Assert-Transformation in einem Zuordnungsdatenfluss
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory als auch in Azure Synapse-Pipelines verfügbar. Dieser Artikel gilt für Zuordnungsdatenflüsse. Wenn Sie noch nicht mit Transformationen arbeiten, lesen Sie den Einführungsartikel Transformieren von Daten mit einem Zuordnungsdatenfluss.
Mit der Assert-Transformation können Sie benutzerdefinierte Regeln zur Datenqualität und Datenüberprüfung in Ihren Zuordnungsdatenflüssen erstellen. Sie können Regeln erstellen, die bestimmen, ob Werte einer erwarteten Wertdomäne entsprechen. Darüber hinaus können Sie Regeln erstellen, die die Eindeutigkeit von Zeilen überprüfen. Mit der Assert-Transformation können Sie überprüfen, ob jede Zeile in Ihren Daten bestimmte Kriterien erfüllt. Außerdem können Sie mit der Assert-Transformation benutzerdefinierte Fehlermeldungen festlegen, die angezeigt werden, wenn die Datenüberprüfungsregeln nicht erfüllt werden.
Konfiguration
Im Konfigurationsbereich für Assert-Transformationen wählen Sie den Assert-Typ aus, geben der Assertion einen eindeutigen Namen und optional eine Beschreibung und definieren den Ausdruck und optional einen Filter. Im Datenvorschaubereich wird angegeben, welche Zeilen Ihre Assertionen nicht bestanden haben. Darüber hinaus können Sie jedes Zeilentag nachgelagert mithilfe von isError() und hasError() auf Zeilen testen, bei denen Assertionen fehlgeschlagen sind.
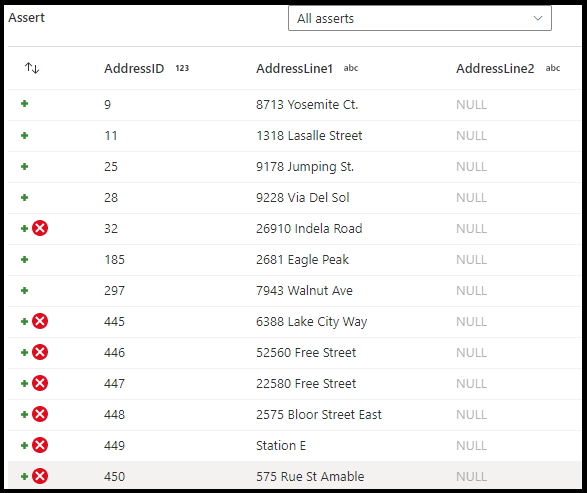
Assert-Typ
- Expect true („TRUE“ erwarten): Das Ergebnis Ihres Ausdrucks muss zu einem booleschen „True“-Ergebnis ausgewertet werden. Verwenden Sie diese Einstellung, um Domänenwertbereiche in Ihren Daten zu überprüfen.
- Expect unique („Unique“ erwarten): Legen Sie eine Spalte oder einen Ausdruck als Eindeutigkeitsregel in Ihren Daten fest. Verwenden Sie diese Einstellung, um doppelte Zeilen zu markieren.
- Expect exists (Vorhandensein erwartet): Diese Option ist nur verfügbar, wenn Sie einen zweiten eingehenden Datenstrom ausgewählt haben. „Exists“ untersucht beide Datenströme und bestimmt basierend auf den angegebenen Ausdrücken, ob die Spalten in beiden Datenströmen vorhanden sind. Wählen Sie
Additional streamsaus, um einen zweiten Datenstrom für „exists“ hinzuzufügen.
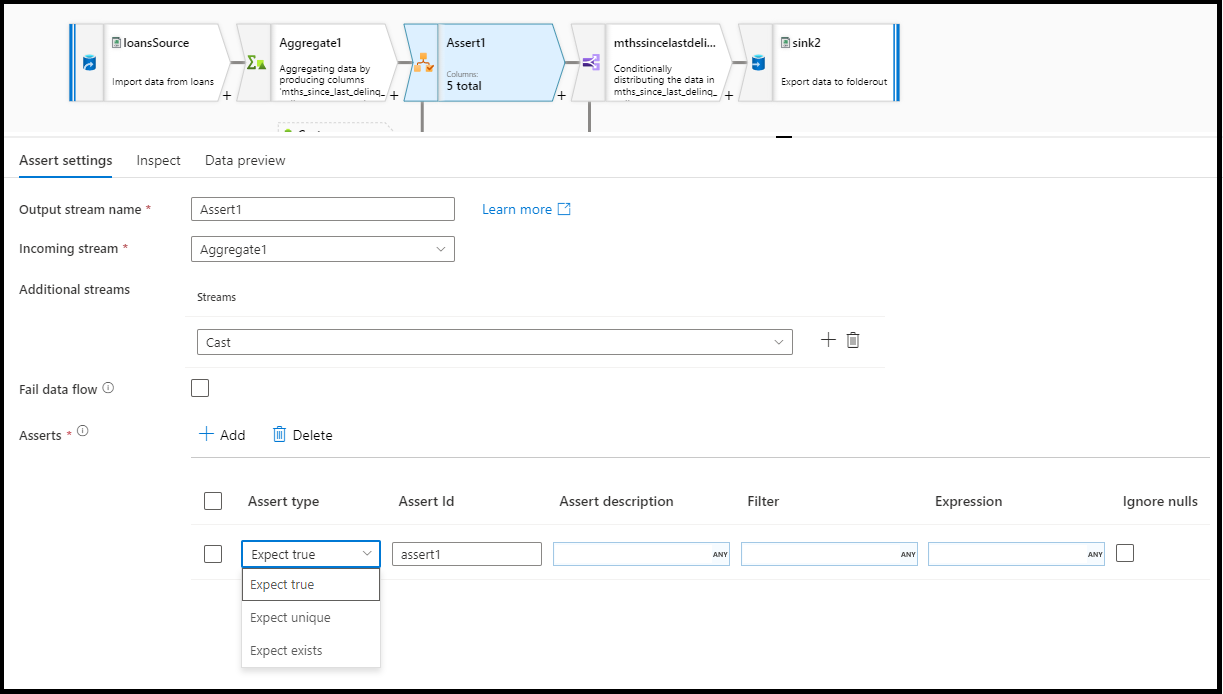
Fail data flow
Wählen Sie fail data flow aus, wenn die Datenflussaktivität sofort fehlschlagen soll, sobald die Assertionsregel fehlschlägt.
Assert-ID
Die Assert-ID ist eine Eigenschaft, für die Sie einen Namen (als Zeichenfolge) für Ihre Assertion eingeben. Sie können den Bezeichner später mit hasError() in Ihrem Datenfluss verwenden oder damit den Fehlercode der Assertion ausgeben. Assert-IDs müssen innerhalb jedes Dataflows eindeutig sein.
Assert-Beschreibung
Geben Sie hier eine Zeichenfolgenbeschreibung für Ihre Assertion ein. Sie können hier auch Ausdrücke und Zeilen-Kontext-Spaltenwerte verwenden.
Filtern
Filter ist eine optionale Eigenschaft, mit der Sie die Assertion basierend auf Ihrem Ausdruckswert nach einer Teilmenge von Zeilen filtern können.
Ausdruck
Geben Sie einen Ausdruck zur Auswertung jeder Ihrer Assertionen ein. Sie können mehrere Assertionen für jede Assert-Transformation haben. Jeder Assertionstyp erfordert einen Ausdruck, den ADF auswerten muss, um zu testen, ob die Assertion erfolgreich war.
Ignorieren von NULL-Werten
Die Assert-Transformation schließt standardmäßig NULL-Werte in die Auswertung von Zeilenassertionen ein. Sie können NULL-Werte mit dieser Eigenschaft ignorieren.
Direktes Bestätigen von Zeilenfehlern
Wenn eine Assertion fehlschlägt, können Sie diese Fehlerzeilen optional mithilfe der Registerkarte „Fehler" in der Senktransformation an eine Datei in Azure weiterleiten. Sie haben auch die Möglichkeit, bei der Senkentransformation keine Zeilen mit Assertionsfehlern auszugeben, indem Sie Fehlerzeilen ignorieren.
Beispiele
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Datenflussskript
Beispiele
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Zugehöriger Inhalt
- Verwenden Sie Transformation auswählen, um Spalten auswählen und zu überprüfen.
- Verwenden Sie Derived column transformation (Transformation für abgeleitete Spalten), um Spaltenwerte zu transformieren.