Inkrementelles Laden von Daten aus Azure SQL-Datenbank in Azure Blob Storage mit Informationen der Änderungsnachverfolgung und PowerShell
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial erstellen Sie eine Azure Data Factory mit einer Pipeline, die Deltadaten basierend auf Informationen der Änderungsnachverfolgung in der Quelldatenbank in Azure SQL-Datenbank als Quelle in Azure Blob Storage lädt.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Vorbereiten des Quelldatenspeichers
- Erstellen einer Data Factory.
- Erstellen Sie verknüpfte Dienste.
- Erstellen von Datasets für Quelle, Senke und Änderungsnachverfolgung
- Erstellen, Ausführen und Überwachen der vollständigen Kopierpipeline
- Hinzufügen oder Aktualisieren von Daten in der Quelltabelle
- Erstellen, Ausführen und Überwachen der inkrementellen Kopierpipeline
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Übersicht
In einer Datenintegrationslösung ist das inkrementelle Laden von Daten nach anfänglichen vollständigen Ladevorgängen ein häufig verwendetes Szenario. In einigen Fällen können die geänderten Daten für einen Zeitraum Ihres Quelldatenspeichers leicht aufgeteilt werden (z.B. LastModifyTime, CreationTime). Manchmal gibt es keine explizite Möglichkeit, die Deltadaten seit der letzten Verarbeitung der Daten zu identifizieren. Die Technologie für die Änderungsnachverfolgung, die von Datenspeichern unterstützt wird, z.B. Azure SQL-Datenbank und SQL Server, kann zum Identifizieren der Deltadaten verwendet werden. In diesem Tutorial wird beschrieben, wie Sie Azure Data Factory zusammen mit der SQL-Technologie für die Änderungsnachverfolgung nutzen, um Deltadaten inkrementell aus Azure SQL-Datenbank in Azure Blob Storage zu laden. Konkretere Informationen zur SQL-Technologie für die Änderungsnachverfolgung finden Sie unter Informationen zur Änderungsnachverfolgung (SQL Server).
Kompletter Workflow
Hier sind die Schritte des typischen End-to-End-Workflows zum inkrementellen Laden von Daten per Technologie für die Änderungsnachverfolgung angegeben.
Hinweis
Diese Technologie wird sowohl von Azure SQL-Datenbank als auch von SQL Server unterstützt. In diesem Tutorial wird Azure SQL-Datenbank als Quelldatenspeicher verwendet. Sie können auch eine SQL Server-Instanz verwenden.
- Initial loading of historical data (Erstes Laden von Verlaufsdaten) (einmalige Ausführung):
- Aktivieren Sie die Technologie für die Änderungsnachverfolgung in der Quelldatenbank in Azure SQL-Datenbank.
- Rufen Sie den Anfangswert von SYS_CHANGE_VERSION in der Datenbank als Baseline zum Erfassen von geänderten Daten ab.
- Laden Sie die vollständigen Daten aus der Quelldatenbank in Azure Blob Storage.
- Incremental loading of delta data on a schedule (Inkrementelles Laden von Deltadaten nach einem Zeitplan) (regelmäßige Ausführung nach dem ersten Laden der Daten):
- Rufen Sie die alten und neuen SYS_CHANGE_VERSION-Werte ab.
- Laden Sie die Deltadaten, indem Sie die Primärschlüssel von geänderten Zeilen (zwischen zwei SYS_CHANGE_VERSION-Werten) aus sys.change_tracking_tables mit Daten in der Quelltabelle verknüpfen, und verschieben Sie die Deltadaten dann auf das Ziel.
- Aktualisieren Sie SYS_CHANGE_VERSION für das nächste Deltaladen.
Allgemeine Lösung
In diesem Tutorial erstellen Sie zwei Pipelines, mit denen die folgenden beiden Vorgänge durchgeführt werden:
Erstes Laden: : Sie erstellen eine Pipeline mit einer Kopieraktivität, bei der die gesamten Daten aus dem Quelldatenspeicher (Azure SQL-Datenbank) in den Zieldatenspeicher (Azure Blob Storage) kopiert werden.

Inkrementell laden: Sie erstellen eine Pipeline mit den folgenden Aktivitäten und führen sie regelmäßig aus.
- Erstellen Sie zwei Lookup-Aktivitäten, um die alte und neue SYS_CHANGE_VERSION aus Azure SQL-Datenbank abzurufen und an die Kopieraktivität zu übergeben.
- Erstellen Sie eine Kopieraktivität, um die eingefügten/aktualisierten/gelöschten Daten zwischen den beiden SYS_CHANGE_VERSION-Werten aus Azure SQL-Datenbank nach Azure Blob Storage zu kopieren.
- Erstellen Sie eine Aktivität „Gespeicherte Prozedur“ , um den Wert von SYS_CHANGE_VERSION für die nächste Pipelineausführung zu aktualisieren.

Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
- Azure PowerShell. Installieren Sie die aktuellen Azure PowerShell-Module, indem Sie die Anweisungen unter Installieren und Konfigurieren von Azure PowerShell befolgen.
- Azure SQL-Datenbank. Sie verwenden die Datenbank als den Quell-Datenspeicher. Wenn Sie in Azure SQL-Datenbank noch keine Datenbank haben, lesen Sie den Artikel Erstellen einer Datenbank in Azure SQL-Datenbank. Dort finden Sie die erforderlichen Schritte zum Erstellen einer solchen Datenbank.
- Azure Storage-Konto. Sie verwenden den Blob Storage als den Senken-Datenspeicher. Wenn Sie kein Azure Storage-Konto besitzen, finden Sie im Artikel Erstellen eines Speicherkontos Schritte zum Erstellen eines solchen Kontos. Erstellen Sie einen Container mit dem Namen Adftutorial.
Erstellen einer Datenquellentabelle in Ihrer Datenbank
Starten Sie SQL Server Management Studio, und stellen Sie eine Verbindung mit SQL-Datenbank her.
Klicken Sie im Server-Explorer mit der rechten Maustaste auf Ihre Datenbank, und wählen Sie Neue Abfrage.
Führen Sie den folgenden SQL-Befehl für Ihre Datenbank aus, um eine Tabelle mit dem Namen
data_source_tableals Datenquellenspeicher zu erstellen.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Aktivieren Sie den Mechanismus für die Änderungsnachverfolgung in Ihrer Datenbank und der Quelltabelle (data_source_table), indem Sie die folgende SQL-Abfrage ausführen:
Hinweis
- Ersetzen Sie <your database name> durch den Namen Ihrer Datenbank, in der „data_source_table“ enthalten ist.
- Im aktuellen Beispiel werden die geänderten Daten zwei Tage lang aufbewahrt. Wenn Sie die geänderten Daten für drei oder mehr Tage laden, sind einige geänderte Daten nicht enthalten. Eine Möglichkeit besteht darin, den Wert von CHANGE_RETENTION zu erhöhen. Alternativ dazu können Sie sicherstellen, dass Ihr Zeitraum für das Laden der geänderten Daten nicht mehr als zwei Tage beträgt. Weitere Informationen finden Sie unter Aktivieren der Änderungsnachverfolgung für eine Datenbank.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Erstellen Sie eine neue Tabelle, und speichern Sie „ChangeTracking_version“ mit einem Standardwert, indem Sie die folgende Abfrage ausführen:
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Hinweis
Wenn sich die Daten nach dem Aktivieren der Änderungsnachverfolgung für SQL-Datenbank nicht geändert haben, lautet der Wert für die Version der Änderungsnachverfolgung „0“.
Führen Sie die folgende Abfrage zum Erstellen einer gespeicherten Prozedur in Ihrer Datenbank aus. Die Pipeline ruft diese gespeicherte Prozedur auf, um die Version der Änderungsnachverfolgung in der Tabelle zu aktualisieren, die Sie im vorherigen Schritt erstellt haben.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Installieren Sie die aktuellen Azure PowerShell-Module, indem Sie die Anweisungen unter Installieren und Konfigurieren von Azure PowerShell befolgen.
