Verwenden von Azure Data Factory zum Migrieren von Daten von einem lokalen Hadoop-Cluster zu Azure Storage
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Azure Data Factory stellt einen leistungsstarken, stabilen und kostengünstigen Mechanismus bereit, um Daten bedarfsabhängig vom lokalen HDFS zu Azure Blob Storage oder Azure Data Lake Storage Gen2 zu migrieren.
Data Factory bietet zwei grundlegende Methoden, um Daten vom lokalen HDFS zu Azure zu migrieren. Sie können die jeweilige Methode basierend auf Ihrem Szenario auswählen.
- Data Factory-DistCp-Modus (empfohlen): In Data Factory können Sie DistCp (Distributed Copy, verteiltes Kopieren) verwenden, um Dateien unverändert in Azure Blob Storage (einschließlich gestaffelten Kopierens) oder Azure Data Lake Store Gen2 zu kopieren. Verwenden Sie in Data Factory integriertes DistCp, um einen vorhandenen leistungsfähigen Cluster zu nutzen und einen optimalen Kopierdurchsatz zu erzielen. Außerdem profitieren Sie von der flexiblen Planung und einer einheitlichen Überwachung von Data Factory. Abhängig von Ihrer Data Factory-Konfiguration erstellt die Kopieraktivität automatisch einen DistCp-Befehl, sendet die Daten an den Hadoop-Cluster und überwacht dann den Kopierstatus. Der DistCp-Modus von Data Factory wird zum Migrieren von Daten von einem lokalen Hadoop-Cluster zu Azure empfohlen.
- Nativer Integration Runtime-Modus von Data Factory: DistCp ist nicht in allen Szenarien eine Option. Beispielsweise unterstützt das DistCp-Tool in einer Azure Virtual Network-Umgebung nicht das private ExpressRoute-Peering mit einem virtuellen Azure Storage-Netzwerkendpunkt. In einigen Fällen soll außerdem nicht der vorhandene Hadoop-Cluster als Engine zum Migrieren von Daten verwendet werden, damit sich keine hohen Lasten für den Cluster ergeben, da sich dies auf die Leistung vorhandener ETL-Aufträge auswirken kann. Stattdessen können Sie die native Integration Runtime-Funktion in Data Factory als Engine verwenden, mit der Daten vom lokalen HDFS in Azure kopiert werden.
Dieser Artikel enthält die folgenden Informationen zu beiden Methoden:
- Leistung
- Resilienz beim Kopieren
- Netzwerksicherheit
- Allgemeine Lösungsarchitektur
- Bewährte Methoden für die Implementierung
Leistung
Im DistCp-Modus von Data Factory entspricht der Durchsatz dem der unabhängigen Verwendung des DistCp-Tools. Mit dem DistCp-Modus von Data Factory wird die Kapazität des vorhandenen Hadoop-Clusters maximiert. Sie können DistCp für umfangreiche Kopiervorgänge innerhalb von und zwischen Clustern verwenden.
DistCp verwendet MapReduce, um die Verteilung, die Fehlerbehandlung und -behebung sowie die Berichterstellung zu steuern. Das Tool erweitert eine Liste von Dateien und Verzeichnissen in eine Eingabe für die Aufgabenzuordnung. Mit jeder Aufgabe wird jeweils eine in der Quellliste angegebene Dateipartition kopiert. Durch Verwendung von Data Factory mit Integration in DistCp können Sie Pipelines erstellen, um die Netzwerkbandbreite sowie IOPS und Bandbreite des Speichers in vollem Umfang zu nutzen und so den Datenverschiebungsdurchsatz in der Umgebung zu maximieren.
Im nativen Integration Runtime-Modus von Data Factory ist außerdem Parallelität auf unterschiedlichen Ebenen möglich. Durch Verwendung von Parallelität lassen sich die Netzwerkbandbreite, die IOPS und die allgemeine Bandbreite in vollem Umfang nutzen, um den Datenverschiebungsdurchsatz zu maximieren:
- Eine einzelne Kopieraktivität kann skalierbare Computeressourcen nutzen. Mit einer selbstgehosteten Integration Runtime können Sie den Computer manuell hochskalieren oder auf mehrere Computer (bis zu vier Knoten) aufskalieren. Bei einer einzelnen Kopieraktivität wird die Dateigruppe auf alle Knoten verteilt.
- Für eine Kopieraktivität werden mehrere Threads genutzt, um für den Datenspeicher Lese- und Schreibvorgänge durchzuführen.
- Mit der Data Factory-Ablaufsteuerung können mehrere Kopieraktivitäten parallel gestartet werden. Beispielsweise können Sie eine ForEach-Schleife verwenden.
Weitere Informationen finden Sie unter Handbuch zur Leistung und Skalierbarkeit der Kopieraktivität.
Resilienz
Im DistCp-Modus von Data Factory können Sie verschiedene DistCp-Befehlszeilenparameter (z. B. -i: Fehler ignorieren oder -update: Daten schreiben, wenn Quelldatei und Zieldatei eine unterschiedliche Größe aufweisen), für unterschiedliche Resilienzebenen nutzen.
Im nativen Integration Runtime-Modus verfügt Data Factory bei der Ausführung einer einzelnen Kopieraktivität über einen integrierten Wiederholungsmechanismus. Damit kann ein gewisses Maß an vorübergehenden Fehlern in den Datenspeichern oder im zugrunde liegenden Netzwerk verarbeitet werden.
Beim Durchführen von binären Kopiervorgängen vom lokalen HDFS in Blob Storage und vom lokalen HDFS zu Data Lake Store Gen2 werden in Data Factory automatisch Prüfpunkte in großem Umfang gesetzt. Wenn beim Ausführen einer Kopieraktivität ein Fehler oder Timeout auftritt, wird der Vorgang bei einer darauffolgenden Wiederholung (Wiederholungsanzahl muss > 1 sein) ab dem letzten Fehlerpunkt fortgesetzt und nicht wieder am Anfang gestartet.
Netzwerksicherheit
Standardmäßig werden Daten mit Data Factory über eine verschlüsselte Verbindung per HTTPS-Protokoll vom lokalen HDFS in Blob Storage oder Azure Data Lake Storage Gen2 übertragen. HTTPS ermöglicht die Datenverschlüsselung während der Übertragung und verhindert Abhör- und Man-in-the-Middle-Angriffe.
Wenn Sie nicht möchten, dass Daten über das öffentliche Internet übertragen werden, können Sie alternativ aus Sicherheitsgründen Daten über einen privaten Peeringlink per ExpressRoute übertragen.
Lösungsarchitektur
In dieser Abbildung ist die Migration von Daten über das öffentliche Internet dargestellt:
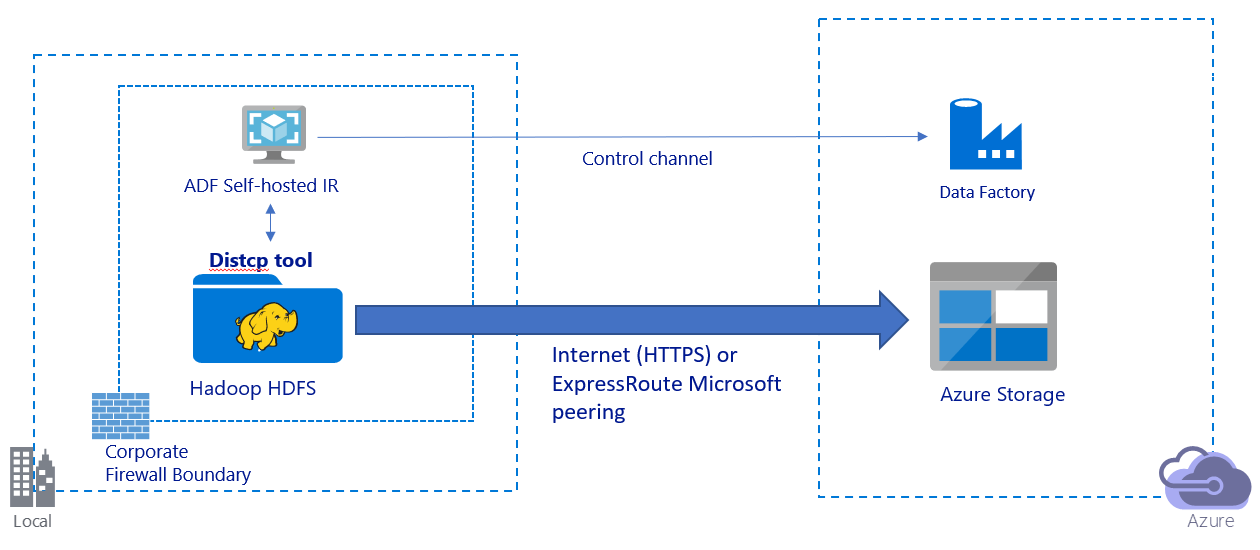
- Bei dieser Architektur werden Daten auf sichere Weise per HTTPS über das öffentliche Internet übertragen.
- Der DistCp-Modus von Data Factory wird für die Verwendung in einer öffentlichen Netzwerkumgebung empfohlen. Dadurch können Sie einen vorhandenen leistungsfähigen Cluster nutzen, um einen optimalen Kopierdurchsatz zu erzielen. Außerdem profitieren Sie von der flexiblen Planung und einheitlichen Überwachung von Data Factory.
- Bei dieser Architektur müssen Sie die selbstgehostete Integration Runtime von Data Factory auf einem Windows-Computer hinter einer Unternehmensfirewall installieren, damit der DistCp-Befehl an den Hadoop-Cluster gesendet und der Kopierstatus überwacht werden kann. Da der Computer nicht als Engine zum Verschieben von Daten verwendet wird (sondern nur zur Steuerung), wirkt sich die Kapazität des Computers nicht auf den Durchsatz der Datenverschiebung aus.
- Die vorhandenen Parameter für den DistCp-Befehl werden unterstützt.
In dieser Abbildung ist die Migration von Daten über einen privaten Link dargestellt:
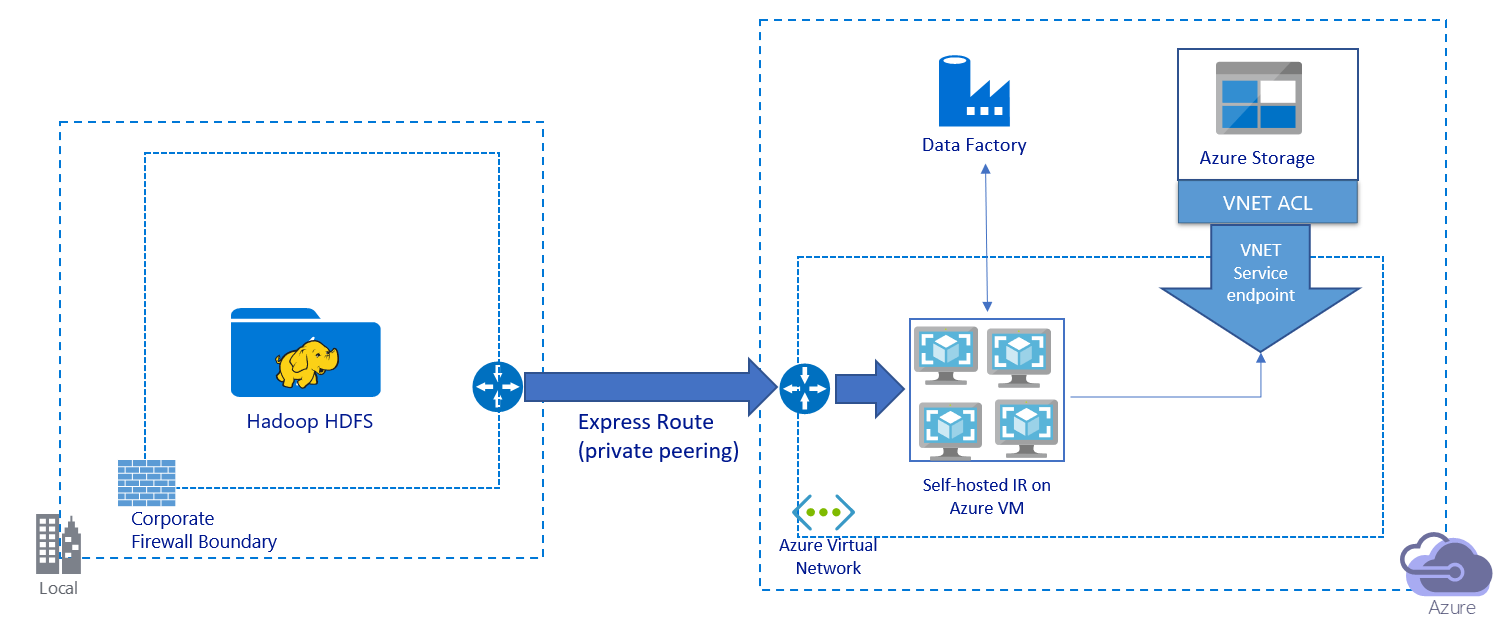
- Bei dieser Architektur werden Daten über einen privaten Peeringlink per Azure ExpressRoute migriert. Die Daten werden nie über das öffentliche Internet übertragen.
- Das DistCp-Tool unterstützt kein privates ExpressRoute-Peering mit einem virtuellen Azure Storage-Netzwerkendpunkt. Es wird empfohlen, die Daten mithilfe der nativen Data Factory-Funktion über die Integration Runtime zu migrieren.
- Bei dieser Architektur müssen Sie die selbstgehostete Integration Runtime von Data Factory auf einem virtuellen Windows-Computer in Ihrem virtuellen Azure-Netzwerk installieren. Sie können den virtuellen Computer manuell zentral hochskalieren oder das horizontale Hochskalieren auf mehrere virtuelle Computer durchführen, um IOPS und Bandbreite für Netzwerk und Speicher im vollem Umfang zu nutzen.
- Die empfohlene Konfiguration, mit der für jeden virtuellen Azure-Computer (mit installierter selbstgehosteter Integration Runtime von Data Factory) begonnen werden sollte, ist „Standard_D32s_v3“ mit 32 vCPUs und 128 GB Arbeitsspeicher. Sie können die Auslastung der CPU und des Arbeitsspeichers für den virtuellen Computer während der Datenmigration überwachen. So können Sie ermitteln, ob Sie den virtuellen Computer zentral hochskalieren müssen, um die Leistung zu verbessern, oder ihn stattdessen zentral herunterskalieren müssen, um Kosten zu senken.
- Sie können auch horizontal hochskalieren, indem Sie bis zu vier VM-Knoten einer selbstgehosteten Integration Runtime zuordnen. Bei einem einzelnen Kopierauftrag, der für eine selbstgehostete Integration Runtime ausgeführt wird, wird die Dateigruppe automatisch partitioniert, und alle VM-Knoten werden genutzt, um die Dateien parallel zu kopieren. Zur Sicherstellung von Hochverfügbarkeit wird empfohlen, mit zwei VM-Knoten zu beginnen, um bei der Datenmigration das Szenario eines Single Point of Failure zu vermeiden.
- Bei Verwendung dieser Architektur ist die Migration sowohl der Daten einer Anfangsmomentaufnahme als auch der Deltadaten möglich.
Bewährte Methoden für die Implementierung
Bei der Implementierung der Datenmigration empfehlen sich folgende bewährte Methoden.
Authentifizierung und Verwaltung von Anmeldeinformationen
- Zum Authentifizieren bei HDFS können Sie entweder „Windows“ (Kerberos) oder „Anonym“ verwenden.
- Für die Herstellung einer Verbindung mit Azure Blob Storage werden mehrere Authentifizierungstypen unterstützt. Wir empfehlen dringend die Verwendung von verwalteten Identitäten für Azure-Ressourcen. Verwaltete Identitäten basieren auf einer automatisch verwalteten Data Factory-Identität in Microsoft Entra ID und ermöglichen Ihnen die Konfiguration von Pipelines, ohne dass in der Definition des verknüpften Diensts Anmeldeinformationen angegeben werden müssen. Alternativ können Sie die Authentifizierung für Blob Storage auch per Dienstprinzipal, Shared Access Signature oder Speicherkontoschlüssel durchführen.
- Auch für die Herstellung einer Verbindung mit Data Lake Storage Gen2 werden mehrere Authentifizierungstypen unterstützt. Die Verwendung von verwalteten Identitäten für Azure-Ressourcen wird dringend empfohlen. Sie können aber auch einen Dienstprinzipal oder einen Speicherkontoschlüssel verwenden.
- Wenn Sie keine verwalteten Identitäten für Azure-Ressourcen verwenden, ist das Speichern der Anmeldeinformationen in Azure Key Vault dringend zu empfehlen, um das zentrale Verwalten und Rotieren von Schlüsseln ohne Änderung der verknüpften Azure Data Factory-Dienste zu vereinfachen. Dies ist auch eine bewährte Methode für CI/CD.
Migration der Daten der Anfangsmomentaufnahme
Im DistCp-Modus von Data Factory können Sie eine Kopieraktivität erstellen, um den DistCp-Befehl zu senden und unterschiedliche Parameter zu verwenden und so das anfängliche Datenmigrationsverhalten zu steuern.
Im nativen Integration Runtime-Modus von Data Factory ist die Datenpartition empfehlenswert, vor allem, wenn mehr als 10 TB an Daten migriert werden. Verwenden Sie zum Partitionieren der Daten die Ordnernamen in HDFS. Anschließend kann mit jedem Data Factory-Kopierauftrag jeweils eine Ordnerpartition kopiert werden. Sie können mehrere Data Factory-Kopieraufträge gleichzeitig ausführen, um einen besseren Durchsatz zu erzielen.
Wenn Kopieraufträge aufgrund eines vorübergehenden Problems mit dem Netzwerk oder dem Datenspeicher nicht erfolgreich sind, können Sie den fehlerhaften Kopierauftrag erneut ausführen, um diese spezifische Partition erneut in HDFS zu laden. Andere Kopieraufträge, mit denen andere Partitionen geladen werden, sind nicht betroffen.
Migration von Deltadaten
Im DistCp-Modus von Data Factory können Sie den DistCp-Befehlszeilenparameter -update (Daten schreiben, wenn Quelldatei und Zieldatei eine unterschiedliche Größe aufweisen) für die Migration von Deltadaten verwenden.
Im nativen Integration Runtime-Modus von Data Factory ist die Verwendung einer Namenskonvention mit Zeitpartitionierung am effizientesten zum Identifizieren von neuen oder geänderten Dateien aus HDFS. Wenn für die Daten in HDFS die Zeitpartitionierung mit Zeitsegmentinformationen im Datei- oder Ordnernamen durchgeführt wurde (z. B. /jjjj/mm/tt/file.csv), kann in der Pipeline einfach ermittelt werden, welche Dateien und Ordner inkrementell kopiert werden müssen.
Wenn die Daten in HDFS nicht über eine Zeitpartitionierung verfügen, kann Data Factory neue oder geänderte Dateien anhand des Werts LastModifiedDate identifizieren. Data Factory scannt alle Dateien aus HDFS und kopiert nur die neuen und aktualisierten Dateien, deren Zeitstempel der letzten Änderung größer als ein festgelegter Wert ist.
Bei einer großen Anzahl von Dateien in HDFS kann der erste Scanvorgang für die Dateien unabhängig davon, wie viele Dateien mit der Filterbedingung übereinstimmen, sehr lange dauern. In diesem Fall sollten Sie die Daten zunächst partitionieren, indem Sie die für die Migration der Anfangsmomentaufnahme verwendete Partition verwenden. Der Scanvorgang kann anschließend parallel erfolgen.
Preisschätzung
Sehen Sie sich die folgende Pipeline für die Migration von Daten aus HDFS zu Azure Blob Storage an:
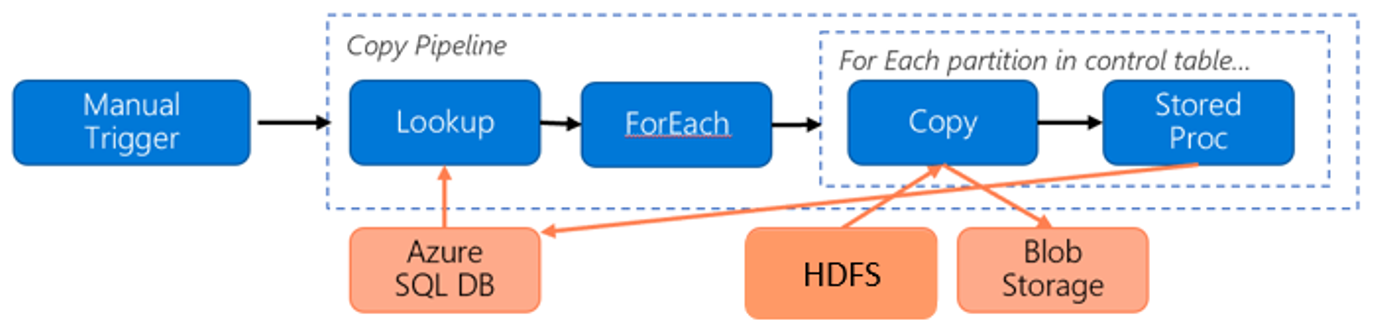
Wir gehen von Folgendem aus:
- Das gesamte Datenvolumen beträgt 1 PB.
- Sie migrieren die Daten mit dem nativen Integration Runtime-Modus von Data Factory.
- Die 1 PB sind in 1.000 Partitionen unterteilt. Bei jedem Kopiervorgang wird eine Partition verschoben.
- Jede Kopieraktivität ist mit einer selbstgehosteten Integration Runtime konfiguriert, die vier Computern zugeordnet ist, und erzielt einen Durchsatz von 500 MBit/s.
- Die ForEach-Parallelität ist auf 4 festgelegt. Der aggregierte Durchsatz beträgt 2 GBit/s.
- Insgesamt dauert es 146 Stunden, bis die Migration abgeschlossen ist.
Hier ist der geschätzte Preis basierend auf diesen Annahmen angegeben:
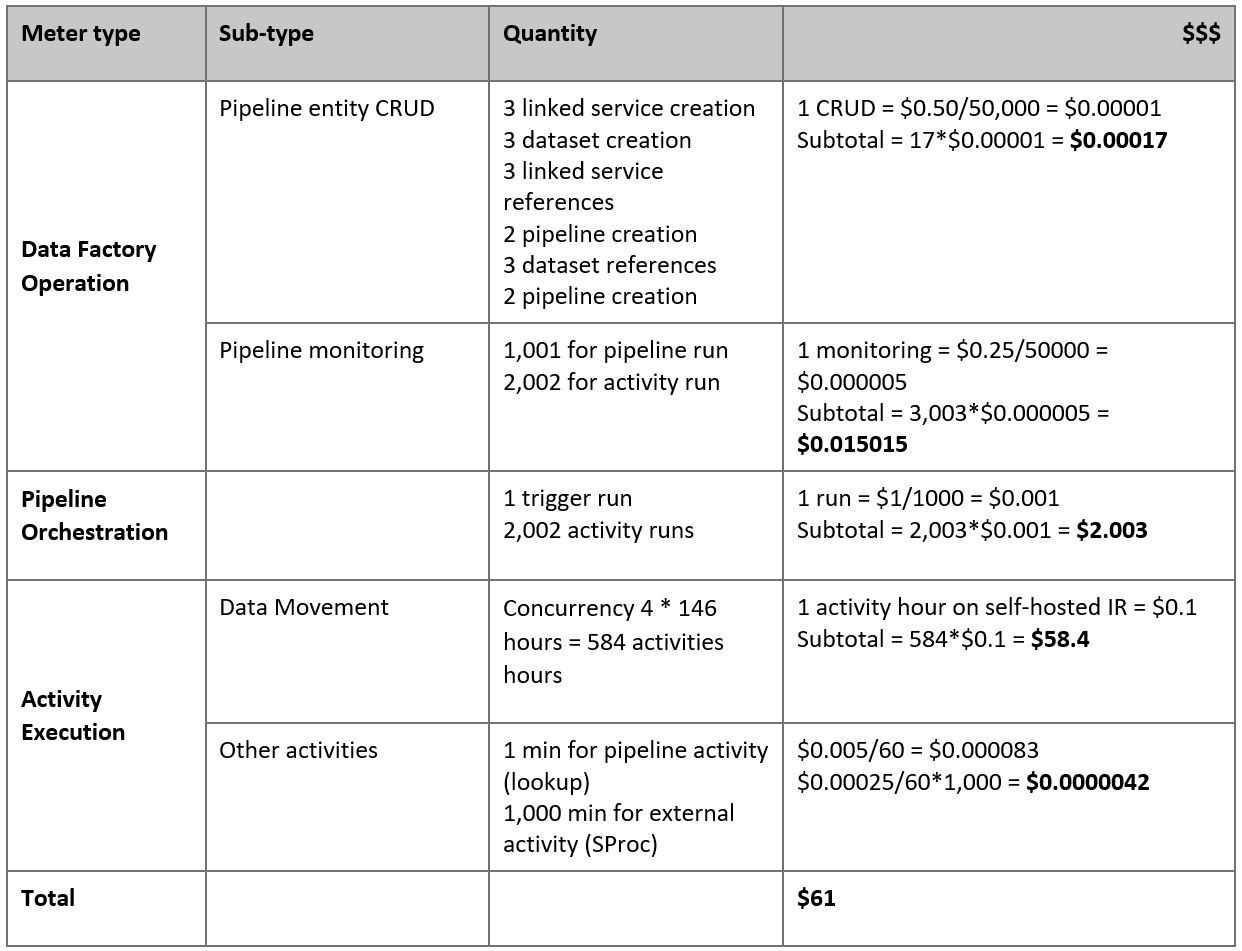
Hinweis
Dies ist ein hypothetisches Preisbeispiel. Der tatsächliche Preis richtet sich nach dem tatsächlichen Durchsatz in Ihrer Umgebung. Der Preis für einen virtuellen Azure-Computer (mit installierter selbstgehosteter Integration Runtime) ist nicht enthalten.
Weitere Verweise
- HDFS-Connector
- Azure Blob Storage-Connector
- Azure Data Lake Storage Gen2-Connector
- Handbuch zur Leistung und Optimierung der Kopieraktivität
- Erstellen und Konfigurieren einer selbstgehosteten Integration Runtime
- Selbstgehostete Integration Runtime: Hochverfügbarkeit und Skalierbarkeit
- Sicherheitsüberlegungen für Datenverschiebung in Azure Data Factory
- Speichern von Anmeldeinformationen in Azure Key Vault
- Inkrementelles Kopieren neuer Dateien basierend auf dem zeitpartitionierten Dateinamen und mithilfe des Tools „Daten kopieren“
- Inkrementelles Kopieren neuer und geänderter Dateien auf Basis von LastModifiedDate und mithilfe des Tools zum Kopieren von Daten
- Preisübersicht für Data Factory