Verwenden von Azure Data Factory zum Migrieren von Daten von Amazon S3 zu Azure Storage
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Von Azure Data Factory wird ein performanter, stabiler und kostengünstiger Mechanismus bereitgestellt, um Daten bedarfsabhängig von Amazon S3 zu Azure Blob Storage oder Azure Data Lake Storage Gen2 zu migrieren. Dieser Artikel enthält für Datentechniker und Entwickler Informationen zu den folgenden Bereichen:
- Leistung
- Resilienz beim Kopieren
- Netzwerksicherheit
- Allgemeine Lösungsarchitektur
- Bewährte Methoden für die Implementierung
Leistung
ADF verfügt über eine serverlose Architektur, die Parallelität auf unterschiedlichen Ebenen ermöglicht. Entwickler*innen können dann Pipelines erstellen, um Ihre Netzwerkbandbreite sowie IOPS und Bandbreite des Speichers vollständig zu nutzen, um den Durchsatz für die Datenverschiebung Ihrer Umgebung zu maximieren.
Kunden haben erfolgreiche Migrationen von Daten im Petabyte-Bereich durchgeführt, bei denen mit einem dauerhaften Durchsatz von mindestens 2 GBit/s Hunderte Millionen Dateien aus Amazon S3 in Azure Blob Storage verschoben wurden.
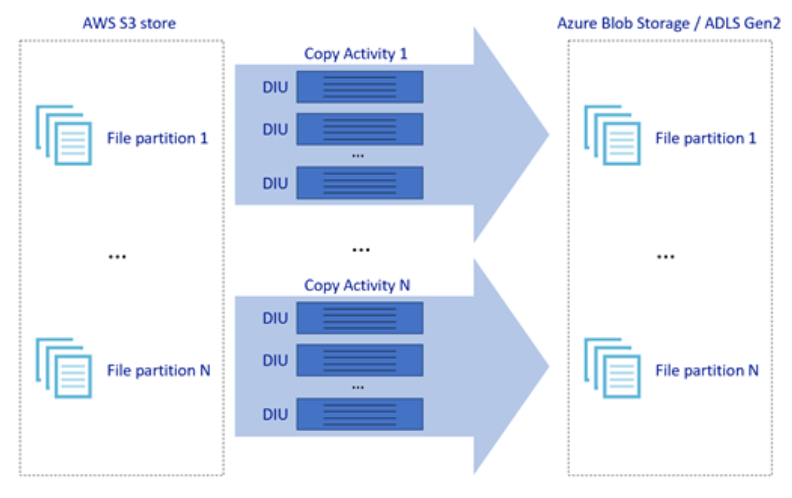
In der obigen Abbildung ist dargestellt, wie Sie für unterschiedliche Parallelitätsebenen hohe Geschwindigkeiten bei der Datenverschiebung erzielen:
- Für eine einzelne Kopieraktivität können skalierbare Computeressourcen genutzt werden: Bei Verwendung der Azure Integration Runtime können Sie bis zu 256 Datenintegrationseinheiten (DIUs) serverlos für jede Kopieraktivität angeben. Wenn Sie die selbstgehostete Integration Runtime nutzen, können Sie den Computer manuell hochskalieren oder das Aufskalieren auf mehrere Computer durchführen (bis zu vier Knoten). Bei einer einzelnen Kopieraktivität wird die Dateigruppe dann auf alle Knoten verteilt.
- Für eine Kopieraktivität werden mehrere Threads genutzt, um für den Datenspeicher Lese- und Schreibvorgänge durchzuführen.
- Mit der ADF-Ablaufsteuerung können mehrere Kopieraktivitäten parallel gestartet werden, z. B. per foreach-Schleife.
Resilienz
Bei Ausführung einer einzelnen Kopieraktivität verfügt ADF über einen integrierten Wiederholungsmechanismus, damit in den Datenspeichern oder im zugrunde liegenden Netzwerk eine bestimmte Ebene vorübergehender Fehler verarbeitet werden kann.
Beim Durchführen von binären Kopiervorgängen von S3 zu Blob Storage und von S3 zu ADLS Gen2 werden von ADF automatisch Prüfpunkte gesetzt. Wenn bei einer Ausführung der Kopieraktivität ein Fehler oder Timeout aufgetreten ist, wird die Kopie bei einer nachfolgenden Wiederholung ab dem letzten Fehlerpunkt fortgesetzt und nicht wieder vom Anfang gestartet.
Netzwerksicherheit
Standardmäßig werden Daten mit ADF von Amazon S3 in Azure Blob Storage oder Azure Data Lake Storage Gen2 übertragen, indem eine verschlüsselte Verbindung per HTTPS-Protokoll genutzt wird. HTTPS ermöglicht die Datenverschlüsselung während der Übertragung und verhindert Abhör- und Man-in-the-Middle-Angriffe.
Falls Sie nicht möchten, dass Daten über das öffentliche Internet übertragen werden, können Sie auch eine bessere Sicherheit erzielen, indem Sie Daten über einen Link für privates Peering zwischen AWS Direct Connect und Azure ExpressRoute übertragen. Im nächsten Abschnitt zur Lösungsarchitektur ist beschrieben, wie Sie dies erreichen.
Lösungsarchitektur
Migrieren von Daten über das öffentliche Internet:
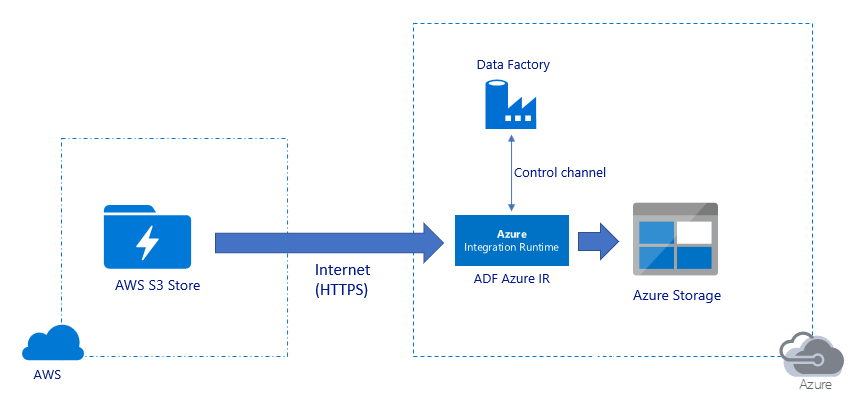
- Bei dieser Architektur werden Daten auf sichere Weise per HTTPS über das öffentliche Internet übertragen.
- Sowohl die Amazon S3-Quelle als auch das Azure Blob Storage- bzw. Azure Data Lake Storage Gen2-Ziel sind so konfiguriert, dass Datenverkehr von allen IP-Netzwerkadressen zulässig ist. In der zweiten Architektur weiter unten auf dieser Seite ist beschrieben, wie Sie den Netzwerkzugriff auf einen bestimmten IP-Bereich beschränken können.
- Sie können die Leistung leicht serverlos hochskalieren, um Ihre Netzwerk- und Speicherbandbreite vollständig zu nutzen, damit Sie den besten Durchsatz für Ihre Umgebung erzielen.
- Mit dieser Architektur ist sowohl die Migration der Anfangsmomentaufnahme als auch der Deltadaten möglich.
Migrieren von Daten über einen privaten Link:
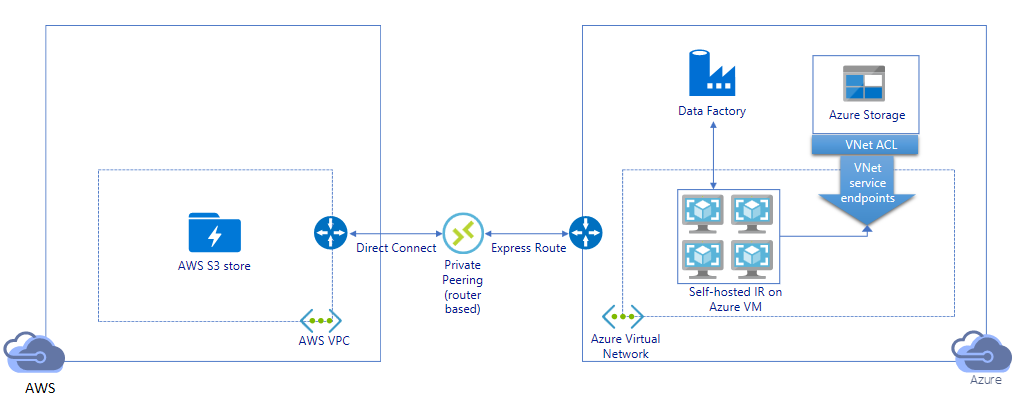
- Bei dieser Architektur wird die Datenmigration über einen privaten Peeringlink zwischen AWS Direct Connect und Azure ExpressRoute durchgeführt, damit Daten niemals über das öffentliche Internet übertragen werden. Hierfür ist die Verwendung von AWS VPC und eines virtuellen Azure-Netzwerks erforderlich.
- Sie müssen die selbstgehostete Integration Runtime von ADF auf einer Windows-VM in Ihrem virtuellen Azure-Netzwerk installieren, um diese Architektur zu erhalten. Sie können Ihre VMs mit selbstgehosteter IR manuell hochskalieren oder auf mehrere VMs aufskalieren (bis zu vier Knoten), um IOPS und Bandbreite für Netzwerk und Speicher vollständig zu nutzen.
- Mit dieser Architektur ist sowohl die Migration der Daten einer Anfangsmomentaufnahme als auch der Deltadaten möglich.
Bewährte Methoden für die Implementierung
Authentifizierung und Verwaltung von Anmeldeinformationen
- Zum Durchführen der Authentifizierung für das Amazon S3-Konto müssen Sie den Zugriffsschlüssel für das IAM-Konto verwenden.
- Für die Verbindungsherstellung mit Azure Blob Storage werden mehrere Authentifizierungstypen unterstützt. Die Verwendung von verwalteten Identitäten für Azure-Ressourcen wird dringend empfohlen: Sie basieren auf einer automatisch verwalteten ADF-Identität in Microsoft Entra ID und ermöglichen Ihnen die Konfiguration von Pipelines, ohne dass in der Definition des verknüpften Diensts Anmeldeinformationen bereitgestellt werden müssen. Alternativ können Sie die Authentifizierung für Azure Blob Storage auch per Dienstprinzipal, Shared Access Signature oder Speicherkontoschlüssel durchführen.
- Auch für die Verbindungsherstellung mit Azure Data Lake Storage Gen2 werden mehrere Authentifizierungstypen unterstützt. Die Verwendung von verwalteten Identitäten für Azure-Ressourcen wird dringend empfohlen. Es können aber auch ein Dienstprinzipal oder ein Speicherkontoschlüssel verwendet werden.
- Wenn Sie keine verwalteten Identitäten für Azure-Ressourcen nutzen, ist das Speichern der Anmeldeinformationen in Azure Key Vault dringend zu empfehlen, um das zentrale Verwalten und Rotieren von Schlüsseln ohne Änderung der verknüpften ADF-Dienste zu vereinfachen. Dies ist auch eine der bewährten Methoden für CI/CD.
Migration der Daten der Anfangsmomentaufnahme
Die Datenpartition ist besonders zu empfehlen, wenn mehr als 100 TB Daten migriert werden. Nutzen Sie zum Partitionieren der Daten die Einstellung „Präfix“, um die Ordner und Dateien in Amazon S3 nach Name zu filtern. So kann dann mit jedem ADF-Kopierauftrag jeweils eine Partition kopiert werden. Sie können mehrere ADF-Kopieraufträge gleichzeitig ausführen, um einen besseren Durchsatz zu erzielen.
Falls Kopieraufträge aufgrund eines vorübergehenden Problems mit dem Netzwerk oder dem Datenspeicher nicht erfolgreich sind, können Sie den fehlerhaften Kopierauftrag erneut ausführen, um diese spezifische Partition erneut aus AWS S3 zu laden. Alle anderen Kopieraufträge, bei denen andere Partitionen geladen werden, werden nicht beeinträchtigt.
Migration von Deltadaten
Die beste Möglichkeit zum Identifizieren von neuen oder geänderten Dateien aus AWS S3 ist die Verwendung der Namenskonvention mit Zeitpartitionierung. Wenn für Ihre Daten in AWS S3 die Zeitpartitionierung mit Zeitsegmentinformationen im Datei- oder Ordnernamen durchgeführt wurde (z. B. „/jjjj/mm/tt/file.csv), kann Ihre Pipeline leicht ermitteln, welche Dateien bzw. Ordner inkrementell kopiert werden müssen.
Wenn Ihre Daten in AWS S3 nicht über eine Zeitpartitionierung verfügen, kann ADF neue oder geänderte Dateien anhand des letzten Änderungsdatums (LastModifiedDate) identifizieren. Hierbei scannt ADF alle Dateien aus AWS S3 und kopiert nur die neuen und aktualisierten Dateien, deren Zeitstempel der letzten Änderung größer als ein bestimmter Wert ist. Wenn Sie in S3 über eine große Anzahl von Dateien verfügen, kann der erste Scanvorgang für die Dateien unabhängig davon, wie viele Dateien die Filterbedingung erfüllen, lange dauern. In diesem Fall sollten Sie die Daten zuerst partitionieren, indem Sie die gleiche „Präfix“-Einstellung für die Migration der Anfangsmomentaufnahme verwenden, damit die Dateiüberprüfung parallel erfolgen kann.
Szenarien mit selbstgehosteter Integration Runtime auf einer Azure-VM
Unabhängig davon, ob Sie Daten über eine private Verbindung migrieren oder in der Amazon S3-Firewall einen bestimmten IP-Adressbereich zulassen möchten, müssen Sie die selbstgehostete Integration Runtime auf einer Azure Windows-VM installieren.
- Die empfohlene Konfiguration, mit der für jeden virtuellen Azure-Computer begonnen werden sollte, ist „Standard_D32s_v3“ mit 32 vCPUs und 128 GB Arbeitsspeicher. Sie können die Auslastung der CPU und des Arbeitsspeichers für die IR-VM während der Datenmigration weiter überwachen. So können Sie ermitteln, ob Sie die VM weiter hochskalieren müssen, um die Leistung zu verbessern, oder herunter, um Kosten zu sparen.
- Sie können auch aufskalieren, indem Sie bis zu vier VM-Knoten einer selbstgehosteten Integration Runtime zuordnen. Bei einem einzelnen Kopierauftrag, der für eine selbstgehostete IR ausgeführt wird, wird die Dateigruppe automatisch partitioniert, und alle VM-Knoten werden genutzt, um die Dateien parallel zu kopieren. Zur Sicherstellung von Hochverfügbarkeit ist es ratsam, mit zwei VM-Knoten zu beginnen, um bei der Datenmigration einen Single Point of Failure zu vermeiden.
Ratenbegrenzung
Die bewährte Methode besteht darin, mit einem repräsentativen Beispieldataset einen Proof of Concept-Vorgang in Bezug auf die Leistung durchzuführen, damit Sie eine geeignete Partitionsgröße ermitteln können.
Beginnen Sie mit einer einzelnen Partition und einer einzelnen Kopieraktivität mit der DIU-Standardeinstellung. Erhöhen Sie die DIU-Einstellung nach und nach, bis Sie das Bandbreitenlimit Ihres Netzwerks oder das IOPS-/Bandbreitenlimit der Datenspeicher erreichen bzw. bis die maximal zulässigen 256 DIUs pro Kopieraktivität erreicht sind.
Erhöhen Sie anschließend schrittweise die Anzahl gleichzeitiger Kopieraktivitäten, bis Sie die Grenzwerte Ihrer Umgebung erreicht haben.
Wenn für die ADF-Kopieraktivität Drosselungsfehler gemeldet werden, sollten Sie entweder die Parallelitäts- oder die DIU-Einstellung in ADF reduzieren oder erwägen, die IOPS-/Bandbreitenlimits für das Netzwerk und die Datenspeicher zu erhöhen.
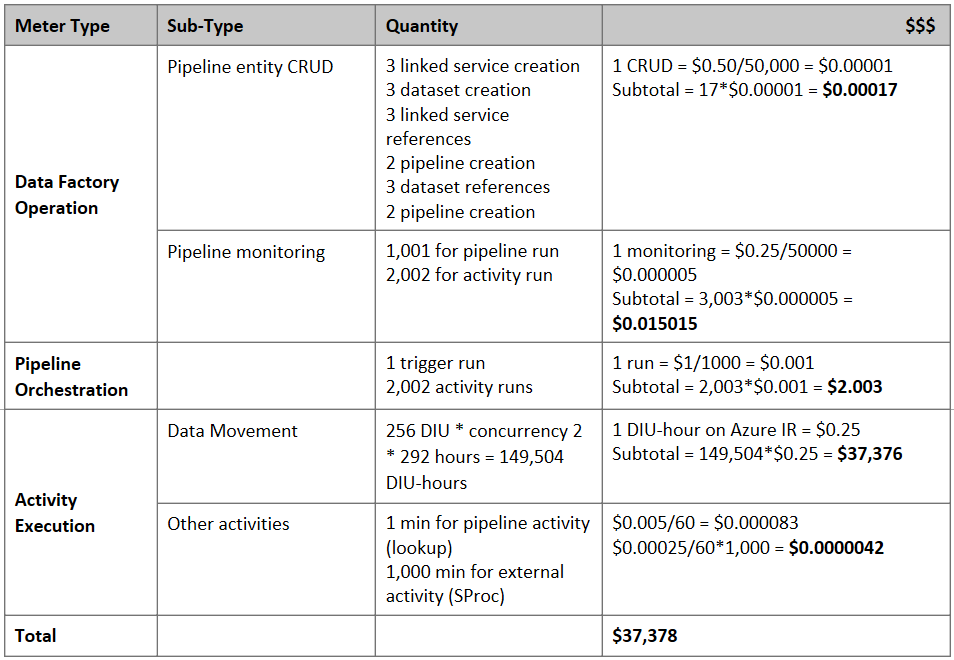
Schätzen des Preises
Hinweis
Dies ist ein hypothetisches Preisbeispiel. Der tatsächliche Preis richtet sich nach dem tatsächlichen Durchsatz in Ihrer Umgebung.
Sehen Sie sich die folgende Pipeline für die Migration von Daten aus S3 zu Azure Blob Storage an:
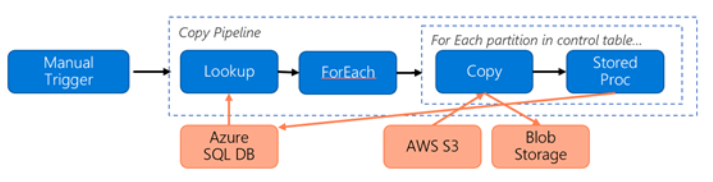
Wir nehmen Folgendes an:
- Das gesamte Datenvolumen beträgt 2 PB.
- Daten werden mit der ersten Lösungsarchitektur per HTTPS migriert.
- Die 2 PB sind in Partitionen von 1 K unterteilt, und bei jedem Kopiervorgang wird eine Partition verschoben.
- Für jeden Kopiervorgang ist „DIU = 256“ konfiguriert, und es wird ein Durchsatz von 1 GBit/s erzielt.
- Die Foreach-Parallelität ist auf den Wert 2 festgelegt, und der Aggregatdurchsatz beträgt 2 GBit/s.
- Insgesamt dauert es 292 Stunden, bis die Migration abgeschlossen ist.
Hier ist der geschätzte Preis basierend auf den obigen Annahmen angegeben:
Zusätzliche Verweise
- Amazon Simple Storage Service-Connector
- Azure Blob Storage-Connector
- Azure Data Lake Storage Gen2-Connector
- Handbuch zur Leistung und Optimierung der Kopieraktivität
- Erstellen und Konfigurieren einer selbstgehosteten Integration Runtime
- Selbstgehostete Integration Runtime: Hochverfügbarkeit und Skalierbarkeit
- Sicherheitsüberlegungen für Datenverschiebung in Azure Data Factory
- Speichern von Anmeldeinformationen in Azure Key Vault
- Inkrementelles Kopieren neuer Dateien basierend auf dem zeitpartitionierten Dateinamen und mithilfe des Tools „Daten kopieren“
- Inkrementelles Kopieren neuer und geänderter Dateien auf Basis von LastModifiedDate und mithilfe des Tools zum Kopieren von Daten
- Azure Data Factory: Datenpipelines – Preise
Vorlage
Mit dieser Vorlage können Sie Petabytes an Daten mit mehreren hundert Millionen Dateien von Amazon S3 zu Azure Data Lake Storage Gen2 migrieren.