Kopieren von Daten aus Azure Blob Storage in eine Datenbank in Azure SQL-Datenbank mithilfe von Azure Data Factory
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial erstellen Sie eine Data Factory über die Azure Data Factory-Benutzeroberfläche (User Interface, UI). Die Pipeline in dieser Data Factory kopiert Daten aus Azure Blob Storage in eine Datenbank in Azure SQL-Datenbank. Das Konfigurationsmuster in diesem Tutorial gilt für Kopiervorgänge aus einem dateibasierten Datenspeicher in einen relationalen Datenspeicher. Eine Liste der Datenspeicher, die als Quellen und Senken unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Hinweis
Falls Sie noch nicht mit Data Factory vertraut sind, ist es ratsam, den Artikel Einführung in Azure Data Factory zu lesen.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory.
- Erstellen einer Pipeline mit einer Copy-Aktivität
- Ausführen eines Testlaufs für die Pipeline
- Manuelles Auslösen der Pipeline
- Auslösen der Pipeline nach einem Zeitplan
- Überwachen der Pipeline- und Aktivitätsausführungen.
Voraussetzungen
- Azure-Abonnement. Wenn Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Azure-Konto erstellen, bevor Sie beginnen.
- Azure-Speicherkonto. Sie verwenden Blob Storage als Quelldatenspeicher. Wenn Sie kein Speicherkonto besitzen, finden Sie unter Informationen zu Azure-Speicherkonten Schritte zum Erstellen eines solchen Kontos.
- Azure SQL-Datenbank. Sie verwenden die Datenbank als Senkendatenspeicher. Wenn Sie in Azure SQL-Datenbank noch keine Datenbank haben, lesen Sie Erstellen einer Datenbank in Azure SQL-Datenbank. Dort finden Sie die erforderlichen Schritte zum Erstellen einer solchen Datenbank.
Erstellen eines Blobs und einer SQL-Tabelle
Nun bereiten Sie Ihre Blob Storage-Instanz und SQL-Datenbank durch Ausführen der folgenden Schritte auf das Tutorial vor:
Erstellen eines Quellblobs
Starten Sie den Editor. Kopieren Sie den folgenden Text, und speichern Sie ihn als emp.txt-Datei auf einem Datenträger:
FirstName,LastName John,Doe Jane,DoeErstellen Sie in Blob Storage einen Container mit dem Namen adftutorial. Erstellen Sie einen Ordner namens input in diesem Container. Laden Sie anschließend die Datei emp.txt in den Ordner input hoch. Verwenden Sie für diese Aufgaben das Azure-Portal oder Tools wie Azure Storage-Explorer.
Erstellen einer SQL-Senkentabelle
Verwenden Sie das folgende SQL-Skript zum Erstellen der Tabelle dbo.emp in Ihrer Datenbank:
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);Gewähren Sie Azure-Diensten den Zugriff auf SQL Server. Stellen Sie sicher, dass die Einstellung Zugriff auf Azure-Dienste erlauben für Ihre SQL Server-Instanz aktiviert ist, damit Data Factory Daten in diese SQL Server-Instanz schreiben kann. Wenn Sie diese Einstellung überprüfen und aktivieren möchten, navigieren Sie auf dem logischen SQL-Server zu „Übersicht“ > „Serverfirewall festlegen“, und legen Sie die Option Zugriff auf Azure-Dienste zulassen auf EIN fest.
Erstellen einer Data Factory
In diesem Schritt erstellen Sie eine Data Factory und starten die Data Factory-Benutzeroberfläche, um eine Pipeline in der Data Factory zu erstellen.
Öffnen Sie Microsoft Edge oder Google Chrome. Die Data Factory-Benutzeroberfläche wird zurzeit nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Wählen Sie im Menü auf der linken Seite Ressource erstellen>Integration>Data Factory aus.
Wählen Sie auf der Seite Data Factory erstellen auf der Registerkarte Grundlagen das Azure-Abonnement aus, in dem Sie die Data Factory erstellen möchten.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
a. Wählen Sie in der Dropdownliste eine vorhandene Ressourcengruppe aus.
b. Wählen Sie Neu erstellen aus, und geben Sie den Namen einer neuen Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie unter Region einen Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Die Datenspeicher (etwa Azure Storage und SQL-Datenbank) und Computeeinheiten (etwa Azure HDInsight), die von der Data Factory genutzt werden, können sich in anderen Regionen befinden.
Geben Sie unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Azure Data Factory muss global eindeutigsein. Wenn eine Fehlermeldung zum Namenswert angezeigt wird, geben Sie einen anderen Namen für die Data Factory ein. (Verwenden Sie beispielsweise „IhrNameADFTutorialDataFactory“.) Benennungsregeln für Data Factory-Artefakte finden Sie im Thema Azure Data Factory – Benennungsregeln.
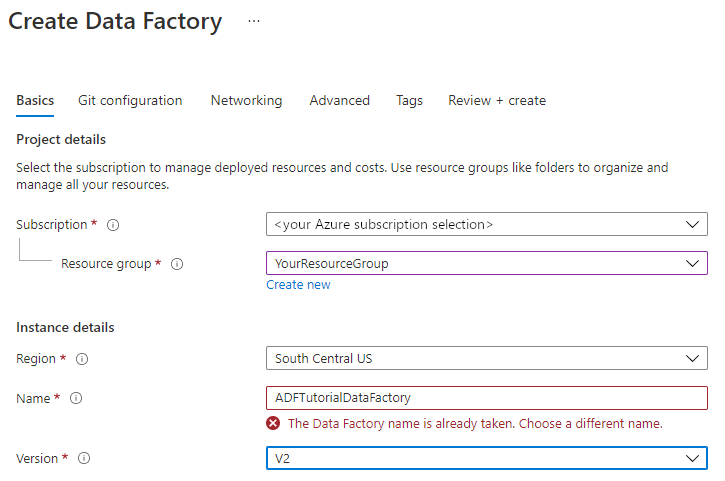
Wählen Sie unter Version die Option V2.
Wählen Sie oben die Registerkarte Git-Konfiguration aus, und aktivieren Sie das Kontrollkästchen Git später konfigurieren.
Wählen Sie Überprüfen und erstellen und nach erfolgreicher Prüfung Erstellen aus.
Nach Abschluss der Erstellung wird der Hinweis im Benachrichtigungscenter angezeigt. Wählen Sie Zu Ressource wechseln aus, um zur Data Factory-Seite zu navigieren.
Wählen Sie auf der Kachel Azure Data Factory Studio öffnen die Option Öffnen aus, um die Azure Data Factory-Benutzeroberfläche in einer separaten Registerkarte zu starten.
Erstellen einer Pipeline
In diesem Schritt erstellen Sie eine Pipeline mit einer Copy-Aktivität in der Data Factory. Die Copy-Aktivität kopiert Daten aus Blob Storage in SQL-Datenbank. Im Schnellstarttutorial haben Sie anhand der folgenden Schritte eine Pipeline erstellt:
- 1\. Erstellen des verknüpften Diensts
- Erstellen von Eingabe- und Ausgabedatasets
- Erstellen einer Pipeline.
In diesem Tutorial beginnen Sie mit dem Erstellen der Pipeline. Verknüpfte Dienste und Datasets erstellen Sie, wenn Sie sie zum Konfigurieren der Pipeline benötigen.
Wählen Sie auf der Startseite die Option Orchestrieren aus.
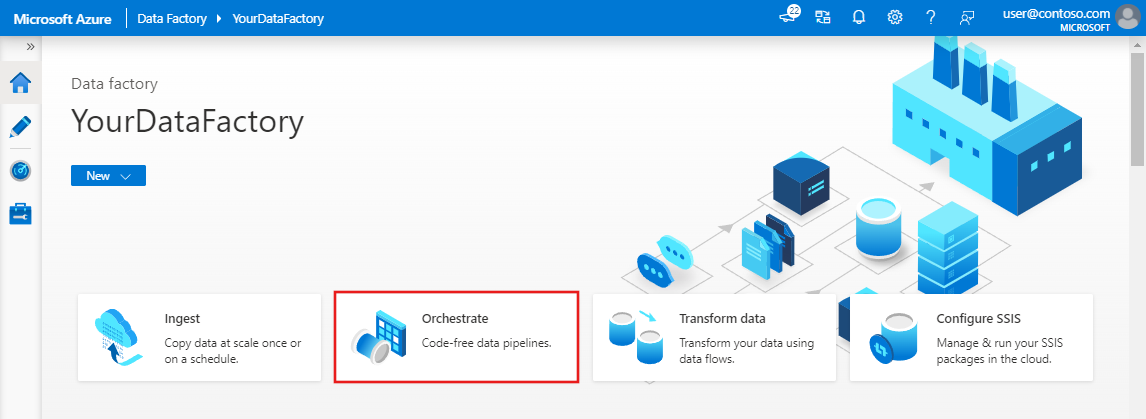
Geben Sie im Bereich „Allgemein“ unter Eigenschaften die Eigenschaft CopyPipeline für Name an. Reduzieren Sie dann den Bereich, indem Sie in der oberen rechten Ecke auf das Symbol „Eigenschaften“ klicken.
