Erstellen eines Triggers zum Ausführen einer Pipeline als Reaktion auf ein Speicherereignis
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird der Trigger für Speicherereignisse beschrieben, den Sie in Ihren Azure Data Factory- oder Azure Synapse Analytics-Pipelines erstellen können.
Die ereignisgesteuerte Architektur ist ein allgemeines Datenintegrationsmuster, das die Produktion, Erkennung, Verbrauch und Reaktion auf Ereignisse beinhaltet. In Datenintegrationsszenarien ist es oft erforderlich, dass Kunden Pipelines aufgrund von Ereignissen in Azure Storage-Konten auslösen, z. B. wenn eine Datei zu einem Azure Blob Storage-Konto hinzugefügt oder daraus gelöscht wird. Data Factory- und Azure Synapse Analytics-Pipelines lassen sich in Azure Event Grid nativ integrieren, sodass Sie Pipelines für solche Ereignisse auslösen können.
Überlegungen zu Speicherereignistriggern
Berücksichtigen Sie die folgenden Punkte, wenn Sie Speicherereignistrigger verwenden:
- Die in diesem Artikel beschriebene Integration basiert auf Azure Event Grid. Stellen Sie sicher, dass Ihr Abonnement für den Event Grid-Ressourcenanbieter registriert ist. Weitere Informationen finden Sie unter Ressourcenanbieter und -typen. Sie müssen in der Lage sein, die Aktion
Microsoft.EventGrid/eventSubscriptions/auszuführen. Diese Aktion ist Teil derEventGrid EventSubscription Contributorintegrierten Rolle. - Wenn Sie dieses Feature in Azure Synapse Analytics verwenden, stellen Sie sicher, dass Sie Ihr Abonnement auch beim Data Factory-Ressourcenanbieter registrieren. Andernfalls wird eine Meldung angezeigt, die besagt, dass „die Erstellung eines Ereignisabonnements fehlgeschlagen ist“.
- Wenn sich das Blob Storage-Konto hinter einem privaten Endpunkt befindet und den Zugriff auf öffentliche Netzwerke blockiert, müssen Sie Netzwerkregeln konfigurieren, um die Kommunikation von Blob Storage zu Event Grid zu ermöglichen. Sie können entweder Speicherzugriff auf vertrauenswürdige Azure-Dienste gewähren, z. B. Event Grid, wie in der Storage-Dokumentation beschrieben, oder private Endpunkte für Event Grid konfigurieren, die an einen virtuellen Netzwerkadressraum entsprechend der Event Grid-Dokumentation zuordnen.
- Der Speicherereignistrigger unterstützt derzeit nur Azure Data Lake Storage Gen2-Speicherkonten und universelle Speicherkonten (Version 2). Wenn Sie mit SFTP-Speicherereignissen (Secure File Transfer Protocol) arbeiten, müssen Sie auch die SFTP Daten-API im Filterabschnitt angeben. Aufgrund einer Einschränkung von Event Grid unterstützt Data Factory nur maximal 500 Speicherereignistrigger pro Speicherkonto.
- Zum Erstellen eines neuen Speicherereignistriggers oder zum Ändern eines vorhandenen muss das Azure-Konto, das für die Anmeldung beim Dienst und die Veröffentlichung des Triggers genutzt wird, die entsprechende rollenbasierte Zugriffssteuerungsberechtigung (Azure RBAC) für das Speicherkonto haben. Es sind keine weiteren Berechtigungen erforderlich. Der Dienstprinzipal für die Azure Data Factory und Azure Synapse Analytics benötigt keine besondere Berechtigung für das Speicherkonto oder das Event Grid. Weitere Informationen zur Zugriffssteuerung finden Sie im Abschnitt Rollenbasierte Zugriffssteuerung.
- Wenn Sie eine Azure Resource Manager-Sperre auf Ihr Speicherkonto angewendet haben, wirkt sich dies möglicherweise auf die Fähigkeit des Blobtriggers zum Erstellen oder Löschen von Blobs aus. Eine
ReadOnly-Sperre verhindert sowohl das Erstellen als auch das Löschen, während eineDoNotDelete-Sperre das Löschen verhindert. Stellen Sie sicher, dass Sie diese Einschränkungen berücksichtigen, um Probleme mit Ihren Triggern zu vermeiden. - Es wird nicht empfohlen, Dateieingangstrigger als auslösenden Mechanismus aus Datenflusssenken zu verwenden. Datenflüsse führen eine Reihe von Dateiumbenennungs- und Partitionsdatei-Shufflingaufgaben im Zielordner durch, die versehentlich ein Dateieingangsereignis auslösen können, bevor Ihre Daten vollständig verarbeitet worden sind.
Erstellen eines Triggers über die Benutzeroberfläche
In diesem Abschnitt wird gezeigt, wie Sie über die Benutzeroberfläche (UI) der Azure Data Factory- und Azure Synapse Analytics-Pipeline einen Speicherereignistrigger erstellen können.
Wechseln Sie in Data Factory zur Registerkarte Bearbeiten oder in Azure Synapse Analytics zur Registerkarte Integrieren.
Wählen Sie im Menü Trigger aus und wählen Sie dann Neu/Bearbeiten aus.
Klicken Sie auf der Seite Auslöser hinzufügen auf Auslöser auswählen und dann auf +Neu.
Wählen Sie den Triggertyp Speicherereignisse aus.
Wählen Sie aus der Dropdownliste für die Azure-Abonnements Ihr Storage-Konto aus, oder geben Sie die Ressourcen-ID des Storage-Kontos ein. Wählen Sie den Container aus, in dem die Ereignisse auftreten sollen. Die Containerauswahl ist erforderlich, aber die Auswahl aller Container kann zu einer hohen Anzahl von Ereignissen führen.
Mit den Eigenschaften
Blob path begins withundBlob path ends withkönnen Sie die Container, Ordner und Blobnamen angeben, für die Sie Ereignisse empfangen möchten. Der Speicherereignistrigger erfordert, dass mindestens eine dieser Eigenschaften definiert wird. Sie können verschiedene Muster für beideBlob path begins with- undBlob path ends with-Eigenschaften verwenden, wie in den Beispielen weiter unten in diesem Artikel gezeigt.-
Blob path begins with: Der Blobpfad muss mit einem Ordnerpfad beginnen. Beispielsweise können die folgenden Werte verwendet werden:2018/und2018/april/shoes.csv. Dieses Feld kann nicht ausgewählt werden, wenn kein Container ausgewählt ist. -
Blob path ends with: Der Blobpfad muss auf einem Dateinamen oder einer Erweiterung enden. Beispielsweise können die folgenden Werte verwendet werden:shoes.csvund.csv. Container- und Ordnernamen müssen, sofern angegeben, durch ein/blobs/-Segment getrennt werden. Beispielsweise kann ein Container mit dem Namenordersden Wert/orders/blobs/2018/april/shoes.csvhaben. Wenn Sie einen Ordner in einem beliebigen Container angeben möchten, lassen Sie das vorangestellte Zeichen/aus. Beispielsweise löstapril/shoes.csvein Ereignis für jede Datei mit dem Namenshoes.csvaus, die sich in einem beliebigen Container in einem Ordner namensaprilbefindet.
Beachten Sie, dass
Blob path begins withundBlob path ends withdie einzigen Musterabgleiche sind, die in einem Speicherereignistrigger zulässig sind. Andere Arten des Platzhalterabgleichs sind für den Auslösertyp nicht zulässig.-
Wählen Sie aus, ob der Trigger auf ein Blob erstellt-Ereignis, auf ein Blob gelöscht-Ereignis oder auf beides reagiert. Am angegebenen Speicherort löst jedes Ereignis die Data Factory- und Azure Synapse Analytics-Pipelines aus, die dem Trigger zugeordnet sind.
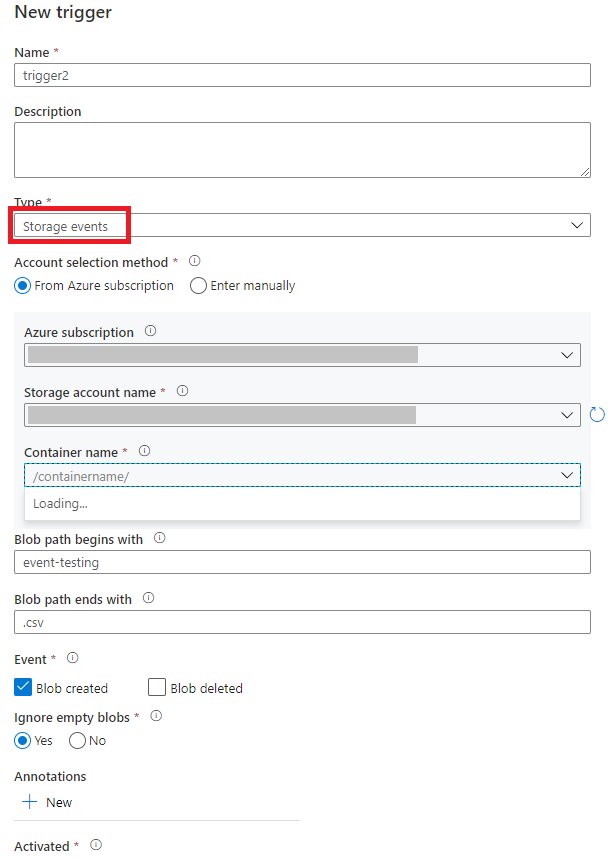
Wählen Sie aus, ob Ihr Trigger Blobs mit null Bytes ignorieren soll oder nicht.
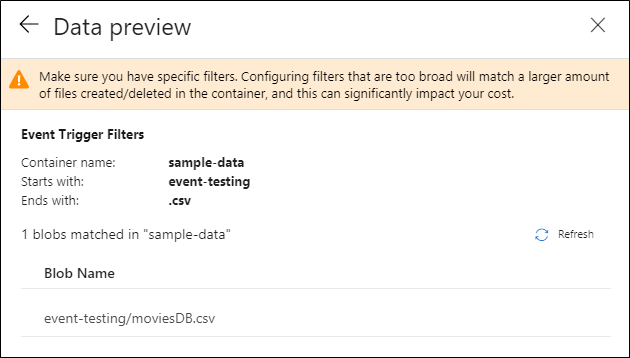
Nachdem Sie den Trigger konfiguriert haben, wählen Sie Weiter: Datenvorschau aus. Diese Anzeige informiert über die vorhandenen Blobs, die Ihrer Konfiguration für Speicherereignistrigger entsprechen. Vergewissern Sie sich, dass Sie spezifische Filter ausgewählt haben. Das Konfigurieren von Filtern, die zu breit sind, kann mit einer großen Anzahl von Dateien übereinstimmen, die erstellt oder gelöscht wurden, und sich möglicherweise erheblich auf Ihre Kosten auswirken. Nachdem die Filterbedingungen überprüft wurden, wählen Sie Fertigstellen aus.
Um eine Pipeline an diesen Trigger anzufügen, wechseln Sie zum Pipeline-Zeichenbereich, und wählen Sie Trigger>Neu/Bearbeiten aus. Wenn der Seitenbereich angezeigt wird, wählen Sie die Dropdownliste Trigger auswählen aus, und wählen Sie den von Ihnen erstellten Trigger aus. Wählen Sie Weiter: Datenvorschau aus, um zu bestätigen, dass die Konfiguration korrekt ist. Wählen Sie dann Weiter aus, um zu überprüfen, ob die Datenvorschau korrekt ist.
