Data Lakehouse-Architektur: gut strukturiertes Framework von Databricks
Diese Reihe von Architekturartikeln bietet Prinzipien und bewährte Methoden für die Implementierung und den Betrieb eines Data Lakehouse mit Azure Databricks.
Das gut strukturierte Framework von Databricks für das Data Lakehouse
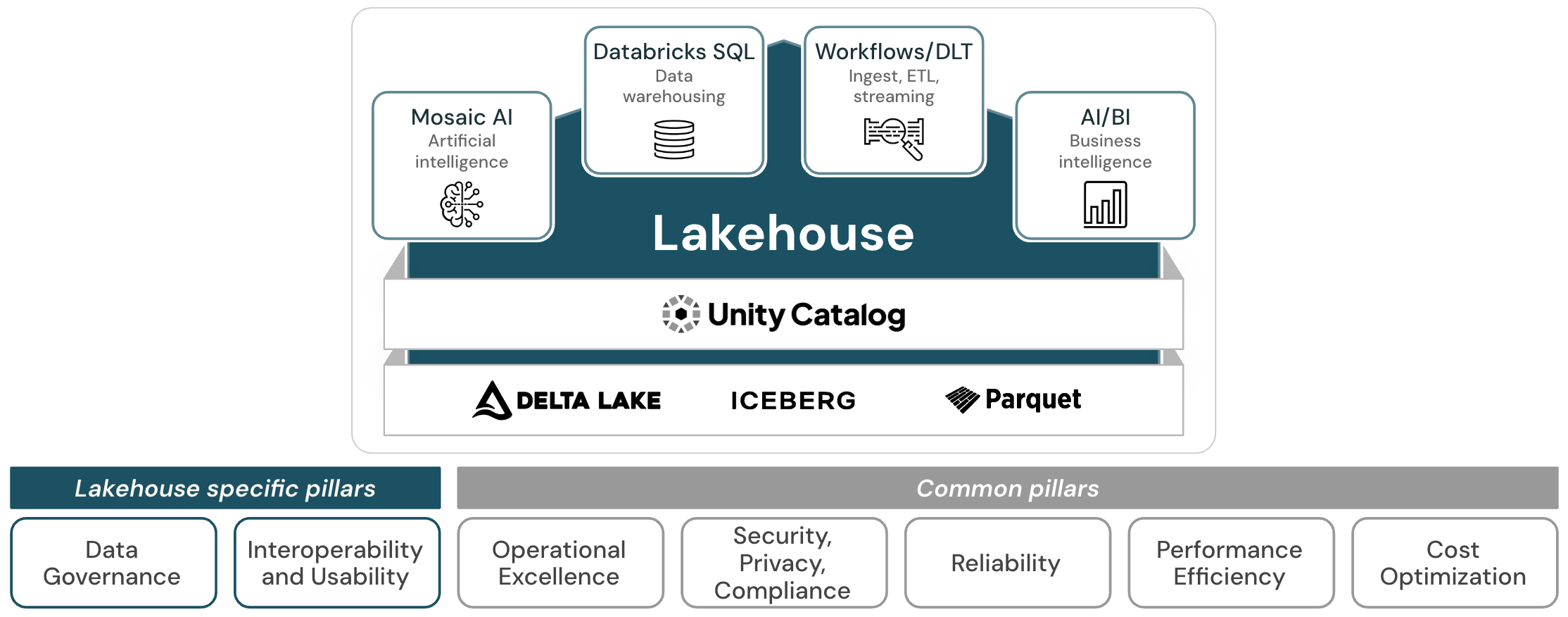
Das gut strukturierte Lakehouse besteht aus 7 Säulen, die unterschiedliche Bereiche beschreiben, die bei der Umsetzung eines Data Lakehouse in der Cloud zu beachten sind:
Datengovernance
Die Aufsicht, um sicherzustellen, dass Daten einen Mehrwert bringen und Ihre Geschäftsstrategie unterstützen.
Interoperabilität und Benutzerfreundlichkeit
Die Fähigkeit des Lakehouse, mit anderen Systemen und Benutzer*innen zu interagieren.
Operational Excellence
Alle Betriebsabläufe, die das Lakehouse in der Produktion am Laufen halten.
Sicherheit, Datenschutz und Compliance
Schützen Sie die Azure Databricks-Anwendung, Kundenworkloads und Kundendaten vor Bedrohungen.
Zuverlässigkeit
Die Fähigkeit eines Systems, nach Ausfällen eine Wiederherstellung durchzuführen und die Betriebsbereitschaft sicherzustellen.
