Leitprinzipien für das Lakehouse
Leitprinzipien sind Regeln der Ebene Null, die Ihre Architektur definieren und beeinflussen. Zum Erstellen eines Data Lakehouse, das Ihrem Unternehmen jetzt und in Zukunft zum Erfolg verhilft, ist ein Konsens zwischen den Beteiligten in Ihrem Unternehmen entscheidend.
Kuratieren von Daten und Anbieten vertrauenswürdiger Daten als Produkte
Die Kuratierung von Daten ist entscheidend für das Erstellen eines hochwertigen Data Lake für BI und ML/KI. Behandeln Sie Daten wie ein Produkt mit einer klaren Definition, einem Schema und einem Lebenszyklus. Stellen Sie die semantische Konsistenz sicher, und dass sich die Datenqualität von Ebene zu Schicht verbessert, damit Geschäftsanwender den Daten vollständig vertrauen können.
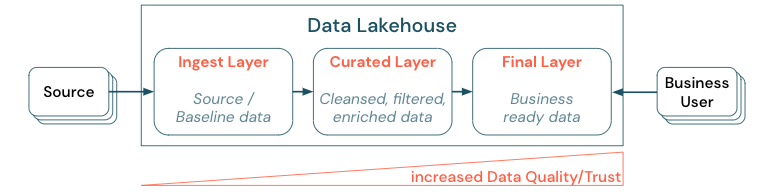
Die Kuratierung von Daten durch die Erstellung einer Architektur mit mehreren Ebenen (oder Multi-Hop-Architektur) ist eine wichtige bewährte Methode für das Lakehouse, da sie es Datenteams ermöglicht, die Daten nach Qualitätsebenen zu strukturieren und Rollen und Verantwortlichkeiten pro Ebene zu definieren. Ein gängiger Ansatz für Ebenen ist:
- Erfassungsebene: Quelldaten werden im Lakehouse auf der ersten Ebene erfasst und sollten dort beibehalten werden. Wenn alle nachgelagerten Daten auf der Erfassungsebene erstellt werden, ist bei Bedarf eine Neuerstellung der nachfolgenden Ebenen aus dieser Ebene möglich.
- Ebene für kuratierte Daten: Der Zweck der zweiten Ebene besteht darin, bereinigte, verfeinerte, gefilterte und aggregierte Daten zu enthalten. Ziel dieser Ebene ist es, eine solide und zuverlässige Grundlage für Analysen und Berichte über alle Rollen und Funktionen hinweg bereitzustellen.
- Letzte Ebene: Die dritte Ebene wird für Geschäfts- oder Projektanforderungen erstellt. Sie bietet eine andere Ansicht als Datenprodukte für andere Geschäftseinheiten oder Projekte, bereitet Daten für Sicherheitsanforderungen (z. B. anonymisierte Daten) vor oder optimiert die Leistung (z. B. mit voraggregierten Ansichten). Die Datenprodukte auf dieser Ebene gelten als korrekte Version für das Unternehmen.
Pipelines auf allen Ebenen müssen sicherstellen, dass die Einschränkungen für die Datenqualität erfüllt werden, d. h. dass Daten jederzeit korrekt, vollständig, zugänglich und konsistent sind, auch während gleichzeitigen Lese- und Schreibvorgängen. Die Validierung neuer Daten erfolgt zum Zeitpunkt des Dateneintrags in die kuratierte Ebene, und die folgenden ETL-Schritte arbeiten an der Verbesserung der Qualität dieser Daten. Die Datenqualität muss sich verbessern, je weiter die Daten die Ebenen durchlaufen, sodass das Vertrauen in die Daten aus geschäftlicher Sicht zunimmt.
Entfernen von Datensilos und Minimieren der Datenverschiebung
Erstellen Sie keine Kopien eines Datasets mit Geschäftsprozessen, die auf diesen verschiedenen Kopien basieren. Kopien können zu Datensilos werden, die nicht mehr synchronisiert sind, was zu einer geringeren Qualität Ihres Data Lake und schließlich zu veralteten oder falschen Erkenntnissen führt. Verwenden Sie für die gemeinsame Nutzung von Daten mit externen Partnern einen Unternehmensfreigabemechanismus, der einen direkten und sicheren Zugriff auf die Daten ermöglicht.
