Entwickeln von Pipelinecode mit Python
Delta Live Tables führt mehrere neue Python-Codekonstrukte zum Definieren materialisierter Ansichten und Streamingtabellen in Pipelines ein. Python-Unterstützung für die Entwicklung von Pipelines basiert auf den Grundlagen von PySpark DataFrame und Structured Streaming APIs.
Für Benutzerinnen und Benutzer, die nicht mit Python und DataFrames vertraut sind, empfiehlt Databricks die Verwendung der SQL-Schnittstelle. Siehe Entwickeln von Pipelinecode mit SQL.
Eine vollständige Referenz zur Syntax von Delta Live Tables Python finden Sie in der Sprachreferenz zu Delta Live Tables Python.
Grundlagen von Python für die Pipelineentwicklung
Python-Code zum Erstellen von Delta Live Tables-Datasets muss DataFrames zurückgeben.
Alle Python-APIs von Delta Live Tables werden im dlt-Modul implementiert. Ihr mit Python implementierter Delta Live Tables-Pipelinecode muss das dlt-Modul am Anfang von Python-Notebooks und -Dateien explizit importieren.
Liest und schreibt standardmäßig in den Katalog und das Schema, die während der Pipelinekonfiguration angegeben wurden. Siehe Festlegen des Zielkatalogs und des Schemas.
Delta Live Tables-spezifischer Python-Code unterscheidet sich von anderen Python-Codetypen auf eine wichtige Weise: Python-Pipelinecode ruft nicht direkt die Funktionen auf, die Datenaufnahme und Transformation durchführen, um Delta Live Tables-Datasets zu erstellen. Stattdessen interpretiert Delta Live Tables die Dekorierfunktionen aus dem dlt Modul in allen Quellcodedateien, die in einer Pipeline konfiguriert sind, und erstellt ein Datenflussdiagramm.
Wichtig
Um ein unerwartetes Verhalten bei der Ausführung Ihrer Pipeline zu vermeiden, sollten Sie in Ihre Funktionen, die Datasets definieren, keinen Code aufnehmen, der Nebeneffekte haben könnte. Weitere Informationen finden Sie in der Python-Referenz.
Erstellen einer materialisierten Ansicht oder Streamingtabelle mit Python
Der @dlt.table Dekorateur teilt Delta Live Tables mit, basierend auf den ergebnissen, die von einer Funktion zurückgegeben werden, eine materialisierte Ansicht oder Streamingtabelle zu erstellen. Die Ergebnisse eines Batchlesevorgangs erstellen eine materialisierte Ansicht, während die Ergebnisse eines Streaminglesevorgangs eine Streamingtabelle erstellen.
Standardmäßig werden materialisierte Ansichts- und Streamingtabellennamen von Funktionsnamen abgeleitet. Das folgende Codebeispiel zeigt die grundlegende Syntax zum Erstellen einer materialisierten Ansichts- und Streamingtabelle:
Hinweis
Beide Funktionen verweisen auf dieselbe Tabelle im samples Katalog und verwenden dieselbe Dekorierfunktion. In diesen Beispielen wird hervorgehoben, dass der einzige Unterschied in der grundlegenden Syntax für materialisierte Ansichten und Streamingtabellen im Vergleich dazu spark.readverwendet spark.readStream wird.
Nicht alle Datenquellen unterstützen Streaminglesevorgänge. Einige Datenquellen sollten immer mit Streamingsemantik verarbeitet werden.
import dlt
@dlt.table()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Optional können Sie den Tabellennamen mithilfe des name Arguments im @dlt.table Dekorateur angeben. Im folgenden Beispiel wird dieses Muster für eine materialisierte Ansichts- und Streamingtabelle veranschaulicht:
import dlt
@dlt.table(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Laden von Daten aus objektspeicher
Delta Live Tables unterstützt das Laden von Daten aus allen von Azure Databricks unterstützten Formaten. Siehe Datenformatoptionen.
Hinweis
In diesen Beispielen werden Daten verwendet, die unter der /databricks-datasets automatischen Bereitstellung in Ihrem Arbeitsbereich verfügbar sind. Databricks empfiehlt die Verwendung von Volumepfaden oder Cloud-URIs, um auf daten zu verweisen, die im Cloudobjektspeicher gespeichert sind. Weitere Informationen finden Sie unter Was sind Unity Catalog-Volumes?.
Databricks empfiehlt die Verwendung von AutoLade- und Streamingtabellen beim Konfigurieren von inkrementellen Erfassungsworkloads für Daten, die im Cloudobjektspeicher gespeichert sind. Weitere Informationen finden Sie unter Automatisches Laden.
Im folgenden Beispiel wird eine Streamingtabelle aus JSON-Dateien mit dem automatischen Ladeprogramm erstellt:
import dlt
@dlt.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Im folgenden Beispiel werden Batchsemantik verwendet, um ein JSON-Verzeichnis zu lesen und eine materialisierte Ansicht zu erstellen:
import dlt
@dlt.table()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Überprüfen von Daten mit Erwartungen
Sie können die Erwartungen verwenden, um Einschränkungen für die Datenqualität festzulegen und zu erzwingen. Weitere Informationen finden Sie unter Verwalten der Datenqualität mit Pipelineerwartungen.
Mit dem folgenden Code wird @dlt.expect_or_drop eine Erwartung valid_data definiert, die datensätze abbricht, die während der Datenaufnahme null sind:
import dlt
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Abfragen materialisierter Ansichten und Streamingtabellen, die in Ihrer Pipeline definiert sind
Im folgenden Beispiel werden vier Datasets definiert:
- Eine Streamingtabelle,
ordersdie JSON-Daten lädt. - Eine materialisierte Ansicht, die CSV-Daten
customerslädt. - Eine materialisierte Ansicht mit dem Namen
customer_orders, die Datensätze aus denordersDatensätzen undcustomersDatasets verknüpft, den Zeitstempel der Reihenfolge in ein Datum wandelt und diecustomer_idFelder ,order_number, undstateorder_datedie Felder auswählt. - Eine materialisierte Ansicht mit dem Namen
daily_orders_by_state, die die tägliche Anzahl der Bestellungen für jeden Zustand aggregiert.
Hinweis
Beim Abfragen von Ansichten oder Tabellen in Ihrer Pipeline können Sie den Katalog und das Schema direkt angeben oder die in Ihrer Pipeline konfigurierten Standardwerte verwenden. In diesem Beispiel werden die Tabellen orders, customersund customer_orders aus dem Standardkatalog und dem für Ihre Pipeline konfigurierten Schema geschrieben und gelesen.
Im Legacyveröffentlichungsmodus wird das LIVE Schema verwendet, um andere materialisierte Ansichten und Streamingtabellen abzufragen, die in Ihrer Pipeline definiert sind. In neuen Pipelines wird die LIVE Schema-Syntax stillschweigend ignoriert. Weitere Informationen finden Sie unter LIVE-Schema (Legacy).
import dlt
from pyspark.sql.functions import col
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dlt.table()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dlt.table()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dlt.table()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Tabellen in einer for Schleife erstellen
Sie können Python-Schleifen for verwenden, um mehrere Tabellen programmgesteuert zu erstellen. Dies kann nützlich sein, wenn Sie über viele Datenquellen oder Zieldatensets verfügen, die von nur wenigen Parametern variieren, was zu weniger Gesamtcode führt, um Coderedundanz zu erhalten und weniger Coderedundanz zu gewährleisten.
Die for Schleife wertet logik in der seriellen Reihenfolge aus, aber sobald die Planung für die Datasets abgeschlossen ist, wird die Pipeline logik parallel ausgeführt.
Wichtig
Stellen Sie bei Verwendung dieses Musters zum Definieren von Datasets sicher, dass die Liste der an die for Schleife übergebenen Werte immer additiv ist. Wenn ein zuvor in einer Pipeline definiertes Dataset aus einer zukünftigen Pipelineausführung weggelassen wird, wird dieses Dataset automatisch aus dem Zielschema gelöscht.
Im folgenden Beispiel werden fünf Tabellen erstellt, die Kundenbestellungen nach Region filtern. Hier wird der Regionsname verwendet, um den Namen der materialisierten Zielansichten festzulegen und die Quelldaten zu filtern. Temporäre Ansichten werden verwendet, um Verknüpfungen aus den Quelltabellen zu definieren, die beim Erstellen der endgültigen materialisierten Ansichten verwendet werden.
import dlt
from pyspark.sql.functions import collect_list, col
@dlt.view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dlt.view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dlt.table(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Im Folgenden sehen Sie ein Beispiel für das Datenflussdiagramm für diese Pipeline:
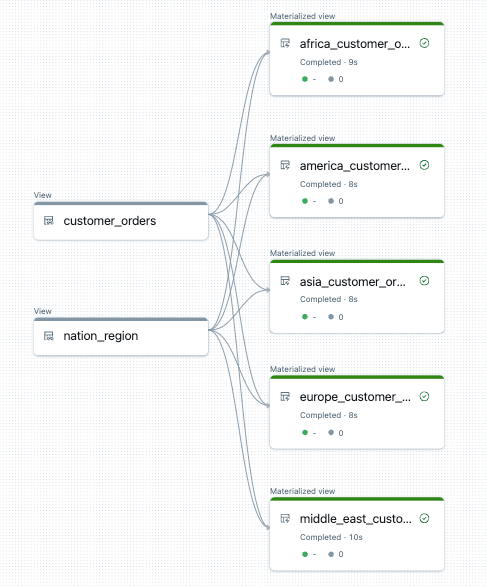
Problembehandlung: for Schleife erstellt viele Tabellen mit denselben Werten
Das faule Ausführungsmodell, das pipelines zum Auswerten von Python-Code verwendet, erfordert, dass Ihre Logik direkt auf einzelne Werte verweist, wenn die von der Funktion versehene @dlt.table() Funktion aufgerufen wird.
Im folgenden Beispiel werden zwei richtige Ansätze zum Definieren von Tabellen mit einer for Schleife veranschaulicht. In beiden Beispielen wird auf jeden Tabellennamen aus der tables Liste explizit innerhalb der funktion verwiesen, die von @dlt.table().
import dlt
# Create a parent function to set local variables
def create_table(table_name):
@dlt.table(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dlt.table()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
Im folgenden Beispiel wird nicht richtig auf Werte verwiesen. In diesem Beispiel werden Tabellen mit unterschiedlichen Namen erstellt, aber alle Tabellen laden Daten aus dem letzten Wert in der for Schleife:
import dlt
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table():
return spark.read.table(t_name)