Effiziente Leistung
Die Fähigkeit eines Systems, sich an Laständerungen anzupassen
Kostenoptimierung
Verwalten der Kosten zur Maximierung des erzielten Werts
Das gut strukturierte Lakehouse erweitert das Microsoft Azure Well-Architected Framework auf die Data Intelligence-Plattform von Databricks und teilt mit diesem die Säulen „Optimaler Betrieb“, „Sicherheit“ (als „Sicherheit, Datenschutz und Compliance“), „Zuverlässigkeit“, „Leistungseffizienz“ und „Kostenoptimierung“.
In Bezug auf diese fünf Säulen gelten die Grundsätze und bewährten Methoden des Cloud-Frameworks auch für das Lakehouse. Das gut strukturierte Lakehouse erweitert diese mit Prinzipien und bewährten Methoden, die für das Lakehouse spezifisch und für den Aufbau eines effektiven und effizienten Lakehouse wichtig sind.
Datengovernance und Interoperabilität und Benutzerfreundlichkeit in Lakehouse-Architekturen
Die Säulen „Datengovernance“ und „Interoperabilität und Benutzerfreundlichkeit“ decken spezifische Belange des Lakehouse ab.
Data Governance umfasst die Richtlinien und Praktiken, die implementiert werden, um die Datenbestände innerhalb einer Organisation sicher zu verwalten. Einer der grundlegenden Aspekte eines Lakehouses ist die zentrale Datengovernance: Das Lakehouse vereint Data Warehouse- und KI-Anwendungsfälle auf einer einzigen Plattform. Dies vereinfacht den modernen Datenstapel, indem die Datensilos eliminiert werden, die Datentechnik, Analyse, BI, Data Science und maschinelles Lernen traditionell trennen und verkomplizieren. Zur Vereinfachung der Datengovernance bietet das Lakehouse eine einheitliche Governancelösung für Daten, Analysen und KI. Durch die Minimierung der Datenkopien und die Umstellung auf eine einzige Datenverarbeitungsebene, in der alle Data-Governance-Kontrollen zusammenlaufen können, verbessern Sie Ihre Chancen, konform zu bleiben und Datenschutzverletzungen zu erkennen.
Ein weiterer wichtiger Bestandteil des Lakehouse ist die Bereitstellung einer großartigen Benutzererfahrung für alle damit arbeitenden Personas und die Fähigkeit, mit einem breiten Ökosystem externer Systeme zu interagieren. Azure verfügt bereits über eine Vielzahl von Datentools, die die meisten Aufgaben erfüllen, die ein datengesteuertes Unternehmen möglicherweise benötigt. Diese Tools müssen jedoch ordnungsgemäß zusammengestellt werden, um alle Funktionen bereitzustellen, wobei jeder Dienst eine andere Benutzererfahrung bietet. Dieser Ansatz kann zu hohen Implementierungskosten führen und bietet in der Regel nicht die gleiche Benutzererfahrung wie eine native Lakehouse-Plattform: Benutzer*innen sind durch Inkonsistenzen zwischen Tools und fehlenden Funktionen für die Zusammenarbeit begrenzt und müssen häufig komplexe Prozesse durchlaufen, um Zugriff auf das System und damit auf die Daten zu erhalten.
Ein integriertes Lakehouse bietet andererseits eine konsistente Benutzererfahrung über alle Workloads hinweg und erhöht somit die Benutzerfreundlichkeit. Dadurch werden Trainings- und Onboardingkosten reduziert und die Zusammenarbeit zwischen Funktionen verbessert. Überdies werden automatisch im Laufe der Zeit neue Features hinzugefügt (um die Benutzererfahrung weiter zu verbessern), ohne interne Ressourcen und Budgets investieren zu müssen.
Ein Multicloud-Ansatz kann eine bewusste Strategie eines Unternehmens oder das Ergebnis von Fusionen und Akquisitionen oder unabhängigen Geschäftseinheiten sein, die verschiedene Cloudanbieter auswählen. In diesem Fall resultiert die Verwendung eines Multicloud-Lakehouse in einer einheitlichen Benutzererfahrung in allen Clouds. Dadurch wird die Verbreitung von Systemen im gesamten Unternehmen reduziert, was wiederum den Qualifikations- und Trainingsbedarf der mit datengesteuerten Aufgaben betrauten Mitarbeiter*innen verringert.
Schließlich müssen in einer vernetzten Welt mit unternehmensübergreifenden Geschäftsprozessen die Systeme so nahtlos wie möglich zusammenarbeiten. Der Grad der Interoperabilität ist hier ein entscheidendes Kriterium, und die aktuellen Daten müssen als Kernstück eines jeden Unternehmens sicher zwischen den Systemen interner und externer Partner fließen.