Lakehouse-Referenzarchitekturen (Download)
Dieser Artikel befasst sich mit architektonischen Anleitungen für das Seehaus in Bezug auf Datenquelle, Erfassung, Transformation, Abfrage und Verarbeitung, Bereitstellung, Analyse und Speicherung.
Für jede Referenzarchitektur gibt es eine herunterladbare PDF-Datei im Format 11 x 17 (A3).
Während das Lakehouse auf Databricks eine offene Plattform ist, die in ein großes Ökosystem von Partnertoolsintegriert ist, konzentrieren sich die Referenzarchitekturen nur auf Azure-Dienste und das Databricks Lakehouse. Die angezeigten Cloudanbieterdienste sind ausgewählt, um die Konzepte zu veranschaulichen und nicht erschöpfend zu sein.
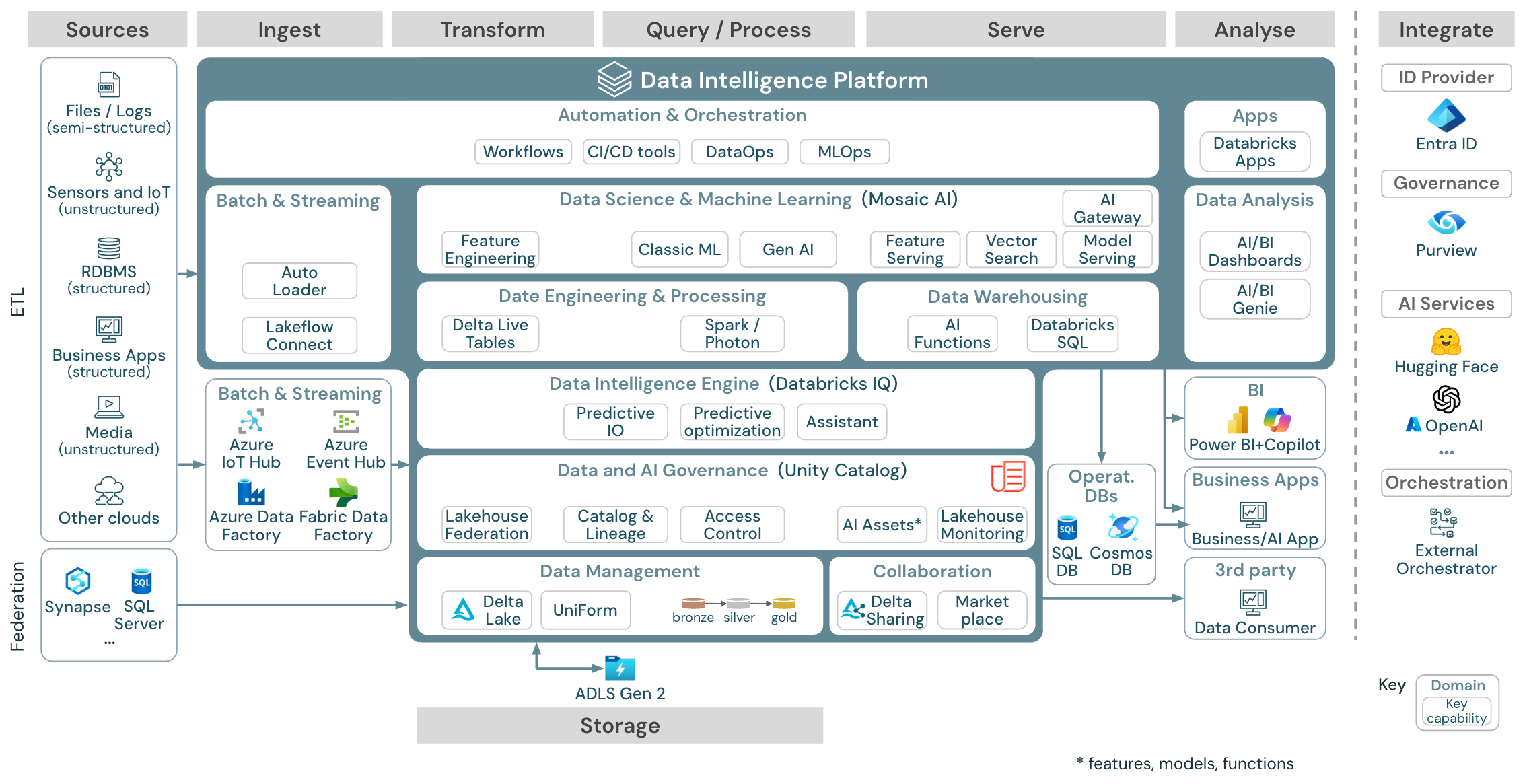
Download: Referenzarchitektur für das Azure Databricks Lakehouse
Die Azure-Referenzarchitektur zeigt die folgenden Azure-spezifischen Dienste zum Aufnehmen, Speichern, Bereitstellung und Analysieren:
- Azure Synapse und SQL Server als Quellsysteme für den Lakehouse-Verbund
- Azure IoT Hub und Azure Event Hubs für Streamingerfassung
- Azure Data Factory für Batcherfassung
- Azure Data Lake Storage Gen 2 (ADLS) als Objektspeicher
- Azure SQL DB und Azure Cosmos DB als Betriebsdatenbanken
- Azure Purview als Unternehmenskatalog, in welches UC Schema- und Abstammungsinformationen exportiert.
- Power BI als BI-Tool
Organisation der Referenzarchitekturen
Die Referenzarchitektur gliedert sich in die Verantwortlichkeitsbereiche Quelle, Erfassung, Transformation, Abfrage/Verarbeitung, Bereitstellung, Analyse und Speicherung:
Quelle
Die Architektur unterscheidet zwischen halbstrukturierten und unstrukturierten Daten (Sensoren und IoT, Medien, Dateien/Protokolle) und strukturierten Daten (RDBMS, Geschäftsanwendungen). SQL-Quellen (RDBMS) können über den Lakehouse-Verbund auch ohne ETL in das Lakehouse und Unity Catalog integriert werden. Darüber hinaus können Daten von anderen Cloudanbietern geladen werden.
