Verwenden von Azure Data Factory zum Migrieren von Daten von einem lokalen Netezza-Server zu Azure
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Azure Data Factory stellt einen leistungsstarken, stabilen und kostengünstigen Mechanismus bereit, um Daten bedarfsabhängig von einem lokalen Netezza-Server zu Ihrem Azure Storage-Konto oder der Azure Synapse Analytics-Datenbank zu migrieren.
Dieser Artikel enthält für Datentechniker und Entwickler Informationen zu den folgenden Bereichen:
- Leistung
- Resilienz beim Kopieren
- Netzwerksicherheit
- Allgemeine Lösungsarchitektur
- Bewährte Methoden für die Implementierung
Leistung
Azure Data Factory bietet eine serverlose Architektur, die Parallelität auf verschiedenen Ebenen ermöglicht. Wenn Sie ein Entwickler sind, bedeutet dies, dass Sie Pipelines erstellen können, um sowohl die Netzwerk- als auch die Datenbankbandbreite vollständig zu nutzen, um den Datendurchsatz für Ihre Umgebung zu maximieren.
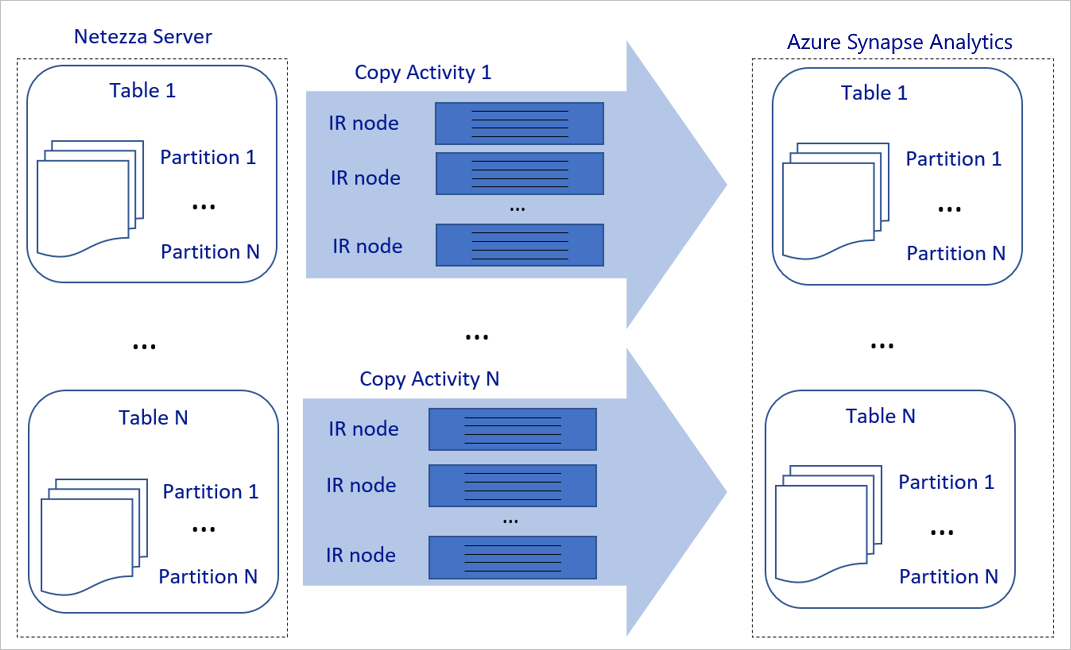
Das vorhergehende Diagramm kann wie folgt interpretiert werden:
Eine einzelne Kopieraktivität kann skalierbare Computeressourcen nutzen. Wenn Sie Azure Integration Runtime verwenden, können Sie bis zu 256 DIUs für jede Kopieraktivität serverlos angeben. Bei einer selbstgehosteten Integration Runtime (selbstgehostete IR) können Sie den Computer manuell hochskalieren oder das Aufskalieren auf mehrere Computer durchführen (bis zu vier Knoten). Eine einzelne Kopieraktivität verteilt ihre Partition auf alle Knoten.
Für eine Kopieraktivität werden mehrere Threads genutzt, um für den Datenspeicher Lese- und Schreibvorgänge durchzuführen.
Mit der Azure Data Factory-Ablaufsteuerung können mehrere Kopieraktivitäten parallel gestartet werden. Sie kann sie z. B. mit einer For-Each-Schleife starten.
Weitere Informationen finden Sie unter Handbuch zur Leistung und Skalierbarkeit der Kopieraktivität.
Resilienz
Bei Ausführung einer einzelnen Kopieraktivität verfügt Azure Data Factory über einen integrierten Wiederholungsmechanismus, damit vorübergehende Fehler in den Datenspeichern oder im zugrunde liegenden Netzwerk bis zu einem gewissen Grad gehandhabt werden können.
Mit der Azure Data Factory-Kopieraktivität haben Sie beim Kopieren von Daten zwischen Quell- und Senkendatenspeichern zwei Möglichkeiten, inkompatible Zeilen zu behandeln. Sie können die Kopieraktivität entweder mit einem Fehler abbrechen oder den Kopiervorgang für die übrigen Daten fortsetzen, indem die inkompatiblen Datenzeilen übersprungen werden. Darüber hinaus können Sie die inkompatiblen Zeilen in Azure Blob Storage oder Azure Data Lake Store protokollieren, um die Ursache des Fehlers zu ermitteln, die Daten in der Datenquelle korrigieren und die Kopieraktivität wiederholen.
Netzwerksicherheit
Standardmäßig überträgt Azure Data Factory Daten über eine verschlüsselte Verbindung per HTTPS-Protokoll (Hypertext Transfer Protocol Secure) vom lokalen Netezza-Server in ein Azure Storage-Konto oder eine Azure Synapse Analytics-Datenbank. HTTPS ermöglicht die Datenverschlüsselung während der Übertragung und verhindert Abhör- und Man-in-the-Middle-Angriffe.
Falls Sie nicht möchten, dass Daten über das öffentliche Internet übertragen werden, können Sie auch eine bessere Sicherheit erzielen, indem Sie Daten über einen privaten Peeringlink per Azure ExpressRoute übertragen.
Im nächsten Abschnitt wird erläutert, wie Sie die Sicherheit erhöhen können.
Lösungsarchitektur
In diesem Abschnitt werden zwei Möglichkeiten zum Migrieren Ihrer Daten erläutert.
Migrieren von Daten über das öffentliche Internet
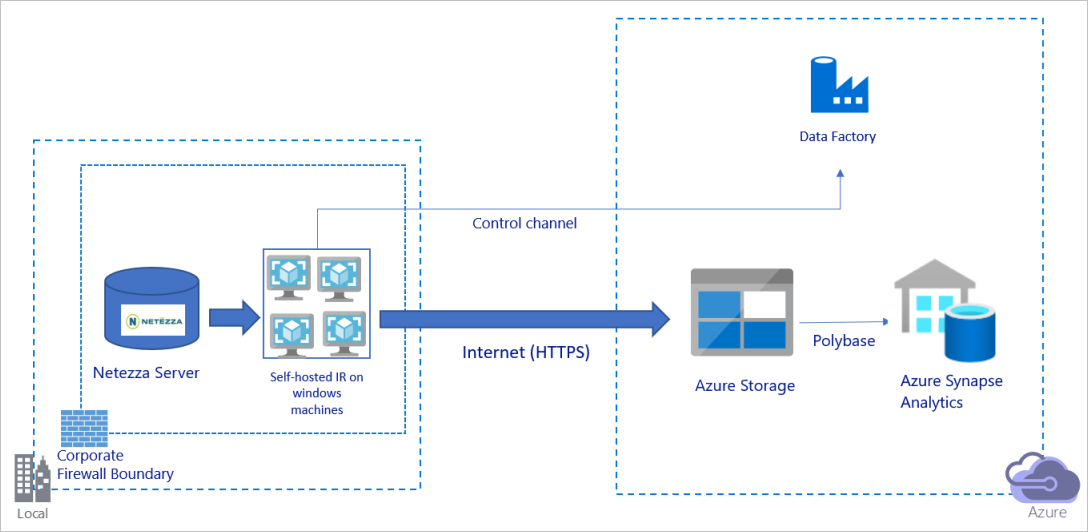
Das vorhergehende Diagramm kann wie folgt interpretiert werden:
Bei dieser Architektur übertragen Sie Daten per HTTPS sicher über das öffentliche Internet.
Sie müssen die (selbstgehostete) Integration Runtime von Azure Data Factory auf einem Windows-Computer hinter der Unternehmensfirewall installieren, um diese Architektur zu erhalten. Stellen Sie sicher, dass diese Integration Runtime direkt auf den Netezza-Server zugreifen kann. Sie können Ihren Computer manuell hochskalieren oder das Aufskalieren auf mehreren Computern durchführen, um die Bandbreite Ihres Netzwerks und der Datenspeicher zum Kopieren von Daten vollständig zu nutzen.
Durch die Verwendung dieser Architektur können Sie sowohl Daten der Anfangsmomentaufnahme als auch Deltadaten migrieren.
Migrieren von Daten über ein privates Netzwerk
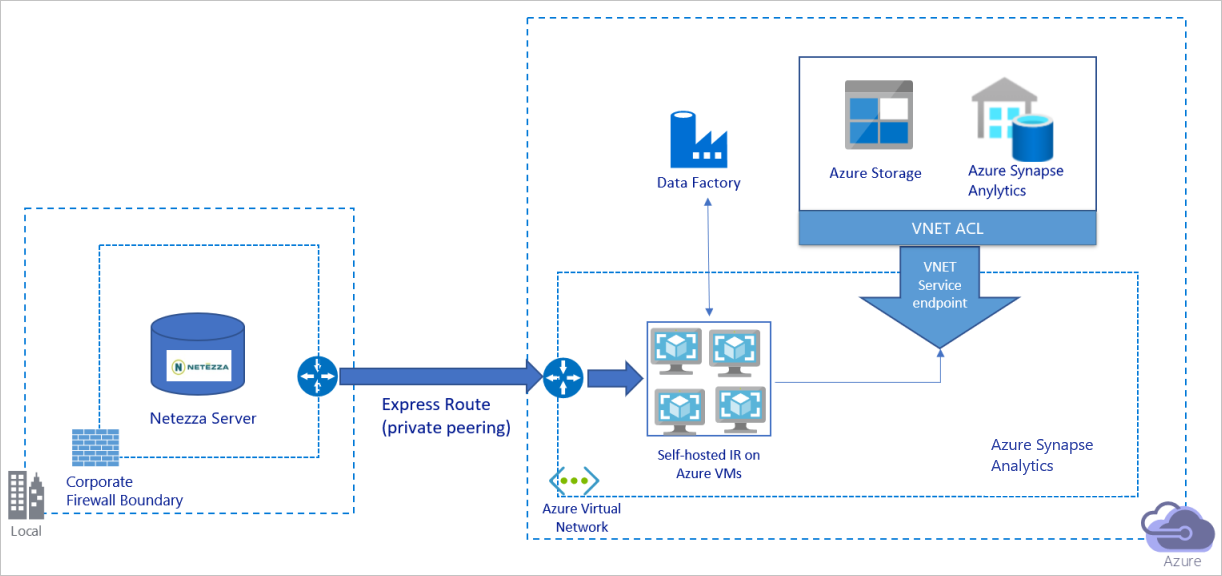
Das vorhergehende Diagramm kann wie folgt interpretiert werden:
Bei dieser Architektur wird die Datenmigration über einen privaten Peeringlink per Azure ExpressRoute durchgeführt, damit Daten niemals über das öffentliche Internet übertragen werden.
Sie müssen die (selbstgehostete) Integration Runtime von Azure Data Factory auf einem virtuellen Windows-Computer (VM) in Ihrem virtuellen Azure-Netzwerk installieren, um diese Architektur zu erhalten. Sie können Ihre VMs manuell hochskalieren oder das Aufskalieren auf mehreren VMs durchführen, um die Bandbreite Ihres Netzwerks und der Datenspeicher zum Kopieren von Daten vollständig zu nutzen.
Durch die Verwendung dieser Architektur können Sie sowohl Daten der Anfangsmomentaufnahme als auch Deltadaten migrieren.
Implementieren von bewährten Methoden
Verwalten von Authentifizierung und Anmeldeinformationen
Zum Authentifizieren bei Netezza können Sie die ODBC-Authentifizierung über eine Verbindungszeichenfolge verwenden.
So authentifizieren Sie sich für Azure Blob Storage
Wir empfehlen dringend die Verwendung von verwalteten Identitäten für Azure-Ressourcen. Verwaltete Identitäten basieren auf einer automatisch verwalteten Azure Data Factory-Identität in Microsoft Entra ID und ermöglichen Ihnen die Konfiguration von Pipelines, ohne dass in der Definition des verknüpften Diensts Anmeldeinformationen angegeben werden müssen.
Alternativ können Sie die Authentifizierung für Azure Blob Storage auch per Dienstprinzipal, Shared Access Signature oder Speicherkontoschlüssel durchführen.
So authentifizieren Sie sich für Azure Data Lake Storage Gen2
Wir empfehlen dringend die Verwendung von verwalteten Identitäten für Azure-Ressourcen.
Sie können auch einen Dienstprinzipal oder Speicherkontoschlüssel verwenden.
So authentifizieren Sie sich bei Azure Synapse Analytics:
Wir empfehlen dringend die Verwendung von verwalteten Identitäten für Azure-Ressourcen.
Sie können auch einen Dienstprinzipal oder die SQL-Authentifizierung verwenden.
Wenn Sie keine verwalteten Identitäten für Azure-Ressourcen nutzen, ist das Speichern der Anmeldeinformationen in Azure Key Vault dringend zu empfehlen, um das zentrale Verwalten und Rotieren von Schlüsseln ohne Änderung der verknüpften Azure Data Factory-Dienste zu vereinfachen. Dies ist auch eine der bewährten Methoden für CI/CD.
Migrieren der Daten der Anfangsmomentaufnahme
Bei kleinen Tabellen (d. h. Tabellen mit einem Volumen von weniger als 100 GB oder Tabellen, die innerhalb von zwei Stunden zu Azure migriert werden können) können mit jedem Kopierauftrag die Daten pro Tabelle geladen werden. Bei größeren Durchsätzen können Sie mehrere Azure Data Factory-Kopieraufträge ausführen, um separate Tabellen gleichzeitig zu laden.
Innerhalb jedes Kopierauftrags können Sie, um parallele Abfragen auszuführen und Daten nach Partitionen zu kopieren, auch einen gewissen Grad an Parallelität erreichen, indem Sie die parallelCopies-Eigenschaftseinstellung mit einer der folgenden Datenpartitionsoptionen verwenden:
Um eine höhere Effizienz zu erreichen, empfehlen wir Ihnen, von einem Datenslice auszugehen. Stellen Sie sicher, dass der Wert in der Einstellung
parallelCopieskleiner ist als die Gesamtzahl der Datenslicepartitionen in Ihrer Tabelle auf dem Netezza-Server.Wenn das Volumen der einzelnen Datenslicepartitionen immer noch groß ist (z. B. 10 GB oder mehr), empfehlen wir Ihnen, zu einer dynamischen Bereichspartition zu wechseln. Diese Option bietet Ihnen eine größere Flexibilität bei der Definition der Anzahl der Partitionen und des Volumens der einzelnen Partitionen pro Partitionsspalte, d. h. Ober- und Untergrenze.
Für größere Tabellen (d. h. Tabellen mit einem Volumen von 100 GB oder mehr oder die nicht innerhalb von zwei Stunden zu Azure migriert werden können) empfehlen wir, die Daten durch eine benutzerdefinierte Abfrage zu partitionieren und dann jede Kopie eines Kopierauftrags einzeln zu erstellen. Sie können mehrere Azure Data Factory-Kopieraufträge gleichzeitig ausführen, um einen besseren Durchsatz zu erzielen. Für jedes Ziel eines Kopierauftrags, eine Partition per benutzerdefinierter Abfrage zu laden, können Sie den Durchsatz erhöhen, indem Sie die Parallelität entweder über den Datenslice oder den dynamischen Bereich aktivieren.
Falls Kopieraufträge aufgrund eines vorübergehenden Problems mit dem Netzwerk oder dem Datenspeicher nicht erfolgreich sind, können Sie den fehlerhaften Kopierauftrag erneut ausführen, um diese spezifische Partition aus der Tabelle zu laden. Andere Kopieraufträge, die andere Partitionen laden, sind nicht betroffen.
Wenn Sie Daten in eine Azure Synapse Analytics-Datenbank laden, wird empfohlen, PolyBase innerhalb des Kopierauftrags mit Azure Blob Storage für das Staging zu aktivieren.
Migrieren von Deltadaten
Um die neuen oder aktualisierten Zeilen aus Ihrer Tabelle zu identifizieren, verwenden Sie eine Zeitstempelspalte oder einen Inkrementierungsschlüssel innerhalb des Schemas. Sie können dann den neuesten Wert als hohen Grenzwert in einer externen Tabelle speichern und beim nächsten Laden der Daten die Deltadaten filtern.
Jede Tabelle kann eine andere Grenzwertspalte verwenden, um ihre neuen oder aktualisierten Zeilen zu identifizieren. Wir empfehlen Ihnen, eine externe Steuertabelle zu erstellen. In der Tabelle stellt jede Zeile eine Tabelle auf dem Netezza-Server mit ihrem spezifischen Namen der Grenzwertspalte und dem hohen Grenzwert dar.
Konfigurieren einer selbstgehosteten Integration Runtime
Wenn Sie Daten vom Netezza-Server zu Azure migrieren, müssen Sie unabhängig davon, ob sich der Server lokal hinter Ihrer Unternehmensfirewall oder in einer virtuellen Netzwerkumgebung befindet, eine selbstgehostete IR auf einem Windows-Computer oder einer VM installieren, die die Engine zum Verschieben von Daten darstellt. Bei der Installation des selbstgehosteten IR empfehlen wir den folgenden Ansatz:
Beginnen Sie für jeden Windows-Computer oder jede VM mit einer Konfiguration von 32 vCPUs und 128 GB Arbeitsspeicher. Sie können die Auslastung der CPU und des Arbeitsspeichers für den IR-Computer während der Datenmigration weiter überwachen. So können Sie ermitteln, ob Sie den Computer weiter hochskalieren müssen, um die Leistung zu verbessern, oder herunterskalieren müssen, um Kosten zu sparen.
Sie können auch aufskalieren, indem Sie bis zu vier Knoten einer selbstgehosteten Integration Runtime zuordnen. Bei einem einzelnen Kopierauftrag, der für eine selbstgehostete IR ausgeführt wird, werden automatisch alle VM-Knoten angewendet, um die Daten parallel zu kopieren. Zur Sicherstellung von Hochverfügbarkeit beginnen Sie mit zwei VM-Knoten, um bei der Datenmigration einen Single Point of Failure zu vermeiden.
Begrenzen der Partitionen
Die bewährte Methode besteht darin, mit einem repräsentativen Beispieldataset einen Proof of Concept-Vorgang (POC) in Bezug auf die Leistung durchzuführen, damit Sie eine geeignete Partitionsgröße für jede Kopieraktivität ermitteln können. Wir empfehlen, dass Sie jede Partition innerhalb von zwei Stunden in Azure hochladen.
Beginnen Sie zum Kopieren einer Tabelle mit einer einzelnen Kopieraktivität mit einem einzelnen Computer mit der selbstgehosteten IR. Erhöhen Sie die Einstellung parallelCopies allmählich, basierend auf der Anzahl der Datenslicepartitionen in Ihrer Tabelle. Prüfen Sie, ob die gesamte Tabelle innerhalb von zwei Stunden zu Azure geladen werden kann, je nach Durchsatz, der sich aus dem Kopierauftrag ergibt.
Wenn sie nicht innerhalb von zwei Stunden zu Azure geladen werden kann und die Kapazität des selbst gehosteten IR-Knotens und des Datenspeichers nicht voll ausgeschöpft wird, erhöhen Sie schrittweise die Anzahl der gleichzeitigen Kopieraktivitäten, bis Sie die Grenzen Ihres Netzwerks oder das Bandbreitenlimit der Datenspeicher erreichen.
Überwachen Sie weiterhin die Auslastung von CPU/Arbeitsspeicher auf dem Computer mit der selbstgehosteten IR, und halten Sie sich bereit, den Computer hochzuskalieren oder das Aufskalieren auf mehrere Computer durchzuführen, wenn die CPU und der Arbeitsspeicher voll ausgelastet sind.
Wenn für die Azure Data Factory-Kopieraktivität Drosselungsfehler gemeldet werden, sollten Sie entweder die Parallelitäts- oder die parallelCopies-Einstellung in Azure Data Factory reduzieren oder erwägen, die IOPS-/Bandbreitenlimits (Vorgänge pro Sekunde) für das Netzwerk und die Datenspeicher zu erhöhen.
Schätzen der Preise
Sehen Sie sich die folgende Pipeline an, die für die Migration von Daten vom lokalen Netezza-Server zu einer Azure Synapse Analytics-Datenbank ausgelegt ist:
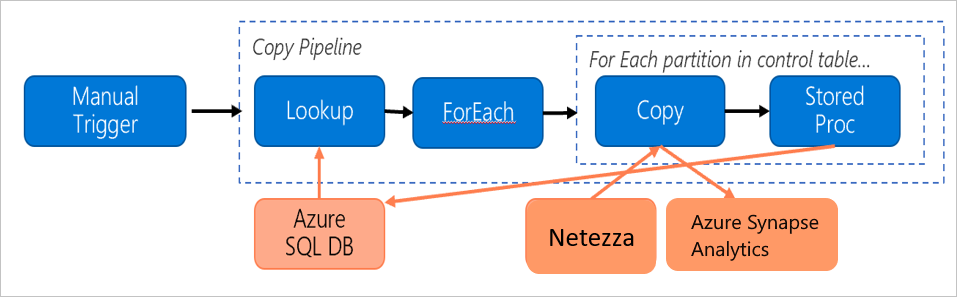
Nehmen wir an, dass die folgenden Aussagen wahr sind:
Das Gesamtdatenvolumen beträgt 50 Terabyte (TB).
Wir migrieren Daten mithilfe der ersten Lösungsarchitektur (der Netezza-Server befindet sich lokal hinter der Firewall).
Das Volumen von 50 TB ist in 500 Partitionen unterteilt, und bei jeder Kopieraktivität wird eine Partition verschoben.
Jede Kopieraktivität ist mit einer selbstgehosteten IR für vier Computer konfiguriert und erzielt einen Durchsatz von 20 MBit/s (Megabyte pro Sekunde). (Innerhalb der Kopieraktivität ist
parallelCopiesauf 4 festgelegt, und jeder Thread zum Laden von Daten aus der Tabelle erzielt einen Durchsatz von 5 MBit/s.)Die ForEach-Parallelität ist auf 3 festgelegt, und der aggregierte Durchsatz beträgt 60 MBit/s.
Insgesamt dauert es 243 Stunden, bis die Migration abgeschlossen ist.
Basierend auf den vorhergehenden Annahmen, ist hier der geschätzte Preis:
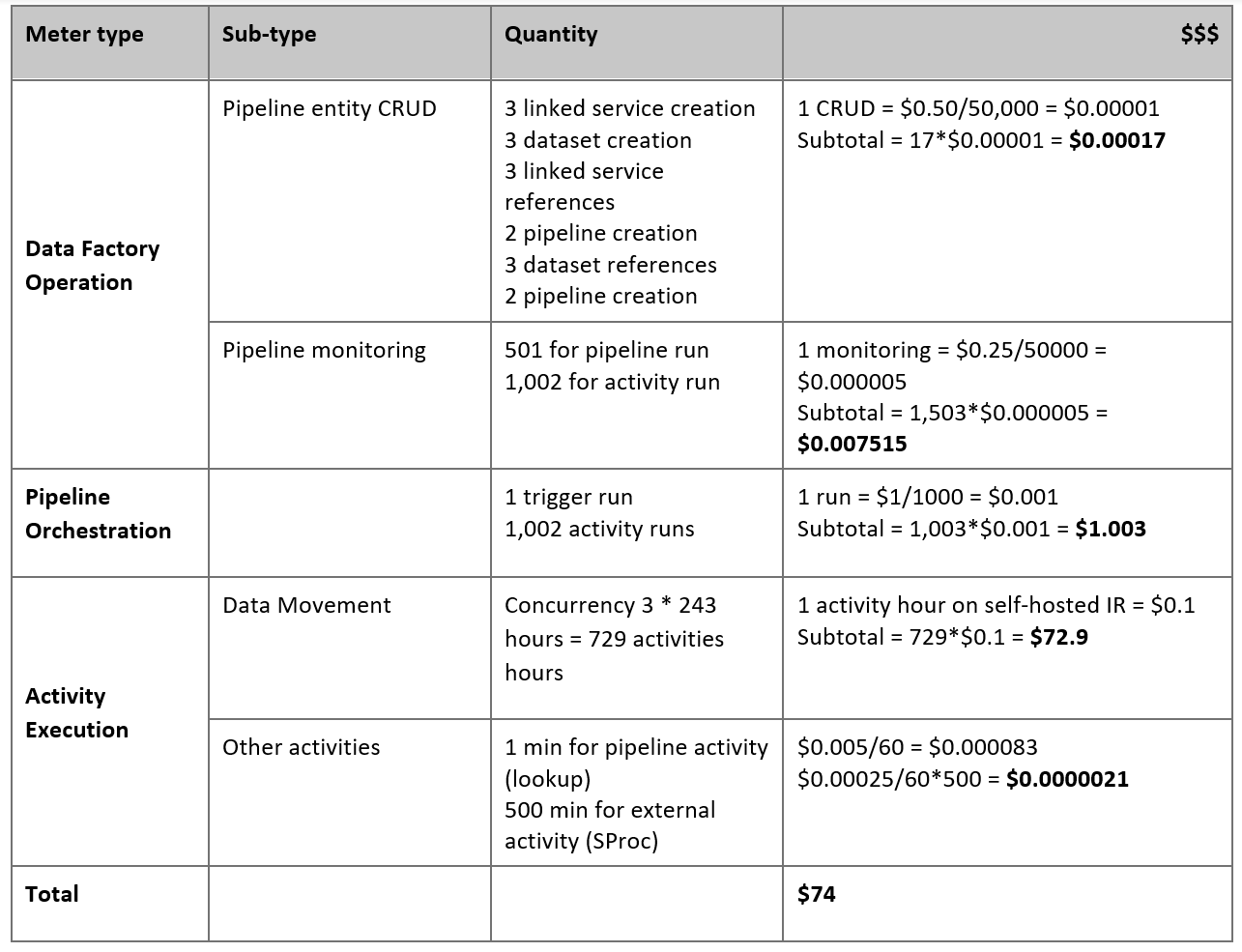
Hinweis
Die in der vorhergehenden Tabelle dargestellten Preise sind hypothetisch. Der tatsächliche Preis richtet sich nach dem tatsächlichen Durchsatz in Ihrer Umgebung. Der Preis für den Windows-Computer (mit installierter selbstgehosteter Integration Runtime) ist nicht enthalten.
Zusätzliche Verweise
Weitere Informationen finden Sie in den folgenden Artikeln und Leitfäden:
- Netezza-Connector
- ODBC-Connector
- Azure Blob Storage-Connector
- Azure Data Lake Storage Gen2-Connector
- Azure Synapse Analytics-Connector
- Handbuch zur Leistung und Optimierung der Kopieraktivität
- Erstellen und Konfigurieren einer selbstgehosteten Integration Runtime
- Selbstgehostete Integration Runtime: Hochverfügbarkeit und Skalierbarkeit
- Sicherheitsüberlegungen für Datenverschiebung in Azure Data Factory
- Speichern von Anmeldeinformationen in Azure Key Vault
- Inkrementelles Kopieren von Daten aus einer einzelnen Tabelle
- Inkrementelles Kopieren von Daten aus mehreren Tabellen
- Azure Data Factory – Preise