Anleitung zur Leistung und Optimierung der Mapping Data Flow-Funktion
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Zuordnungsdatenflüsse in Azure Data Factory- und Synapse-Pipelines bieten eine codefreie Benutzeroberfläche zum Entwerfen und Ausführen von Datentransformationen im großen Stil. Wenn Sie mit der Mapping Data Flow-Funktion nicht vertraut sind, finden Sie weitere Informationen in der Übersicht über Mapping Data Flow. In diesem Artikel werden verschiedene Möglichkeiten beschrieben, wie Sie Ihre Datenflüsse so anpassen und optimieren können, dass sie Ihre Leistungsbenchmarks erreichen.
Sehen Sie sich das folgende Video an, das einige Beispiele für die erforderliche Dauer beim Transformieren von Daten mit Datenflüssen enthält.
Überwachen der Datenflussleistung
Nachdem Sie Ihre Transformationslogik im Debugmodus überprüft haben, sollten Sie Ihren Datenfluss per End-to-End-Vorgang als Aktivität in einer Pipeline ausführen. Datenflüsse werden in einer Pipeline mit der Aktivität zum Ausführen eines Datenflusses operationalisiert. Die Datenflussaktivität verfügt im Gegensatz zu anderen Aktivitäten über eine einzigartige Überwachungsoberfläche, auf der ein ausführlicher Ausführungsplan und das Leistungsprofil der Transformationslogik angezeigt werden. Klicken Sie in der Ausgabe der Aktivitätsausführung einer Pipeline auf das Brillensymbol, um für den Datenfluss ausführliche Überwachungsinformationen anzuzeigen. Weitere Informationen finden Sie unter Überwachen von Datenflüssen.

Beim Überwachen der Leistung von Datenflüssen gibt es vier mögliche Engpässe, auf die Sie achten sollten:
- Startzeit des Clusters
- Lesen von einer Quelle
- Transformationszeit
- Schreiben in eine Senke
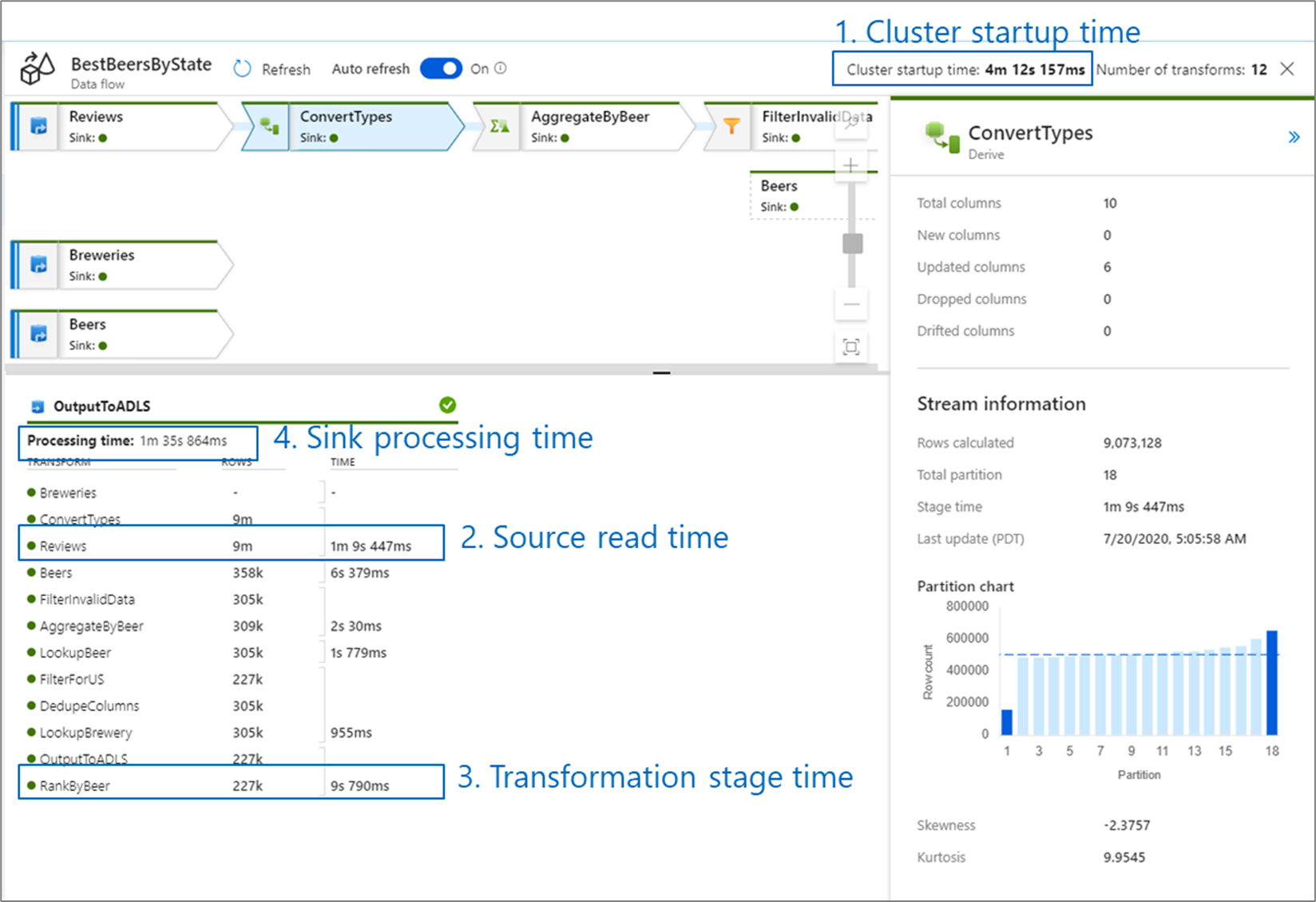
Die Startzeit des Clusters ist die benötigte Dauer für den Start eines Apache Spark-Clusters. Dieser Wert befindet sich oben rechts auf dem Überwachungsbildschirm. Datenflüsse basieren auf einem Just-In-Time-Modell, bei dem für jeden Auftrag ein isolierter Cluster verwendet wird. Diese Startzeit hat normalerweise eine Dauer von drei bis fünf Minuten. Für sequenzielle Aufträge kann diese reduziert werden, indem ein Wert für die Gültigkeitsdauer aktiviert wird. Weitere Informationen finden Sie unter Gültigkeitsdauer (TTL) und Integration Runtime-Leistung.