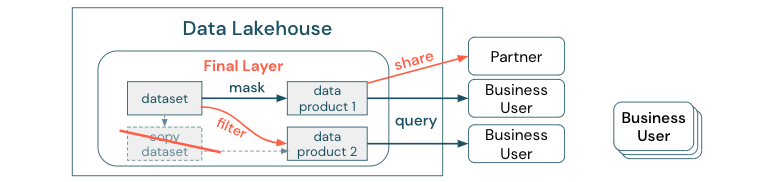
Um den Unterschied zwischen einer Datenkopie und einem Datensilo deutlich zu machen: Eine eigenständige Kopie oder Wegwerfkopie von Daten ist für sich genommen nicht schädlich. Sie ist manchmal sogar notwendig, um Flexibilität, Experimentieren und Innovation zu fördern. Wenn diese Kopien jedoch mit nachgelagerten, von ihnen abhängigen Geschäftsdatenprodukten in Betrieb genommen werden, werden sie zu Datensilos.
Um Datensilos zu vermeiden, versuchen Datenteams in der Regel, einen Mechanismus oder eine Datenpipeline zu erstellen, um alle Kopien mit dem Original synchron zu halten. Da dies wahrscheinlich nicht durchgängig möglich ist, verschlechtert sich die Datenqualität mit der Zeit. Dies kann auch zu höheren Kosten und einem erheblichen Vertrauensverlust bei den Benutzern führen. Andererseits ist es in vielen Geschäftsfällen erforderlich, Daten mit Partnern oder Lieferanten auszutauschen.
Ein wichtiger Aspekt ist die sichere und zuverlässige Freigabe der aktuellen Version des Datasets. Kopien des Datasets reichen oft nicht aus, da sie häufig schnell nicht mehr synchronisiert sind. Stattdessen sollten die Daten über Tools für die gemeinsame Nutzung von Unternehmensdaten freigegeben werden.
Demokratisierung der Wertschöpfung durch Selfservice
Der beste Data Lake kann keinen ausreichenden Nutzen bieten, wenn Benutzer nicht problemlos auf die Plattform oder Daten für ihre BI- und ML/KI-Aufgaben zugreifen können. Verringern Sie die Barrieren für den Zugriff auf Daten und Plattformen für alle Geschäftseinheiten. Erwägen Sie schlanke Datenverwaltungsprozesse, und bieten Sie Selfservicezugriff auf die Plattform und die zugrunde liegenden Daten.
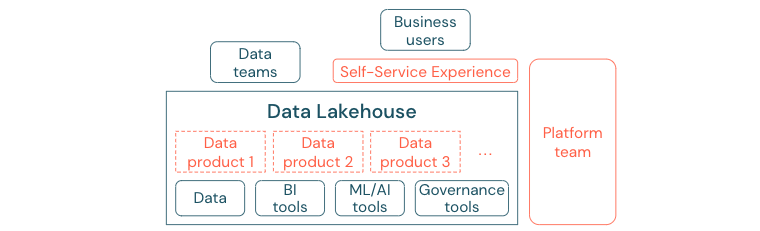
Unternehmen, die erfolgreich zu einer datengesteuerten Kultur übergegangen sind, werden florieren. Das bedeutet, dass jede Geschäftseinheit ihre Entscheidungen aus analytischen Modellen oder aus der Analyse eigener oder zentral bereitgestellter Daten ableitet. Für Verbraucher müssen Daten leicht auffindbar und sicher zugänglich sein.
Ein gutes Konzept für Datenproduzenten ist „Daten als Produkt“: Die Daten werden von einer Geschäftseinheit oder einem Geschäftspartner wie ein Produkt angeboten und gepflegt und von anderen Parteien mit entsprechender Berechtigungskontrolle genutzt. Anstatt sich auf ein zentrales Team und potenziell langsame Anforderungsprozesse zu verlassen, müssen diese Datenprodukte in einem Selfserviceverfahren erstellt, angeboten, entdeckt und genutzt werden.
Doch es geht nicht nur um die Daten. Die Demokratisierung von Daten erfordert die richtigen Tools, die es allen ermöglichen, die Daten zu erstellen oder zu nutzen und zu verstehen. Zu diesem Zweck muss das Data Lakehouse eine moderne Daten- und KI-Plattform sein, die die Infrastruktur und Tools für die Erstellung von Datenprodukten bereitstellt, ohne dass der Aufwand für die Einrichtung eines weiteren Toolstapels verdoppelt wird.
Einführung einer organisationsweiten Datengovernancestrategie
Daten sind für jedes Unternehmen von entscheidender Bedeutung, aber Sie können nicht allen Personen Zugang zu allen Daten ermöglichen. Der Datenzugriff muss aktiv verwaltet werden. Zugriffssteuerung, Überwachung und Nachverfolgung der Datenherkunft sind der Schlüssel für die korrekte und sichere Nutzung von Daten.
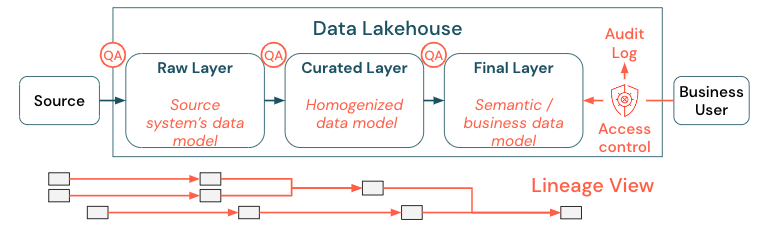
Datengovernance ist ein weites Feld. Das Lakehouse deckt die folgenden Dimensionen ab:
Datenqualität
Die wichtigste Voraussetzung für korrekte und aussagekräftige Berichte, Analyseergebnisse und Modelle sind qualitativ hochwertige Daten. Qualitätssicherung (Quality Assurance, QA) muss bei allen Pipelineschritten vorhanden sein. Beispiele für die Umsetzung sind Datenverträge, die Einhaltung von SLAs, die Stabilität von Schemata und deren kontrollierte Weiterentwicklung.
Datenkatalog
Ein weiterer wichtiger Aspekt ist die Datenermittlung: Benutzer aller Geschäftsbereiche müssen, insbesondere in einem Selfservicemodell, in der Lage sein, relevante Daten leicht zu finden. Daher benötigt ein Lakehouse einen Datenkatalog, der alle geschäftsrelevanten Daten abdeckt. Die Hauptziele eines Datenkatalogs sind folgende:
- Sicherstellen, dass das gleiche Geschäftskonzept im gesamten Unternehmen einheitlich aufgerufen und deklariert wird. Man könnte es als semantisches Modell in der kuratierten und der letzten Ebene betrachten.
- Genaue Verfolgung der Datenherkunft, damit Benutzer erklären können, wie diese Daten zu ihrer aktuellen Form gekommen sind.
- Pflege hochwertiger Metadaten, die für die ordnungsgemäße Nutzung der Daten ebenso wichtig sind wie die Daten selbst.
Zugriffssteuerung
Da die Wertschöpfung aus den Daten im Lakehouse in allen Geschäftsbereichen erfolgt, muss das Lakehouse so aufgebaut sein, dass die Sicherheit einen hohen Stellenwert hat. Unternehmen können eine offenere Datenzugriffsrichtlinie haben oder sich strikt an das Prinzip der geringsten Rechte halten. Unabhängig davon müssen auf jeder Ebene Datenzugriffssteuerungen vorhanden sein. Es ist wichtig, von Anfang an fein abgestufte Berechtigungsschemata zu implementieren (Zugriffssteuerung auf Spalten- und Zeilenebene, rollenbasierte oder attributbasierte Zugriffssteuerung). Unternehmen können mit weniger strengen Regeln beginnen. Aber wenn die Lakehouse-Plattform wächst, sollten alle Mechanismen und Prozesse für ein ausgefeilteres Sicherheitssystem bereits vorhanden sein. Außerdem muss jeder Zugriff auf die Daten im Lakehouse von Anfang an durch Überwachungsprotokolle geregelt werden.
Förderung offener Schnittstellen und offener Formate
Offene Schnittstellen und Datenformate sind entscheidend für die Interoperabilität zwischen dem Lakehouse und anderen Tools. Dies vereinfacht die Integration mit bestehenden Systemen und eröffnet zudem ein Ökosystem von Partnern, die ihre Tools in die Plattform integriert haben.
