Integrationslaufzeit in Azure Data Factory
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Bei der Integration Runtime (IR) handelt es sich um die Compute-Infrastruktur, mit der Azure Data Factory- und Azure Synapse-Pipelines die folgenden Datenintegrationsfunktionen übergreifend für verschiedene Netzwerkumgebungen bereitstellen:
- Datenfluss: Ausführen eines Datenflusses in einer verwalteten Azure-Compute-Umgebung.
- Datenverschiebung: Kopieren Sie Daten zwischen Datenspeichern in einem öffentlichen oder privaten Netzwerk (sowohl für lokale als auch für virtuelle private Netzwerke). Der Dienst bietet Unterstützung für integrierte Connectors, Formatkonvertierung, Spaltenzuordnung und eine leistungsstarke und skalierbare Datenübertragung.
- Aktivitätsverteilung: Dient zum Verteilen und Überwachen von Transformationsaktivitäten, die in vielen verschiedenen Computediensten wie Azure Databricks, Azure HDInsight, ML Studio (klassisch), Azure SQL-Datenbank, SQL Server und vielen weiteren ausgeführt werden.
- SSIS-Paketausführung: Dient zum nativen Ausführen von SSIS-Paketen (SQL Server Integration Services) in einer verwalteten Azure-Computeumgebung.
In Data Factory und Synapse-Pipelines wird mit einer Aktivität eine durchzuführende Aktion definiert. Mit einem verknüpften Dienst wird ein Zieldatenspeicher oder ein Computedienst definiert. Eine Integration Runtime stellt die Brücke zwischen Aktivitäten und verknüpften Diensten dar. Sie wird vom verknüpften Dienst oder der Aktivität referenziert und stellt die Compute-Umgebung bereit, in der die Aktivität entweder direkt ausgeführt oder verteilt wird. Auf diese Weise kann die Aktivität in der Region durchgeführt werden, die dem Zieldatenspeicher oder Computedienst am nächsten liegt, um die Leistung zu maximieren und gleichzeitig die Flexibilität zu gewährleisten, Sicherheits- und Complianceanforderungen zu erfüllen.
Integration Runtimes können in der Azure Data Factory- und der Azure Synapse-Benutzeroberfläche über den Verwaltungshub direkt erstellt werden, ebenso wie aus allen Aktivitäten, Datasets oder Datenflüssen, die auf sie verweisen.
Integrationslaufzeit-Typen
Data Factory bietet drei Arten von Integration Runtime (IR) an, und Sie sollten den Typ wählen, der Ihren Datenintegrationsfähigkeiten und Anforderungen an die Netzwerkumgebung am besten entspricht. Die drei IR-Typen sind:
- Azure
- Selbstgehostet
- Azure-SSIS
Hinweis
Synapse-Pipelines unterstützen derzeit nur Azure- oder selbstgehostete Integration Runtime-Instanzen.
In der folgenden Tabelle sind die Funktionen und die Netzwerkunterstützung für die einzelnen Integrationslaufzeit-Typen beschrieben:
| IR-Typ | Unterstützung für öffentliche Netzwerke | Private Link-Unterstützung |
|---|---|---|
| Azure | Datenfluss Datenverschiebung Aktivitätsverteilung |
Datenfluss Datenverschiebung Aktivitätsverteilung |
| Selbstgehostet | Datenverschiebung Aktivitätsverteilung |
Datenverschiebung Aktivitätsverteilung |
| Azure-SSIS | SSIS-Paketausführung | SSIS-Paketausführung |
Hinweis
Ausgehende Steuerelemente variieren nach Dienst für Azure IR. In Synapse verfügen Arbeitsbereiche über Optionen zum Einschränken von ausgehendem Datenverkehr aus dem verwalteten virtuellen Netzwerk bei Verwendung von Azure IR. In Data Factory werden alle Ports für die ausgehende Kommunikation geöffnet, wenn Azure IR verwendet wird. Azure-SSIS IR kann in Ihr VNet integriert werden, um Steuerelemente für die ausgehende Kommunikation bereitzustellen.
Azure-Integrationslaufzeit
Eine Azure Integration Runtime bietet folgende Möglichkeiten:
- Ausführen von Datenflüssen in Azure
- Ausführen von Copy-Aktivitäten zwischen Clouddatenspeichern
- Bereitstellen der folgenden Transformationsaktivitäten in einem öffentlichen Netzwerk:
- Benutzerdefinierte .NET-Aktivität
- Aktivität „Azure Function“
- Databricks Notebook-/ Jar-/ Python-Aktivität
- U-SQL-Aktivität für Data Lake Analytics
- Aktivität „Metadaten abrufen“
- HDInsight Hive-Aktivität
- HDInsight Pig-Aktivität
- HDInsight MapReduce-Aktivität
- HDInsight Spark-Aktivität
- HDInsight-Streamingaktivität
- Lookup-Aktivität
- Batch Execution-Aktivität für Machine Learning Studio (klassisch)
- Ressourcenaktualisierungsaktivität für Azure Machine Learning Studio (klassisch)
- Aktivität der gespeicherten Prozedur
- Aktivität „Prüfung“
- Webaktivität
Azure-Integrationslaufzeit: Netzwerkumgebung
Die Azure Integration Runtime unterstützt die Herstellung von Verbindungen mit Datenspeichern und Computediensten mit öffentlich zugänglichen Endpunkten. Indem ein verwaltetes virtuelles Netzwerk aktiviert wird, unterstützt Azure Integration Runtime das Herstellen einer Verbindung mit Datenspeichern über den privaten Verknüpfungsdienst in einer privaten Netzwerkumgebung. In Synapse verfügen Arbeitsbereiche über Optionen zum Einschränken von ausgehendem Datenverkehr aus dem verwalteten virtuellen Netzwerk der IR. In Data Factory sind alle Ports sind für die ausgehende Kommunikation geöffnet. Azure-SSIS IR kann in Ihr VNet integriert werden, um Steuerelement für die ausgehende Kommunikation bereitzustellen.
Azure-Integrationslaufzeit: Computeressource und Skalierung
Die Azure-Integrationslaufzeit stellt in Azure eine vollständig verwaltete, serverlose Computeressource bereit. Sie müssen sich keine Gedanken um die Infrastrukturbereitstellung, die Softwareinstallation, das Patchen oder die Kapazitätsskalierung machen. Darüber hinaus zahlen Sie nur für die tatsächliche Nutzungsdauer.
Mit der Azure-Integrationslaufzeit wird die native Computeressource zum sicheren, zuverlässigen und leistungsstarken Verschieben von Daten zwischen Clouddatenspeichern bereitgestellt. Sie können festlegen, wie viele Datenintegrationseinheiten für die Copy-Aktivität verwendet werden. Die Computegröße der Azure IR wird entsprechend elastisch zentral hochskaliert, ohne dass Sie die Größe der Azure Integration Runtime explizit anpassen müssen.
Die Aktivitätsverteilung ist ein einfacher Vorgang zum Weiterleiten der Aktivität an den Zielcomputedienst. Deshalb muss die Computegröße bei diesem Szenario nicht zentral hochskaliert werden.
Informationen zur Erstellung und Konfiguration einer Azure IR finden Sie unter Erstellen und Konfigurieren von Azure Integration Runtime.
Hinweis
Azure Integration Runtime verfügt über Eigenschaften, die mit der Datenflussruntime in Zusammenhang stehen, die die zugrunde liegende Computeinfrastruktur definiert, auf der die Datenflüsse ausgeführt würden.
Selbstgehostete Integrationslaufzeit
Eine selbstgehostete Integrationslaufzeit ermöglicht Folgendes:
- Ausführen einer Kopieraktivität zwischen einem Clouddatenspeicher und einem Datenspeicher im privaten Netzwerk.
- Bereitstellen der folgenden Transformationsaktivitäten für Computeressourcen im lokalen Netzwerk oder im virtuellen Azure-Netzwerk:
- Aktivität „Azure Function“
- Custom-Aktivität (wird in Azure Batch ausgeführt)
- U-SQL-Aktivität für Data Lake Analytics
- Aktivität „Metadaten abrufen“
- Hive-Aktivität mit HDInsight (BYOC, Bring Your Own Cluster)
- Pig-Aktivität mit HDInsight (BYOC)
- MapReduce-Aktivität mit HDInsight (BYOC)
- Spark-Aktivität mit HDInsight (BYOC)
- Streaming-Aktivität mit HDInsight (BYOC)
- Lookup-Aktivität
- Batch Execution-Aktivität für Machine Learning Studio (klassisch)
- Ressourcenaktualisierungsaktivität für Azure Machine Learning Studio (klassisch)
- Execute Pipeline-Aktivität (Machine Learning)
- Aktivität der gespeicherten Prozedur
- Aktivität „Prüfung“
- Webaktivität
Hinweis
Verwenden Sie die selbstgehostete Integration Runtime, um Datenspeicher zu unterstützen, die „Bring-your-own Driver“ erfordern, z. B. SAP Hana, MySQL usw. Weitere Informationen finden Sie unter Unterstützte Datenspeicher.
Hinweis
Die Java Runtime Environment (JRE) ist eine Abhängigkeit der selbstgehosteten IR. Stellen Sie sicher, dass die JRE auf dem gleichen Host installiert ist.
Selbstgehostete Integrationslaufzeit: Netzwerkumgebung
Wenn Sie die Datenintegration auf sichere Weise in einer privaten Netzwerkumgebung durchführen möchten, die nicht über eine direkte Sichtverbindung aus der öffentlichen Cloudumgebung verfügt, können Sie eine selbstgehostete IR in Ihrer lokalen Umgebung hinter einer Firewall oder in einem virtuellen privaten Netzwerk installieren. Die selbstgehostete Integration Runtime stellt nur ausgehende HTTP-basierte Verbindungen mit dem Internet her.
Selbstgehostete Integrationslaufzeit: Computeressource und Skalierung
Installieren Sie eine selbstgehostete IR auf einem lokalen Computer oder einem virtuellen Computer in einem privaten Netzwerk. Derzeit wird die selbstgehostete IR nur unter einem Windows-Betriebssystem unterstützt.
Zur Erzielung von Hochverfügbarkeit und Skalierbarkeit können Sie die selbstgehostete Integrationslaufzeit aufskalieren, indem Sie die logische Instanz mehreren lokalen Computern im Aktiv-Aktiv-Modus zuordnen. Weitere Informationen finden Sie im Artikel zum Erstellen und Konfigurieren einer selbstgehosteten IR.
Azure SSIS-Integrationslaufzeit
Für die Durchführung von Lift & Shift-Vorgängen für vorhandene SSIS-Workloads können Sie eine Azure-SSIS-Integrationslaufzeit erstellen, um SSIS-Pakete nativ auszuführen.
Azure-SSIS-Integrationslaufzeit: Netzwerkumgebung
Die Azure-SSIS Integration Runtime kann entweder im öffentlichen oder im privaten Netzwerk bereitgestellt werden. Der lokale Datenzugriff wird unterstützt, indem Azure-SSIS IR mit einem virtuellen Netzwerk verknüpft wird, für das eine Verbindung mit Ihrem lokalen Netzwerk besteht.
Azure-SSIS-Integrationslaufzeit: Computeressource und Skalierung
Die Azure-SSIS Integration Runtime ist ein vollständig verwalteter Cluster mit Azure-VMs, die speziell für die Ausführung von SSIS-Paketen bestimmt sind. Sie können Ihre eigene Azure SQL-Datenbank-Instanz oder verwaltete SQL-Instanz für den Katalog mit den SSIS-Projekten/-Paketen (SSISDB) bereitstellen. Sie können die Computeleistung hochskalieren, indem Sie die Knotengröße angeben und aufskalieren. Geben Sie hierzu die Anzahl von Knoten im Cluster an. Sie können die Kosten für die Ausführung Ihrer Azure-SSIS Integration Runtime verwalten, indem Sie sie je nach Bedarf anhalten und starten.
Weitere Informationen finden Sie unter Erstellen und Konfigurieren der Azure-SSIS IR. Nach der Erstellung können Sie Ihre vorhandenen SSIS-Pakete mit nur wenigen oder auch ganz ohne Änderungen bereitstellen und verwalten, indem Sie vertraute Tools wie SQL Server Data Tools (SSDT) und SQL Server Management Studio (SSMS) verwenden – genauso wie bei der lokalen Nutzung von SSIS.
Weitere Informationen zur Azure-SSIS Integration Runtime finden Sie in den folgenden Artikeln:
- Tutorial: Bereitstellen von SSIS-Paketen in Azure: Dieser Artikel enthält schrittweise Anweisungen zum Erstellen einer Azure-SSIS-Integrationslaufzeit und verwendet eine Azure SQL-Datenbank zum Hosten des SSIS-Katalogs.
- Vorgehensweise: Azure-SSIS Integration Runtime in Azure Data Factory: In diesem Artikel wird das Tutorial vertieft, und er enthält Anleitungen zum Verwenden einer verwalteten Azure SQL-Instanz und zum Einbinden der IR in ein virtuelles Netzwerk.
- Überwachen einer Azure-SSIS-Integrationslaufzeit: In diesem Artikel wird das Abrufen von Informationen zu einer Azure-SSIS Integration Runtime veranschaulicht, und er enthält Beschreibungen der Status in den zurückgegebenen Informationen.
- Verwalten einer Azure-SSIS-Integrationslaufzeit: In diesem Artikel wird beschrieben, wie Sie eine Azure-SSIS-Integrationslaufzeit beenden, starten oder entfernen. Es wird zudem gezeigt, wie Sie Ihre Azure-SSIS-Integrationslaufzeit aufskalieren, indem Sie der Integrationslaufzeit weitere Knoten hinzufügen.
- Verknüpfen einer Azure-SSIS-Integration Runtime mit einem virtuellen Netzwerk:. Dieser Artikel enthält grundlegende Informationen zum Verknüpfen einer Azure-SSIS-IR mit einem virtuellen Azure-Netzwerk. Außerdem wird beschrieben, wie Sie das Azure-Portal verwenden, um ein virtuelles Netzwerk zu konfigurieren und eine Azure-SSIS IR mit diesem zu verbinden.
Ort der Integrationslaufzeit
Beziehung zwischen Speicherort der Factory und IR-Speicherort
Wenn Sie eine Instanz von Data Factory oder eines Synapse-Arbeitsbereichs erstellen, müssen Sie den Speicherort angeben. Die Metadaten für die Instanz werden hier gespeichert, und das Auslösen der Pipeline wird von hier aus initiiert. Metadaten werden nur in der ausgewählten Region und nicht in anderen Regionen gespeichert.
Eine Pipeline kann währenddessen auf Datenspeicher und Compute Services in anderen Azure-Regionen zugreifen, um Daten zwischen Datenspeichern zu verschieben oder Daten mithilfe von Computediensten zu verarbeiten. Dieses Verhalten wird durch die global verfügbare Integrationslaufzeit realisiert, um für Datenkonformität, Effizienz und geringere Kosten für ausgehenden Netzwerkdatenverkehr zu sorgen.
Mit dem Integration Runtime-Standort wird der Standort der Back-End-Compute-Instanz und auch der Standort definiert, an dem die Datenverschiebung, Aktivitätsverteilung und SSIS-Paketausführung durchgeführt werden. Der Standort der Integration Runtime kann sich vom Standort der Data Factory unterscheiden, zu der er gehört.
Azure-Integrationslaufzeit: Standort
Sie können die Standortregion einer Azure IR festlegen. In diesem Fall erfolgt die Ausführung oder Verteilung der Aktivität in der ausgewählten Region.
Die Standardeinstellung ist das automatische Auflösen der Azure IR im öffentlichen Netzwerk. Merkmale dieser Option:
Bei der Copy-Aktivität wird versucht, den Standort Ihres Senkendatenspeichers automatisch zu erkennen, und dann die Integration Runtime entweder in derselben Region (falls verfügbar) oder in der nächstgelegenen Region im selben geografischen Gebiet zu verwenden. Wenn die Region des Senkendatenspeichers andernfalls nicht erkannt werden kann, wird stattdessen die Integration Runtime in der Region der Instanz verwendet.
Es wurde z. B. in der Region „USA, Osten“ ein Data Factory- oder Synapse-Arbeitsbereich erstellt.
- Wenn beim Kopieren von Daten in ein Azure-Blob in der Region „USA, Westen“ erkannt wird, dass sich das Blob in der Region „USA, Westen“ befindet, wird der Kopiervorgang auf der IR in der Region „USA, Westen“ ausgeführt. Tritt ein Fehler bei der Regionserkennung auf, wird der Kopiervorgang auf der IR in der Region „USA, Osten“ ausgeführt.
- Wenn beim Kopieren von Daten in Salesforce die Region nicht erkannt werden kann, wird die Copy-Aktivität in der Integration Runtime in „USA, Osten“ ausgeführt.
Tipp
Wenn Ihre Daten strengen Complianceanforderungen unterliegen und ein bestimmtes geografisches Gebiet nicht verlassen dürfen, können Sie explizit eine Azure Integration Runtime in einer bestimmten Region erstellen und den verknüpften Dienst mithilfe der ConnectVia-Eigenschaft auf diese Integration Runtime verweisen. Wenn Sie beispielsweise Daten aus einem Blob in der Region „Vereinigtes Königreich, Süden“ in einen Azure Synapse-Arbeitsbereich in der Region „Vereinigtes Königreich, Süden“ kopieren und dabei sicherstellen möchten, dass die Daten das Vereinigte Königreich nicht verlassen, erstellen Sie eine Azure IR in der Region „Vereinigtes Königreich, Süden“, und verknüpfen Sie beide verknüpften Dienste mit dieser IR.
Für Vorgänge zur Ausführung von Lookup-/GetMetadata-/Delete-Aktivitäten (Pipelineaktivitäten), zur Verteilung von Transformationsaktivitäten (externe Aktivitäten) und zur Erstellung (Verbindung testen, Ordner- und Tabellenliste durchsuchen und Daten als Vorschau anzeigen) wird die IR in derselben Region wie für den Data Factory- oder Synapse-Arbeitsbereich verwendet.
Für den Datenfluss wird die IR in der Region des Data Factory- oder Synapse-Arbeitsbereichs verwendet.
Tipp
Eine bewährte Methode besteht in der Sicherstellung, dass Datenflüsse nach Möglichkeit in derselben Region wie ihre entsprechenden Datenspeicher ausgeführt werden. Sie können dies entweder durch die automatische Auflösung für die Azure IR-Instanz (falls der Datenspeicherort mit dem Data Factory- oder Synapse-Arbeitsbereichstandort identisch ist) oder das Erstellen einer neuen Azure-IR-Instanz, die sich in der gleichen Region wie Ihre Datenspeicher befindet, und anschließendes Ausführen der Datenflüsse erreichen.
Wenn Sie ein verwaltetes virtuelles Netzwerk für die Azure IR mit automatischer Auflösung aktivieren, wird die IR in der Region des Data Factory- oder Synapse-Arbeitsbereichs verwendet.
Sie können überwachen, welcher IR-Standort während der Aktivitätsausführung in der Überwachungsansicht für die Pipelineaktivität in Data Factory Studio oder Synapse Studio oder in den Nutzdaten der Aktivitätsüberwachung wirksam wird.
Selbstgehostete Integrationslaufzeit: Standort
Die selbstgehostete Integration Runtime wird logisch unter dem Data Factory- oder Synapse-Arbeitsbereich registriert, und die Compute-Instanz, mit der die Funktionen unterstützt werden, wird von Ihnen bereitgestellt. Aus diesem Grund ist für die selbstgehostete Integrationslaufzeit keine explizite Standorteigenschaft vorhanden.
Bei Verwendung zum Durchführen der Datenverschiebung extrahiert die selbstgehostete Integrationslaufzeit Daten aus der Quelle und schreibt sie an das Ziel.
Azure-SSIS-Integrationslaufzeit: Standort
Hinweis
Azure-SSIS Integration Runtime-Instanzen werden in Synapse-Pipelines derzeit nicht unterstützt.
Die Auswahl des richtigen Standorts für Ihre Azure-SSIS-Integrationslaufzeit ist entscheidend, um für Ihre ETL-Workflows (Extrahieren-Transformieren-Laden) eine hohe Leistung zu erzielen.
- Der Standort der Azure-SSIS IR muss nicht dem Standort Ihrer Data Factory entsprechen. Es sollte aber derselbe Standort wie für Ihre eigene Azure SQL-Datenbank-Instanz bzw. verwaltete SQL-Instanz sein, in der sich SSISDB befindet. Ihre Azure-SSIS Integration Runtime kann dann leicht auf SSISDB zugreifen, ohne dass es zwischen unterschiedlichen Standorten zu übermäßig viel Datenverkehr kommt.
- Falls Sie nicht über eine SQL-Datenbank-Instanz oder eine verwaltete SQL-Instanz verfügen, aber über lokale Datenquellen bzw. -ziele, sollten Sie wie folgt vorgehen: Erstellen Sie eine neue Azure SQL-Datenbank-Instanz bzw. verwaltete SQL-Instanz am Standort eines virtuellen Netzwerks, das mit Ihrem lokalen Netzwerk verbunden ist. Auf diese Weise können Sie Ihre Azure-SSIS IR mithilfe der neuen Azure SQL-Datenbank oder SQL Managed Instance erstellen und diesem virtuellen Netzwerk beitreten. Alles befindet sich am gleichen Standort, was die Datenverschiebung und die damit verbundenen Kosten minimiert und gleichzeitig die Leistung maximiert.
- Wenn der Standort Ihrer vorhandenen Azure SQL-Datenbank-Instanz bzw. verwalteten SQL-Instanz nicht dem Standort eines virtuellen Netzwerks entspricht, das mit Ihrem lokalen Netzwerk verbunden ist, sollten Sie wie folgt vorgehen: Erstellen Sie zuerst die Azure-SSIS IR, indem Sie eine vorhandene Azure SQL-Datenbank-Instanz bzw. eine verwaltete SQL-Instanz verwenden und den Beitritt zu einem anderen virtuellen Netzwerk an demselben Ort durchführen. Konfigurieren Sie anschließend eine VNet-zu-VNet-Verbindung zwischen den verschiedenen Standorten.
Im folgenden Diagramm sind die Standorteinstellungen für Data Factory und die dazugehörigen Integration Runtimes dargestellt:
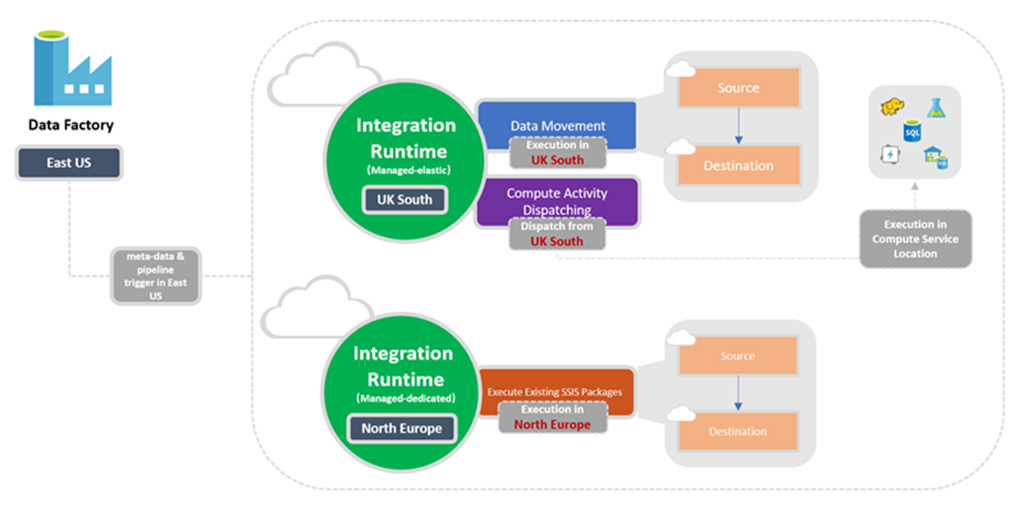
Ermitteln der richtigen Integrationslaufzeit
Wenn eine Aktivität mehreren Integration Runtime-Typen zugeordnet ist, wird sie in eine davon aufgelöst. Die selbstgehostete Integration Runtime hat Vorrang vor Azure Integration Runtime in Azure Data Factory- oder Synapse-Arbeitsbereichsinstanzen, die ein verwaltetes virtuelles Netzwerk verwenden. Und letzteres hat Vorrang vor der globalen Azure Integration Runtime.
Beispielsweise wird eine Kopieraktivität verwendet, um Daten aus der Quelle in die Senke zu kopieren. Die globale Azure Integration Runtime ist dem verknüpften Dienst mit der Quelle zugeordnet, und eine Azure Integration Runtime im von Azure Data Factory verwalteten virtuellen Netzwerk wird dem verknüpften Dienst für die Senke zugeordnet. Als Ergebnis verwenden die verknüpften Quellen- und Senkendienste die Azure Integration Runtime im von Azure Data Factory verwalteten virtuellen Netzwerk. Wenn jedoch eine selbstgehostete Integration Runtime den verknüpften Dienst für die Quelle zugeordnet, verwenden die verknüpften Quellen- und Senkendienste die selbstgehostete Integration Runtime.
Copy-Aktivität
Für die Copy-Aktivität sind hierbei sowohl verknüpfte Quellen- und Senkendienste zum Definieren der Datenflussrichtung erforderlich. Anhand der folgenden Logik wird ermittelt, welche Integrationslaufzeit-Instanz zum Durchführen des Kopiervorgangs verwendet wird:
- Kopieren zwischen zwei Clouddatenquellen: Wenn sowohl die mit der Quelle als auch die mit der Senke verknüpften Dienste die Azure IR verwenden, wird die regionale Azure IR verwendet, sofern sie angegeben wurde, oder der Speicherort der Azure IR wird automatisch bestimmt, wenn die IR-Option mit automatischer Auflösung (Standard) gewählt wurde, wie im Abschnitt Standort der Integration Runtime beschrieben.
- Kopieren zwischen einer Clouddatenquelle und einer Datenquelle in einem privaten Netzwerk: Wenn entweder der verknüpfte Quellen- oder Senkendienst auf eine selbstgehostete Integrationslaufzeit zeigt, wird die Copy-Aktivität unter dieser selbstgehosteten Integration Runtime ausgeführt.
- Kopieren zwischen zwei Datenquellen in einem privaten Netzwerk: Sowohl der verknüpfte Quelldienst als auch der verknüpfte Senkendienst muss auf die gleiche Integration Runtime verweisen, und diese IR wird zum Ausführen der Copy-Aktivität verwendet.
Lookup-/GetMetadata-Aktivität
Die Lookup-/GetMetadata-Aktivität wird für die Integrationslaufzeit ausgeführt, die dem verknüpften Datenspeicherdienst zugeordnet ist.
Externe Transformationsaktivität
Jede externe Transformationsaktivität, die eine externe Compute-Engine nutzt, verfügt über einen verknüpften Zielcomputedienst, der auf eine Integration Runtime verweist. Diese Integration Runtime-Instanz bestimmt den Standort, von dem die externe manuell codierte Transformationsaktivität gesendet wird.
Datenflussaktivität
Datenflussaktivitäten werden auf der ihnen zugeordneten Azure Integration Runtime ausgeführt. Der für Datenflüsse genutzte Spark-Computedienst wird durch die Datenflusseigenschaften in Ihrer Azure IR bestimmt und vollständig vom Dienst verwaltet.
Integration Runtime in CI/CD
Integration Runtimes werden nicht sehr häufig geändert und sind in allen Stufen von CI/CD ähnlich. Data Factory erfordert, dass Sie in allen Phasen von CI/CD denselben Namen und Typ der Integrationslaufzeit verwenden. Wenn Sie Integration Runtimes über alle Stufen hinweg freigeben möchten, können Sie eine dedizierte Factory verwenden, die nur die freigegebenen Integration Runtimes enthält. Diese freigegebene Factory können Sie dann in allen Umgebungen als verknüpften Integration Runtime-Typ verwenden.
Zugehöriger Inhalt
Weitere Informationen finden Sie in folgenden Artikeln:
- Erstellen einer Azure Integration Runtime-Instanz
- Create self-hosted integration runtime (Erstellen einer selbstgehosteten Integrationslaufzeit)
- Erstellen einer Azure-SSIS Integration Runtime in Azure Data Factory | Microsoft-Dokumentation. In diesem Artikel wird das Tutorial vertieft, und er enthält Anleitungen zum Verwenden einer verwalteten Azure SQL-Instanz und zum Einbinden der IR in ein virtuelles Netzwerk.