Was ist ein Data Lakehouse?
Ein Data Lakehouse ist ein Datenverwaltungssystem, das die Vorteile von Data Lakes und Data Warehouses kombiniert. Dieser Artikel beschreibt das architektonische Muster des Lakehouses und was Sie damit machen können.
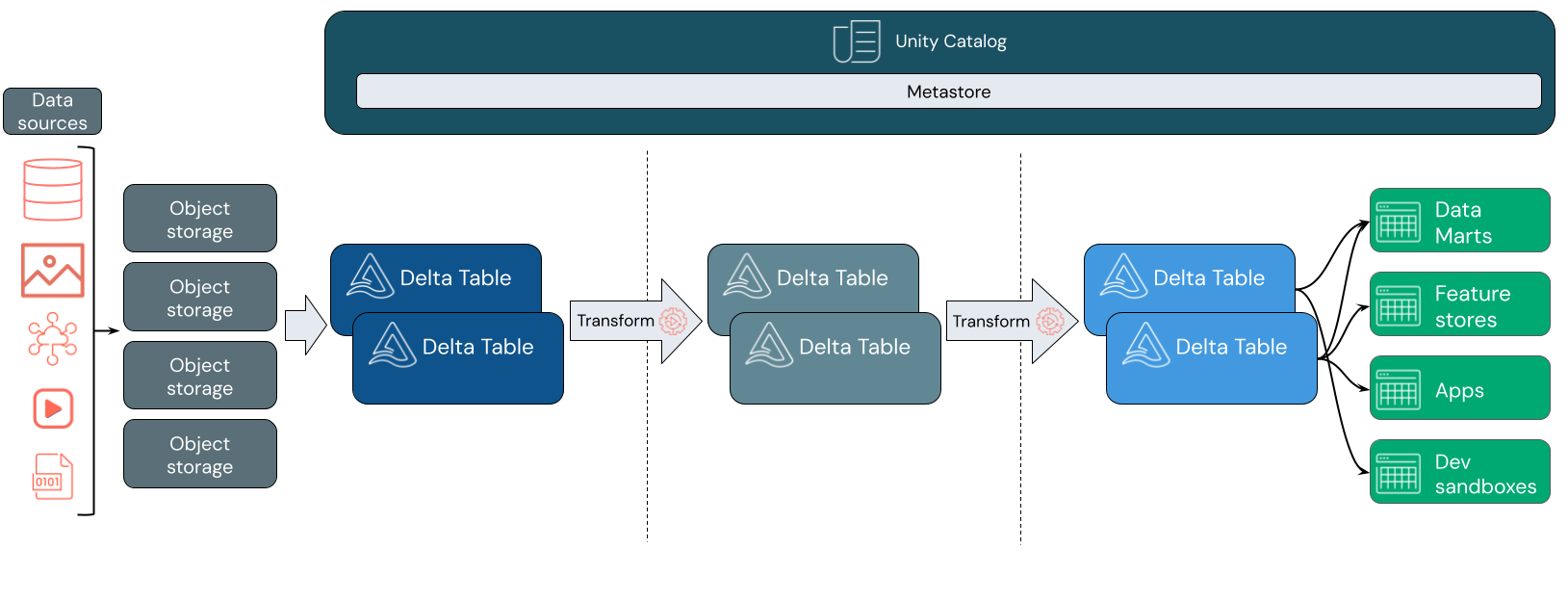
Wofür wird ein Data Lakehouse verwendet?
Ein Data Lakehouse bietet skalierbare Speicher- und Verarbeitungskapazität für moderne Organisationen, die ein isoliertes System für die Verarbeitung verschiedener Workloads vermeiden möchten, z. B. Machine Learning (ML) und Business Intelligence (BI). Ein Data Lakehouse kann dazu beitragen, eine einzige Wahrheitsquelle zu schaffen, redundante Kosten zu beseitigen und die Aktualität der Daten sicherzustellen.
Data Lakehouses verwenden häufig ein Datenentwurfsmuster, das Daten inkrementell verbessert, anreichert und optimiert, während sie sich durch Ebenen von Staging und Transformation bewegen. Jede Ebene des Lakehouses kann eine oder mehrere Ebenen enthalten. Dieses Muster wird häufig als Medallion-Architektur bezeichnet. Weitere Informationen finden Sie unter Was ist die Medallion Lakehouse-Architektur?
