Transformation zum Sortieren in einem Zuordnungsdatenfluss
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory als auch in Azure Synapse-Pipelines verfügbar. Dieser Artikel gilt für Zuordnungsdatenflüsse. Wenn Sie noch nicht mit Transformationen arbeiten, lesen Sie den Einführungsartikel Transformieren von Daten mit einem Zuordnungsdatenfluss.
Mit der Transformation zum Sortieren können Sie die eingehenden Zeilen im aktuellen Datenstrom sortieren. Sie können einzelne Spalten auswählen und in aufsteigender oder absteigender Reihenfolge sortieren.
Hinweis
Zuordnungsdatenflüsse werden auf Spark-Clustern ausgeführt, die Daten auf mehrere Knoten und Partitionen verteilen. Wenn Sie Ihre Daten in einer nachfolgenden Transformation neu partitionieren möchten, geht Ihre Sortierung möglicherweise aufgrund dieser Umverteilung von Daten verloren. Die beste Möglichkeit, die Sortierreihenfolge in Ihrem Datenfluss zu verwalten, besteht darin, eine einzelne Partition auf der Registerkarte „Optimieren“ für die Transformation festzulegen und die Sortiertransformation so nah wie möglich an der Senke zu platzieren.
Konfiguration
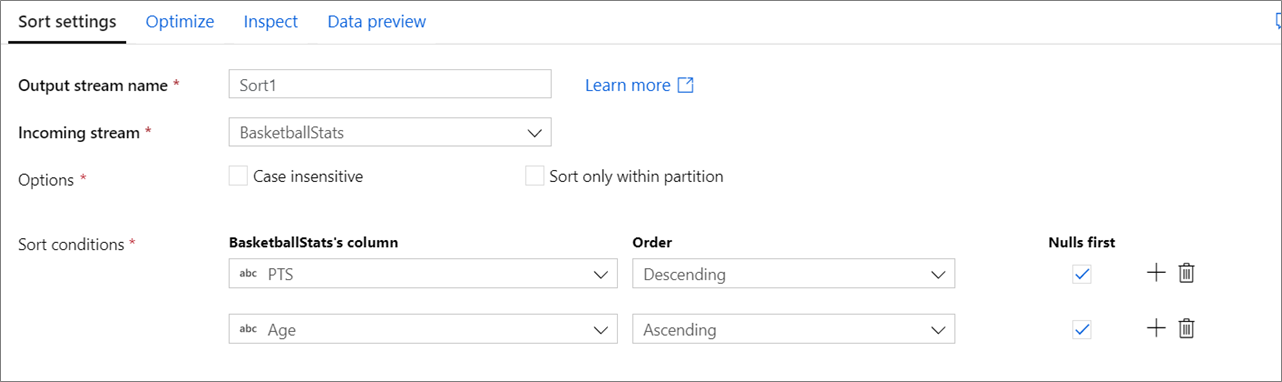
Keine Beachtung von Groß-/Kleinschreibung: Legen Sie fest, ob die Groß-/Kleinschreibung beim Sortieren von Zeichenfolgen- oder Textfeldern ignoriert werden soll.
Nur innerhalb von Partitionen sortieren: Wenn Datenflüsse auf Spark ausgeführt werden, wird jeder Datenfluss in Partitionen unterteilt. Mit dieser Einstellung werden Daten nur innerhalb der eingehenden Partitionen und nicht im gesamten Datenstrom sortiert.
Sortierbedingungen: Wählen Sie aus, welche Spalten sortiert werden sollen und in welcher Reihenfolge die Sortierung erfolgt. Die Reihenfolge bestimmt die Sortierpriorität. Legen Sie fest, ob Nullen am Anfang und Ende des Datenstroms gezeigt werden.
Berechnete Spalten
Um einen Spaltenwert vor der Sortierung zu ändern oder zu extrahieren, zeigen Sie auf die Spalte und wählen „Berechnete Spalte“ aus. Dadurch wird für die Sortierung kein Spaltenwert verwendet, sondern der Ausdrucks-Generator geöffnet, um einen Ausdruck für den Sortiervorgang zu erstellen.
Datenflussskript
Syntax
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
Beispiel
Der nachfolgende Codeausschnitt zeigt das Datenflussskript für die obige Konfiguration der Sortierung.
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
Zugehöriger Inhalt
Nach dem Sortieren können Sie die Transformation für das Aggregieren verwenden.