Erstellen einer Data Factory
Definieren Sie eine Variable für den Ressourcengruppennamen zur späteren Verwendung in PowerShell-Befehlen. Kopieren Sie den folgenden Befehlstext nach PowerShell, geben Sie einen Namen für die Azure-Ressourcengruppe in doppelten Anführungszeichen an, und führen Sie dann den Befehl aus. Beispiel:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Beachten Sie, dass die Ressourcengruppe ggf. nicht überschrieben werden soll, falls sie bereits vorhanden ist. Weisen Sie der Variablen
$resourceGroupNameeinen anderen Wert zu, und führen Sie den Befehl erneut aus.Definieren Sie eine Variable für den Speicherort der Data Factory:
$location = "East US"Führen Sie den folgenden Befehl aus, um die Azure-Ressourcengruppe zu erstellen:
New-AzResourceGroup $resourceGroupName $locationBeachten Sie, dass die Ressourcengruppe ggf. nicht überschrieben werden soll, falls sie bereits vorhanden ist. Weisen Sie der Variablen
$resourceGroupNameeinen anderen Wert zu, und führen Sie den Befehl erneut aus.Definieren Sie eine Variable für den Namen der Data Factory.
Wichtig
Aktualisieren Sie den Data Factory-Namen, damit er global eindeutig ist.
$dataFactoryName = "IncCopyChgTrackingDF";Führen Sie zum Erstellen der Data Factory das Cmdlet Set-AzDataFactoryV2 wie folgt aus:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Beachten Sie folgende Punkte:
Der Name der Azure Data Factory muss global eindeutig sein. Wenn die folgende Fehlermeldung angezeigt wird, ändern Sie den Namen, und wiederholen Sie den Vorgang.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Damit Sie Data Factory-Instanzen erstellen können, muss das Benutzerkonto, mit dem Sie sich bei Azure anmelden, ein Mitglied der Rolle Mitwirkender oder Besitzer oder ein Administrator des Azure-Abonnements sein.
Eine Liste der Azure-Regionen, in denen Data Factory derzeit verfügbar ist, finden Sie, indem Sie die für Sie interessanten Regionen auf der folgenden Seite auswählen und dann Analysen erweitern, um Data Factory zu finden: Verfügbare Produkte nach Region. Die von der Data Factory verwendeten Datenspeicher (Azure Storage, Azure SQL-Datenbank usw.) und Computedienste (HDInsight usw.) können sich in anderen Regionen befinden.
Erstellen von verknüpften Diensten
Um Ihre Datenspeicher und Compute Services mit der Data Factory zu verknüpfen, können Sie verknüpfte Dienste in einer Data Factory erstellen. In diesem Abschnitt erstellen Sie verknüpfte Dienste mit Ihrem Azure Storage-Konto und mit Ihrer Datenbank in Azure SQL-Datenbank.
Erstellen des verknüpften Azure Storage-Diensts.
In diesem Schritt verknüpfen Sie Ihr Azure Storage-Konto mit der Data Factory.
Erstellen Sie eine JSON-Datei mit dem Namen AzureStorageLinkedService.json im Ordner C:\ADFTutorials\IncCopyChangeTrackingTutorial und dem folgenden Inhalt: (Erstellen Sie den Ordner, falls er noch nicht vorhanden ist.) Ersetzen Sie
<accountName>und<accountKey>durch den Namen bzw. Schlüssel Ihres Azure Storage-Kontos, bevor Sie die Datei speichern.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }Wechseln Sie in Azure PowerShell zum Ordner C:\ADFTutorials\IncCopyChangeTrackingTutorial.
Führen Sie das Cmdlet Set-AzDataFactoryV2LinkedService aus, um den verknüpften Dienst zu erstellen: AzureStorageLinkedService. Im folgenden Beispiel, übergeben Sie Werte für die ResourceGroupName- und DataFactoryName-Parameter.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Hier ist die Beispielausgabe:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Erstellen Sie einen Azure SQL-Datenbank -verknüpften Dienst.
In diesem Schritt verknüpfen Sie Ihre Datenbank mit der Data Factory.