Für Datenflüsse wird ein Spark-Optimierer genutzt, mit dem Ihre Geschäftslogik in „Stufen“ neu sortiert und ausgeführt wird, damit die Dauer möglichst kurz ist. Für jede Senke, in die Ihr Datenfluss geschrieben wird, sind in der Ausgabe der Überwachung die Dauer der einzelnen Transformationsstufen sowie die Zeiten enthalten, die zum Schreiben der Daten in die Senke benötigt werden. Anhand der längsten Dauer können Sie wahrscheinlich den Engpass für Ihren Datenfluss ermitteln. Falls die Transformationsstufe mit der längsten Dauer eine Quelle enthält, sollten Sie überlegen, ob Sie Ihre Lesedauer weiter optimieren können. Wenn eine Transformation lange dauert, müssen Sie ggf. neu partitionieren oder die Größe für Ihre Integration Runtime erhöhen. Bei einer langen Dauer der Senkenverarbeitung müssen Sie unter Umständen Ihre Datenbank hochskalieren oder sich vergewissern, dass die Ausgabe nicht nur in eine einzelne Datei erfolgt.
Nachdem Sie den Engpass für Ihren Datenfluss identifiziert haben, sollten Sie die unten angegebenen Strategien nutzen, um die Leistung zu verbessern.
Testen der Datenflusslogik
Wenn Sie Datenflüsse über die Benutzeroberfläche entwerfen und testen, können Sie im Debugmodus interaktiv einen Test mit einem Spark-Cluster durchführen, mit dem Sie Datenflüsse in der Vorschau anzeigen und ausführen können, ohne auf das Aufwärmen eines Clusters zu warten. Weitere Informationen finden Sie unter Debugmodus.
Registerkarte „Optimieren“
Die Registerkarte Optimieren enthält Einstellungen zum Konfigurieren des Partitionsschemas für den Spark-Cluster. Diese Registerkarte ist für jede Transformation des Datenflusses vorhanden und gibt an, ob Sie die Daten neu partitionieren sollten, nachdem die Transformation abgeschlossen ist. Das Anpassen der Partitionierung bietet Kontrolle über die Verteilung Ihrer Daten auf Computeknoten und Datenstandortoptimierungen, die sowohl positive als auch negative Auswirkungen auf die gesamte Datenflussleistung haben können.

Standardmäßig ist die Option Aktuelle Partitionierung verwenden ausgewählt, die den Dienst anweist, die aktuelle Ausgabepartitionierung der Transformation beizubehalten. Da die erneute Partitionierung einige Zeit in Anspruch nimmt, ist die Verwendung der Option Aktuelle Partitionierung verwenden in den meisten Szenarien zu empfehlen. Szenarien, in denen Sie Ihre Daten ggf. neu partitionieren sollten, sind beispielsweise Aggregations- und Joinvorgänge, bei denen es für Ihre Daten zu einer erheblichen Datenschiefe kommt, oder bei Verwendung einer Quellpartitionierung auf einer SQL-Datenbank-Instanz.
Wenn Sie die Partitionierung für eine Transformation ändern möchten, wählen Sie die Registerkarte Optimieren und das Optionsfeld Partitionierung festlegen aus. Ihnen werden mehrere Optionen für die Partitionierung angezeigt. Die beste Methode der Partitionierung richtet sich jeweils nach den Datenmengen, Kandidatenschlüsseln, NULL-Werten und der Kardinalität.
Wichtig
Bei nur einer Partition werden darin alle verteilten Daten kombiniert. Hierbei handelt es sich um einen sehr langsamen Vorgang, bei dem auch alle nachgeschalteten Transformationen und Schreibvorgänge erheblich beeinträchtigt werden. Von dieser Option wird dringend abgeraten, es sei denn, es gibt einen expliziten geschäftlichen Grund, sie zu verwenden.
Die folgenden Partitionierungsoptionen sind in jeder Transformation verfügbar:
Roundrobin
Per Roundrobin werden Daten gleichmäßig auf die Partitionen verteilt. Verwenden Sie die Option „Roundrobin“, wenn Sie nicht über gute Kandidaten verfügen, um eine solide, intelligente Partitionierungsstrategie zu implementieren. Sie können die Anzahl der physischen Partitionen festlegen.
Hash
Der Dienst erzeugt einen Hash von Spalten, um einheitliche Partitionen zu erstellen, damit Zeilen mit ähnlichen Werten in die gleiche Partition eingefügt werden. Führen Sie bei Verwendung der Option „Hash“ einen Test auf mögliche Partitionsungleichmäßigkeiten durch. Sie können die Anzahl der physischen Partitionen festlegen.
Dynamischer Bereich
Bei dieser Option werden die dynamischen Spark-Bereiche basierend auf den von Ihnen angegebenen Spalten oder Ausdrücken verwendet. Sie können die Anzahl der physischen Partitionen festlegen.
Fester Bereich
Erstellen Sie einen Ausdruck, der einen festen Bereich für Werte in Ihren partitionierten Datenspalten bereitstellt. Sie sollten über fundiertes Wissen über Ihre Daten verfügen, bevor Sie diese Option verwenden, um Partitionsungleichmäßigkeiten zu vermeiden. Die von Ihnen für den Ausdruck eingegebenen Werte werden als Teil einer Partitionsfunktion verwendet. Sie können die Anzahl der physischen Partitionen festlegen.
Schlüssel
Wenn Sie gut mit der Kardinalität Ihrer Daten vertraut sind, kann die Schlüsselpartitionierung eine gute Strategie darstellen. Die Schlüsselpartitionierung erstellt Partitionen für jeden eindeutigen Wert in der Spalte. Sie können die Anzahl der Partitionen nicht festlegen, weil die Anzahl auf den eindeutigen Werten in den Daten basiert.
Tipp
Beim manuellen Festlegen des Partitionierungsschemas werden die Daten neu angeordnet, sodass die Vorteile des Spark-Optimierers ggf. nicht voll zur Geltung kommen. Eine bewährte Methode besteht darin, die Partitionierung nicht manuell festzulegen, sofern dies nicht unbedingt erforderlich ist.
Protokolliergrad
Wenn es nicht erforderlich ist, dass jede Pipelineausführung Ihrer Datenflussaktivitäten alle ausführlichen Telemetrieprotokolle vollständig protokolliert, können Sie den Protokolliergrad optional auf „Standard“ oder „Kein“ festlegen. Wenn Sie Ihre Datenflüsse im Modus „Ausführlich“ (Standard) ausführen, fordern Sie vom Dienst, dass die Aktivität während der Datentransformation auf den einzelnen Partitionsebenen vollständig protokolliert wird. Da dies ein kostspieliger Vorgang sein kann, kann nur die ausschließliche Aktivierung von „Ausführlich“ bei der Problembehandlung den gesamten Datenfluss und die Pipelineleistung verbessern. Der Modus „Standard“ protokolliert nur die Transformationszeitspannen, während „Kein“ nur eine Zusammenfassung der Zeitspannen bietet.

Zugehöriger Inhalt
- Optimieren von Quellen
- Optimieren von Senken
- Optimieren von Transformationen
- Verwenden von Datenflüssen in Pipelines
Lesen Sie die folgenden Artikel zu Datenflüssen in Bezug auf die Leistung: