Auftragssystemtabellenreferenz
Hinweis
Das Schema lakeflow wurde früher als workflow bezeichnet. Der Inhalt beider Schemas ist identisch. Damit das lakeflow-Schema sichtbar wird, muss es separat aktiviert werden.
Dieser Artikel ist ein Leitfaden für die Verwendung der lakeflow System-Tabellen zum Überwachen von Aufträgen in Ihrem Konto. Diese Tabellen enthalten Datensätze aus allen Arbeitsbereichen in Ihrem Konto, die in derselben Cloudregion bereitgestellt wurden. Um Datensätze aus einer anderen Region anzuzeigen, müssen Sie die Tabellen aus einem Arbeitsbereich anzeigen, der in dieser Region bereitgestellt wird.
Anforderungen
- Das
system.lakeflowSchema muss von einem Kontoadministrator aktiviert werden. Siehe Aktivieren von Systemtabellenschemas. - Um auf diese Systemtabellen zuzugreifen, müssen Benutzer eine der folgenden Aktionen ausführen:
- Seien Sie sowohl ein Metastore-Administrator als auch ein Kontoadministrator, oder ...
- Verfügen Sie über
USE- undSELECT-Berechtigungen für die Systemschemata. Siehe Gewähren des Zugriffs auf Systemtabellen.
Verfügbare Auftragstabellen
Alle auftragsbezogenen Systemtabellen befinden sich im system.lakeflow Schema. Derzeit hostet das Schema vier Tabellen:
| Tabelle | Beschreibung | Unterstützt Streaming | Kostenloser Aufbewahrungszeitraum | Umfasst globale oder regionale Daten |
|---|---|---|---|---|
| Aufträge (öffentliche Vorschauversion) | Verfolgt alle aufträge, die im Konto erstellt wurden | Ja | 365 Tage | Regional |
| job_tasks (öffentliche Vorschauversion) | Verfolgt alle Auftragsaufgaben, die im Konto ausgeführt werden | Ja | 365 Tage | Regional |
| job_run_timeline (öffentliche Vorschauversion) | Verfolgt die Ausführung des Auftrags und zugehörige Metadaten | Ja | 365 Tage | Regional |
| job_task_run_timeline (öffentliche Vorschauversion) | Verfolgt die Ausführung von Auftragsaufgaben und zugehörige Metadaten | Ja | 365 Tage | Regional |
Detaillierte Schemareferenz
In den folgenden Abschnitten werden Schemaverweise für jede der auftragsbezogenen Systemtabellen bereitgestellt.
Auftragstabellenschema
Die jobs Tabelle ist eine langsam ändernde Dimensionstabelle (SCD2). Wenn eine Zeile geändert wird, wird eine neue Zeile ausgegeben, die logisch die vorherige Zeile ersetzt.
Tabellenpfad: system.lakeflow.jobs
| Spaltenname | Datentyp | Beschreibung | Notizen |
|---|---|---|---|
account_id |
string | Die ID des Kontos, zu dem dieser Auftrag gehört | |
workspace_id |
string | Die ID des Arbeitsbereichs, zu dem dieser Auftrag gehört | |
job_id |
string | Die ID des Auftrags | Nur innerhalb eines einzelnen Arbeitsbereichs eindeutig |
name |
string | Der vom Benutzer angegebene Name des Auftrags | |
description |
string | Die vom Benutzer bereitgestellte Beschreibung des Auftrags | Dieses Feld ist leer, wenn vom Kunden verwaltete Schlüssel konfiguriert sind. Wird nicht ausgefüllt für Zeilen, die vor Ende August 2024 ausgegeben wurden |
creator_id |
string | Die ID des Prinzipals, der den Auftrag erstellt hat | |
tags |
string | Die vom Benutzer bereitgestellten benutzerdefinierten Tags, die diesem Auftrag zugeordnet sind | |
change_time |
Zeitstempel | Der Zeitpunkt, zu dem der Auftrag zuletzt geändert wurde | Als +00:00 (UTC) aufgezeichnete Zeitzone |
delete_time |
Zeitstempel | Der Zeitpunkt, zu dem der Auftrag vom Benutzer gelöscht wurde | Als +00:00 (UTC) aufgezeichnete Zeitzone |
run_as |
string | Die ID des Benutzer- oder Dienstprinzipals, dessen Berechtigungen für die Ausführung des Auftrags verwendet werden |
Beispielabfrage
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
Auftragsaufgabentabellenschema
Die Auftragsaufgabentabelle ist eine langsam ändernde Dimensionstabelle (SCD2). Wenn eine Zeile geändert wird, wird eine neue Zeile ausgegeben, die logisch die vorherige Zeile ersetzt.
Tabellenpfad: system.lakeflow.job_tasks
| Spaltenname | Datentyp | Beschreibung | Notizen |
|---|---|---|---|
account_id |
string | Die ID des Kontos, zu dem dieser Auftrag gehört | |
workspace_id |
string | Die ID des Arbeitsbereichs, zu dem dieser Auftrag gehört | |
job_id |
string | Die ID des Auftrags | Nur innerhalb eines einzelnen Arbeitsbereichs eindeutig |
task_key |
string | Der Referenzschlüssel für einen Vorgang in einem Auftrag | Nur innerhalb eines einzelnen Auftrags eindeutig |
depends_on_keys |
array | Die Aufgabenschlüssel aller vorgelagerten Abhängigkeiten dieses Vorgangs | |
change_time |
Zeitstempel | Zeitpunkt der letzten Änderung des Vorgangs | Als +00:00 (UTC) aufgezeichnete Zeitzone |
delete_time |
Zeitstempel | Der Zeitpunkt, zu dem eine Aufgabe vom Benutzer gelöscht wurde | Als +00:00 (UTC) aufgezeichnete Zeitzone |
Beispielabfrage
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
Zeitachsentabellenschema für Auftragsausführung
Die Zeitachsentabelle für die Auftragsausführung ist unveränderlich und zum Zeitpunkt der Produktion abgeschlossen.
Tabellenpfad: system.lakeflow.job_run_timeline
| Spaltenname | Datentyp | Beschreibung | Notizen |
|---|---|---|---|
account_id |
string | Die ID des Kontos, zu dem dieser Auftrag gehört | |
workspace_id |
string | Die ID des Arbeitsbereichs, zu dem dieser Auftrag gehört | |
job_id |
string | Die ID des Auftrags | Dieser Schlüssel ist nur innerhalb eines einzelnen Arbeitsbereichs eindeutig. |
run_id |
string | Die ID der Auftragsausführung | |
period_start_time |
Zeitstempel | Die Startzeit für die Ausführung oder den Zeitraum | Zeitzoneninformationen werden am Ende des Werts mit +00:00 aufgezeichnet, die UTC darstellt. |
period_end_time |
Zeitstempel | Die Endzeit für die Ausführung oder den Zeitraum | Zeitzoneninformationen werden am Ende des Werts mit +00:00 aufgezeichnet, die UTC darstellt. |
trigger_type |
string | Der Triggertyp, der eine Ausführung auslösen kann | Mögliche Werte finden Sie unter Triggertypwerte |
run_type |
string | Der Auftragstyp, der ausgeführt wird | Mögliche Werte finden Sie unter Ausführungstypwerte |
run_name |
string | Der vom Benutzer angegebene Ausführungsname, der diesem Auftrag zugeordnet ist | |
compute_ids |
array | Array, das die Auftragsberechnungs-IDs für den übergeordneten Auftrag enthält | Verwenden zum Identifizieren des Auftragsclusters, der von WORKFLOW_RUN-Ausführungstypen verwendet wird. Weitere Berechnungsinformationen finden Sie in der job_task_run_timeline Tabelle.Wird nicht ausgefüllt für Zeilen, die vor Ende August 2024 ausgegeben wurden |
result_state |
string | Das Ergebnis der Ausführung des Auftrags | Mögliche Werte finden Sie unter Ergebnisstatuswerte |
termination_code |
string | Der Beendigungscode des Auftragslaufs | Mögliche Werte finden Sie unter Beendigungscodewerte. Wird nicht ausgefüllt für Zeilen, die vor Ende August 2024 ausgegeben wurden |
job_parameters |
Karte | Die Parameter auf Auftragsebene, die in der Auftragsausführung verwendet werden | Die veralteten notebook_params Einstellungen sind in diesem Feld nicht enthalten. Wird nicht ausgefüllt für Zeilen, die vor Ende August 2024 ausgegeben wurden |
Beispielabfrage
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
Auftragsaufgabe: Zeitachsentabellenschema ausführen
Die Zeitachsentabelle für die Auftragsausführung ist unveränderlich und zum Zeitpunkt der Produktion abgeschlossen.
Tabellenpfad: system.lakeflow.job_task_run_timeline
| Spaltenname | Datentyp | Beschreibung | Notizen |
|---|---|---|---|
account_id |
string | Die ID des Kontos, dem dieser Auftrag zugeordnet ist | |
workspace_id |
string | Die ID des Arbeitsbereichs, zu dem dieser Auftrag gehört | |
job_id |
string | Die ID des Auftrags | Nur innerhalb eines einzelnen Arbeitsbereichs eindeutig |
run_id |
string | Die ID der Ausführung der Aufgabe | |
job_run_id |
string | Die ID der Auftragsausführung | Wird nicht ausgefüllt für Zeilen, die vor Ende August 2024 ausgegeben wurden |
parent_run_id |
string | Die ID der übergeordneten Ausführung | Wird nicht ausgefüllt für Zeilen, die vor Ende August 2024 ausgegeben wurden |
period_start_time |
Zeitstempel | Die Startzeit für den Vorgang oder für den Zeitraum | Zeitzoneninformationen werden am Ende des Werts mit +00:00 aufgezeichnet, die UTC darstellt. |
period_end_time |
Zeitstempel | Die Endzeit für den Vorgang oder für den Zeitraum | Zeitzoneninformationen werden am Ende des Werts mit +00:00 aufgezeichnet, die UTC darstellt. |
task_key |
string | Der Referenzschlüssel für einen Vorgang in einem Auftrag | Dieser Schlüssel ist nur innerhalb eines einzelnen Auftrags eindeutig. |
compute_ids |
array | Das compute_ids Array enthält IDs von Auftragsclustern, interaktiven Clustern und SQL-Lagerhäusern, die von der Auftragsaufgabe verwendet werden. | |
result_state |
string | Das Ergebnis der Ausführung der Auftragsaufgabe | Mögliche Werte finden Sie unter Ergebnisstatuswerte |
termination_code |
string | Der Beendigungscode der Aufgabe | Mögliche Werte finden Sie unter Beendigungscodewerte. Wird nicht ausgefüllt für Zeilen, die vor Ende August 2024 ausgegeben wurden |
Allgemeine Verknüpfungsmuster
In den folgenden Abschnitten werden Beispielabfragen bereitgestellt, die häufig verwendete Verknüpfungsmuster für Auftragssystemtabellen hervorheben.
Verknüpfen von Aufträgen und Aufträgen mit Zeitachsentabellen
Anreichern einer Auftragsausführung mit einem Auftragsnamen
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Verknüpfen der Auftragsausführungszeitachsen- und Verbrauchstabellen
Anreichern jedes Abrechnungsprotokolls mit Auftragsausführungsmetadaten
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Berechnen der Kosten pro Auftragsausführung
Diese Abfrage wird mit der billing.usage Systemtabelle verknüpft, um die Kosten pro Auftragsausführung zu berechnen.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Abrufen von Verbrauchsprotokollen für SUBMIT_RUN Aufträge
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
Verknüpfen der Auftragsaufgabenausführung-Zeitskala mit Clustertabellen
Aufgabenläufe mit Clustermetadaten anreichern
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Suchen von Aufträgen, die auf All-Purpose Compute ausgeführt werden
Diese Abfrage wird mit der compute.clusters Systemtabelle verknüpft, um zuletzt ausgeführte Aufträge zurückzugeben, die auf All-Purpose Compute ausgeführt werden, anstatt auf Jobs Compute.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Dashboard zur Überwachung von Aufträgen
Das folgende Dashboard verwendet Systemtabellen, um Ihnen bei den ersten Schritten bei der Überwachung Ihrer Aufträge und des Betriebszustands zu helfen. Sie umfasst häufige Anwendungsfälle wie Auftragsleistungsnachverfolgung, Fehlerüberwachung und Ressourcenauslastung.