Erstellen Sie eine JSON-Datei mit dem Namen AzureSQLDatabaseLinkedService.json im Ordner C:\ADFTutorials\IncCopyChangeTrackingTutorial mit dem folgenden Inhalt: Ersetzen Sie dabei <your-server-name> und <your-database-name> durch den Namen Ihres Servers und Ihrer Datenbank, bevor Sie die Datei speichern. Sie müssen außerdem Ihre Azure SQL Server-Instanz so konfigurieren, dass Zugriff auf die verwaltete Identität Ihrer Datenfactory gewährt wird.
{ "name": "AzureSqlDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server=tcp:<your-server-name>.database.windows.net,1433;Database=<your-database-name>;" }, "authenticationType": "ManagedIdentity", "annotations": [] } }Führen Sie in Azure PowerShell das Cmdlet Set-AzDataFactoryV2LinkedService aus, um den verknüpften Dienst zu erstellen: AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Hier ist die Beispielausgabe:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Erstellen von Datasets
In diesem Schritt erstellen Sie Datasets, die für die Datenquelle, das Datenziel und den Ort zum Speichern der SYS_CHANGE_VERSION stehen.
Erstellen eines Quelldatasets
In diesem Schritt erstellen Sie ein Dataset, das für die Quelldaten steht.
Erstellen Sie eine JSON-Datei mit dem Namen „SourceDataset.json“ im selben Ordner und dem folgenden Inhalt:
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Führen Sie das Cmdlet „Set-AzDataFactoryV2Dataset“ aus, um das Dataset zu erstellen: SourceDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Hier ist die Beispielausgabe des Cmdlets:
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Erstellen Sie ein Senkendataset
In diesem Schritt erstellen Sie ein Dataset, das für die Daten steht, die aus dem Quelldatenspeicher kopiert werden.
Erstellen Sie eine JSON-Datei mit dem Namen „SinkDataset.json“ im selben Ordner und dem folgenden Inhalt:
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }Sie erstellen den Container „adftutorial“ in Ihrer Azure Blob Storage-Instanz im Rahmen der Erfüllung der Voraussetzungen. Erstellen Sie den Container, wenn er noch nicht vorhanden ist (oder) geben Sie den Namen eines bereits vorhandenen ein. In diesem Tutorial wird der Name der Ausgabedatei dynamisch generiert, indem der folgende Ausdruck verwendet wird: @CONCAT(('Incremental-', pipeline().RunId, '.txt').
Führen Sie das Cmdlet „Set-AzDataFactoryV2Dataset“ aus, um das Dataset zu erstellen: SinkDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Hier ist die Beispielausgabe des Cmdlets:
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Erstellen eines Datasets für die Änderungsnachverfolgung
In diesem Schritt erstellen Sie ein Dataset zum Speichern der Version für die Änderungsnachverfolgung.
Erstellen Sie in demselben Ordner eine JSON-Datei mit dem Namen „ChangeTrackingDataset.json“ und folgendem Inhalt:
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Sie erstellen die Tabelle „table_store_ChangeTracking_version“ im Rahmen der Erfüllung der Voraussetzungen.
Führen Sie das Cmdlet „Set-AzDataFactoryV2Dataset“ aus, um das Dataset zu erstellen: ChangeTrackingDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Hier ist die Beispielausgabe des Cmdlets:
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Erstellen einer Pipeline für den vollständigen Kopiervorgang
In diesem Schritt erstellen Sie eine Pipeline mit einer Kopieraktivität, bei der die gesamten Daten aus dem Quelldatenspeicher (Azure SQL-Datenbank) in den Zieldatenspeicher (Azure Blob Storage) kopiert werden.
Erstellen Sie die JSON-Datei „FullCopyPipeline.json“ im gleichen Ordner, aber mit folgendem Inhalt:
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Führen Sie das Cmdlet „Set-AzDataFactoryV2Pipeline“ aus, um die Pipeline zu erstellen: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Hier ist die Beispielausgabe:
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Ausführen der vollständigen Kopierpipeline
Führen Sie die Pipeline FullCopyPipeline mithilfe des Cmdlets Invoke-AzDataFactoryV2Pipeline aus.
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Überwachen der vollständigen Kopierpipeline
Melden Sie sich beim Azure-Portal an.
Klicken Sie auf Alle Dienste, führen Sie eine Suche mit dem Schlüsselwort
data factoriesdurch, und wählen Sie Data Factorys aus.
Suchen Sie in der Liste mit den Data Factorys nach Ihrer Data Factory, und wählen Sie sie aus, um die Seite „Data Factory“ anzuzeigen.
Klicken Sie auf der Seite für die Data Factory auf die Kachel Überwachung und Verwaltung.
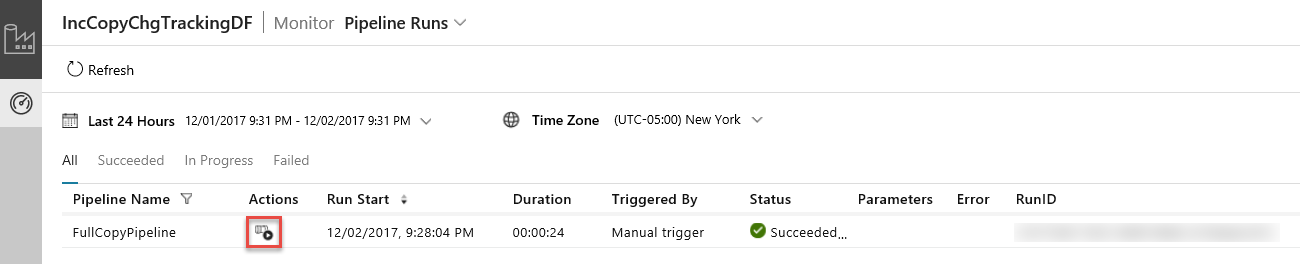
Die Anwendung für die Datenintegration wird in einer separaten Registerkarte gestartet. Alle Pipelineausführungen mit dem dazugehörigen Status werden angezeigt. Beachten Sie, dass der Status der Pipelineausführung im folgenden Beispiel Erfolgreich lautet. Sie können die an die Pipeline übergebenen Parameter überprüfen, indem Sie in der Spalte Parameter auf den Link klicken. Wenn ein Fehler auftritt, wird in der Spalte Fehler ein Link angezeigt. Klicken Sie in der Spalte Aktionen auf den Link.
Wenn Sie in der Spalte Aktionen auf den Link klicken, wird die folgende Seite mit allen Aktivitätsausführungen der Pipeline angezeigt.
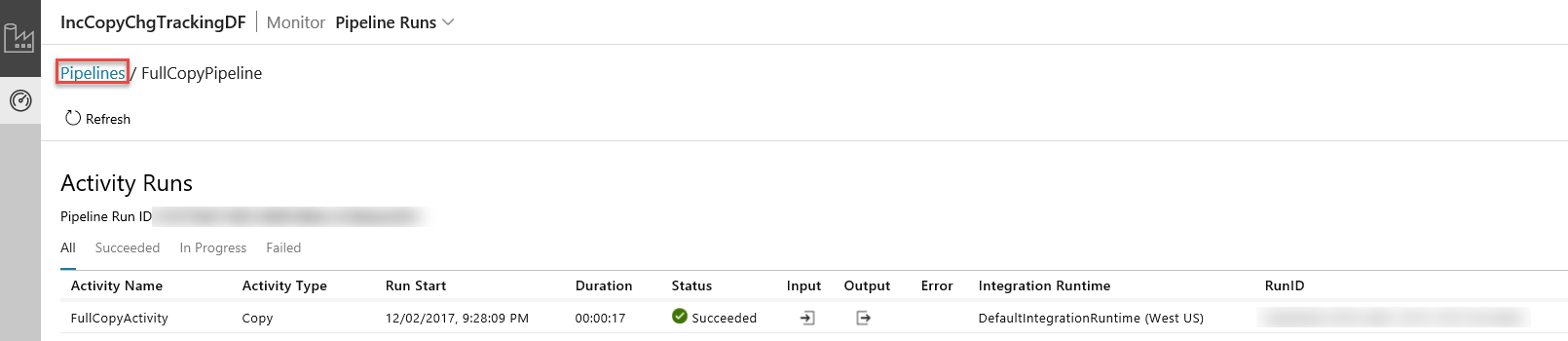
Klicken Sie wie in der Abbildung dargestellt auf Pipelines, um zurück zur Ansicht Pipelineausführungen zu wechseln.
Überprüfen der Ergebnisse
Im Ordner incchgtracking des Containers adftutorial wird eine Datei mit dem Namen incremental-<GUID>.txt angezeigt.
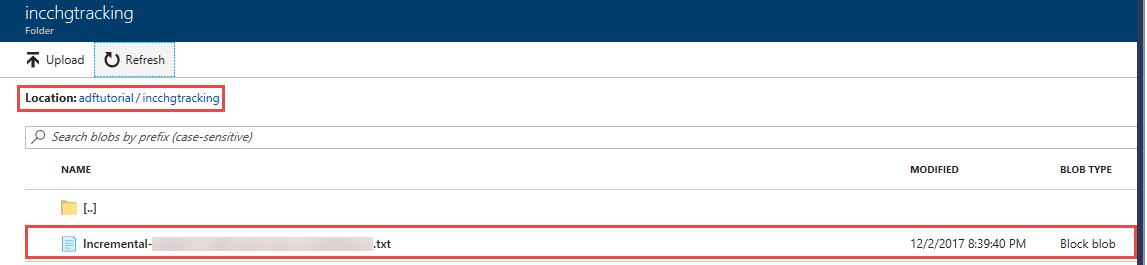
Die Datei sollte die Daten aus Ihrer Datenbank enthalten:
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Hinzufügen von weiteren Daten zur Quelltabelle
Führen Sie die folgende Abfrage für Ihre Datenbank aus, um eine Zeile hinzuzufügen und eine Zeile zu aktualisieren.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Erstellen einer Pipeline für die Deltakopie
In diesem Schritt erstellen Sie eine Pipeline mit den folgenden Aktivitäten und führen sie regelmäßig aus. Mit den Lookup-Aktivitäten wird die alte und neue SYS_CHANGE_VERSION aus Azure SQL-Datenbank abgerufen und an die Kopieraktivität übergeben. Die Kopieraktivität kopiert die eingefügten/aktualisierten/gelöschten Daten zwischen den beiden SYS_CHANGE_VERSION-Werten aus Azure SQL-Datenbank nach Azure Blob Storage. Die Aktivität „Gespeicherte Prozedur“ aktualisiert den Wert von SYS_CHANGE_VERSION für die nächste Pipelineausführung.
Erstellen Sie die JSON-Datei „IncrementalCopyPipeline.json“ im gleichen Ordner, aber mit folgendem Inhalt:
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Führen Sie das Cmdlet „Set-AzDataFactoryV2Pipeline“ aus, um die Pipeline zu erstellen: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Hier ist die Beispielausgabe:
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
Ausführen der inkrementellen Kopierpipeline
Führen Sie die Pipeline IncrementalCopyPipeline mithilfe des Cmdlets Invoke-AzDataFactoryV2Pipeline aus.
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Überwachen der inkrementellen Kopierpipeline
Aktualisieren Sie in der Anwendung für die Datenintegration die Ansicht Pipelineausführungen. Vergewissern Sie sich, dass „IncrementalCopyPipeline“ in der Liste enthalten ist. Klicken Sie in der Spalte Aktionen auf den Link.
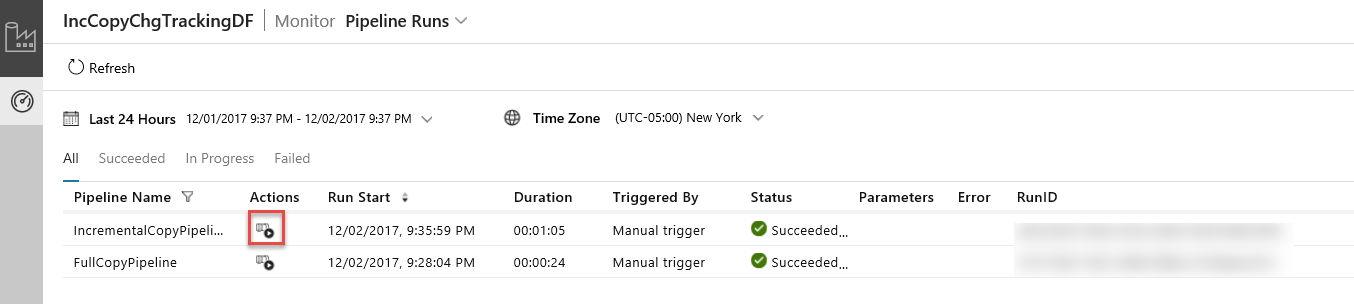
Wenn Sie in der Spalte Aktionen auf den Link klicken, wird die folgende Seite mit allen Aktivitätsausführungen der Pipeline angezeigt.
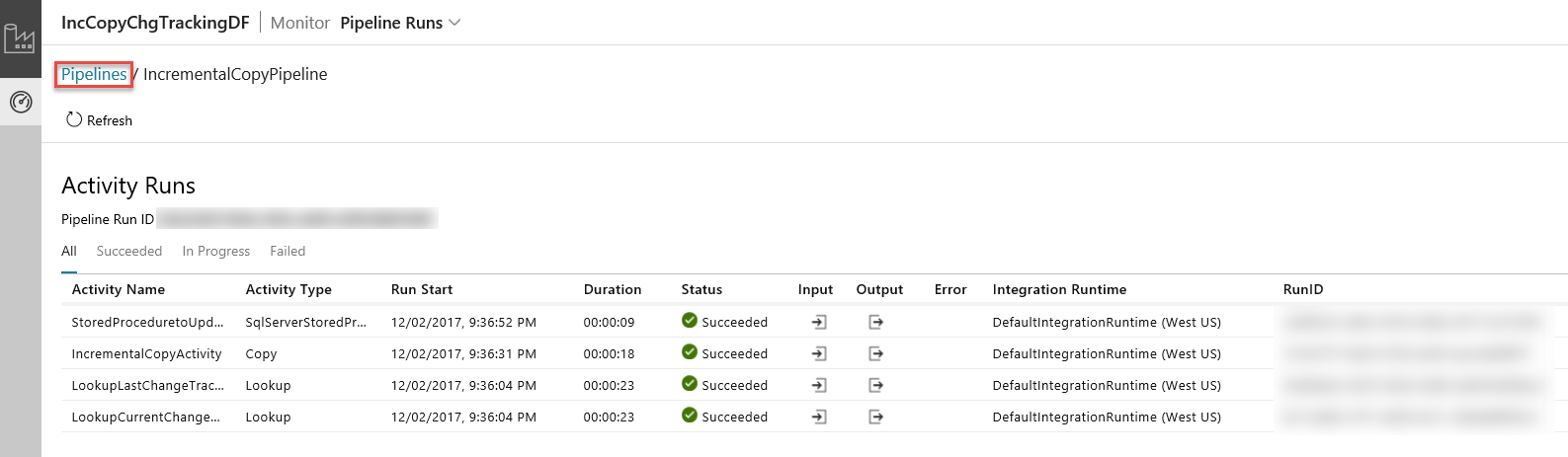
Klicken Sie wie in der Abbildung dargestellt auf Pipelines, um zurück zur Ansicht Pipelineausführungen zu wechseln.
Überprüfen der Ergebnisse
Die zweite Datei ist im Ordner incchgtracking des Containers adftutorial enthalten.
Die Datei sollte nur die Deltadaten aus Ihrer Datenbank enthalten. Der Datensatz mit der Kennzeichnung U ist die aktualisierte Zeile in der Datenbank, und mit I wird die hinzugefügte Zeile angegeben.
1,update,10,2,U
6,new,50,1,I
Die ersten drei Spalten enthalten geänderte Daten aus „data_source_table“. Die letzten beiden Spalten enthalten die Metadaten aus der Systemtabelle für die Änderungsnachverfolgung. Die vierte Spalte enthält die SYS_CHANGE_VERSION für die einzelnen geänderten Zeilen. Die fünfte Spalte enthält den Vorgang: U = update (aktualisieren), I = insert (einfügen). Weitere Informationen zu den Informationen zur Änderungsnachverfolgung finden Sie unter CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Zugehöriger Inhalt
Im folgenden Tutorial erfahren Sie mehr über das Kopieren von neuen und geänderten Dateien nur auf Grundlage ihres LastModifiedDate-Werts: