RAG-Kette zum Rückschließen
In diesem Artikel wird der Prozess beschrieben, der ausgeführt wird, wenn der Benutzer eine Anforderung an die RAG-Anwendung in einer Onlineeinstellung übermittelt. Sobald die Daten von der Datenpipeline verarbeitet wurden, sind sie für die Verwendung in der RAG-Anwendung geeignet. Die Reihe oder Kette von Schritten, die zur Rückschlusszeit aufgerufen werden, wird häufig als die RAG-Kette bezeichnet.
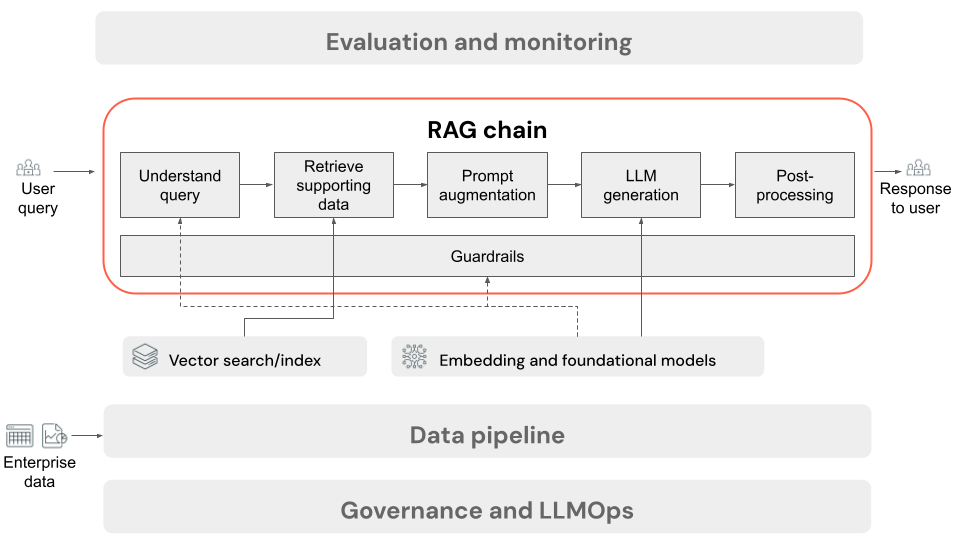
- (Optional) Vorverarbeitung von Benutzerabfragen: In einigen Fällen wird die Abfrage des Benutzers vorverarbeitet, damit sie besser für die Abfrage der Vektordatenbank geeignet ist. Dies kann das Formatieren der Abfrage in einer Vorlage, die Verwendung eines anderen Modells zum Umschreiben der Anforderung oder das Extrahieren von Schlüsselwörtern zur Unterstützung des Abrufs umfassen. Die Ausgabe dieses Schritts ist eine Abrufabfrage, die im nachfolgenden Abrufschritt verwendet wird.
- Abruf: Um unterstützende Informationen aus der Vektordatenbank abzurufen, wird die Abrufabfrage in eine Einbettung mit demselben Einbettungsmodell übersetzt, das zum Einbetten der Dokumentblöcke während der Datenaufbereitung verwendet wurde. Diese Einbettungen ermöglichen den Vergleich der semantischen Ähnlichkeit zwischen der Abrufabfrage und den Blöcken mit unstrukturiertem Text mithilfe von Measures wie Kosinusähnlichkeit. Als Nächstes werden Blöcke aus der Vektordatenbank abgerufen und basierend darauf geordnet, wie ähnlich sie der eingebetteten Anforderung sind. Die wichtigsten (ähnlichsten) Ergebnisse werden zurückgegeben.
- Prompt-Erweiterung: Der an das LLM gesendete Prompt wird durch die Erweiterung der Benutzerabfrage um den abgerufenen Kontext in einer Vorlage gebildet, die das Modell anweist, wie jede Komponente verwendet wird, häufig mit zusätzlichen Anweisungen zum Steuern des Antwortformats. Der Prozess zum Durchlaufen der richtigen Promptvorlage wird als Prompt Engineering bezeichnet.
- LLM-Generierung: Das LLM übernimmt den erweiterten Prompt, der die Abfrage des Benutzers und die abgerufenen unterstützenden Daten enthält, als Eingabe. Anschließend wird eine Antwort generiert, die auf dem zusätzlichen Kontext basiert.
- (Optional) Nachbearbeitung: Die Antwort des LLM kann verarbeitet werden, um zusätzliche Geschäftslogik anzuwenden, Zitate hinzuzufügen oder den generierten Text basierend auf vordefinierten Regeln oder Einschränkungen anderweitig zu verfeinern.
Wie bei der RAG-Anwendungsdatenpipeline gibt es viele daraus folgende Engineering-Entscheidungen, die sich auf die Qualität der RAG-Kette auswirken können. Wenn Sie z. B. bestimmen, wie viele Blöcke in Schritt 2 abgerufen werden sollen und wie sie mit der Abfrage des Benutzers in Schritt 3 kombiniert werden, kann sich dies erheblich auf die Fähigkeit des Modells zum Generieren von qualitativ hochwertigen Antworten auswirken.
In dieser Kette können verschiedene Schutzmechanismen angewendet werden, um die Einhaltung von Unternehmensrichtlinien sicherzustellen. Dies kann das Filtern nach geeigneten Anforderungen, das Überprüfen von Benutzerberechtigungen vor dem Zugriff auf Datenquellen und das Anwenden von Inhaltsmoderationstechniken auf die generierten Antworten umfassen.