Wie funktioniert das Databricks Lakehouse?
Databricks basiert auf Apache Spark. Apache Spark bietet ein massiv skalierbares Modul, das auf Computeressourcen ausgeführt wird, die vom Speicher entkoppelt werden. Weitere Informationen finden Sie unter Apache Spark in Azure Databricks
Das Databricks Lakehouse verwendet zwei zusätzliche Schlüsseltechnologien:
- Delta Lake: eine optimierte Speicherebene, die ACID-Transaktionen und Schemaerzwingung unterstützt.
- Unity Catalog: eine einheitliche, präzise Governancelösung für Daten und KI.
Datenerfassung
Auf der Erfassungsebene kommen Batch- oder Streamingdaten aus einer Vielzahl von Quellen und in einer Vielzahl von Formaten an. Diese erste logische Ebene stellt einen Ort bereit, an dem diese Daten im rohen Format landen. Wenn Sie diese Dateien in Delta-Tabellen konvertieren, können Sie die Delta-Schemaerzwingungsfunktionen verwenden, um nach fehlenden oder unerwarteten Daten zu suchen. Sie können Unity Catalog verwenden, um Tabellen gemäß Ihrem Datengovernancemodell und den erforderlichen Datenisolationsgrenzen zu registrieren. Unity Catalog ermöglicht es Ihnen, die Herkunft Ihrer Daten nachzuverfolgen, während sie transformiert und verfeinert werden, sowie ein einheitliches Governancemodell anzuwenden, um vertrauliche Daten privat und sicher zu halten.
Datenverarbeitung, -kuration und -integration
Nach der Überprüfung können Sie ihre Daten zusammenstellen und verfeinern. Wissenschaftliche Fachkräfte für Daten und Fachkräfte für Machine Learning arbeiten in dieser Phase häufig mit Daten, um mit der Kombination oder Erstellung neuer Features und vollständigen Datenbereinigung zu beginnen. Nachdem Ihre Daten gründlich bereinigt wurden, können sie in Tabellen integriert und neu organisiert werden, die ihren speziellen Geschäftsanforderungen entsprechen.
Ein Schema-on-Write-Ansatz, kombiniert mit den Delta-Schemaentwicklungsfunktionen, bedeutet, dass Sie Änderungen an dieser Ebene vornehmen können, ohne die nachgelagerte Logik, die Daten für Ihre Endbenutzer*innen liefert, neu schreiben zu müssen.
Datenbereitstellung
Die letzte Ebene stellt saubere, angereicherte Daten für Endbenutzer*innen bereit. Die endgültigen Tabellen sollten so konzipiert sein, dass Sie Daten für alle Ihre Anwendungsfälle bereitstellen. Ein einheitliches Governancemodell bedeutet, dass Sie die Datenherkunft zurück zu Ihrer einzigen Quelle der Wahrheit (Source of Truth) nachverfolgen können. Datenlayouts, die für unterschiedliche Aufgaben optimiert sind, ermöglichen Endbenutzer*innen den Zugriff auf Daten für Machine Learning-Anwendungen, Datentechnik und Business Intelligence und Berichterstellung.
Weitere Informationen zu Delta Lake finden Sie unter Was ist Delta Lake? Weitere Informationen zum Unity Catalog finden Sie unter Was ist Unity Catalog?
Funktionen eines Azure Databricks Lakehouses
Ein Lakehouse, das auf Databricks basiert, beseitigt die aktuelle Abhängigkeit moderner Datenunternehmen von Data Lakes und Data Warehouses. Einige wichtige Aufgaben, die Sie ausführen können, umfassen:
- Datenverarbeitung in Echtzeit: Verarbeiten Sie Streamingdaten in Echtzeit zur sofortigen Analyse und zum sofortigen Handeln.
- Datenintegration: Vereinheitlichen Sie alle Ihre Daten in einem einzigen System, um die Zusammenarbeit zu ermöglichen und eine einzige Quelle der Wahrheit für Ihre Organisation zu schaffen.
- Schemaentwicklung: Ändern Sie das Datenschema im Laufe der Zeit, um sich an sich ändernde Geschäftsanforderungen anzupassen, ohne vorhandene Datenpipelines zu unterbrechen.
