CI/CD mit Jenkins in Azure Databricks
Hinweis
Dieser Artikel befasst sich mit Jenkins, einer Drittanbieterplattform. Informationen zum Kontaktieren des Anbieters finden Sie in der Jenkins-Hilfe.
Es gibt zahlreiche CI/CD-Tools, mit denen Sie Ihre CI/CD-Pipelines verwalten und ausführen können. In diesem Artikel wird die Verwendung des Jenkins-Automatisierungsservers veranschaulicht. CI/CD ist ein Entwurfsmuster, sodass die in diesem Artikel beschriebenen Schritte und Phasen mit einigen Änderungen an der Definitionssprache der Pipeline in jedem Tool übertragen werden sollten. Darüber hinaus wird in einem großen Teil des Codes in dieser Beispielpipeline Python-Standardcode ausgeführt, den Sie in anderen Tools aufrufen können. Eine Übersicht über CI/CD in Azure Databricks finden Sie unter Was ist CI/CD in Azure Databricks?.
Wenn Sie stattdessen Azure DevOps mit Azure Databricks verwenden möchten, finden Sie weitere Informationen unter Kontinuierliche Integration und Bereitstellung auf Azure Databricks mit Azure DevOps.
CI/CD-Entwicklungsworkflow
Databricks schlägt den folgenden Workflow für die CI/CD-Entwicklung mit Jenkins vor:
- Erstellen Sie ein Repository, oder verwenden Sie ein vorhandenes Repository mit Ihrem Git-Drittanbieter.
- Verbinden Sie Ihren lokalen Entwicklungscomputer mit demselben Drittanbieter-Repository. Anweisungen finden Sie in der Git-Dokumentation des Drittanbieters.
- Ziehen Sie alle vorhandenen aktualisierten Artefakte (z. B. Notebooks, Codedateien und Buildskripts) aus dem Drittanbieter-Repository auf Ihren lokalen Entwicklungscomputer herunter.
- Erstellen, aktualisieren und testen Sie Artefakte auf Ihrem lokalen Entwicklungscomputer. Pushen Sie dann alle neuen und geänderten Artefakte von Ihrem lokalen Entwicklungscomputer in das Drittanbieter-Repository. Anweisungen finden Sie in der Git-Dokumentation des Drittanbieters.
- Wiederholen Sie die Schritte 3 und 4 nach Bedarf.
- Verwenden Sie Jenkins regelmäßig als integrierten Ansatz, um Artefakte aus Ihrem Drittanbieter-Repository automatisch auf Ihren lokalen Entwicklungscomputer oder Azure Databricks-Arbeitsbereich zu ziehen, um Code auf Ihrem lokalen Entwicklungscomputer oder Azure Databricks-Arbeitsbereich zu erstellen, zu testen und auszuführen, und Berichte zu Test- und Ausführungsergebnissen zu erstellen. Während Sie Jenkins manuell ausführen können, würden Sie in realen Implementierungen Ihren Git-Drittanbieter anweisen, Jenkins jedes Mal auszuführen, wenn ein bestimmtes Ereignis auftritt, z. B. eine Repository-Pullanforderung.
Der Rest dieses Artikels verwendet ein Beispielprojekt, um eine Möglichkeit zu beschreiben, Jenkins zum Implementieren des vorherigen CI/CD-Entwicklungsworkflows zu verwenden.
Informationen zur Verwendung von Azure DevOps anstelle von Jenkins finden Sie unter Continuous Integration und Continuous Delivery in Azure Databricks mithilfe von Azure DevOps.
Einrichtung des lokalen Entwicklungscomputers
In diesem Artikelbeispiel wird Jenkins verwendet, um die Databricks CLI und Databricks-Ressourcenpakete anzuweisen, Folgendes ausführen:
- Erstellen Sie eine Python-Wheel-Datei auf Ihrem lokalen Entwicklungscomputer.
- Stellen Sie die erstellte Python-Wheel-Datei zusammen mit zusätzlichen Python-Dateien und Python-Notebooks von Ihrem lokalen Entwicklungscomputer in einem Azure Databricks-Arbeitsbereich bereit.
