Erstellen und Abfragen eines Vektorsuchindex
In diesem Artikel wird beschrieben, wie Sie einen Vektorsuchindex mithilfe Mosaik AI Vector Searcherstellen und abfragen.
Sie können Vektorsuchkomponenten wie einen Vektorsuchendpunkt und Vektorsuchindizes mithilfe der Benutzeroberfläche, des Python SDKoder der REST-APIerstellen und verwalten.
Anforderungen
- Arbeitsbereich mit Unity Catalog-Unterstützung.
- Serverloses Rechnen aktiviert Anleitungen finden Sie unter Verbinden mit serverlosem Computing.
- Die Quelltabelle muss „Datenfeed ändern“ aktiviert haben. Weitere Anleitungen finden Sie unter Verwenden des Delta Lake-Änderungs-Datenfeeds in Azure Databricks.
- Zum Erstellen eines Vektorsuchindex müssen Sie über CREATE TABLE Berechtigungen für das Katalogschema verfügen, in dem der Index erstellt wird.
- Um einen Index abzufragen, der einem anderen Benutzer gehört, müssen Sie über zusätzliche Berechtigungen verfügen. Weitere Informationen unter Abfrage eines Vektorsuchendpunkts.
Die Berechtigung zum Erstellen und Verwalten von Vektorsuchendpunkten wird mithilfe von Zugriffssteuerungslisten konfiguriert. Siehe Vektor-Suche-Endpunkt-ACLs.
Installation
Um das Vektorsuch-SDK zu verwenden, müssen Sie es in Ihrem Notizbuch installieren. Verwenden Sie den folgenden Code, um das Paket zu installieren:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Verwenden Sie dann den folgenden Befehl, um VectorSearchClientzu importieren:
from databricks.vector_search.client import VectorSearchClient
Authentifizierung
Siehe Datenschutz und Authentifizierung.
Einen Vektor-Suchendpunkt erstellen
Sie können einen Vektorsuchendpunkt mithilfe der Databricks-Benutzeroberfläche, des Python SDK oder der API erstellen.
Erstellen eines Vektorsuchendpunkts mithilfe der Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen Vektorsuchendpunkt mithilfe der Benutzeroberfläche zu erstellen.
Klicken Sie in der linken Seitenleiste auf Compute.
Klicken Sie auf die Registerkarte Vektorsuche und dann auf Erstellen.

Das Formular zum Erstellen von Endpunkten wird geöffnet. Geben Sie einen Namen für diesen Endpunkt ein.
Klicken Sie auf Bestätigen.
Erstellen eines Vektorsuchendpunkts mit dem Python SDK
Im folgenden Beispiel wird die create_endpoint() SDK-Funktion verwendet, um einen Vektorsuchendpunkt zu erstellen.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Erstellen eines Vektorsuchendpunkts mithilfe der REST-API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/endpoints.
(Optional) Erstellen und Konfigurieren eines Endpunkts für das Einbettungsmodell
Wenn die Einbettungen von Databricks berechnet werden sollen, können Sie einen vordefinierten Foundation Model-API-Endpunkt verwenden oder ein Modell erstellen, das den Einbettungsmodell Ihrer Wahl bedient. Anweisungen hierzu finden Sie unter Foundation Model-APIs mit tokenbasierter Bezahlung oder Erstellen von Foundation Model-Bereitstellungsendpunkten. Beispiele für Notebooks finden Sie unter Notebook-Beispiele zum Aufrufen eines Einbettungsmodells.
Wenn Sie einen Einbettungsendpunkt konfigurieren, empfiehlt Databricks, die Standardauswahl von Auf Null skalieren zu entfernen. Die Aufwärmphase von Bereitstellungsendpunkten kann einige Minuten dauern, und die anfängliche Abfrage eines Index mit einem herunterskalierten Endpunkt kann zu einem Timeout führen.
Hinweis
Die Initialisierung des Vektorsuchindex kann ein Timeout auslösen, wenn der Einbettungsendpunkt nicht richtig für das Dataset konfiguriert ist. Sie sollten nur CPU-Endpunkte für kleine Datasets und Tests verwenden. Verwenden Sie für größere Datasets einen GPU-Endpunkt, um eine optimale Leistung zu erzielen.
Erstellen eines Vektorsuchindex
Sie können einen Vektorsuchindex mithilfe der Benutzeroberfläche, des Python SDK oder der REST-API erstellen. Die Benutzeroberfläche ist der einfachste Ansatz.
Es gibt zwei Arten von Indizes:
- Der Delta-Synchronisierungsindex wird automatisch mit einer Delta-Tabelle synchronisiert und aktualisiert den Index inkrementell, während sich die zugrunde liegenden Daten in der Delta-Tabelle ändern.
- Direct Vector Access Index unterstützt das direkte Lesen und Schreiben von Vektoren und Metadaten. Der Benutzer ist für die Aktualisierung dieser Tabelle mit der REST-API oder dem Python SDK verantwortlich. Dieser Indextyp kann nicht mithilfe der Benutzeroberfläche erstellt werden. Sie müssen die REST-API oder das SDK verwenden.
Erstellen von Index mithilfe der Benutzeroberfläche
Klicken Sie in der linken Randleiste auf Katalog, um die Benutzeroberfläche des Katalog-Explorers zu öffnen.
Navigieren Sie zu der Delta-Tabelle, die Sie verwenden möchten.
Wählen Sie oben rechts die Schaltfläche Erstellen, und wählen Sie im Dropdownmenü den Vektorsuchindex aus.
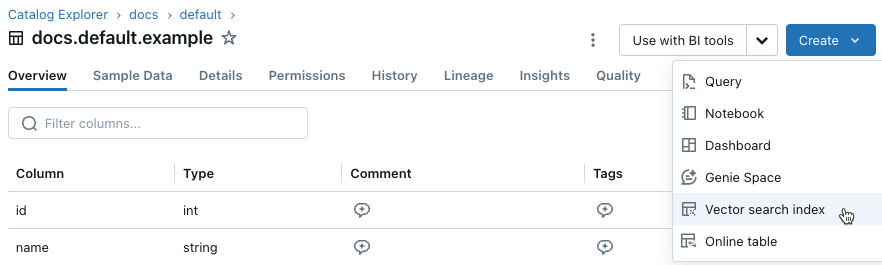
Verwenden Sie die Selektoren im Dialogfeld, um den Index zu konfigurieren.
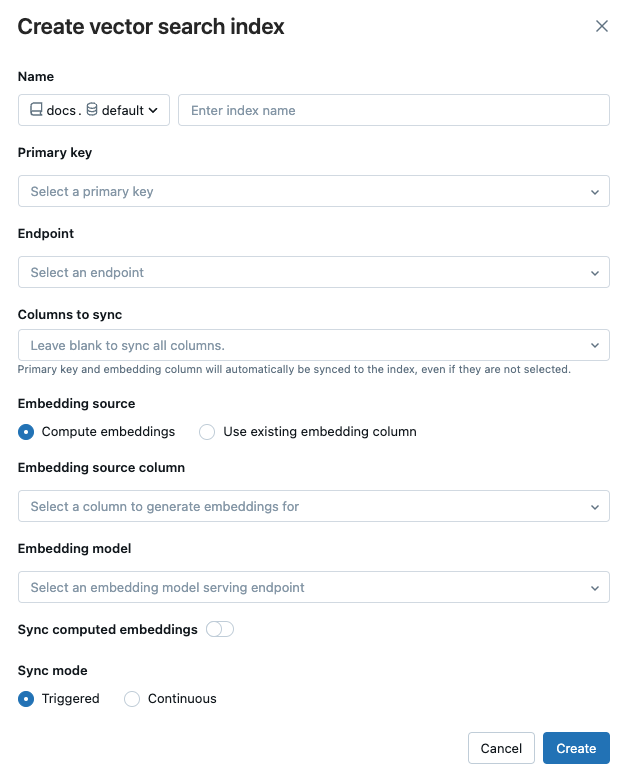
Name: Name, der für die Onlinetabelle im Unity-Katalog verwendet werden soll. Der Name erfordert einen Namespace mit drei Ebenen,
<catalog>.<schema>.<name>. Es sind nur alphanumerische Zeichen und Unterstriche zulässig.Primärschlüssel: Spalte, die als Primärschlüssel verwendet werden soll.
Endpoint: Wählen Sie den Vektorsuchendpunkt aus, den Sie verwenden möchten.
Zu synchronisierende Spalten: Wählen Sie die Spalten aus, die mit dem Vektorindex synchronisiert werden sollen. Wenn Sie dieses Feld leer lassen, werden alle Spalten aus der Quelltabelle mit dem Index synchronisiert. Die Primärschlüsselspalte und die Einbettungsquellenspalte oder Einbettungsvektorspalte werden immer synchronisiert.
Einbettungsquelle: Geben Sie an, ob Databricks Einbettungen für eine Textspalte in der Delta-Tabelle berechnen sollen (Compute Embeddings), oder wenn Ihre Delta-Tabelle vorkompilierte Einbettungen enthält (Vorhandene Einbettungsspalteverwenden ).
- Wenn Sie Compute embeddingsausgewählt haben, wählen Sie die Spalte aus, für die Sie Einbettungen berechnen möchten, und den Endpunkt, der das Einbettungsmodell bedient. Nur Textspalten werden unterstützt.
- Wenn Sie Vorhandene Einbettungsspalte verwenden ausgewählt haben, wählen Sie die Spalte aus, welche die vorkompilierten Einbettungen und die Dimension für das Einbetten enthält. Das Format der vorkompilierten Einbettungsspalte sollte
array[float]sein.
Synchronisierung berechneter Einbettungen: Aktivieren Sie diese Einstellung, um die generierten Einbettungen in einer Unity-Katalogtabelle zu speichern. Weitere Informationen finden Sie unter Speichern generierter Einbettungstabelle.
Synchronisierungsmodus: Fortlaufend hält den Index mit wenigen Sekunden Latenz synchronisiert. Es ist jedoch mit höheren Kosten verbunden, da ein Rechencluster bereitgestellt wird, um die fortlaufende Stream-Synchronisierungspipeline auszuführen. Sowohl bei Fortlaufend als auch bei Ausgelöst ist das Update inkrementell: Es werden nur Daten verarbeitet, die seit der letzten Synchronisierung geändert wurden.
Im -Trigger--Synchronisierungsmodus verwenden Sie das Python SDK oder die REST-API, um die Synchronisierung zu starten. Siehe Delta-Synchronisierungsindex aktualisieren.
Wenn Sie die Konfiguration des Index abgeschlossen haben, klicken Sie auf Erstellen.
Erstellen eines Indexes mit dem Python SDK
Im folgenden Beispiel wird ein Delta-Synchronisierungsindex mit von Databricks berechneten Einbettungen erstellt.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
Im folgenden Beispiel wird ein Delta-Synchronisierungsindex mit selbstverwalteten Einbettungen erstellt. In diesem Beispiel wird auch die Verwendung des optionalen Parameters columns_to_sync gezeigt, um nur eine Teilmenge von Spalten auszuwählen, die im Index verwendet werden sollen.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Standardmäßig werden alle Spalten aus der Quelltabelle mit dem Index synchronisiert. Verwenden Sie columns_to_sync, um nur eine Teilmenge von Spalten zu synchronisieren. Der Primärschlüssel und die Einbettungsspalten sind immer im Index enthalten.
Um nur den Primärschlüssel und die Einbettungsspalte zu synchronisieren, müssen Sie diese in columns_to_sync wie im Beispiel gezeigt angeben.
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Um zusätzliche Spalten zu synchronisieren, geben Sie sie wie dargestellt an. Sie müssen den Primärschlüssel und die Einbettungsspalte nicht einschließen, da sie immer synchronisiert werden.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Im folgenden Beispiel wird ein Direct Vector Access Index erstellt.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Erstellen eines Indexes mithilfe der REST-API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/indexes.
Generierte Einbettungstabelle speichern
Wenn Databricks die Einbettungen generiert, können Sie die generierten Einbettungen in einer Tabelle im Unity-Katalog speichern. Diese Tabelle wird im gleichen Schema wie der Vektorindex erstellt und von der Vektorindexseite verknüpft.
Der Name der Tabelle ist der Name des Vektorsuchindex, angefügt von _writeback_table. Der Name kann nicht bearbeitet werden.
Sie können auf die Tabelle wie jede andere Tabelle im Unity-Katalog zugreifen und diese abfragen. Sie sollten die Tabelle jedoch nicht ablegen oder ändern, da sie nicht manuell aktualisiert werden soll. Die Tabelle wird automatisch gelöscht, wenn der Index gelöscht wird.
Aktualisieren eines Vektorsuchindex
Aktualisieren eines Delta-Synchronisierungsindex
Indizes, die mit fortlaufenden Synchronisierungsmodus erstellt wurden, werden automatisch aktualisiert, wenn sich die Delta-Quelltabelle ändert. Wenn Sie den ausgelösten Synchronisierungsmodus verwenden, verwenden Sie das Python SDK oder die REST-API, um die Synchronisierung zu starten.
Python SDK
index.sync()
REST-API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Aktualisieren eines Direct Vector Access Index
Sie können das Python SDK oder die REST-API verwenden, um Daten aus einem Direct Vector Access-Index einzufügen, zu aktualisieren oder zu löschen.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST-API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/indexes.
Für Produktionsanwendungen empfiehlt Databricks die Verwendung von Dienstprinzipalen anstelle von persönlichen Zugriffstoken. Die Leistung kann durch bis zu 100 msec pro Abfrage verbessert werden.
Im folgenden Codebeispiel wird veranschaulicht, wie ein Index mithilfe eines Dienstprinzipals aktualisiert wird.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Im folgenden Codebeispiel wird veranschaulicht, wie ein Index mithilfe eines persönlichen Zugriffstokens (PERSONAL Access Token, PAT) aktualisiert wird.
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Abfrage eines Vektor-Search-Endpoints
Sie können den Vektorsuchendpunkt nur mithilfe des Python SDK, der REST-API oder der SQL-vector_search() AI-Funktion abfragen.
Hinweis
Wenn der Benutzer, der den Endpunkt abfragt, nicht der Besitzer des Vektorsuchindex ist, muss der Benutzer über die folgenden UC-Berechtigungen verfügen:
- USE CATALOG im Katalog, der den Vektorsuchindex enthält.
- USE SCHEMA für das Schema, das den Vektorsuchindex enthält.
- SELECT im Vektorsuchindex.
Legen Sie den Parameter query_type auf hybridfest, um eine Hybrid-Schlüsselwort-Ähnlichkeitssuche auszuführen. Der Standardwert ist ann (ungefährer Nachbar).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST-API
Weitere Informationen finden Sie in der REST-API-Referenzdokumentation: POST /api/2.0/vector-search/indexes/{index_name}/query.
Für Produktionsanwendungen empfiehlt Databricks die Verwendung von Dienstprinzipalen anstelle von persönlichen Zugriffstoken. Zusätzlich zur verbesserten Sicherheits- und Zugriffsverwaltung kann die Verwendung von Dienstprinzipalen die Leistung um bis zu 100 msec pro Abfrage verbessern.
Das folgende Codebeispiel veranschaulicht, wie ein Index mithilfe eines Serviceprinzips abgefragt wird.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
Im folgenden Codebeispiel wird veranschaulicht, wie sie einen Index mithilfe eines persönlichen Zugriffstokens (PERSONAL Access Token, PAT) abfragen.
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Wichtig
Die KI-Funktion vector_search() befindet sich in der öffentlichen Vorschau.
Informationen zur Verwendung dieser KI-Funktionfinden Sie unter vector_search-Funktion.
Verwenden von Filtern für Abfragen
Eine Abfrage kann Filter basierend auf einer beliebigen Spalte in der Delta-Tabelle definieren. similarity_search gibt nur Zeilen zurück, die den angegebenen Filtern entsprechen. Die folgenden Filter werden unterstützt:
| Filteroperator | Verhalten | Beispiele |
|---|---|---|
NOT |
Hebt den Filter ab. Der Schlüssel muss mit "NOT" enden. Beispielsweise stimmt "color NOT" mit dem Wert "red" mit Dokumenten überein, bei denen die Farbe nicht rot ist. | {"id NOT": 2}{“color NOT”: “red”} |
< |
Überprüft, ob der Feldwert kleiner als der Filterwert ist. Der Schlüssel muss mit " <" enden. Beispielsweise entspricht "Price <" mit dem Wert 200 Dokumenten, bei denen der Preis kleiner als 200 ist. | {"id <": 200} |
<= |
Überprüft, ob der Feldwert kleiner oder gleich dem Filterwert ist. Der Schlüssel muss mit " <=" enden. Beispielsweise entspricht "Price <=" mit dem Wert 200 Dokumenten, bei denen der Preis kleiner oder gleich 200 ist. | {"id <=": 200} |
> |
Überprüft, ob der Feldwert größer als der Filterwert ist. Der Schlüssel muss mit " >" enden. Beispielsweise entspricht "Preis >" mit dem Wert 200 Dokumenten, bei denen der Preis größer als 200 ist. | {"id >": 200} |
>= |
Überprüft, ob der Feldwert größer oder gleich dem Filterwert ist. Der Schlüssel muss mit " >=" enden. Beispielsweise stimmt "Price >=" mit dem Wert 200 mit Dokumenten überein, bei denen der Preis größer oder gleich 200 ist. | {"id >=": 200} |
OR |
Überprüft, ob der Feldwert mit einem der Filterwerte übereinstimmt. Der Schlüssel muss OR enthalten, um mehrere Unterschlüssel zu trennen. Beispielsweise entspricht color1 OR color2 mit wert ["red", "blue"] Dokumenten, bei denen entweder color1red oder color2blueist. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Gleicht leerzeichengetrennte Token in einer Zeichenfolge ab. Sehen Sie sich die folgenden Codebeispiele an. | {"column LIKE": "hello"} |
| Kein Filteroperator angegeben | Der Filter überprüft auf eine genaue Übereinstimmung. Wenn mehrere Werte angegeben werden, stimmt sie mit einem der Werte überein. | {"id": 200}{"id": [200, 300]} |
Sehen Sie sich die folgenden Codebeispiele an:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST-API
Weitere Informationen unter POST /api/2.0/vector-search/indexes/{index_name}/query.
Gefällt mir
LIKE Beispiele
{"column LIKE": "apple"}: entspricht den Zeichenfolgen „apple” und „apple pear”, aber nicht „pineapple” oder „pear”. Beachten Sie, dass es nicht „pineapple” entspricht, obwohl es die Teilzeichenfolge „apple” enthält – es sucht nach einer exakten Übereinstimmung über leerzeichengetrennte Token wie in „apple pear” hinweg.
{"column NOT LIKE": "apple"} tut das Gegenteil. Sie entspricht „pineapple” und „pear”, aber nicht „apple” oder „apple pear”.
Beispiel-Notizbücher
Die Beispiele in diesem Abschnitt veranschaulichen die Verwendung des Python SDK für die Vektorsuche.
LangChain-Beispiele
Weitere Informationen zur Verwendung der Mosaic AI-Vektorsuche wie in der Integration in LangChain-Pakete finden Sie unter Verwenden von LangChain mit der Mosaic AI-Vektorsuche.
Das folgende Notizbuch zeigt, wie Sie Ihre Ähnlichkeitssuchergebnisse in LangChain-Dokumente konvertieren.
Vektorsuche mit dem Python SDK-Notizbuch
Notizbuchbeispiele zum Aufrufen eines Einbettungsmodells
Die folgenden Notizbücher veranschaulichen, wie Sie einen Mosaik AI Model Serving-Endpunkt für die Generierung von Einbettungen konfigurieren.