Vorbereiten von Daten mit Datenwrangling
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Mittels Datenwrangling in Data Factory können Sie interaktive Power Query-Mash-ups nativ in ADF erstellen und dann im großen Stil in einer ADF-Pipeline ausführen.
Erstellen einer Power Query-Aktivität
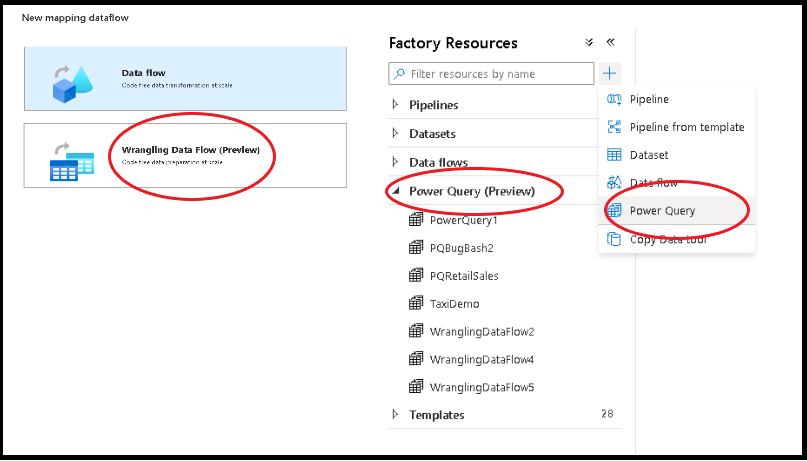
Eine Power Query kann in Azure Data Factory auf zwei Arten erstellt werden. Bei der einen Methode klicken Sie auf das Plussymbol und wählen im Bereich mit den Factory-Ressourcen die Option Power Query aus.
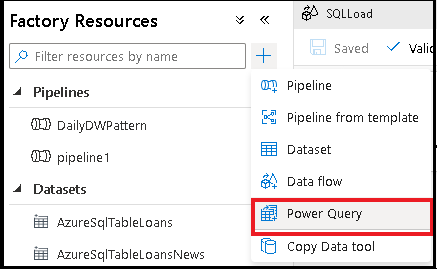
Die andere Möglichkeit befindet sich im Bereich „Aktivitäten“ der Pipelinecanvas. Öffnen Sie das Accordion-Element Power Query, und ziehen Sie die Power Query-Aktivität auf die Canvas.
Erstellen einer Power Query-Datenwranglingaktivität
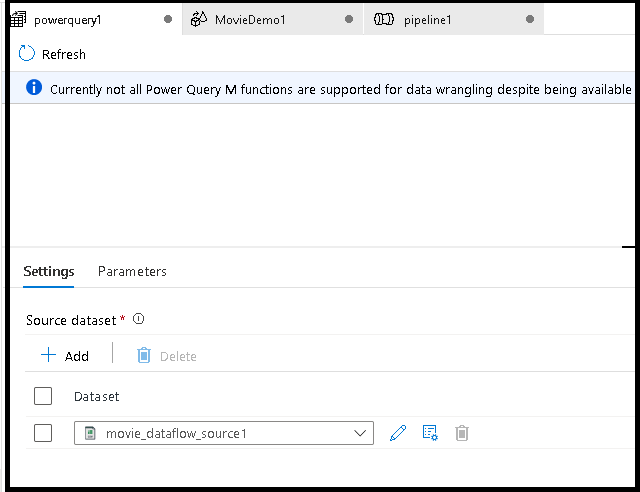
Fügen Sie ein Quelldataset für Ihr Power Query-Mash-Up hinzu. Wählen Sie entweder ein vorhandenes Dataset aus, oder erstellen Sie ein neues. Nachdem Sie Ihr Mashup gespeichert haben, können Sie eine Pipeline erstellen, die Data Wrangling-Aktivität von Power Query Ihrer Pipeline hinzufügen und ein Senkendataset auswählen, um ADF mitzuteilen, wohin Ihre Daten gelangen sollen. Sie können zwar ein oder mehrere Quelldatasets auswählen, doch ist derzeit nur eine Senke zulässig. Die Auswahl eines Senkendatasets ist optional, aber es ist mindestens ein Quelldataset erforderlich.
Klicken Sie auf Erstellen, um den Power Query Online-Mashup-Editor zu öffnen.
Zunächst wählen Sie eine Datasetquelle für den Mashup-Editor aus.