Wenn Ihre Pipeline Parameter enthält, können Sie sie im Seitenbereich Trigger Run Parameters angeben. Der Speicherereignistrigger erfasst den Ordnerpfad und den Dateinamen des Blobs in den Eigenschaften
@triggerBody().folderPathund@triggerBody().fileName. Um die Werte dieser Eigenschaften in einer Pipeline zu verwenden, müssen Sie die Eigenschaften Pipelineparametern zuordnen. Nachdem Sie die Eigenschaften zu Parametern zuordnen, können Sie über den Ausdruck@pipeline().parameters.parameterNameauf die vom Trigger erfassten Werte in der gesamten Pipeline zugreifen. Eine ausführliche Erläuterung finden Sie unter Referenztriggermetadaten in Pipelines.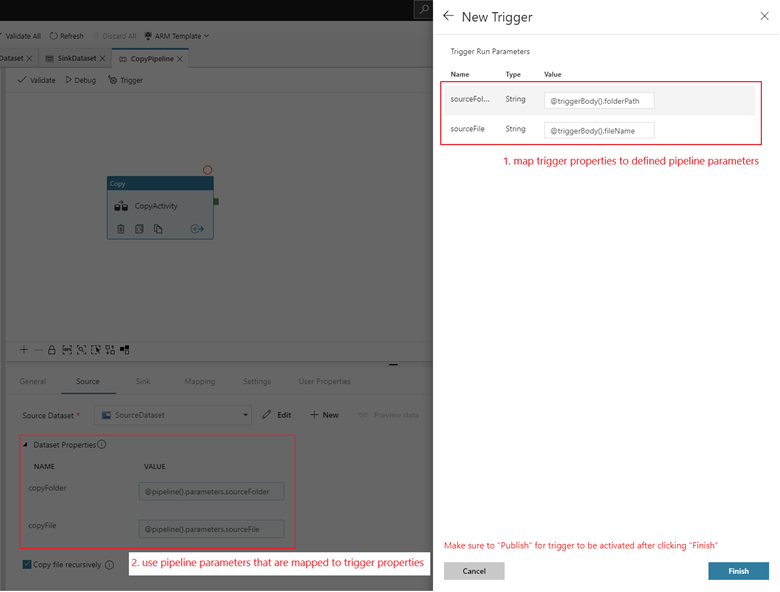
Im vorherigen Beispiel wurde der Trigger so konfiguriert, dass er ausgelöst wird, wenn im Container sample-data (Beispieldaten) ein Blobpfad mit der Erweiterung „.csv“ im Ordner event-testing (Ereignistest) erstellt wird. Die Eigenschaften
folderPathundfileNameerfassen den Speicherort des neuen Blobs. Wenn z. B. MoviesDB.csv dem Pfad Beispieldaten/Ereignistests hinzugefügt wird, hat@triggerBody().folderPathden Wertsample-data/event-testingund@triggerBody().fileNameden WertmoviesDB.csv. Diese Werte werden im Beispiel den PipelineparameternsourceFolderundsourceFilezugeordnet, die in der gesamten Pipeline jeweils als@pipeline().parameters.sourceFolderbzw.@pipeline().parameters.sourceFileverwendet werden können.Nachdem Sie fertig sind, wählen Sie Fertigstellen aus.


JSON-Schema
Die folgende Tabelle bietet eine Übersicht über die Schemaelemente, die mit Speicherereignistriggern verknüpft sind.
| JSON-Element | BESCHREIBUNG | type | Zulässige Werte | Erforderlich |
|---|---|---|---|---|
| scope | Die Ressourcen-ID von Azure Resource Manager im Speicherkonto. | String | Azure Resource Manager-ID | Ja. |
| events | Der Ereignistyp, die diesen Trigger auslöst. | Array |
Microsoft.Storage.BlobCreated, Microsoft.Storage.BlobDeleted |
Ja (beliebige Kombination dieser Werte). |
blobPathBeginsWith |
Der Blobpfad muss mit dem angegebenen Muster beginnen, damit der Trigger ausgelöst wird.
/records/blobs/december/ löst den Trigger beispielsweise nur für Blobs im Ordner december unter dem Container records aus. |
String | Geben Sie einen Wert für mindestens eine der folgenden Eigenschaften an: blobPathBeginsWith oder blobPathEndsWith. |
|
blobPathEndsWith |
Der Blobpfad muss mit dem angegebenen Muster enden, damit der Trigger ausgelöst wird.
december/boxes.csv löst den Trigger beispielsweise nur für Blobs namens boxes aus, die sich in einem Ordner namens december befinden. |
String | Geben Sie einen Wert für mindestens eine der folgenden Eigenschaften an: blobPathBeginsWith oder blobPathEndsWith. |
|
ignoreEmptyBlobs |
Legt fest, ob Null-Byte-Blobs eine Pipelineausführung auslösen oder nicht. Sie ist standardmäßig auf true festgelegt. |
Boolean | true oder false | Nein |
Beispiele für Speicherereignistrigger
Dieser Abschnitt enthält Beispiele für die Einstellungen für Speicherereignistrigger.
Wichtig
Sie müssen das Segment /blobs/ des Pfads wie in den folgenden Beispielen gezeigt immer dann einbeziehen, wenn Sie Container und Ordner, Container und Datei oder Container, Ordner und Datei angeben. Bei blobPathBeginsWith fügt die Benutzeroberfläche automatisch /blobs/ zwischen dem Ordner- und Containernamen im JSON-Code des Triggers hinzu.
| Eigenschaft | Beispiel | Beschreibung |
|---|---|---|
Blob path begins with |
/containername/ |
Empfängt Ereignisse für ein beliebiges Blob im Container. |
Blob path begins with |
/containername/blobs/foldername/ |
Empfängt Ereignisse für ein beliebiges Blob im Container containername und Ordner foldername. |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
Sie können auch auf einen Unterordner verweisen. |
Blob path begins with |
/containername/blobs/foldername/file.txt |
Empfängt Ereignisse für ein Blob namens file.txt im Ordner foldername unter dem Container containername. |
Blob path ends with |
file.txt |
Empfängt Ereignisse für ein Blob namens file.txt unter einem beliebigen Pfad. |
Blob path ends with |
/containername/blobs/file.txt |
Empfängt Ereignisse für ein Blob namens file.txt unter dem Container containername. |
Blob path ends with |
foldername/file.txt |
Empfängt Ereignisse für ein Blob namens file.txt im Ordner foldername unter einem beliebigen Container. |
Rollenbasierte Zugriffssteuerung
In Data Factory- und Azure Synapse Analytics-Pipelines wird mithilfe der rollenbasierten Zugriffssteuerung von Azure (Azure RBAC) sichergestellt, dass unbefugte Zugriffe zum Lauschen auf, Abonnieren von Aktualisierungen aus und Auslösen von Pipelines, die mit Blobereignissen verknüpft sind, streng verboten sind.
- Zum erfolgreichen Erstellen eines neuen oder Aktualisieren eines vorhandenen Speicherereignistriggers muss das beim Dienst angemeldete Azure-Konto entsprechenden Zugriff auf das relevante Speicherkonto haben. Andernfalls schlägt der Vorgang mit der Meldung „Zugriff verweigert“ fehl.
- Data Factory und Azure Synapse Analytics benötigen keine spezielle Berechtigung für Ihre Event Grid-Instanz, und Sie müssen dem Data Factory- oder Azure Synapse Analytics-Dienstprinzipal keine spezielle RBAC-Berechtigung für den Vorgang zuweisen.
Folgende RBAC-Einstellungen eignen sich für einen Speicherereignistrigger:
- Besitzerrolle für das Speicherkonto
- Die Rolle „Mitwirkender“ für das Speicherkonto
-
Microsoft.EventGrid/EventSubscriptions/Write-Berechtigung für das Speicherkonto/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
Speziell:
- Beim Erstellen in der Data Factory (z. B. in der Entwicklungsumgebung) muss das angemeldete Azure-Konto über die voranstehende Berechtigung verfügen.
- Wenn Sie über kontinuierliche Integration und kontinuierliche Bereitstellung veröffentlichen, muss das Konto, das zum Veröffentlichen der Azure Resource Manager-Vorlage in der Test- oder Produktionsfabrik verwendet wird, über die voranstehende Berechtigung verfügen.
Um zu verstehen, wie der Dienst die beiden Zusagen erfüllt, gehen wir einen Schritt zurück und werfen einen Blick hinter die Kulissen. Hier sind die allgemeinen Workflows für die Integration zwischen Data Factory/Azure Synapse, Azure Storage Analytics und Event Grid.
Erstellen eines neuen Speicherereignistriggers
In diesem allgemeinen Workflow wird beschrieben, wie Data Factory mit Event Grid interagiert, um einen Speicherereignistrigger zu erstellen. Der Datenfluss ist in Azure Synapse Analytics identisch, wobei Azure Synapse Analytics-Pipelines im folgenden Diagramm die Rolle der Data Factory übernehmen.
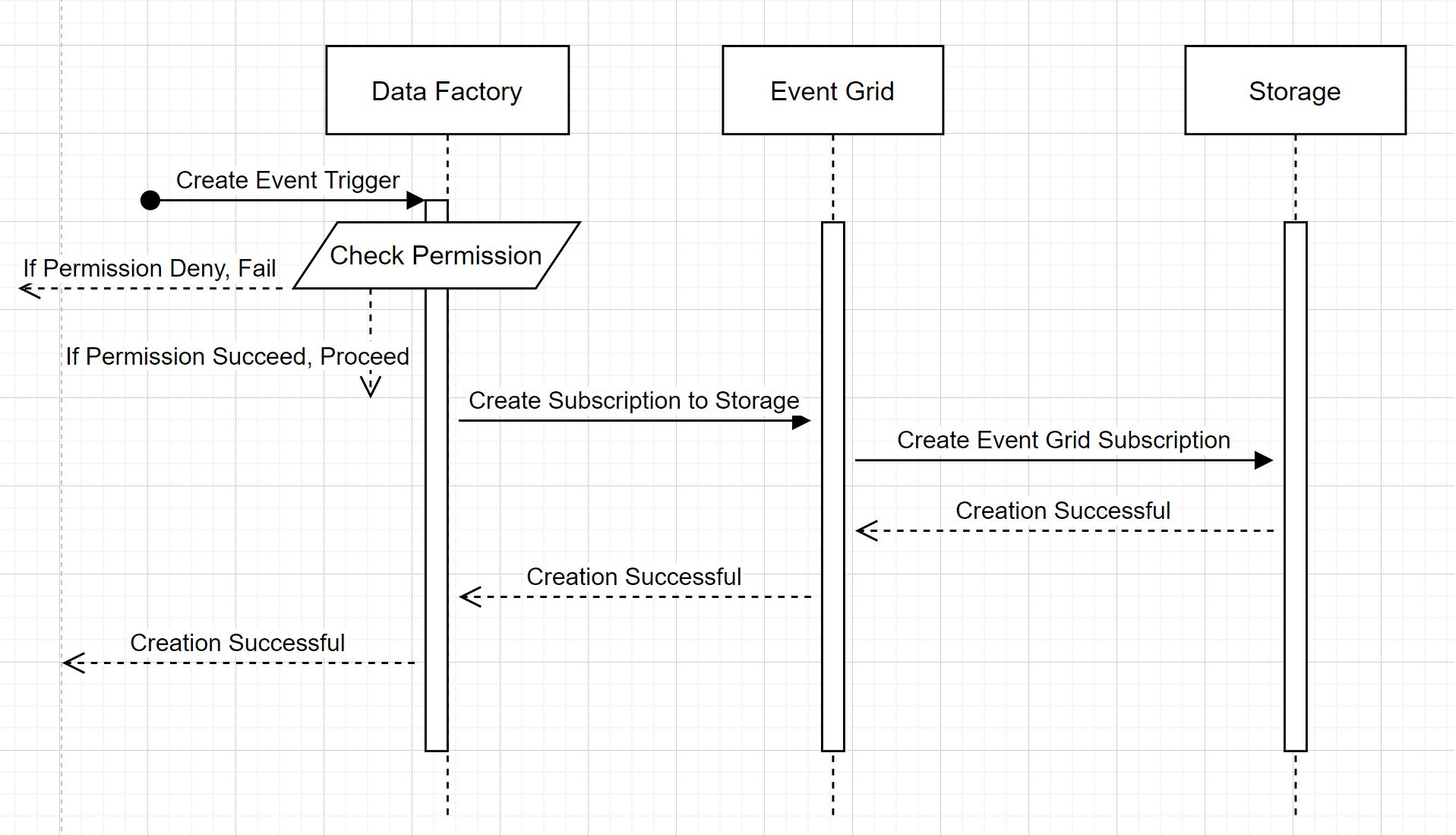
Zwei wichtige Anmerkungen zu den Workflows:
- Data Factory und Azure Synapse Analytics nehmen keinen direkten Kontakt mit dem Speicherkonto auf. Die Anforderung zum Erstellen eines Abonnements wird stattdessen weitergeleitet und von Event Grid verarbeitet. Der Dienst benötigt bei diesem Schritt keine Berechtigung für den Zugang auf das Speicherkonto.
- Zugriffssteuerung und Berechtigungsüberprüfung geschehen innerhalb des Dienstes. Bevor der Dienst eine Anforderung zum Abonnieren eines Speicherereignisses sendet, wird die Berechtigung für den Benutzer überprüft. Genauer gesagt wird überprüft, ob das angemeldete Azure-Konto, das versucht, den Speicherereignistrigger zu erstellen, entsprechenden Zugriff auf das relevante Speicherkonto hat. Wenn die Berechtigungsüberprüfung fehlschlägt, schlägt die Erstellung des Auslösers ebenfalls fehl.
Pipelineausführung für Speicherereignisauslöser
Dieser allgemeine Arbeitsablauf beschreibt, wie Speicherereignisse Pipelines auslösen, die über Event Grid ausgeführt werden. Bei Azure Synapse Analytics ist der Datenfluss identisch, wobei Azure Synapse Analytics-Pipelines die Rolle von Data Factory im folgenden Diagramm übernehmen.
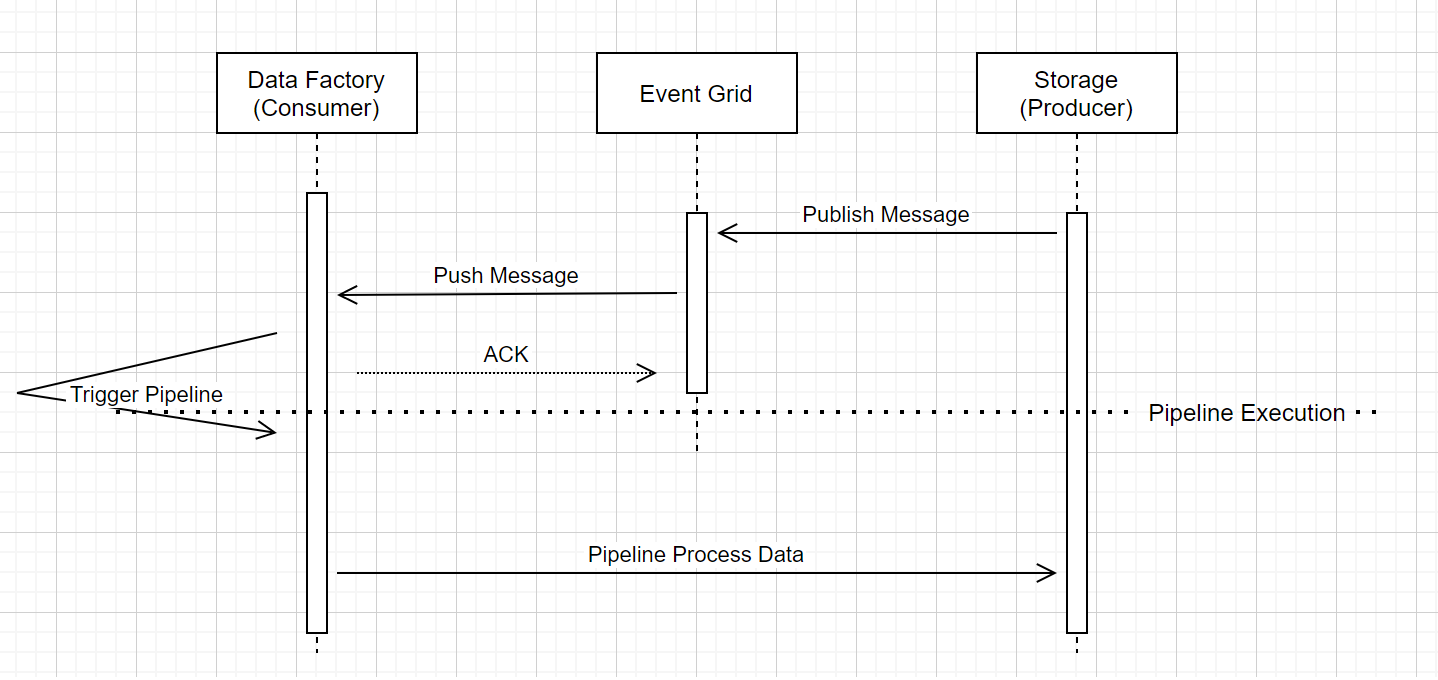
Drei wichtige Anmerkungen im Workflow im Zusammenhang mit ereignisauslösenden Pipelines innerhalb des Dienstes:
Event Grid verwendet ein Pushmodell, das die Nachricht schnellstmöglich weiterleitet, wenn sie vom Speicher im System abgelegt wird. Dieser Ansatz ist ein Unterschied zu Messaging-Systemen, wie z. B. Kafka, die ein Pullsystem verwenden.
Der Ereignistrigger dient als aktiver Listener für die eingehende Nachricht und löst die zugeordnete Pipeline ordnungsgemäß aus.
Der Speicherereignisauslöser selbst hat keinen direkten Kontakt zum Speicherkonto.
- Wenn Sie über eine Kopieraktivität oder eine andere Aktivität in der Pipeline verfügen, um die Daten im Speicherkonto zu verarbeiten, nimmt der Dienst direkten Kontakt mit dem Speicherkonto unter Verwendung der im verknüpften Dienst gespeicherten Anmeldeinformationen auf. Stellen Sie sicher, dass der verknüpfte Dienst ordnungsgemäß eingerichtet ist.
- Wenn in der Pipeline nicht auf das Speicherkonto verwiesen wird, müssen Sie dem Dienst keine Berechtigung für den Zugriff darauf erteilen.
Zugehöriger Inhalt
- Weitere Informationen zu Triggern finden Sie unter Pipelineausführung und -trigger.
- Informationen zum Verweisen auf Triggermetadaten in der Pipeline finden Sie unter Verweisen auf Triggermetadaten in Pipelineausführungen.