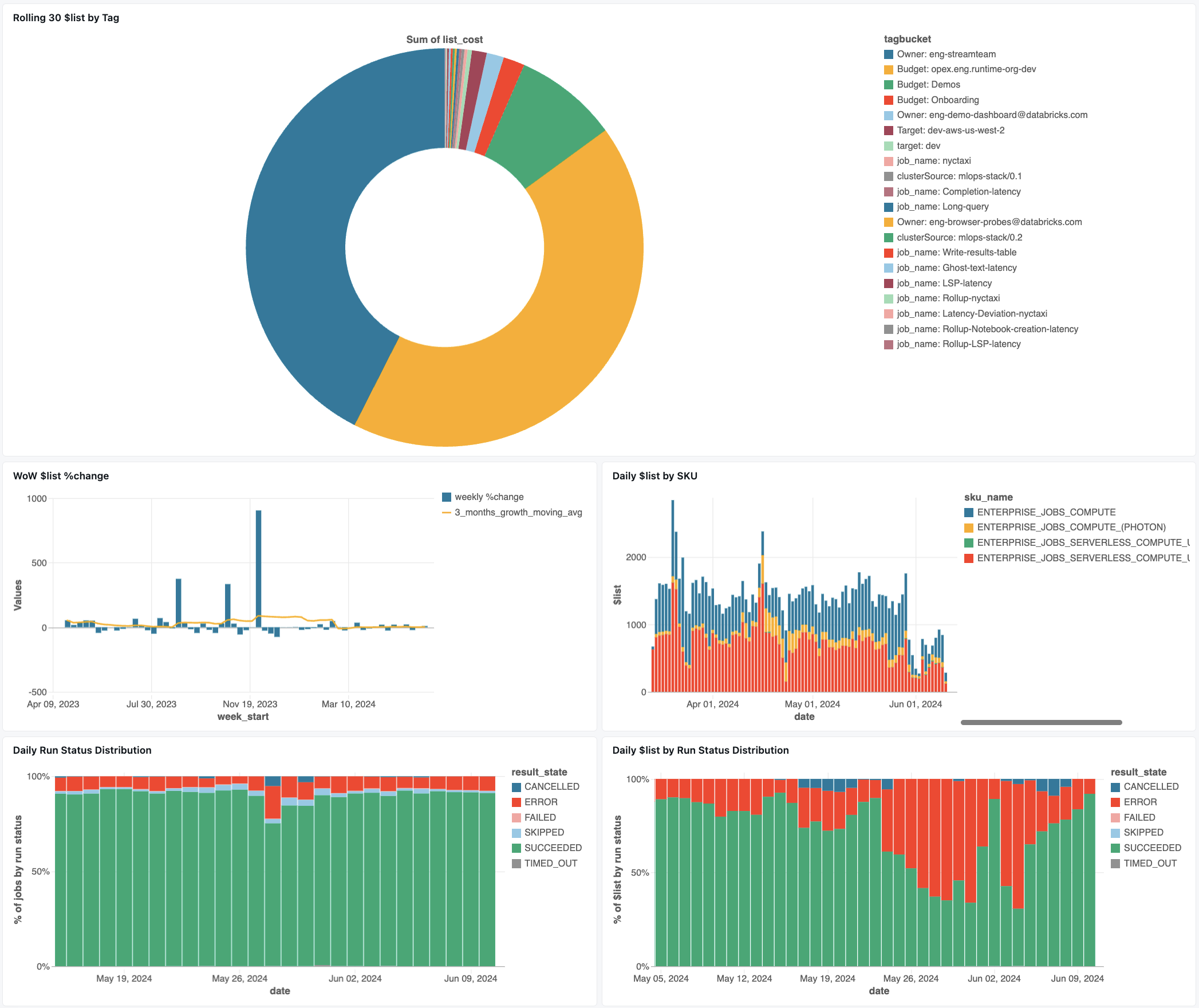
Informationen zum Herunterladen des Dashboards finden Sie unter Überwachen von Auftragskosten und -leistung mit Systemtabellen
Problembehandlung
Auftrag wird nicht in der lakeflow.jobs-Tabelle protokolliert
Wenn ein Auftrag in den Systemtabellen nicht sichtbar ist:
- Der Auftrag wurde in den letzten 365 Tagen nicht geändert.
- Ändern Sie alle Felder des Auftrags, die im Schema vorhanden sind, um einen neuen Datensatz auszugeben.
- Der Job wurde in einer anderen Region erstellt.
- Neuere Auftragserstellung (Tabellenabstand)
In der job_run_timeline-Tabelle vorhandener Auftrag ist nicht zu finden
Nicht alle Auftragsausführungen sind überall sichtbar. Während JOB_RUN-Einträge in allen auftragsbezogenen Tabellen erscheinen, werden WORKFLOW_RUN (Notizbuch-Workflow-Ausführungen) nur in job_run_timeline aufgezeichnet. SUBMIT_RUN (einmalige Übermittlungen) werden hingegen sowohl in der einen als auch in der anderen Zeitleistentabelle aufgezeichnet. Diese Ausführungen werden nicht in andere Auftragssystemtabellen wie jobs oder job_tasks eingetragen.
In der nachstehenden Tabelle Ausführungstypen finden Sie eine detaillierte Übersicht darüber, wo jeder Ausführungstyp sichtbar und zugänglich ist.
Auftragsausführung ist in der billing.usage-Tabelle nicht sichtbar
In system.billing.usage wird das Feld usage_metadata.job_id nur für Aufträge aufgefüllt, die auf Jobcompute oder serverlosem Computing ausgeführt werden.
Darüber hinaus haben WORKFLOW_RUN Arbeitsplätze in system.billing.usagekeine eigene usage_metadata.job_id- oder usage_metadata.job_run_id-Zuordnung.
Stattdessen wird der Computeverbrauch dem übergeordneten Notebook, das sie ausgelöst hat, zugeordnet.
Dies bedeutet Folgendes: Wenn ein Notebook eine Workflowausführung startet, werden alle Computekosten unter dem Verbrauch des übergeordneten Notebooks und nicht als separater Workflowauftrag angezeigt.
Weitere Informationen finden Sie in der -Verwendungsmetadatenreferenz.
Berechnen der Kosten eines Auftrags, der auf All-Purpose Compute ausgeführt wird
Genaue Kostenberechnungen für Aufträge, die auf All-Purpose Compute ausgeführt werden, sind mit einer Genauigkeit von 100 % nicht möglich. Wenn ein Auftrag auf einem interaktiven (allgemeinen) Rechner ausgeführt wird, werden mehrere Workloads wie Notizbücher, SQL-Abfragen oder andere Aufträge häufig gleichzeitig auf derselben Rechnerressource ausgeführt. Da die Clusterressourcen gemeinsam genutzt werden, gibt es keine direkte 1:1-Zuordnung zwischen Rechenkosten und einzelnen Auftragsläufen.
Für die genaue Nachverfolgung von Auftragskosten empfiehlt Databricks das Ausführen von Aufträgen auf dediziertem Job-Compute oder serverlosems Computing, wobei usage_metadata.job_id und usage_metadata.job_run_id eine genaue Kostenzuordnung ermöglichen.
Wenn Sie All-Purpose Compute verwenden müssen, haben Sie folgende Möglichkeiten:
- Überwachen Sie Verbrauch und Kosten des gesamten Clusters in
system.billing.usagebasierend aufusage_metadata.cluster_id. - Separat die Laufzeitmetriken von Aufträgen verfolgen.
- Berücksichtigen Sie, dass jede Kostenschätzung aufgrund gemeinsam genutzter Ressourcen ungefähr ist.
Weitere Informationen zur Kostenzuordnung finden Sie unter Referenz zu Nutzungsmetadaten.
Referenzwerte
Der folgende Abschnitt enthält Verweise auf ausgewählte Spalten in auftragsbezogenen Tabellen.
Triggertypwerte
Die möglichen Werte für die trigger_type Spalte sind:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
Ausführungstypwerte
Die möglichen Werte für die run_type Spalte sind:
| Typ | Beschreibung | Speicherort der Benutzeroberfläche | API-Endpunkt | Systemtabellen |
|---|---|---|---|---|
JOB_RUN |
Standardauftragsausführung | Benutzeroberfläche für Aufträge und Auftragsausführungen | Endpunkte /jobs und /jobs/runs | jobs, job_tasks, job_run_timeline, job_task_run_timeline |
SUBMIT_RUN |
Einmalige Ausführung über POST /jobs/runs/submit | Nur Benutzeroberfläche für Auftragsausführungen | Nur /jobs/runs-Endpunkte | job_run_timeline, job_task_run_timeline |
WORKFLOW_RUN |
Vom Notebookworkflow initiierte Ausführung | Nicht sichtbar | Nicht zugänglich | job_run_timeline |
Ergebnisstatuswerte
Die möglichen Werte für die result_state Spalte sind:
| Staat | Beschreibung |
|---|---|
SUCCEEDED |
Die Ausführung wurde erfolgreich abgeschlossen. |
FAILED |
Die Ausführung wurde mit einem Fehler abgeschlossen. |
SKIPPED |
Die Ausführung wurde nie ausgeführt, weil eine Bedingung nicht erfüllt wurde. |
CANCELLED |
Die Ausführung wurde auf Anforderung des Benutzers abgebrochen. |
TIMED_OUT |
Die Ausführung wurde beendet, nachdem das Timeout aufgetreten ist. |
ERROR |
Die Ausführung wurde mit einem Fehler abgeschlossen. |
BLOCKED |
Die Ausführung wurde für eine Upstreamabhängigkeit blockiert. |
Beendigungscodewerte
Die möglichen Werte für die termination_code Spalte sind:
| Beendigungscode | Beschreibung |
|---|---|
SUCCESS |
Der Lauf wurde erfolgreich abgeschlossen. |
CANCELLED |
Die Ausführung wurde während der Ausführung von der Databricks-Plattform abgebrochen; Beispiel: Wenn die maximale Laufzeit überschritten wurde |
SKIPPED |
Die Ausführung wurde nie ausgeführt, z. B. wenn die Ausführung der Upstream-Aufgabe fehlgeschlagen ist, die Bedingung des Abhängigkeitstyps nicht erfüllt wurde, oder es wurden keine wesentlichen Aufgaben ausgeführt. |
DRIVER_ERROR |
Ein Fehler trat während der Ausführung bei der Kommunikation mit dem Spark-Driver auf. |
CLUSTER_ERROR |
Der Lauf scheiterte aufgrund eines Clusterfehlers. |
REPOSITORY_CHECKOUT_FAILED |
Fehler beim Abschließen des Auscheckens aufgrund eines Fehlers bei der Kommunikation mit dem Drittanbieterdienst |
INVALID_CLUSTER_REQUEST |
Der Lauf ist fehlgeschlagen, weil er eine ungültige Anforderung zum Starten des Clusters ausgestellt hat. |
WORKSPACE_RUN_LIMIT_EXCEEDED |
Der Arbeitsbereich hat das Kontingent für die maximale Anzahl gleichzeitig aktiver Ausführungen erreicht. Erwägen Sie, die Läufe über einen längeren Zeitraum zu planen. |
FEATURE_DISABLED |
Der Vorgang schlug fehl, weil er versucht hat, auf eine Funktion zuzugreifen, die für den Arbeitsbereich nicht verfügbar ist. |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
Die Anzahl der Clustererstellungs-, Start- und Vergrößerungsanfragen hat das zugewiesene Ratenlimit überschritten. Erwägen Sie, die Ausführung über einen größeren Zeitrahmen zu verteilen. |
STORAGE_ACCESS_ERROR |
Fehler bei der Ausführung aufgrund eines Fehlers beim Zugriff auf den Kunden-BLOB-Speicher |
RUN_EXECUTION_ERROR |
Die Ausführung wurde mit Vorgangsfehlern abgeschlossen. |
UNAUTHORIZED_ERROR |
Fehler beim Ausführen aufgrund eines Berechtigungsproblems beim Zugriff auf eine Ressource. |
LIBRARY_INSTALLATION_ERROR |
Fehler bei der Ausführung beim Installieren der vom Benutzer angeforderten Bibliothek. Die Ursachen können enthalten, sind jedoch nicht beschränkt auf: Die bereitgestellte Bibliothek ist ungültig, es gibt unzureichende Berechtigungen zum Installieren der Bibliothek usw. |
MAX_CONCURRENT_RUNS_EXCEEDED |
Die geplante Ausführung überschreitet den Grenzwert für maximale gleichzeitige Ausführungen, der für den Auftrag festgelegt ist. |
MAX_SPARK_CONTEXTS_EXCEEDED |
Die Ausführung ist für einen Cluster geplant, der bereits die maximale Anzahl von konfigurierten Kontexten erreicht hat. |
RESOURCE_NOT_FOUND |
Es ist keine Ressource vorhanden, die für die Ausführung erforderlich ist. |
INVALID_RUN_CONFIGURATION |
Fehler bei der Ausführung aufgrund einer ungültigen Konfiguration. |
CLOUD_FAILURE |
Fehler bei der Ausführung aufgrund eines Cloudanbieterproblems. |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
Die Ausführung wurde aufgrund des Grenzwerts der Warteschlangengröße auf Auftragsebene übersprungen. |