Erfassen
Daten können per Batch oder Streaming im Lakehouse erfasst werden:
- Databricks LakeFlow Connect bietet integrierte Connectors zum Erfassen von Daten aus Unternehmensanwendungen und Datenbanken. Die resultierende Erfassungspipeline wird über Unity Catalog gesteuert und von serverlosem Computing sowie Delta Live Tables (DLT) unterstützt.
- An den Cloudspeicher übermittelte Dateien können direkt mit Databricks Autoloader geladen werden.
- Für die Batcherfassung von Daten aus Unternehmensanwendungen in Delta Lake greift das Databricks-Lakehouse auf Erfassungstools von Partnern zurück, die über spezielle Adapter für diese Systeme verfügen.
- Streamingereignisse können direkt von Ereignisstreamingsystemen wie Kafka mithilfe der strukturierten Streams von Databricks erfasst werden. Streamingquellen können Sensoren, IoT oder Prozesse zur Erfassung von Änderungsdaten sein.
Storage
Die Daten werden in der Regel in einem Cloudspeichersystem gespeichert, in dem die ETL-Pipelines die Medaillon-Architektur verwenden, um die Daten auf kuratierte Weise als Delta-Dateien/Tabellen zu speichern.
Transformation und Abfrage/Verarbeitung
Das Lakehouse von Databricks nutzt seine Module Apache Spark und Photon für alle Transformationen und Abfragen.
DLT (Delta Live Tables) ist ein deklaratives Framework zum Vereinfachen und Optimieren von zuverlässigen, wartungsfähigen und testbaren Datenverarbeitungspipelines.
Powered by Apache Spark und Photon, unterstützt die Databricks Data Intelligence-Plattform beide Workloadtypen: SQL-Abfragen über SQL-Warehouses und SQL-, Python- und Scala-Workloads über Arbeitsbereichscluster.
Für Data Science (ML Modeling und Gen KI) bietet die Databricks-Plattform für Machine Learning und KI spezielle ML-Runtimes für AutoML und für die Codierung von ML-Aufträgen. Alle Data Science- und MLOps-Workflows werden am besten von MLflow unterstützt.
Bereitstellung
Für DWH- und BI-Anwendungsfälle bietet das Databricks-Lakehouse Databricks SQL, das Data Warehouse unterstützt von SQL-Warehouses und serverlosen SQL-Warehouses.
Für maschinelles Lernen ist Model Serving eine skalierbare Funktion für Modellbereitstellung in Echtzeit auf Unternehmensniveau, die auf der Databricks-Steuerungsebene gehostet wird. Mosaik AI Gateway ist Databricks-Lösung zum Verwalten und Überwachen des Zugriffs auf unterstützte generative KI-Modelle und deren zugeordnetes Modell, das Endpunkte bedient.
Betriebsdatenbanken: Externe Systeme, z. B. operative Datenbanken, können zur Speicherung und Bereitstellung von endgültigen Datenprodukten für Benutzeranwendungen verwendet werden.
Zusammenarbeit: Geschäftspartner erhalten über Delta Sharing sicheren Zugriff auf die benötigten Daten. Databricks Marketplace basiert auf Delta Sharing und ist ein offenes Forum für den Austausch von Datenprodukten.
Analyse
Die endgültigen Geschäftsanwendungen befinden sich in diesem Verantwortlichkeitsbereich. Beispiele hierfür sind benutzerdefinierte Clients wie KI-Anwendungen, die für Echtzeitrückschlüsse mit Mosaic AI Model Serving verbunden sind, oder Anwendungen, die auf Daten zugreifen, die vom Lakehouse in eine Betriebsdatenbank gepusht wurden.
Für BI-Anwendungsfälle verwenden Analysten in der Regel BI-Tools für den Zugriff auf das Data Warehouse. SQL-Entwickler können zusätzlich den Databricks SQL Editor (nicht im Diagramm dargestellt) für Abfragen und Dashboardvorgänge verwenden.
Die Data Intelligence-Plattform bietet auch Dashboards zur Erstellung von Datenvisualisierungen und zur Freigabe von Erkenntnissen.
Integrieren
Die Databricks-Plattform ist in Standardidentitätsanbieter für Benutzerverwaltung und einmaliges Anmelden (Single Sign-On, SSO)integriert.
Externe KI-Dienste wie OpenAI, LangChain oder HuggingFace können direkt aus der Databricks Intelligence Platform verwendet werden.
Externe Orchestratoren können entweder die umfassende REST-API- oder dedizierte Anschlüsse für externe Orchestrierungstools wie Apache Airflowverwenden.
Unity Catalog wird für die gesamte Daten- und KI-Governance in Databricks Intelligence Platform verwendet und kann andere Datenbanken über den Lakehouse-Verbund in die Governance integrieren.
Darüber hinaus kann Unity-Katalog in andere Unternehmenskataloge integriert werden, z. B. Purview-. Wenden Sie sich an den Anbieter des Unternehmenskatalogs, um Weitere Informationen zu erhalten.
Allgemeine Funktionen für alle Workloads
Darüber hinaus verfügt das Databricks-Lakehouse über Verwaltungsfunktionen, die alle Workloads unterstützen:
Daten- und KI-Governance
Das zentrale Daten- und KI-Governancesystem in der Databricks Data Intelligence-Plattform ist Unity Catalog. Unity Catalog bietet einen zentralen Ort für die Verwaltung von Datenzugriffsrichtlinien, die für alle Arbeitsbereiche gelten, und unterstützt alle Ressourcen, die im Lakehouse erstellt oder verwendet werden, wie Tabellen, Volumes, Features (Feature Store) und Modelle (Modellregistrierung). Unity Catalog kann auch verwendet werden, um die Runtime-Datenherkunft über Abfragen hinweg zu erfassen, die für Databricks ausgeführt werden.
Mit der Lakehouse-Überwachung von Databricks können Sie die Datenqualität von allen Tabellen Ihres Kontos überwachen. Außerdem lässt sich damit die Leistung von Machine Learning-Modellen und Endpunkten, die Modelle bereitstellen nachverfolgen.
Systemtabellen sind ein von Azure Databricks gehosteter Analysespeicher der Betriebsdaten Ihres Kontos, der Einblick bietet. Systemtabellen können für die Verlaufsbeobachtung Ihres Kontos verwendet werden.