- Testen Sie die hochgeladene Python-Wheel-Datei und die Notebooks in diesem Arbeitsbereich, und führen Sie sie aus.
Wenn Sie Ihren lokalen Entwicklungscomputer so einrichten möchten, dass Ihr Azure Databricks-Arbeitsbereich die Erstellungs- und Uploadphasen für dieses Beispiel ausführt, gehen Sie auf Ihrem lokalen Entwicklungscomputer wie folgt vor:
Schritt1: Installieren der erforderlichen Tools
In diesem Schritt installieren Sie die Databricks-CLI, Jenkins, jq und Python-Wheel-Buildtools auf Ihrem lokalen Entwicklungscomputer. Diese Tools sind erforderlich, um dieses Beispiel auszuführen.
Installieren Sie die Databricks-CLI, Version 0.205 oder höher, sofern noch nicht geschehen. Jenkins verwendet die Databricks-CLI, um diesen Beispieltest zu bestehen und Anweisungen an Ihren Arbeitsbereich auszuführen. Weitere Informationen finden Sie unter Installieren oder Aktualisieren der Databricks CLI.
Installieren und starten Sie Jenkins, wenn Sie dies noch nicht getan haben. Siehe Installieren von Jenkins für Linux, macOS oder Windows.
Installieren Sie jq. In diesem Beispiel wird
jqverwendet, um einige JSON-formatierte Befehlsausgabe zu analysieren.Verwenden Sie
pip, um die Python-Wheel-Buildtools mit dem folgenden Befehl zu installieren (einige Systeme erfordern möglicherweise, dass Siepip3anstelle vonpipverwenden):pip install --upgrade wheel
Schritt 2: Erstellen einer Jenkins-Pipeline