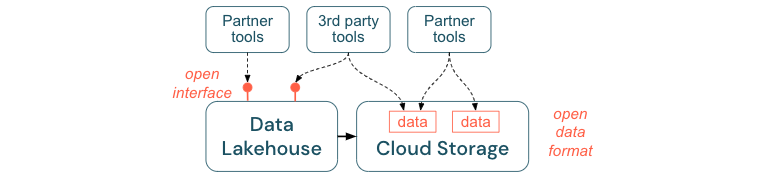
Offene Schnittstellen sind entscheidend, um Interoperabilität zu ermöglichen und die Abhängigkeit von einem einzigen Anbieter zu verhindern. In der Vergangenheit haben Anbieter proprietäre Technologien und geschlossene Schnittstellen entwickelt, die Unternehmen in der Art und Weise, wie sie Daten speichern, verarbeiten und gemeinsam nutzen können, eingeschränkt haben.
Die Verwendung offener Schnittstellen hilft Ihnen, für die Zukunft gerüstet zu sein:
- Sie erhöhen die Langlebigkeit und Übertragbarkeit der Daten, sodass Sie sie in mehr Anwendungen und für mehr Anwendungsfälle nutzen können.
- Sie eröffnen ein Ökosystem von Partnern, die die offenen Schnittstellen schnell nutzen können, um ihre Tools in die Lakehouse-Plattform zu integrieren.
Und schließlich werden durch die Standardisierung offener Datenformate die Gesamtkosten erheblich gesenkt; man kann direkt im Cloudspeicher auf die Daten zugreifen, ohne sie durch eine proprietäre Plattform leiten zu müssen, die hohe Kosten für ausgehende Daten sowie Berechnungen verursachen kann.
Skalierbarkeit und Optimierung für Leistung und Kosten
Daten wachsen unweigerlich weiter und werden immer komplexer. Um Ihre Organisation für zukünftige Anforderungen zu rüsten, sollte Ihr Lakehouse skalierbar sein. Zum Beispiel sollten Sie bei Bedarf problemlos neue Ressourcen hinzufügen können. Die Kosten sollten auf den tatsächlichen Verbrauch begrenzt sein.
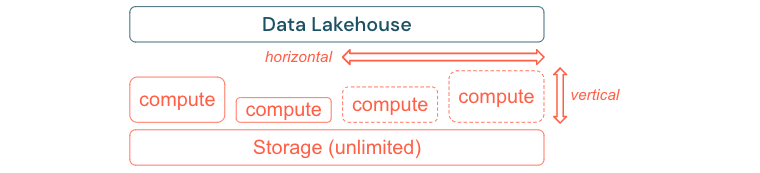
Standard-ETL-Prozesse, Geschäftsberichte und Dashboards haben oft einen vorhersehbaren Ressourcenbedarf in Bezug auf Speicher und Berechnungen. Neue Projekte, saisonabhängige Aufgaben oder moderne Ansätze wie Modelltraining (Churn, Prognose, Wartung) erzeugen jedoch Spitzen beim Ressourcenbedarf. Damit ein Unternehmen all diese Workloads bewältigen kann, ist eine skalierbare Plattform für Speicher und Berechnungen erforderlich. Neue Ressourcen müssen bei Bedarf problemlos hinzugefügt werden können, und nur der tatsächliche Verbrauch sollte Kosten verursachen. Sobald der Höchststand überschritten wurde, können Ressourcen wieder freigegeben und die Kosten entsprechend reduziert werden. Dies wird häufig als horizontale Skalierung (weniger oder mehr Knoten) und vertikale Skalierung (größere oder kleinere Knoten) bezeichnet.
Durch die Skalierung können Unternehmen auch die Leistung von Abfragen verbessern, indem Knoten mit mehr Ressourcen oder Clustern mit mehr Knoten ausgewählt werden. Anstatt jedoch permanent große Computer und Cluster bereitzustellen, können diese bei Bedarf nur für den Zeitraum bereitgestellt werden, der für die Optimierung des Gesamtverhältnisses zwischen Leistung und Kosten erforderlich ist. Ein weiterer Aspekt der Optimierung ist die Abwägung zwischen Speicher- und Rechenressourcen. Da es keine eindeutige Beziehung zwischen dem Datenvolumen und den Workloads gibt, die diese Daten nutzen (z. B. nur Teile der Daten nutzen oder intensive Berechnungen mit kleinen Daten durchführen), wird empfohlen, sich für eine Infrastrukturplattform zu entscheiden, die Speicher- und Computeressourcen entkoppelt.