Data Intelligence-Modul
Die Databricks Data Intelligence-Plattform ermöglicht Ihrer gesamten Organisation die Nutzung von Daten und KI. Sie wird von DatabricksIQ unterstützt und kombiniert generative KI mit den Vereinheitlichungsvorteilen eines Lakehouse, um die einzigartige Semantik Ihrer Daten zu verstehen.
Der Databricks-Assistent ist als kontextabhängiger KI-Assistent in Databricks-Notebooks, SQL-Editor und Datei-Editor verfügbar.
Automatisierung und Orchestrierung
Databricks-Aufträge orchestrieren Datenverarbeitungs- und Analysepipelines sowie Pipelines des maschinellen Lernens auf der Databricks Data Intelligence-Plattform. M;it Delta Live Tables können Sie zuverlässige und wartungsfähige ETL-Pipelines mit deklarativer Syntax erstellen. Die Plattform unterstützt auch CI/CD und MLOps.
Hochrangige Anwendungsfälle für die Data Intelligence Platform auf Azure
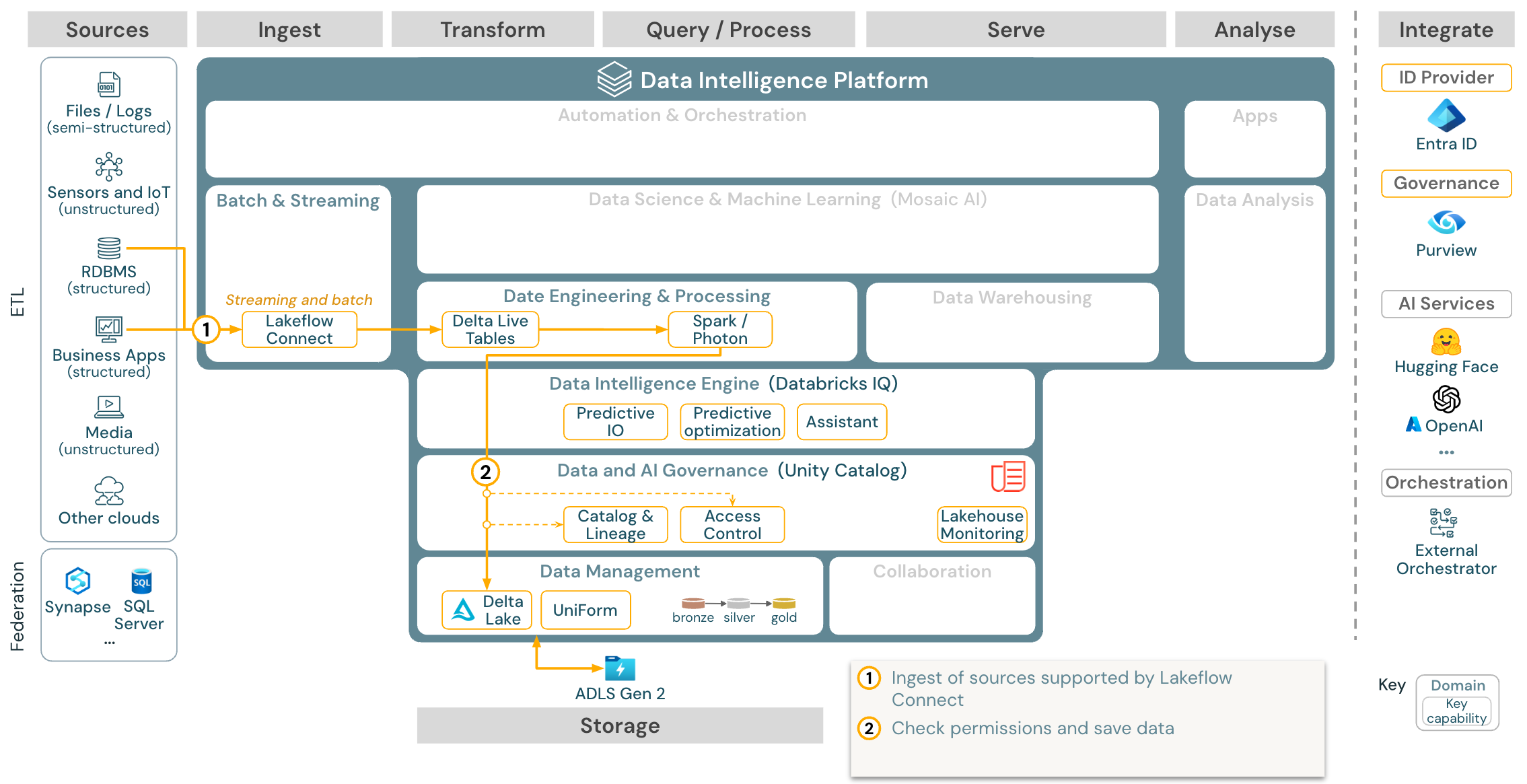
Databricks LakeFlow Connect bietet integrierte Konnektoren für die Datenübernahme aus Unternehmensanwendungen und Datenbanken. Die resultierende Erfassungspipeline wird über Unity Catalog gesteuert und von serverlosem Computing sowie Delta Live Tables (DLT) unterstützt. LakeFlow Connect nutzt effiziente inkrementelle Lese- und Schreibvorgänge, um die Datenerfassung schneller, skalierbarer und kosteneffizienter zu gestalten, während Ihre Daten für den nachgeschalteten Verbrauch frisch bleiben.
Anwendungsfall: Datenerfassung mit Lakeflow Connect
Herunterladen: Batch-ETL-Referenzarchitektur für Azure Databricks.
Anwendungsfall: Batch ETL
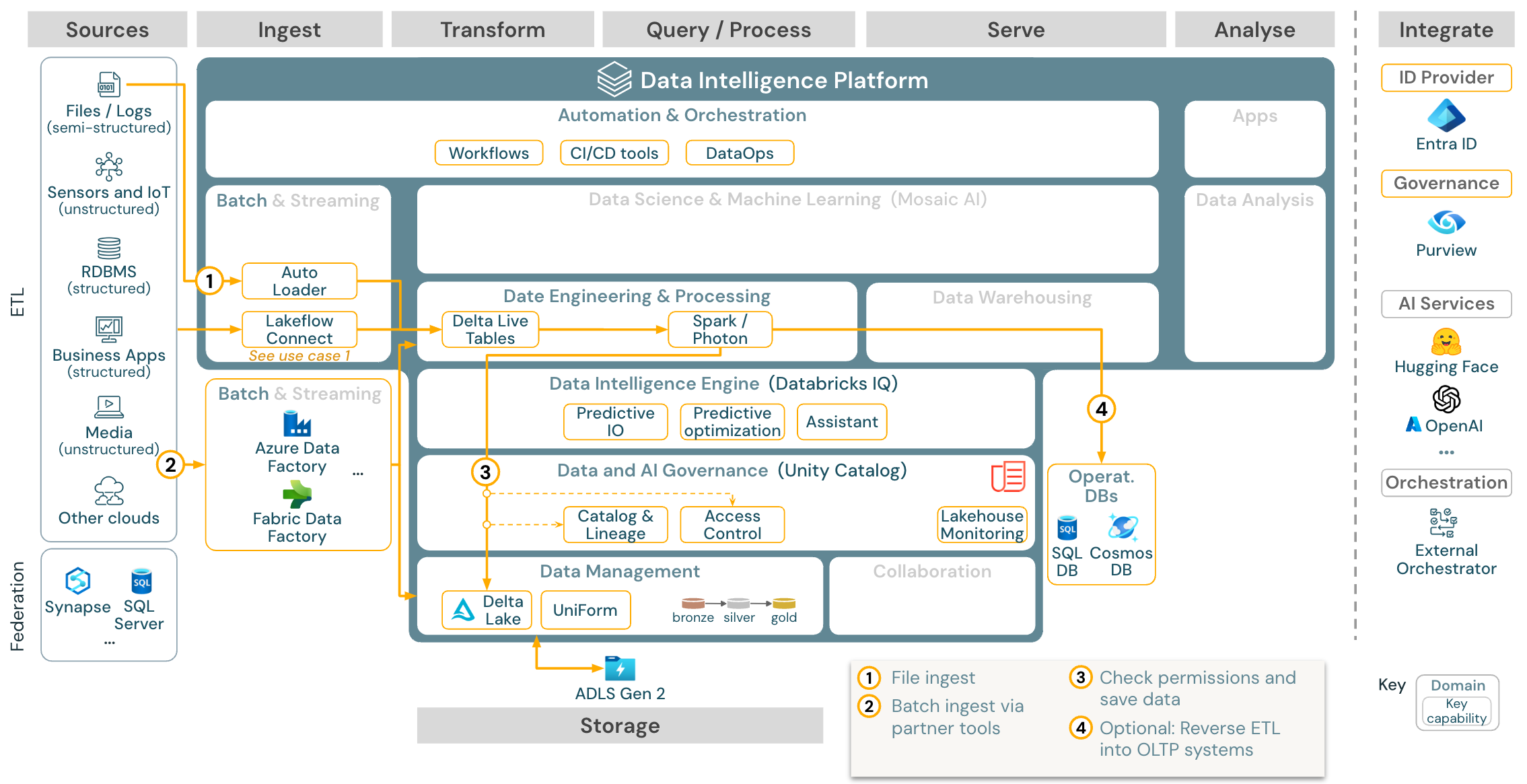
Download: Batch ETL-Referenzarchitektur für Azure Databricks
Erfassungstools verwenden quellenspezifische Adapter, um Daten aus der Quelle zu lesen und sie dann entweder im Cloudspeicher zu speichern, aus dem Autoloader sie lesen kann, oder Databricks direkt aufzurufen (z. B. mit in das Databricks-Lakehouse integrierten Erfassungstools von Partnern). Um die Daten zu laden, führt das ETL- und Verarbeitungsmodul von Databricks – über DLT – die Abfragen aus. Workflows mit einer oder mehreren Aufgaben können durch Databricks-Aufträge orchestriert und durch Unity Catalog verwaltet werden (Zugriffssteuerung, Überwachung, Datenherkunft usw.). Wenn latenzarme Betriebssysteme Zugriff auf bestimmte goldene Tabellen benötigen, können diese am Ende der ETL-Pipeline in eine Betriebsdatenbank wie ein RDBMS oder einen Schlüssel-Wert-Speicher exportiert werden.
Anwendungsfall: Streamen und Change Data Capture (CDC)
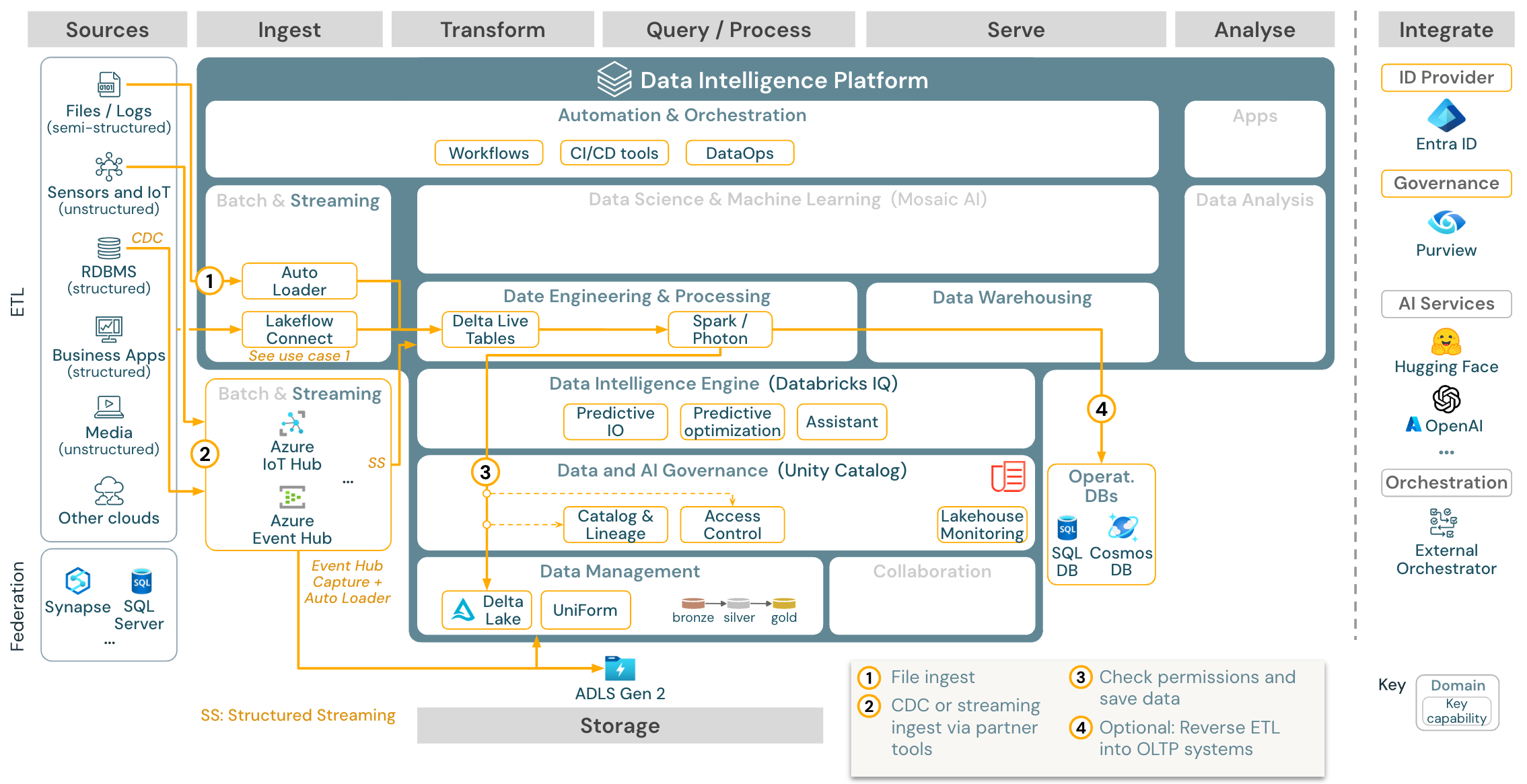
Download: Strukturierte Spark-Streamingarchitektur für Azure Databricks
Das ETL-Modul von Databricks verwendet strukturiertes Spark-Streaming zum Lesen aus Ereigniswarteschlangen wie Apache Kafka oder Azure Event Hub. Die nachgelagerten Schritte folgen dem Ansatz des obigen Batchanwendungsfalls.
Change Data Capture (CDC) in Echtzeit verwendet in der Regel eine Ereigniswarteschlange zum Speichern der extrahierten Ereignisse. Ab dort folgt der Anwendungsfall dem Streaminganwendungsfall.
Wenn CDC in Batch erfolgt, in dem die extrahierten Datensätze zuerst im Cloudspeicher gespeichert werden, kann Databricks Autoloader sie lesen und der Anwendungsfall folgt Batch-ETL.
Anwendungsfall: Maschinelles Lernen und KI
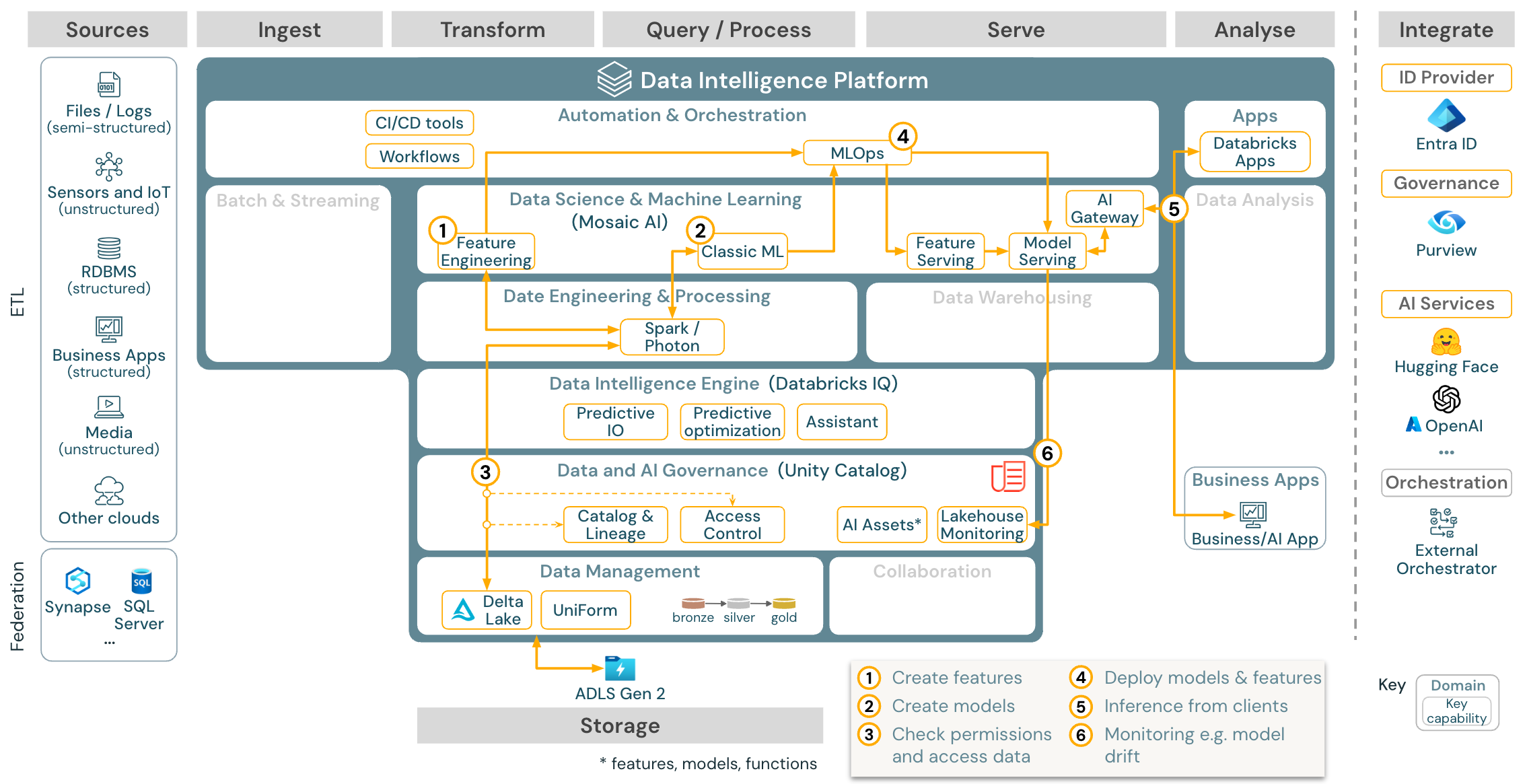
Download: Referenzarchitektur für maschinelles Lernen und KI für Azure Databricks
Für maschinelles Lernen bietet die Databricks Data Intelligence-Plattform Mosaic AI mit modernsten Computern und Deep Learning-Bibliotheken. Diese KI bietet Funktionen wie Feature Store und Modellregistrierung (beides in Unity Catalog integriert), Low-Code-Features mit AutoML und MLflow-Integration in den Data Science-Lebenszyklus.
Alle datenwissenschaftlichen Ressourcen (Tabellen, Features und Modelle) werden von Unity Catalog verwaltet, und wissenschaftliche Fachkräfte für Daten können Databricks-Aufträge zur Orchestrierung ihrer Aufgaben verwenden.
Verwenden Sie die MLOps-Funktionen zur Veröffentlichung der Modelle in Model Serving, um Modelle auf skalierbare und unternehmensgerechte Weise bereitzustellen.
Anwendungsfall: Generative KI-Agent-Anwendungen (Gen AI)
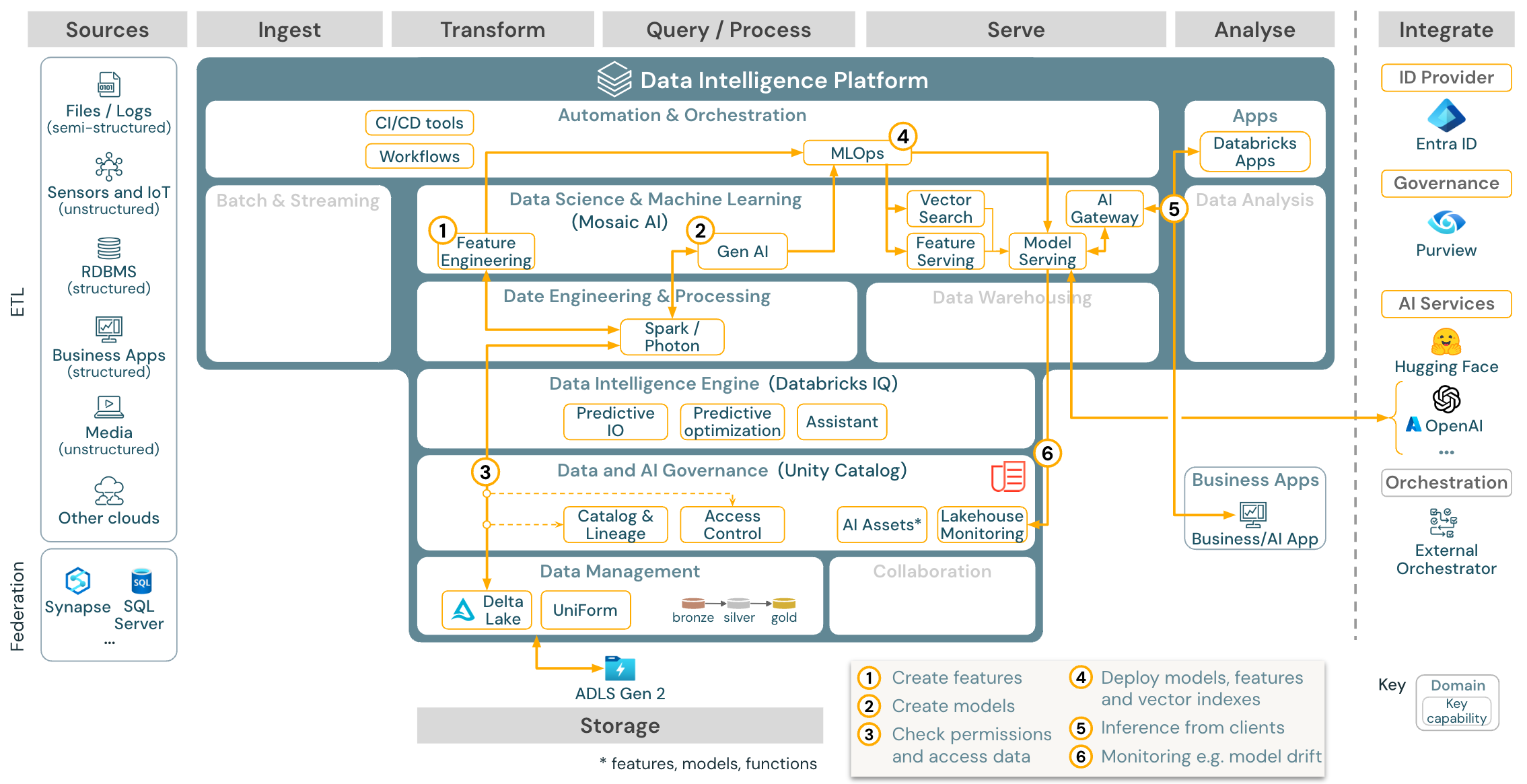
Download: Gen AI-Anwendungsreferenzarchitektur für Azure Databricks
Für generative KI-Anwendungsfälle bietet Mosaic AI modernste Bibliotheken und spezifische Gen-KI-Fähigkeiten von Prompt-Engineering bis hin zur Feinabstimmung bestehender Modelle und Vortraining von Grund auf. Die obige Architektur zeigt ein Beispiel dafür, wie die Vektorsuche integriert werden kann, um eine genetische KI-Anwendung mithilfe von RAG (abruf-erweiterte Generierung) zu erstellen.
Verwenden Sie die MLOps-Funktionen zur Veröffentlichung der Modelle in Model Serving, um Modelle auf skalierbare und unternehmensgerechte Weise bereitzustellen.