Nachdem Sie Ihre Power Query erstellt haben, können Sie sie speichern und dann eine Pipeline erstellen. Sie müssen das Mashup Ihrer Pipeline als Aktivität hinzufügen. Dann erstellen/wählen Sie das Senkendataset aus, in das Ihre Daten gelangen sollen. Sie können die Eigenschaften des Senkendatasets auch festlegen, indem Sie auf die zweite Schaltfläche rechts neben dem Senkendataset klicken. Denken Sie daran, die „Partitionsoption“ unter „Optimieren“ in „Einzelne Partition“ zu ändern, wenn Sie nur eine einzelne Ausgabedatei abrufen möchten.
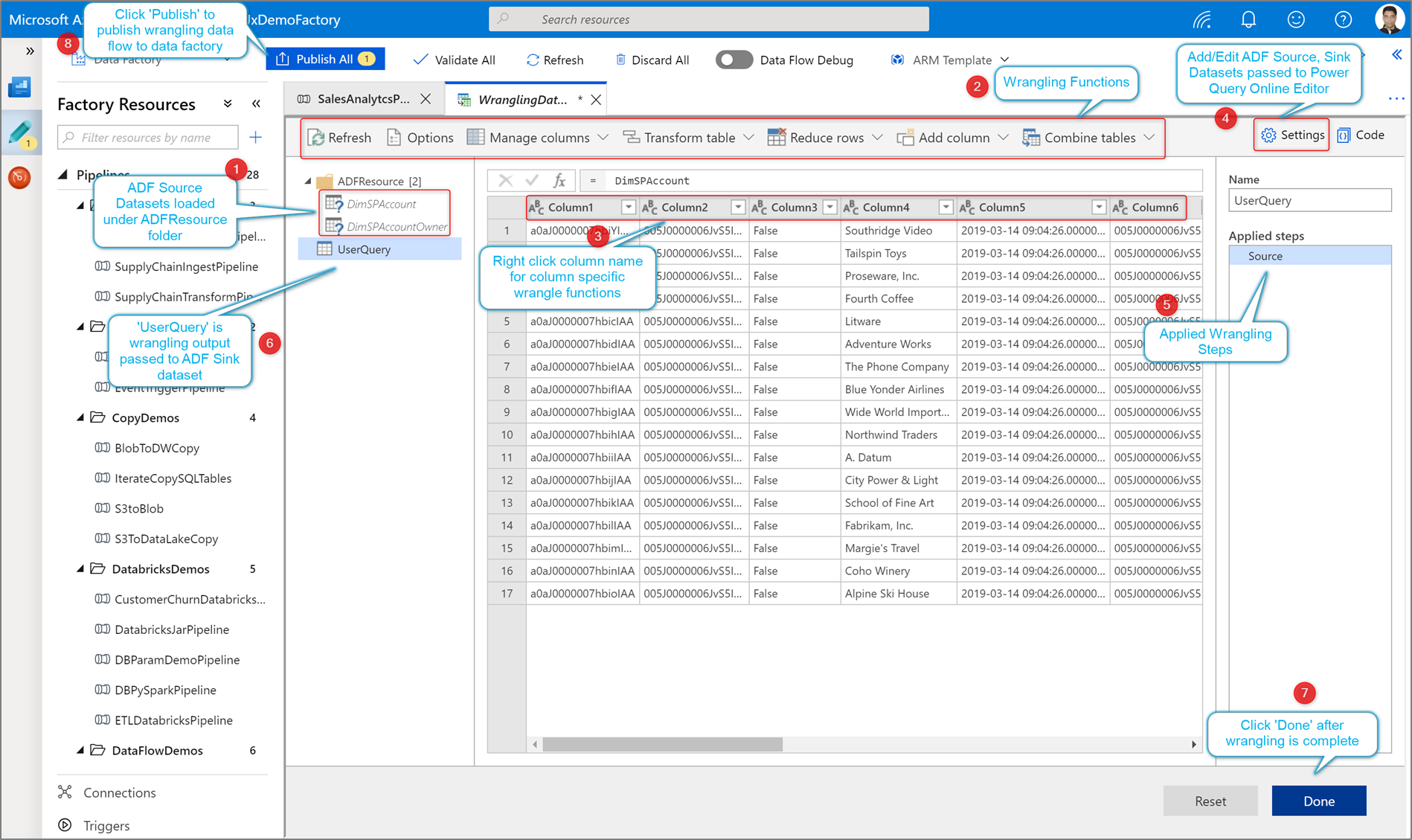
Erstellen Sie Ihre Wrangling-Power Query mithilfe der codefreien Datenvorbereitung. Die Liste der verfügbaren Funktionen finden Sie unter Transformationsfunktionen. ADF übersetzt das M-Skript in ein Datenflussskript, sodass Sie Ihre Power Query im großen Stil mithilfe der Azure Data Factory-Datenfluss-Spark-Umgebung ausführen können.
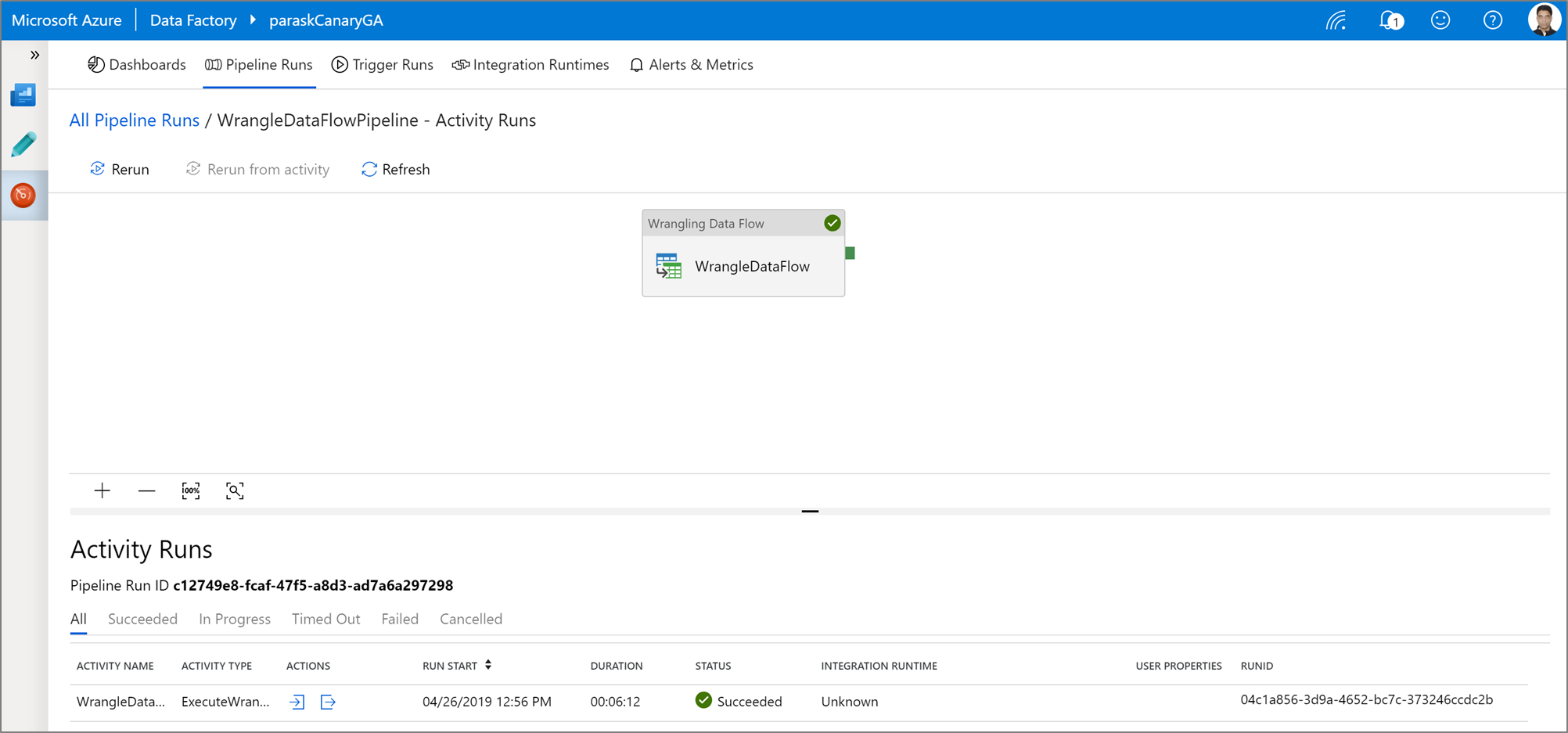
Ausführen und Überwachen einer Power Query-Datenwranglingaktivität
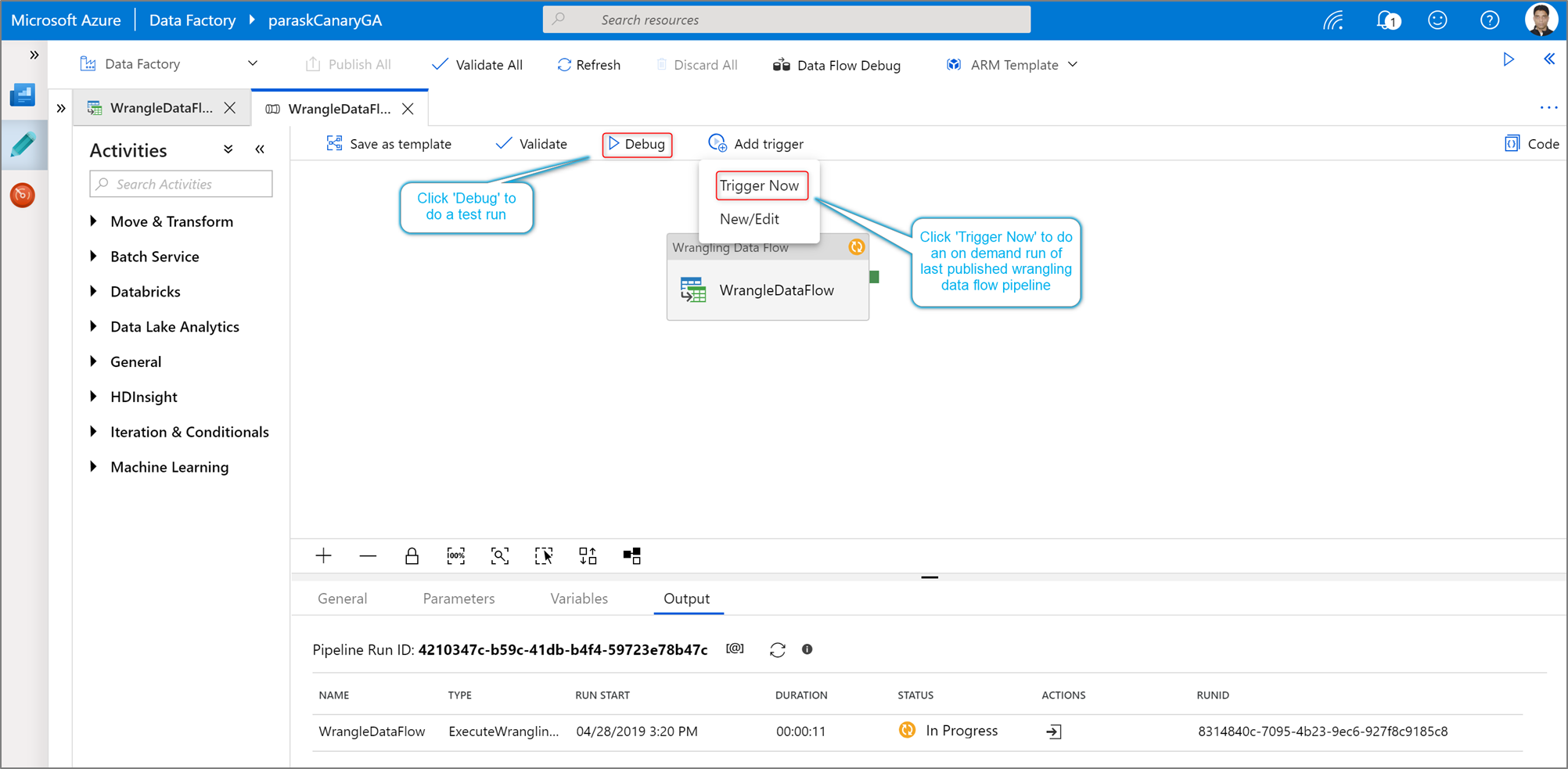
Um eine Ausführung einer Power Query-Aktivität zum Debuggen einer Pipeline zu starten, klicken Sie in der Pipelinecanvas auf Debuggen. Nachdem Sie Ihre Pipeline veröffentlicht haben, können Sie mit Jetzt auslösen eine bedarfsgesteuerte Ausführung der letzten veröffentlichten Pipeline durchführen. Power Query-Pipelines können mit allen vorhandenen Azure Data Factory-Triggern geplant werden.
Wechseln Sie zur Registerkarte Überwachen, um die Ausgabe einer ausgelösten Power Query-Aktivität zu visualisieren.
Zugehöriger Inhalt
Erfahren Sie, wie Sie einen Zuordnungsdatenfluss erstellen.