In diesem Schritt verwenden Sie Jenkins, um eine Jenkins-Pipeline für das Beispiel in diesem Artikel zu erstellen. Jenkins bietet einige verschiedene Projekttypen zum Erstellen von CI/CD-Pipelines. Jenkins-Pipelines bieten eine Schnittstelle zum Definieren von Phasen in einer Jenkins-Pipeline, indem Groovy-Code zum Aufrufen und Konfigurieren von Jenkins-Plug-Ins verwendet wird.
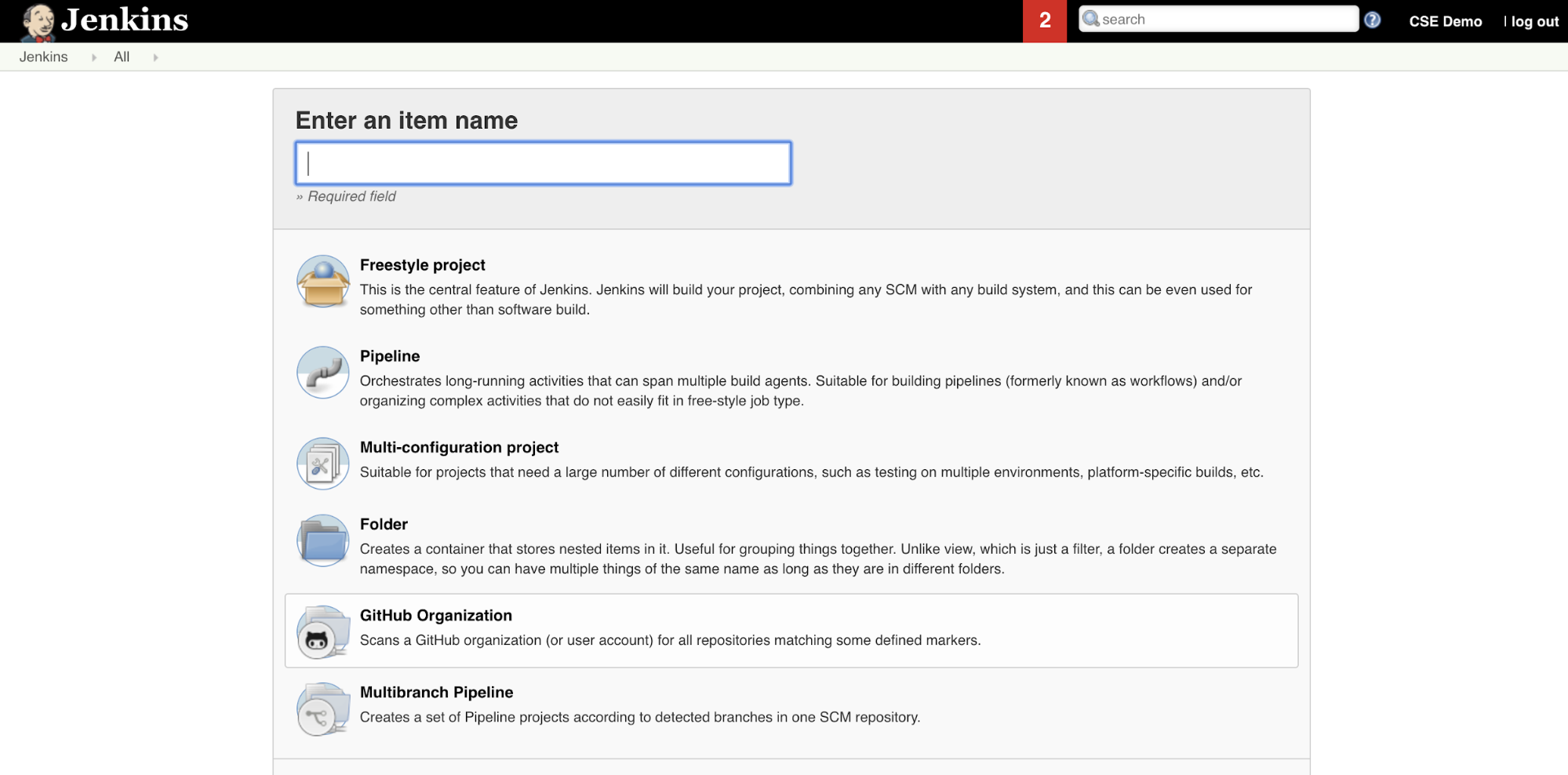
So erstellen Sie die Jenkins-Pipeline in Jenkins:
- Nachdem Sie Jenkins gestartet haben, klicken Sie in Ihrem Jenkins Dashboard auf Neues Element.
- Geben Sie in Elementname eingeben einen Namen für die Jenkins-Pipeline ein, z. B.
jenkins-demo. - Klicken Sie auf das Projekttypsymbol Pipeline.
- Klicken Sie auf OK. Die Seite Konfigurieren für die Jenkins-Pipeline wird angezeigt.
- Wählen Sie im Bereich Pipeline in der Dropdownliste Definition die Option Pipeline script from SCM (Pipeline-Skript von SCM) aus.
- Wählen Sie in der Dropdownliste SCM die Option Git aus.
- Geben Sie für Repository-URL die URL zu dem Repository ein, das von Ihrem Git-Drittanbieter gehostet wird.
- Geben Sie unter Branch Specifier (Branchspezifizierer)
*/<branch-name>ein, wobei<branch-name>der Name der Verzweigung in Ihrem Repository ist, die Sie verwenden möchten, z. B.*/main. - Geben Sie für Skriptpfad
Jenkinsfileein, falls er noch nicht festgelegt ist. Sie erstellen dieJenkinsfileweiter unten in diesem Artikel. - Deaktivieren Sie das Kontrollkästchen mit dem Titel einfaches Auschecken, falls es bereits aktiviert ist.
- Klicken Sie auf Speichern.
Schritt 3: Hinzufügen globaler Umgebungsvariablen zu Jenkins
In diesem Schritt fügen Sie drei globale Umgebungsvariablen zu Jenkins hinzu. Jenkins übergibt diese Umgebungsvariablen an die Databricks-CLI. Die Databricks-CLI benötigt die Werte für diese Umgebungsvariablen für die Authentifizierung bei Ihrem Azure Databricks-Arbeitsbereich. In diesem Beispiel wird die OAuth Machine-to-Machine (M2M)-Authentifizierung für einen Dienstprinzipal verwendet (obwohl auch andere Authentifizierungstypen verfügbar sind). Informationen zum Einrichten der OAuth M2M-Authentifizierung für Ihren Azure Databricks-Arbeitsbereich finden Sie unter Autorisieren des unbeaufsichtigten Zugriffs auf Azure Databricks-Ressourcen mit einem Dienstprinzipal mithilfe von OAuth.
Die drei globalen Umgebungsvariablen für dieses Beispiel sind:
DATABRICKS_HOSTlegen Sie auf ihre Azure Databricks-Arbeitsbereichs-URL fest, beginnend mithttps://. Siehe Arbeitsbereichsnamen, URLs und IDs.DATABRICKS_CLIENT_IDauf die Client-ID des Microsoft Entra ID-Dienstprinzipals festgelegt, die auch als Anwendungs-ID bezeichnet wird.DATABRICKS_CLIENT_SECRETauf das Azure Databricks OAuth-Geheimnis des Dienstprinzipals festgelegt.
So legen Sie globale Umgebungsvariablen auf Jenkins über Ihr Jenkins-Dashboard fest:
- Klicken Sie in der Seitenleiste auf Jenkins verwalten.
- Klicken Sie im Abschnitt Systemkonfiguration auf System.
- Aktivieren Sie im Abschnitt Globale Eigenschaften das Kontrollkästchen für Umgebungsvariablen.
- Klicken Sie auf Hinzufügen und geben Sie dann Name und Wert der Umgebungsvariable ein. Wiederholen Sie dies für jede weitere Umgebungsvariable.
- Wenn Sie alle Umgebungsvariablen hinzugefügt haben, klicken Sie auf Speichern, um zu Ihrem Jenkins-Dashboard zurückzukehren.
Benennen der Jenkins-Pipeline
Jenkins bietet einige verschiedene Projekttypen zum Erstellen von CI/CD-Pipelines. In diesem Beispiel wird eine Jenkins-Pipeline implementiert. Jenkins-Pipelines bieten eine Schnittstelle zum Definieren von Phasen in einer Jenkins-Pipeline, indem Groovy-Code zum Aufrufen und Konfigurieren von Jenkins-Plug-Ins verwendet wird.
Sie schreiben eine Jenkins-Pipelinedefinition in eine Textdatei namens Jenkinsfile, die wiederum in das Quellcodeverwaltungs-Repository eines Projekts eingecheckt wird. Weitere Informationen finden Sie unter Jenkins-Pipeline. Dies ist die Jenkins-Pipeline für das Beispiel in diesem Artikel. Ersetzen Sie in dieser Jenkinsfile-Beispieldatei die folgenden Platzhalter:
- Ersetzen Sie
<user-name>und<repo-name>durch den Benutzernamen und Repositorynamen für Ihren von Ihrem Drittanbieter gehosteten Git-Anbieter. In diesem Artikel wird eine GitHub-URL als Beispiel verwendet. - Ersetzen Sie
<release-branch-name>durch den Namen des Releasebranchs in Ihrem Repository. Das kann beispielsweisemainsein. - Ersetzen Sie
<databricks-cli-installation-path>durch den Pfad auf Ihrem lokalen Entwicklungscomputer, auf dem die Databricks CLI installiert ist. Unter macOS kann dies beispielsweise/usr/local/binsein. - Ersetzen Sie
<jq-installation-path>durch den Pfad auf Ihrem lokalen Entwicklungscomputer, auf demjqinstalliert ist. Unter macOS kann dies beispielsweise/usr/local/binsein. - Ersetzen Sie
<job-prefix-name>durch eine Zeichenfolge, um die Azure Databricks-Aufträge eindeutig zu identifizieren, die in Ihrem Arbeitsbereich für dieses Beispiel erstellt werden. Das kann beispielsweisejenkins-demosein. - Beachten Sie, dass
BUNDLETARGETaufdevfestgelegt ist, wobei es sich um den Namen des Ziels des Databricks-Ressourcenpakets handelt, das weiter unten in diesem Artikel definiert wird. In realen Implementierungen würden Sie dies in den Namen Ihres eigenen Bundleziels ändern. Weitere Details zu Bundlezielen finden Sie weiter unten in diesem Artikel.
Dies ist die Jenkinsfile, die dem Stammverzeichnis Ihres Repositorys hinzugefügt werden muss:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
Im restlichen Teil dieses Artikels werden die einzelnen Phasen in dieser Jenkins-Pipeline und das Einrichten der Artefakte und Befehle für Jenkins beschrieben, die in dieser Phase ausgeführt werden sollen.
Abrufen der neuesten Artefakte aus dem Drittanbieter-Repository
Die erste Phase in dieser Jenkins Pipeline, die Checkout-Phase, ist wie folgt definiert:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
In dieser Phase wird sichergestellt, dass das Arbeitsverzeichnis, das Jenkins auf Ihrem lokalen Entwicklungscomputer verwendet, über die neuesten Artefakte aus dem Git-Repository Ihres Drittanbieters verfügt. In der Regel legt Jenkins dieses Arbeitsverzeichnis auf <your-user-home-directory>/.jenkins/workspace/<pipeline-name> fest. Dadurch können Sie auf demselben lokalen Entwicklungscomputer Ihre eigene Kopie von Artefakten in der Entwicklung von den Artefakten trennen, die Jenkins vom Git-Repository Ihres Drittanbieters verwendet.
Validieren des Databricks-Ressourcenpakets
Die zweite Phase in dieser Jenkins Pipeline, die Validate Bundle-Phase, ist wie folgt definiert:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
In dieser Phase wird sichergestellt, dass das Databricks-Ressourcenpaket, das die Workflows zum Testen und Ausführen Ihrer Artefakte definiert, syntaktisch korrekt ist. Databricks-Ressourcenpakete, einfach als Pakete bezeichnet, ermöglichen, vollständige Daten, Analysen und ML-Projekte als Sammlung von Quelldateien auszudrücken. Weitere Informationen finden Sie unter Was sind Databricks-Ressourcenpakete?.
Um das Paket für diesen Artikel zu definieren, erstellen Sie eine Datei namens databricks.yml im Stammverzeichnis des geklonten Repositorys auf Ihrem lokalen Computer. Ersetzen Sie in dieser databricks.yml-Beispieldatei die folgenden Platzhalter:
- Ersetzen Sie
<bundle-name>durch einen eindeutigen programmgesteuerten Namen für das Bundle. Das kann beispielsweisejenkins-demosein. - Ersetzen Sie
<job-prefix-name>durch eine Zeichenfolge, um die Azure Databricks-Aufträge eindeutig zu identifizieren, die in Ihrem Arbeitsbereich für dieses Beispiel erstellt werden. Das kann beispielsweisejenkins-demosein. Er sollte mit demJOBPREFIX-Wert in Ihrer Jenkinsfile übereinstimmen. - Ersetzen Sie
<spark-version-id>durch die Databricks Runtime-Versions-ID für Ihre Auftragscluster, z. B.13.3.x-scala2.12. - Ersetzen Sie
<cluster-node-type-id>durch die Knotentyp-ID für Ihre Auftragscluster, z. B.Standard_DS3_v2. - Beachten Sie, dass
devin dertargets-Zuordnung mit demBUNDLETARGETin Ihrer Jenkinsfile identisch ist. Ein Bundleziel gibt den Host und das zugehörige Bereitstellungsverhalten an.
Dies ist die databricks.yml-Datei, die dem Stammverzeichnis Ihres Repositorys hinzugefügt werden muss, damit dieses Beispiel ordnungsgemäß funktioniert:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Weitere Informationen zur databricks.yml-Datei finden Sie unter Konfiguration für Databricks-Ressourcenpakete.
Bereitstellen des Bundles in Ihrem Arbeitsbereich
Die dritte Phase der Jenkins Pipeline namens Deploy Bundle ist wie folgt definiert:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Diese Phase erledigt Zweierlei:
- Da die
artifact-Zuordnung in derdatabricks.yml-Datei aufwhlfestgelegt ist, weist dies die Databricks-CLI an, die Python-Wheel-Datei mithilfe dersetup.py-Datei am angegebenen Speicherort zu erstellen. - Nachdem die Python-Wheel-Datei auf Ihrem lokalen Entwicklungscomputer basiert, stellt die Databricks-CLI die erstellte Python-Wheel-Datei zusammen mit den angegebenen Python-Dateien und Notebooks in Ihrem Azure Databricks-Arbeitsbereich bereit. Standardmäßig stellen Databricks-Ressourcenpakete die Python-Wheel-Datei und andere Dateien für
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>bereit.
Um die Python-Wheel-Datei so zu erstellen, wie in der databricks.yml-Datei angegeben, erstellen Sie die folgenden Ordner und Dateien im Stammverzeichnis Ihres geklonten Repositorys auf Ihrem lokalen Computer.
Um die Logik und die Komponententests für die Python-Wheel-Datei zu definieren, für das das Notebook ausgeführt wird, erstellen Sie zwei Dateien mit dem Namen addcol.py und test_addcol.py, und fügen Sie sie einer Ordnerstruktur namens python/dabdemo/dabdemo innerhalb des Libraries-Ordners Ihres Repositorys hinzu, visualisiert wie folgt (Auslassungspunkte geben aus Platzgründen ausgelassene Ordner im Repository an):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Die addcol.py-Datei enthält eine Bibliotheksfunktion, die später in eine Python-Wheel-Datei integriert und dann in einem Azure Databricks-Cluster installiert wird. Es handelt sich um eine einfache Funktion, die eine neue Spalte, die durch ein Literal aufgefüllt wird, einem Apache Spark-DataFrame hinzufügt:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Die Datei test_addcol.py enthält Tests zum Übergeben eines Pseudo-DataFrame-Objekts an die Funktion with_status, die in addcol.py definiert ist. Das Ergebnis wird dann mit einem DataFrame-Objekt verglichen, das die erwarteten Werte enthält. Wenn die Werte übereinstimmen – was in diesem Fall zutrifft – gilt der Test als bestanden:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Damit die Databricks-CLI diesen Bibliothekscode ordnungsgemäß in eine Python-Wheel-Datei packen kann, erstellen Sie zwei Dateien mit dem Namen __init__.py und __main__.py im selben Ordner wie die vorherigen beiden Dateien. Erstellen Sie außerdem eine Datei namens setup.py im Ordner python/dabdemo. Dies sieht wie folgt aus (zur Verbesserung der Übersichtlichkeit wurden nicht relevante Ordner ausgelassen; dies wird durch drei Punkte angezeigt):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Die Datei __init__.py enthält die Versionsnummer und den Autor der Bibliothek. Ersetzen Sie <my-author-name> durch Ihren Namen:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Die Datei __main__.py enthält den Einstiegspunkt der Bibliothek:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Die Datei setup.py enthält zusätzliche Einstellungen zum Erstellen der Bibliothek in einer Python-Wheel-Datei. Ersetzen Sie <my-url>, <my-author-name>@<my-organization> und <my-package-description> durch aussagekräftige Werte:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Testen der Komponentenlogik des Python-Wheels
Die Phase Run Unit Tests, die vierte Phase dieser Jenkins Pipeline, verwendet pytest, um die Logik einer Bibliothek zu testen, um sicherzustellen, dass sie wie erstellt funktioniert. Diese Phase wird folgendermaßen definiert:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
In dieser Phase wird die Databricks-CLI zum Ausführen eines Notebookauftrags verwendet. Dieser Auftrag führt das Python-Notebook mit dem Dateinamen von run-unit-test.py aus. Dieses Notebook führt pytest für die Logik der Bibliothek aus.
Um die Komponententests für dieses Beispiel auszuführen, fügen Sie eine Python-Notebookdatei mit dem Namen run_unit_tests.py mit dem folgenden Inhalt zum Stamm Ihres geklonten Repositorys auf Ihrem lokalen Computer hinzu:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Verwenden des integrierten Python-Wheels
Die fünfte Phase dieser Jenkins Pipeline mit dem Namen Run Notebook führt ein Python-Notebook aus, das die Logik in der integrierten Python-Wheel-Datei aufruft:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
In dieser Phase wird die Databricks-CLI ausgeführt, die wiederum Ihren Arbeitsbereich anweist, einen Notebookauftrag auszuführen. Dieses Notebook erstellt ein DataFrame-Objekt, übergibt es an die with_status-Funktion der Bibliothek, gibt das Ergebnis aus und meldet die Ausführungsergebnisse des Auftrags. Erstellen Sie das Notebook, indem Sie eine Python-Notebookdatei mit dem Namen dabdaddemo_notebook.py mit dem folgenden Inhalt zum Stamm Ihres geklonten Repositorys auf Ihrem lokalen Computer hinzufügen:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Auswerten der Ergebnisse der Ausführung des Notebookauftrags
Die Phase Evaluate Notebook Runs, die sechste Phase dieser Jenkins-Pipeline, wertet die Ergebnisse des vorherigen Notebookauftrags aus. Diese Phase wird folgendermaßen definiert:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
In dieser Phase wird die Databricks-CLI ausgeführt, die wiederum Ihren Arbeitsbereich anweist, einen Python-Dateiauftrag auszuführen. Diese Python-Datei bestimmt die Fehler- und Erfolgskriterien für die Ausführung des Notebookauftrags und meldet diesen Fehler oder das Erfolgsergebnis. Erstellen Sie eine Datei mit dem Namen evaluate_notebook_runs.py mit dem folgenden Inhalt zum Stamm Ihres geklonten Repositorys auf Ihrem lokalen Computer hinzufügen:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Importieren und Melden der Testergebnisse