Anwendungsfall: BI- und SQL-Analysen
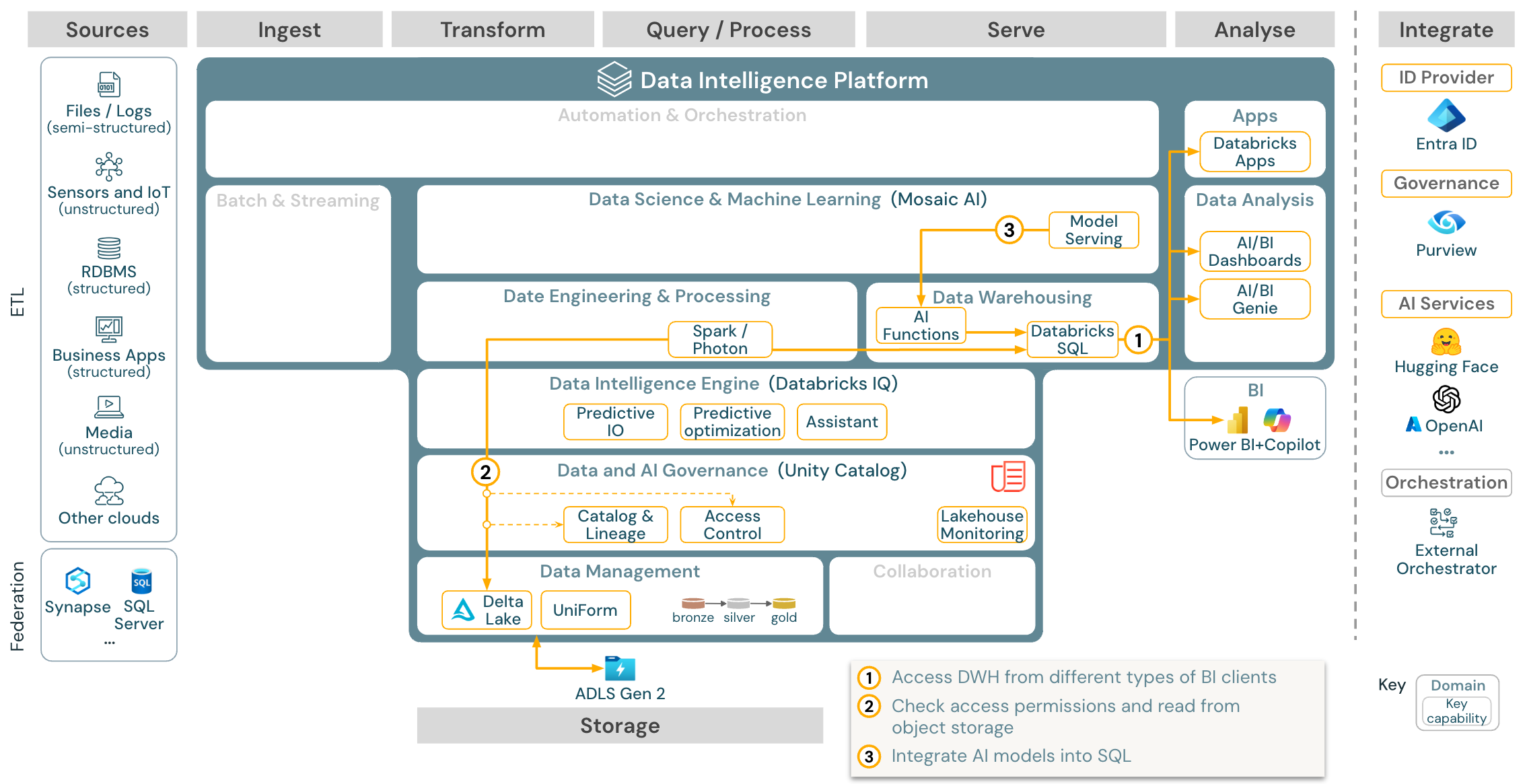
Download: BI- und SQL-Analysereferenzarchitektur für Azure Databricks
Für BI-Anwendungsfälle können Business Analysts Dashboards, den Databricks SQL-Editor oder spezielle BI-Tools wie Tableau oder Power BI verwenden. In allen Fällen handelt es sich beim Modul um Databricks SQL (serverlos oder mit Server) und die Datenermittlung, Erkundung und Zugriffssteuerung wird von Unity Catalog bereitgestellt.
Anwendungsfall: Lakehouse-Verbund
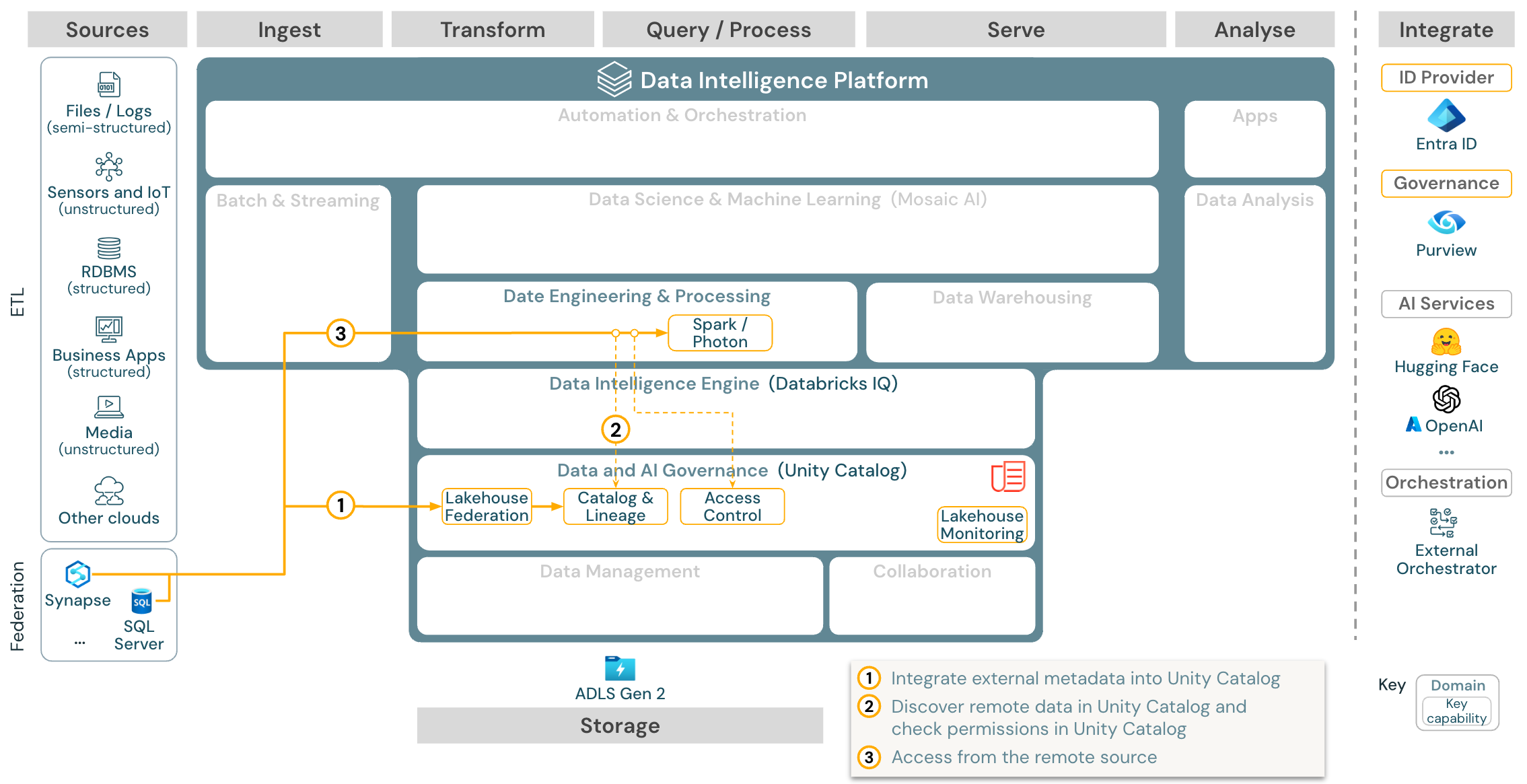
Download: Referenzarchitektur für Lakehouse-Verbund für Azure Databricks
Der Lakehouse-Verbund ermöglicht die Integration externer SQL-Datenbanken (z. B. MySQL, Postgres, SQL Server oder Azure Synapse) in Databricks.
Alle Workloads (KI, DWH und BI) können davon profitieren, ohne dass die Daten zuerst per ETL in den Objektspeicher geladen werden müssen. Der externe Quellkatalog wird Unity Catalog zugeordnet, und der Zugriff über die Databricks-Plattform kann differenziert gesteuert werden.
Anwendungsfall: Gemeinsame Nutzung von Unternehmensdaten
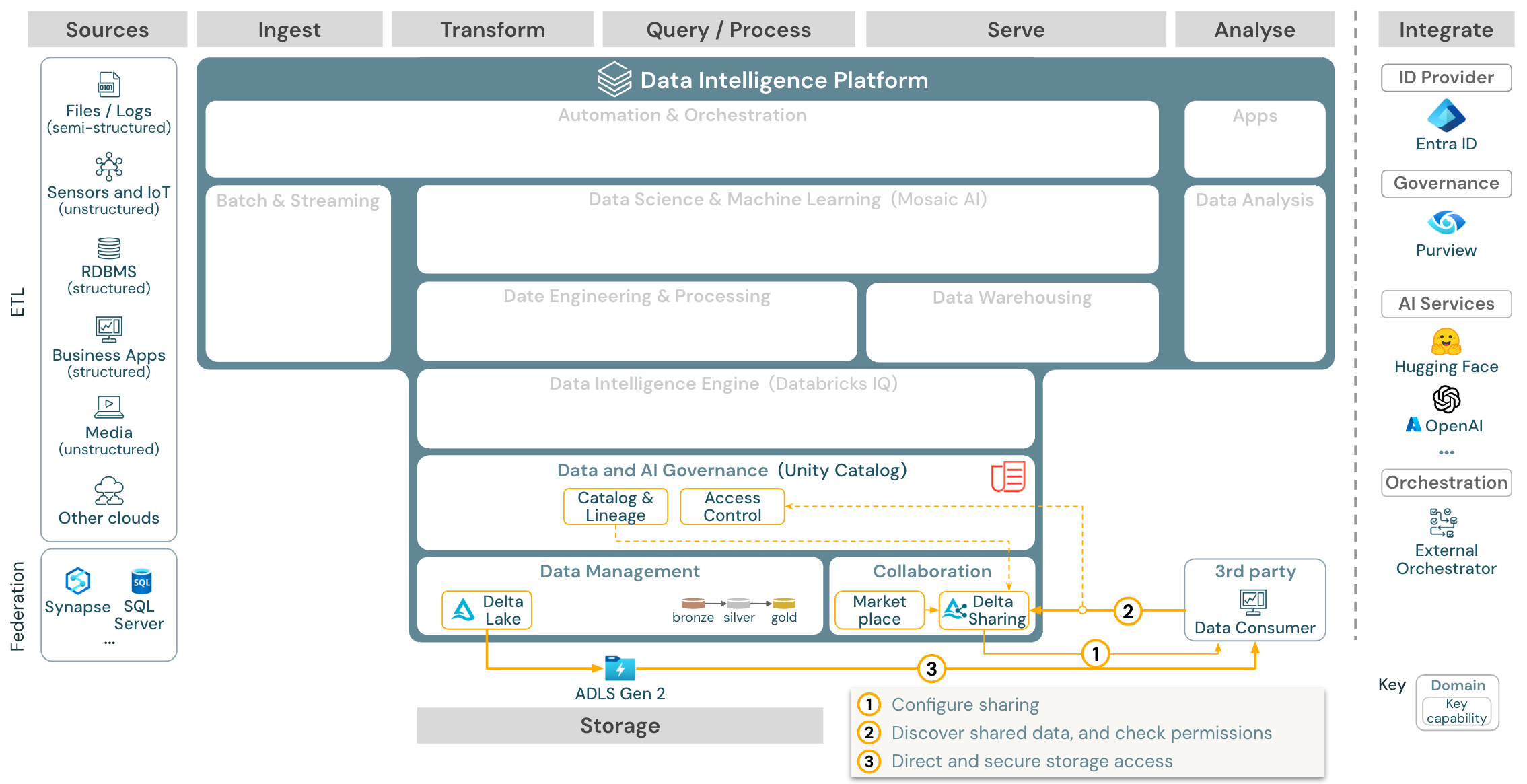
Download: Referenzarchitektur für die gemeinsame Nutzung von Unternehmensdaten für Azure Databricks
Die gemeinsame Nutzung von Daten auf Unternehmensniveau wird von Delta Sharing bereitgestellt. Es bietet direkten Zugriff auf Daten im Objektspeicher, der durch Unity Catalog gesichert ist, und Databricks Marketplace ist ein offenes Forum für den Austausch von Datenprodukten.