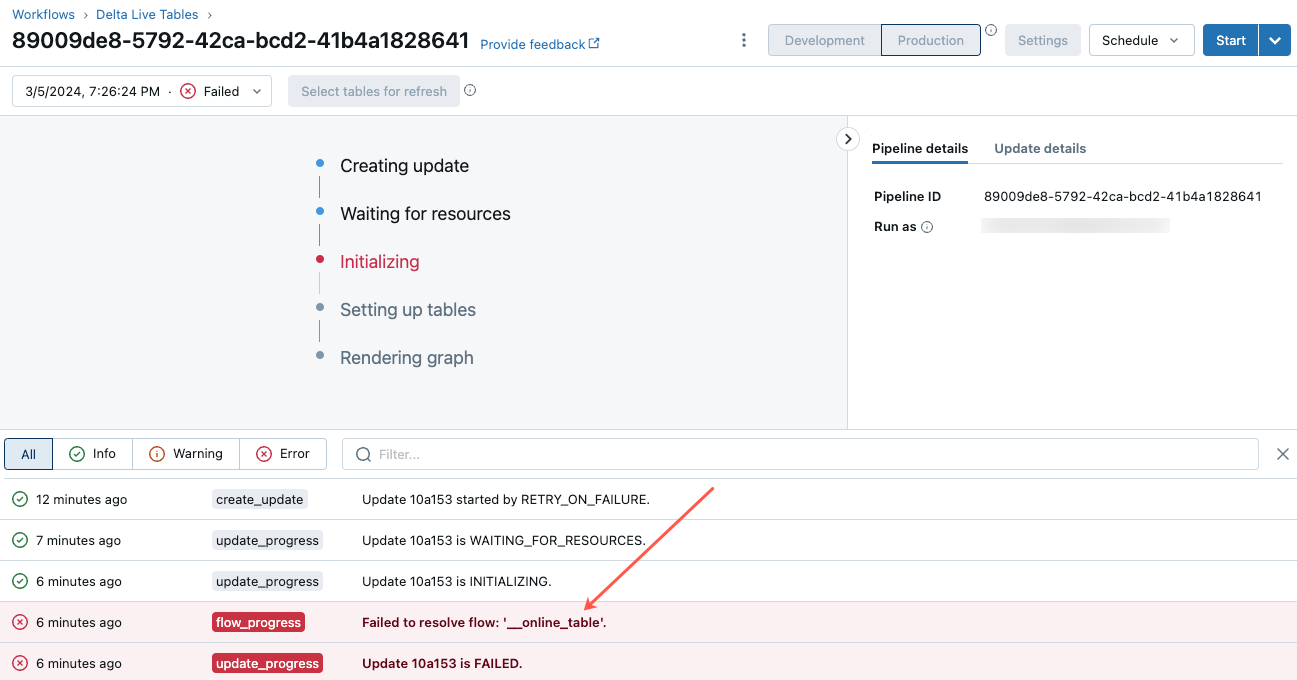
Im Abschnitt Fehlerdetails wird ein Popup mit Details angezeigt.
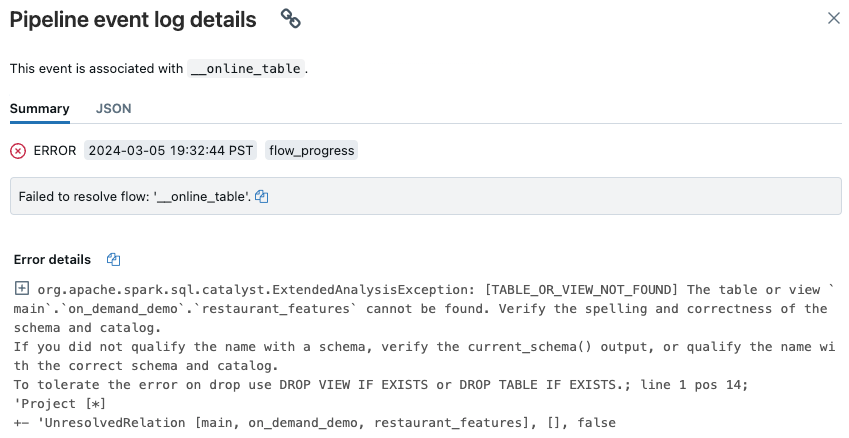
Häufige Fehlerursachen sind unter anderem die folgenden:
Die Quelltabelle wurde gelöscht oder gelöscht und mit demselben Namen neu erstellt, während die Onlinetabelle synchronisiert wurde. Dies ist insbesondere bei kontinuierlichen Onlinetabellen üblich, da sie ständig synchronisiert werden.
Auf die Quelltabelle kann aufgrund von Firewalleinstellungen nicht über serverloses Computing zugegriffen werden. In diesem Fall wird im Abschnitt Fehlerdetails möglicherweise die Fehlermeldung „Fehler beim Starten des DLT-Diensts auf Cluster xxx...“ angezeigt.
Die Aggregierte Größe von Onlinetabellen überschreitet den Metastore-weiten Grenzwert von 2 TB (nicht komprimierte Größe). Der Grenzwert von 2 TB bezieht sich auf die nicht komprimierte Größe nach dem Erweitern der Delta-Tabelle im zeilenorientierten Format. Die Größe der Tabelle im Zeilenformat kann erheblich größer sein als die Größe der Delta-Tabelle, die im Katalog-Explorer angezeigt wird, was auf die komprimierte Größe der Tabelle in einem spaltenorientierten Format verweist. Der Unterschied kann bis zu 100x betragen, je nach Inhalt der Tabelle.
Um die unkomprimierte, zeilenerweiterte Größe einer Delta-Tabelle zu schätzen, verwenden Sie die folgende Abfrage aus einem serverlosen SQL-Warehouse. Die Abfrage gibt die geschätzte erweiterte Tabellengröße in Bytes zurück. Die erfolgreiche Ausführung dieser Abfrage bestätigt außerdem, dass serverloses Computing auf die Quelltabelle zugreifen kann.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;