Erweitern Sie in der Toolbox Aktivitäten die Kategorie Move and Transform (Verschieben und transformieren), und verschieben Sie die Aktivität Daten kopieren aus der Toolbox auf die Oberfläche des Pipeline-Designers. Geben Sie unter Name den Namen CopyFromBlobToSql ein.
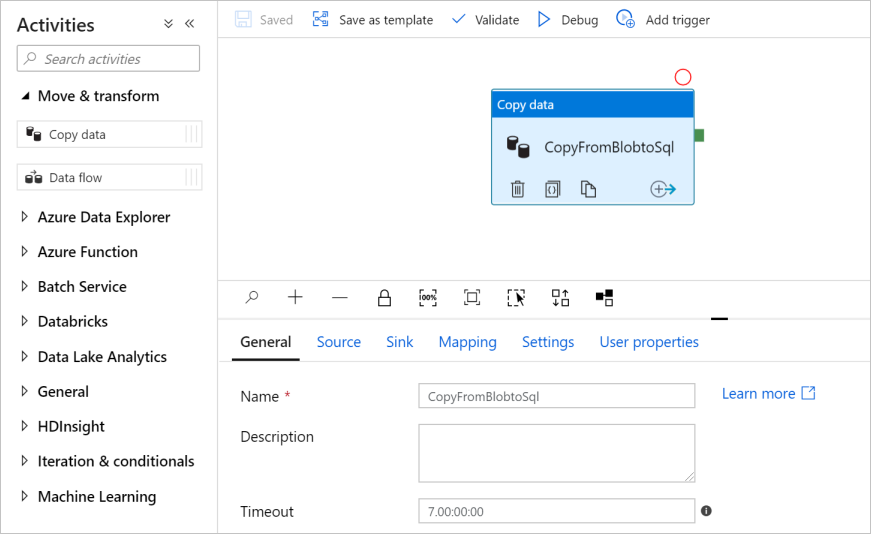
Konfigurieren der Quelle
Tipp
In diesem Tutorial verwenden Sie Kontoschlüssel als Authentifizierungstyp für Ihren Quelldatenspeicher, Sie können bei Bedarf aber auch andere unterstützte Authentifizierungsmethoden auswählen: SAS-URI, Dienstprinzipal und Verwaltete Identität. Ausführlichere Informationen finden Sie in den entsprechenden Abschnitten dieses Artikels. Zum sicheren Speichern von Geheimnissen für Datenspeicher empfiehlt sich darüber hinaus die Verwendung einer Azure Key Vault-Instanz. Eine ausführliche Erläuterung finden Sie in diesem Artikel.
Wechseln Sie zur Registerkarte Quelle. Klicken Sie auf + Neu, um ein Quelldataset zu erstellen.
Wählen Sie im Dialogfeld Neues Dataset die Option Azure Blob Storage und dann Weiter aus. Da sich die Quelldaten in Blob Storage befinden, wählen Sie Azure Blob Storage als Quelldataset aus.
Wählen Sie im Dialogfeld Format auswählen den Formattyp Ihrer Daten und dann Weiter aus.
Geben Sie im Dialogfeld Eigenschaften festlegen als Name SourceBlobDataset ein. Aktivieren Sie das Kontrollkästchen Erste Zeile als Kopfzeile. Klicken Sie unter dem Textfeld Verknüpfter Dienst auf + Neu.
Geben Sie im Dialogfeld New Linked Service (Azure Blob Storage) (Neuer verknüpfter Dienst (Azure Blob Storage)) als Name AzureStorageLinkedService ein, und wählen Sie in der Liste Speicherkontoname Ihr Speicherkonto aus. Testen Sie die Verbindung, und klicken Sie dann auf Erstellen, um den verknüpften Dienst bereitzustellen.
Nach der Erstellung des verknüpften Diensts wird wieder die Seite Eigenschaften festlegen angezeigt. Klicken Sie neben Dateipfad auf Durchsuchen.
Navigieren Sie zum Ordner adftutorial/input, wählen Sie die Datei emp.txt aus, und klicken Sie auf OK.
Klicken Sie auf OK. Die Pipelineseite wird automatisch aufgerufen. Vergewissern Sie sich, dass auf der Registerkarte Quelle die Option SourceBlobDataset ausgewählt ist. Wenn Sie auf dieser Seite eine Vorschau der Daten anzeigen möchten, klicken Sie auf Datenvorschau.
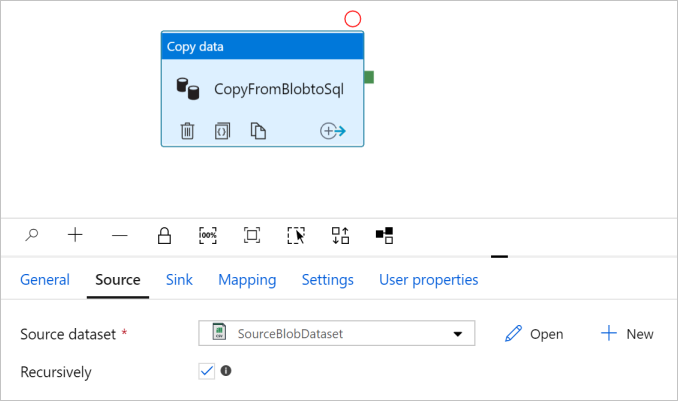
Konfigurieren der Senke
Tipp
In diesem Tutorial verwenden Sie SQL-Authentifizierung als Authentifizierungstyp für Ihren Senkendatenspeicher, Sie können bei Bedarf aber auch andere unterstützte Authentifizierungsmethoden auswählen: Dienstprinzipal und Verwaltete Identität. Ausführlichere Informationen finden Sie in den entsprechenden Abschnitten dieses Artikels. Zum sicheren Speichern von Geheimnissen für Datenspeicher empfiehlt sich darüber hinaus die Verwendung einer Azure Key Vault-Instanz. Eine ausführliche Erläuterung finden Sie in diesem Artikel.
Wechseln Sie zur Registerkarte Senke, und klicken Sie auf + Neu, um ein Senkendataset zu erstellen.
Geben Sie im Dialogfeld Neues Dataset in das Suchfeld „SQL“ ein, um die Connectors zu filtern. Wählen Sie anschließend Azure SQL-Datenbank und dann Weiter aus. In diesem Tutorial kopieren Sie Daten in eine SQL-Datenbank.
Geben Sie im Dialogfeld Eigenschaften festlegen als Name OutputSqlDataset ein. Klicken Sie in der Dropdownliste Verknüpfter Dienst auf + Neu. Einem verknüpften Dienst muss ein Dataset zugewiesen werden. Der verknüpfte Dienst enthält die Verbindungszeichenfolge, die Data Factory zum Herstellen einer Verbindung mit Azure SQL-Datenbank zur Laufzeit verwendet. Das Dataset gibt den Container, den Ordner und (optional) die Datei an, in die die Quelldaten kopiert werden.
Führen Sie im Dialogfeld New Linked Service (Azure SQL Database) (Neuer verknüpfter Dienst (Azure SQL-Datenbank)) die folgenden Schritte aus:
a. Geben Sie unter Name den Namen AzureSqlDatabaseLinkedService ein.
b. Wählen Sie unter Servername Ihre SQL Server-Instanz aus.
c. Wählen Sie unter Datenbankname Ihre Datenbank aus.
d. Geben Sie unter Benutzername den Namen des Benutzers ein.
e. Geben Sie unter Kennwort das Kennwort für den Benutzer ein.
f. Klicken Sie auf Verbindung testen, um die Verbindung zu testen.
g. Wählen Sie Erstellen aus, um den verknüpften Dienst bereitzustellen.