Die siebte Stufe in dieser Jenkins Pipeline mit dem Namen Import Test Resultsverwendet die Databricks-CLI, um die Testergebnisse aus Ihrem Arbeitsbereich an Ihren lokalen Entwicklungscomputer zu senden. Die achte und letzte Phase mit dem Namen Publish Test Results veröffentlicht die Testergebnisse mit dem junit-Jenkins-Plug-In. Dadurch können Sie Berichte und Dashboards im Zusammenhang mit dem Status der Testergebnisse visualisieren. Diese Phasen sind wie folgt definiert:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
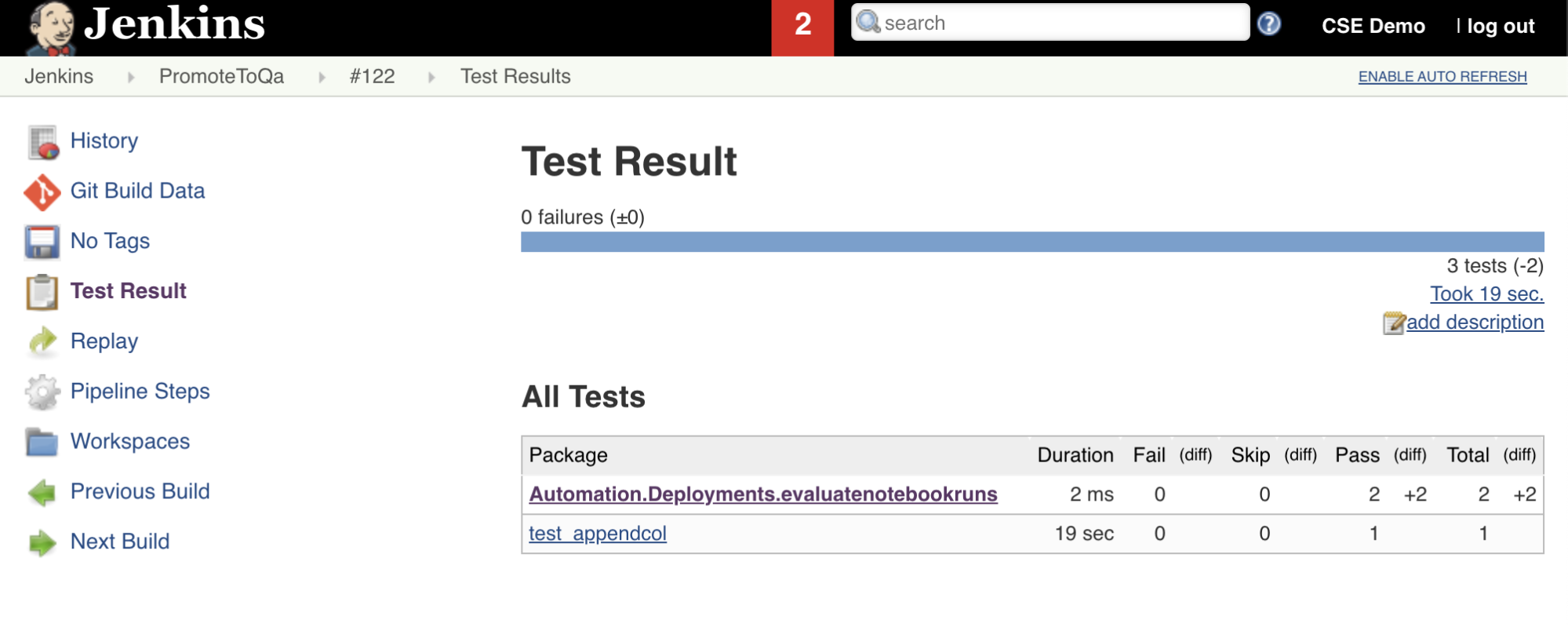
Pushen aller Codeänderungen an Ihr Drittanbieter-Repository
Sie sollten nun den Inhalt Ihres geklonten Repositorys auf Ihrem lokalen Entwicklungscomputer an Ihr Drittanbieter-Repository übertragen. Bevor Sie pushen, sollten Sie zuerst die folgenden Einträge zur .gitignore-Datei in Ihrem geklonten Repository hinzufügen, da Sie wahrscheinlich keine internen Databricks-Ressourcenpaket-Arbeitsdateien, Validierungsberichte, Python-Builddateien und Python-Caches in Ihr Drittanbieter-Repository übertragen sollten. In der Regel sollten Sie neue Validierungsberichte und die letzten Python-Wheel-Builds in Ihrem Azure Databricks-Arbeitsbereich neu generieren, anstatt potenziell veraltete Validierungsberichte und Python-Wheel-Builds zu verwenden:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Ausführen Ihrer Jenkins-Pipeline
Sie sind jetzt bereit, Ihre Jenkins Pipeline manuell auszuführen. Gehen Sie dazu in Ihrem Jenkins-Dashboard wie folgt vor:
- Klicken Sie auf den Namen Ihrer Jenkins-Pipeline.
- Klicken Sie auf der Seitenleiste auf Jetzt erstellen.
- Um die Ergebnisse anzuzeigen, klicken Sie auf die neueste Pipelineausführung (z. B.
#1) und dann auf Konsolenausgabe.
Jetzt hat die CI/CD-Pipeline einen Integrations- und Bereitstellungszyklus abgeschlossen. Durch die Automatisierung dieses Prozesses können Sie sicherstellen, dass Ihr Code durch einen effizienten, konsistenten und wiederholbaren Prozess getestet und bereitgestellt wurde. Wenn Sie Ihren Git-Drittanbieter anweisen möchten, Jenkins jedes Mal auszuführen, wenn ein bestimmtes Ereignis auftritt, z. B. eine Repository-Pullanforderung, lesen Sie die Git-Dokumentation Ihres Drittanbieters.