- Datentransformationen: Die Verwendung von Apache Spark und Delta Lake bringt Geschwindigkeit, Skalierbarkeit und Zuverlässigkeit zu Ihren Daten.
- Datenanalyse und -berichterstellung: Führen Sie komplexe Analyseabfragen mit einem Modul aus, das für Data Warehouse-Workloads optimiert ist.
- Maschinelles Lernen und KI: Wenden Sie erweiterte Analysetechniken auf alle Ihre Daten an. Verwenden Sie ML, um Ihre Daten anzureichern und andere Workloads zu unterstützen.
- Datenversionsverwaltung und Datenherkunft: Verwalten Sie den Versionsverlauf für Datasets und verfolgen Sie die Datenherkunft nach, um die Herkunft und Rückverfolgbarkeit von Daten sicherzustellen.
- Datengovernance: Verwenden Sie ein einzelnes, einheitliches System, um den Zugriff auf Ihre Daten zu steuern und Überprüfungen durchzuführen.
- Datenfreigabe: Vereinfachen Sie die Zusammenarbeit durch die Freigabe kuratierter Datasets, Berichte und Einblicke in Teams.
- Operative Analysen: Überwachen Sie Datenqualitätsmetriken, Modellqualitätsmetriken und Datendrift, indem Sie maschinelles Lernen auf Ihre Lakehouse-Überwachungsdaten anwenden.
Vergleich von Lakehouse, Data Lake und Data Warehouse
Data Warehouses bilden seit ungefähr 30 Jahren die Basis für Business Intelligence(BI)-Entscheidungen. Sie haben sich zu einer Reihe von Entwurfsrichtlinien für Systeme entwickelt, die den Datenfluss steuern. Enterprise Data Warehouses optimieren Abfragen für BI-Berichte – das Generieren der Ergebnisse kann hingegen Minuten oder sogar Stunden dauern. Sie wurden für Daten entwickelt, die sich sehr wahrscheinlich nur selten ändern, daher versuchen Data Warehouses, Konflikte zwischen gleichzeitig ausgeführten Abfragen zu verhindern. Viele Data Warehouses basieren auf proprietären Formaten, die häufig die Unterstützung für maschinelles Lernen einschränken. Data Warehousing in Azure Databricks nutzt die Funktionen von Databricks Lakehouse und Databricks SQL. Weitere Informationen finden Sie unter Was ist Data Warehousing in Azure Databricks?.
Aufgrund des technologischen Fortschritts bei der Datenspeicherung und der exponentiellen Zunahme der Anzahl von Datentypen und des Datenvolumens, wurden in den letzten zehn Jahren immer häufiger Data Lakes eingesetzt. In Data Lakes können Daten günstig und effizient gespeichert und verarbeitet werden. Die Definition von Data Lake bezieht sich häufig auf die Unterschiede zu Data Warehouses: Ein Data Warehouse liefert saubere, strukturierte Daten für BI-Analysen, während ein Data Lake dauerhaft und günstig Daten jeglicher Art in jedem Format speichert. Viele Organisationen verwenden Data Lakes für Data Science und maschinelles Lernen, aber aufgrund fehlender Validierung nicht für BI-Berichte.
Das Data Lakehouse kombiniert die Vorteile von Data Lakes und Data Warehouses und stellt Folgendes bereit:
- Offener und direkter Zugriff auf Daten, die in Standarddatenformaten gespeichert sind
- Indizierungsprotokolle, die für maschinelles Lernen und Data Science optimiert sind
- Niedrige Abfragelatenz und hohe Zuverlässigkeit für BI und komplexe Analysen
Durch die Kombination einer optimierten Metadatenebene mit validierten Daten, die in Standardformaten im Cloudobjektspeicher gespeichert sind, ermöglicht ein Data Lakehouse wissenschaftlichen Fachkräften für Daten und technischen Fachkräften für ML, Modelle aus den gleichen datengesteuerten BI-Berichten zu erstellen.
Nächster Schritt
Weitere Informationen zu den Prinzipien und bewährten Methoden zum Implementieren und Betreiben eines Lakehouse mithilfe von Databricks finden Sie unter Einführung in das gut strukturierte Data Lakehouse.