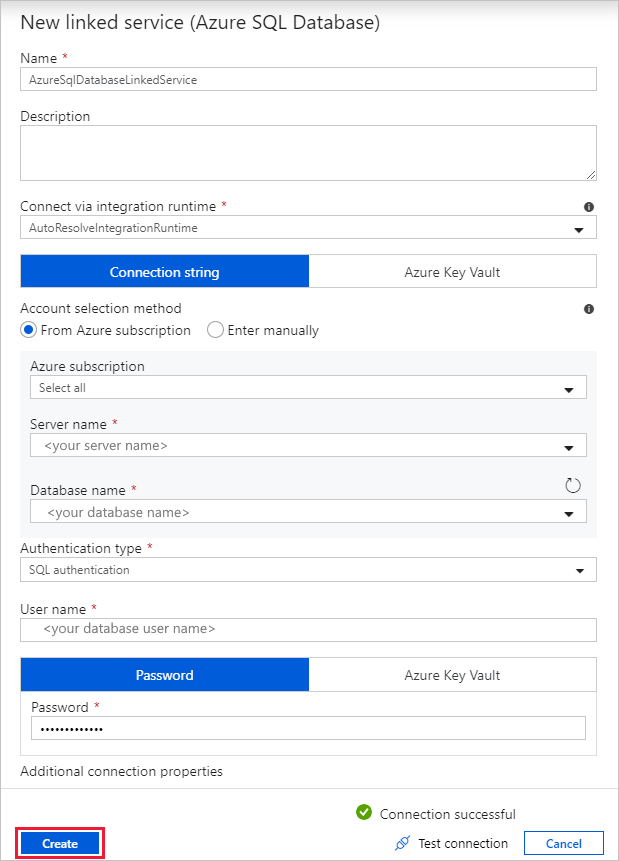
Das Dialogfeld Eigenschaften festlegen wird automatisch geöffnet. Wählen Sie unter Tabelle die Option [dbo].[emp] aus. Klicken Sie anschließend auf OK.
Wechseln Sie zur Registerkarte mit der Pipeline, und überprüfen Sie, ob für Senkendataset die Option OutputSqlDataset ausgewählt ist.
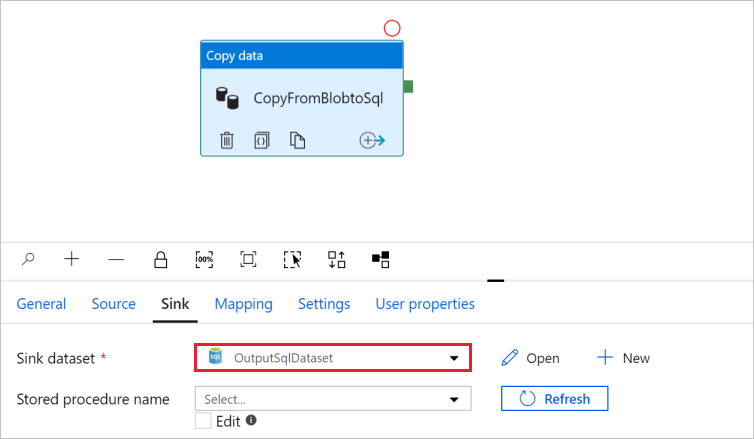
Optional können Sie das Schema der Quelle dem entsprechenden Zielschema zuordnen. Befolgen Sie dazu die Anweisungen unter Schemazuordnung in Kopieraktivität.
Überprüfen der Pipeline
Klicken Sie auf der Symbolleiste auf Überprüfen, um die Pipeline zu überprüfen.
Sie können den JSON-Code der Pipeline anzeigen, indem Sie oben rechts auf Code klicken.
Debuggen und Veröffentlichen der Pipeline
Sie können vor dem Veröffentlichen von Artefakten (verknüpfte Dienste, Datasets und Pipeline) in Data Factory oder Ihrem eigenen Azure DevOps-Git-Repository eine Pipeline debuggen.
Klicken Sie auf der Symbolleiste auf Debuggen, um die Pipeline zu debuggen. Der Status der Pipelineausführung wird unten im Fenster auf der Registerkarte Ausgabe angezeigt.
Sobald die Pipeline erfolgreich ausgeführt werden kann, klicken Sie in der oberen Symbolleiste auf Alle veröffentlichen. Mit dieser Aktion werden erstellte Entitäten (Datasets und Pipelines) in Data Factory veröffentlicht.
Warten Sie, bis die Meldung Erfolgreich veröffentlicht angezeigt wird. Damit Benachrichtigungsmeldungen angezeigt werden, klicken Sie oben rechts auf Benachrichtigungen anzeigen (Schaltfläche mit Glocke).
Manuelles Auslösen der Pipeline
In diesem Schritt lösen Sie die im vorherigen Schritt veröffentlichte Pipeline manuell aus.
Wählen Sie in der Symbolleiste die Option Trigger und dann Trigger Now (Jetzt auslösen). Klicken Sie auf der Seite Pipelineausführung auf OK.
Wechseln Sie links zur Registerkarte Überwachen. Sie sehen eine Pipelineausführung, die von einem manuellen Trigger ausgelöst wird. Über die Links unter der Spalte PIPELINENAME können Sie Aktivitätsdetails anzeigen und die Pipeline erneut ausführen.

Um die der Pipelineausführung zugeordneten Aktivitätsausführungen anzuzeigen, wählen Sie unter der Spalte PIPELINENAME den Link CopyPipeline aus. Da in diesem Beispiel nur eine Aktivität vorhanden ist, wird in der Liste nur ein Eintrag angezeigt. Wenn Sie Details zum Kopiervorgang anzeigen möchten, wählen Sie in der Spalte ACTIVTIY NAME (AKTIVITÄTSNAME) den Link Details (das Brillensymbol) aus. Wählen Sie oben Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln. Klicken Sie zum Aktualisieren der Ansicht auf Aktualisieren.

Stellen Sie sicher, dass zwei weitere Zeilen zur Tabelle emp in der Datenbank hinzugefügt werden.

Auslösen der Pipeline nach einem Zeitplan
In diesem Zeitplan erstellen Sie einen Zeitplantrigger für die Pipeline. Der Trigger führt die Pipeline nach dem angegebenen Zeitplan aus, etwa stündlich oder täglich. Hier legen Sie fest, dass der Trigger bis zur angegebenen Endzeit (Datum und Uhrzeit) minütlich ausgeführt wird.
Navigieren Sie auf der linken Seite zur Registerkarte Autor (oberhalb der Registerkarte „Überwachen“).
Navigieren Sie zu Ihrer Pipeline, klicken Sie auf der Symbolleiste auf Trigger, und wählen Sie Neu/Bearbeiten.
Wählen Sie im Dialogfeld Trigger hinzufügen im Bereich Trigger auswählen die Option + Neu aus.
Führen Sie im Fenster Neuer Trigger die folgenden Schritte aus:
a. Geben Sie unter Name den Namen RunEveryMinute ein.
b. Aktualisieren Sie die Angabe unter Startdatum für Ihren Trigger. Liegt das Datum vor dem aktuellen datetime-Wert, ist der Trigger ab Veröffentlichung der Änderung wirksam.
c. Wählen Sie unter Zeitzone die Dropdownliste aus.
d. Legen Sie Serie auf Every 1 Minute(s) (Alle 1 Minute(n)) fest.
e. Aktivieren Sie das Kontrollkästchen Enddatum festlegen, und aktualisieren Sie den Teil End On (Ende am), sodass die angegebene Zeit einige Minuten nach dem aktuellen datetime-Wert liegt. Der Trigger wird erst nach dem Veröffentlichen der Änderungen aktiviert. Wenn nur einige Minuten dazwischen liegen und Sie die Änderungen bis zur angegebenen Zeit nicht veröffentlicht haben, wird kein ausgeführter Trigger angezeigt.
f. Wählen Sie Ja für die Option Aktiviert aus.
g. Klicken Sie auf OK.
Wichtig
Da für jede Pipelineausführung Gebühren anfallen, legen Sie ein geeignetes Enddatum fest.
Überprüfen Sie die Warnung auf der Seite Trigger bearbeiten, und klicken Sie auf Speichern. Die Pipeline in diesem Beispiel akzeptiert keine Parameter.
Klicken Sie auf Alle veröffentlichen, um die Änderung zu veröffentlichen.
Wechseln Sie im linken Bereich zur Registerkarte Überwachen, um die ausgelösten Pipelineausführungen anzuzeigen.

Um von der Ansicht Pipelineausführungen zur Ansicht Triggerausführungen zu wechseln, klicken Sie auf der linken Seite des Fensters auf Triggerausführungen.
Die Triggerausführungen werden in einer Liste angezeigt.
Stellen Sie sicher, dass bis zur angegebenen Endzeit zwei Zeilen pro Minute (für jede Pipelineausführung) in die Tabelle emp eingefügt werden.
Zugehöriger Inhalt
Die Pipeline in diesem Beispiel kopiert Daten in Blob Storage von einem Speicherort in einen anderen. Sie haben Folgendes gelernt:
- Erstellen einer Data Factory.
- Erstellen einer Pipeline mit einer Copy-Aktivität
- Ausführen eines Testlaufs für die Pipeline
- Manuelles Auslösen der Pipeline
- Auslösen der Pipeline nach einem Zeitplan
- Überwachen der Pipeline- und Aktivitätsausführungen.
Fahren Sie mit dem folgenden Tutorial fort, um zu erfahren, wie Sie Daten von einem lokalen Speicherort in die Cloud kopieren: