Überwachen der Azure Data Explorer-Leistung, -Integrität und -Auslastung mit Metriken
Azure Data Explorer-Metriken liefern wichtige Hinweise in Bezug auf die Integrität und Leistung der Azure Data Explorer-Clusterressourcen. Verwenden Sie die in diesem Artikel beschriebenen Metriken, um die Nutzung, Integrität und Leistung von Azure Data Explorer-Clustern in Ihrem jeweiligen Szenario als eigenständige Metriken zu überwachen. Sie können Metriken auch als Basis für den Betrieb von Azure-Dashboards und Azure-Warnungen verwenden.
Weitere Informationen zum Azure-Metrik-Explorer finden Sie unter Erste Schritte mit dem Azure-Metrik-Explorer.
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
- Schnellstart: Erstellen eines Azure Data Explorer-Clusters und einer Datenbank. Erstellen eines Clusters und einer Datenbank
Überwachen Ihrer Azure Data Explorer-Ressourcen mithilfe von Metriken
- Melden Sie sich beim Azure-Portal an.
- Suchen Sie im linken Bereich Ihres Azure Data Explorer-Clusters nach Metriken.
- Wählen Sie Metriken aus, um den Bereich „Metriken“ zu öffnen und mit der Analyse Ihres Clusters zu beginnen.
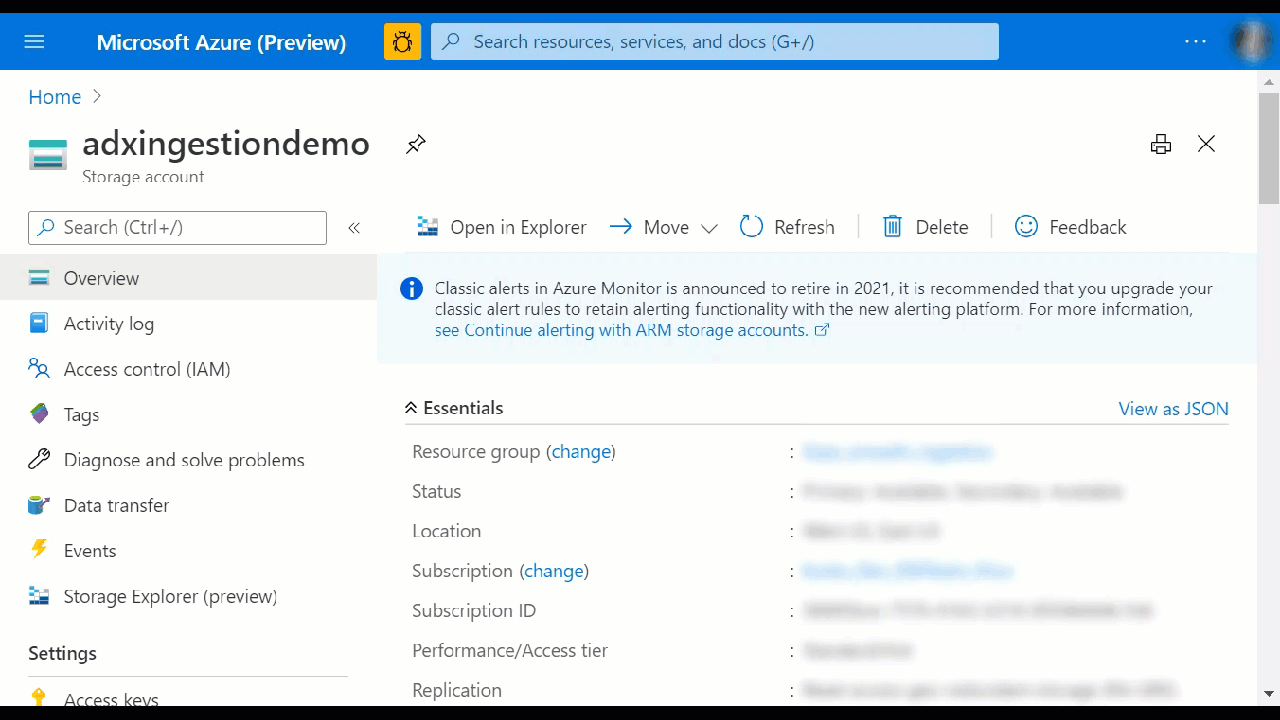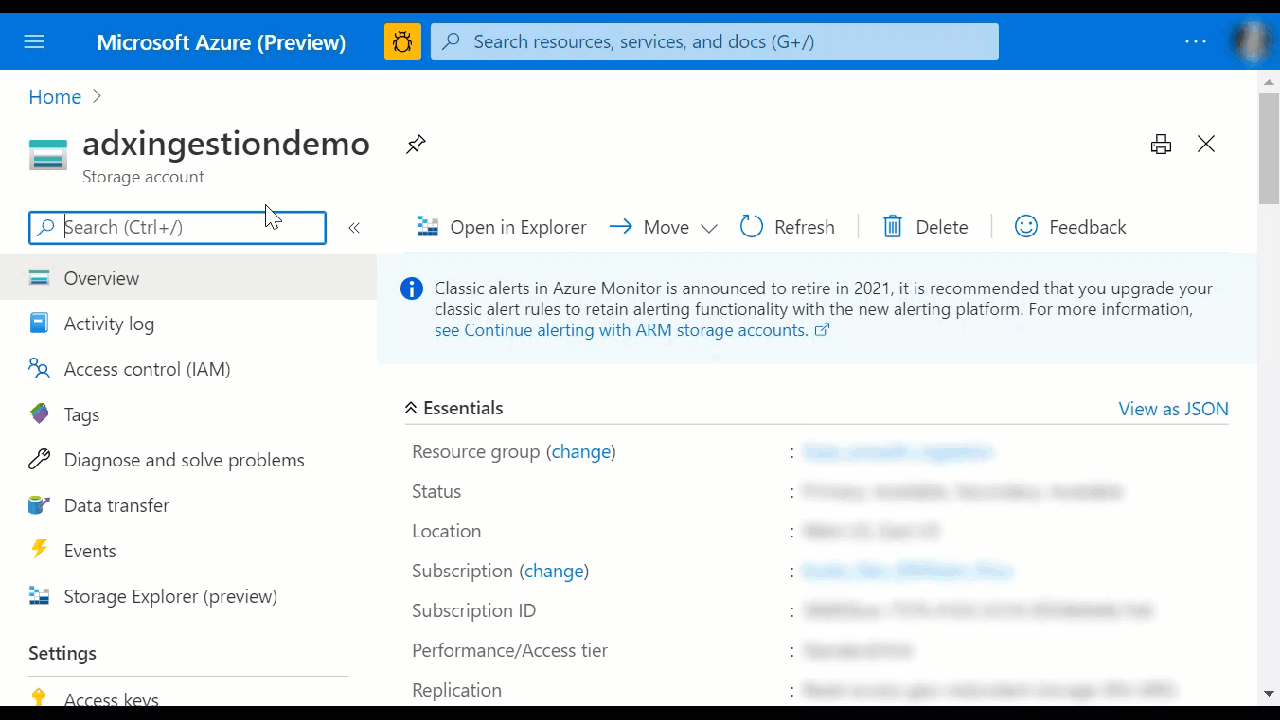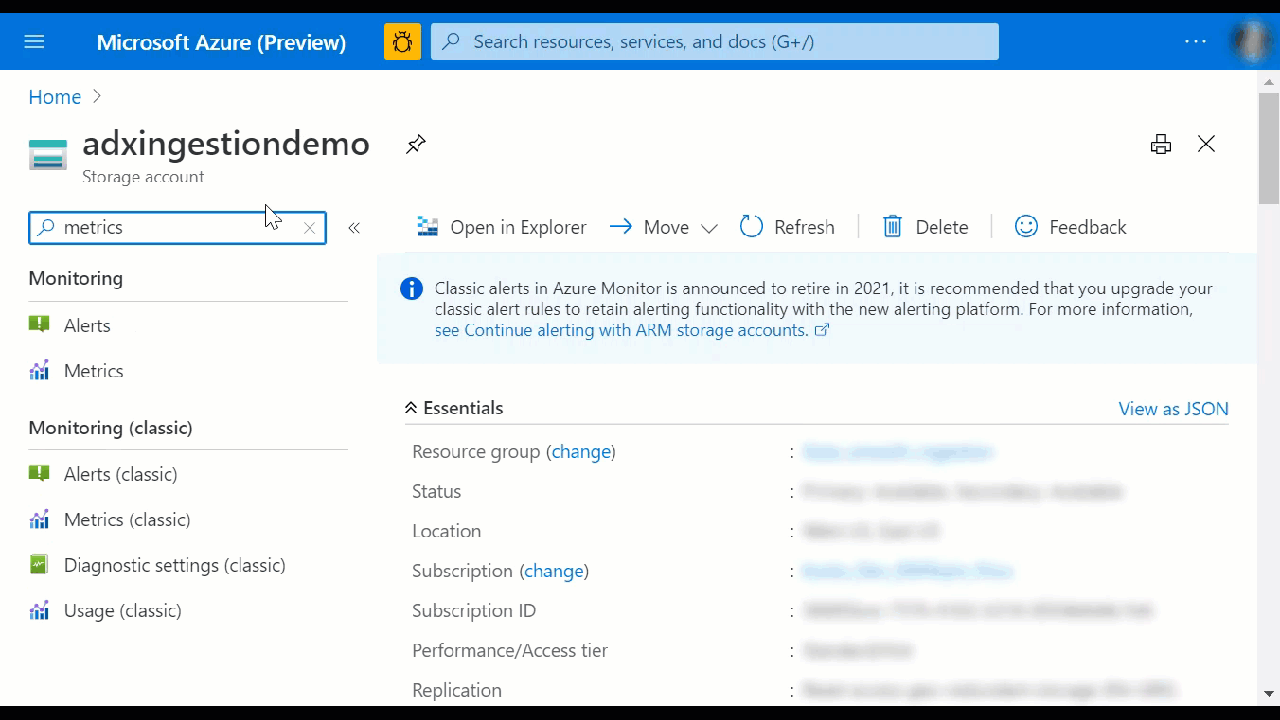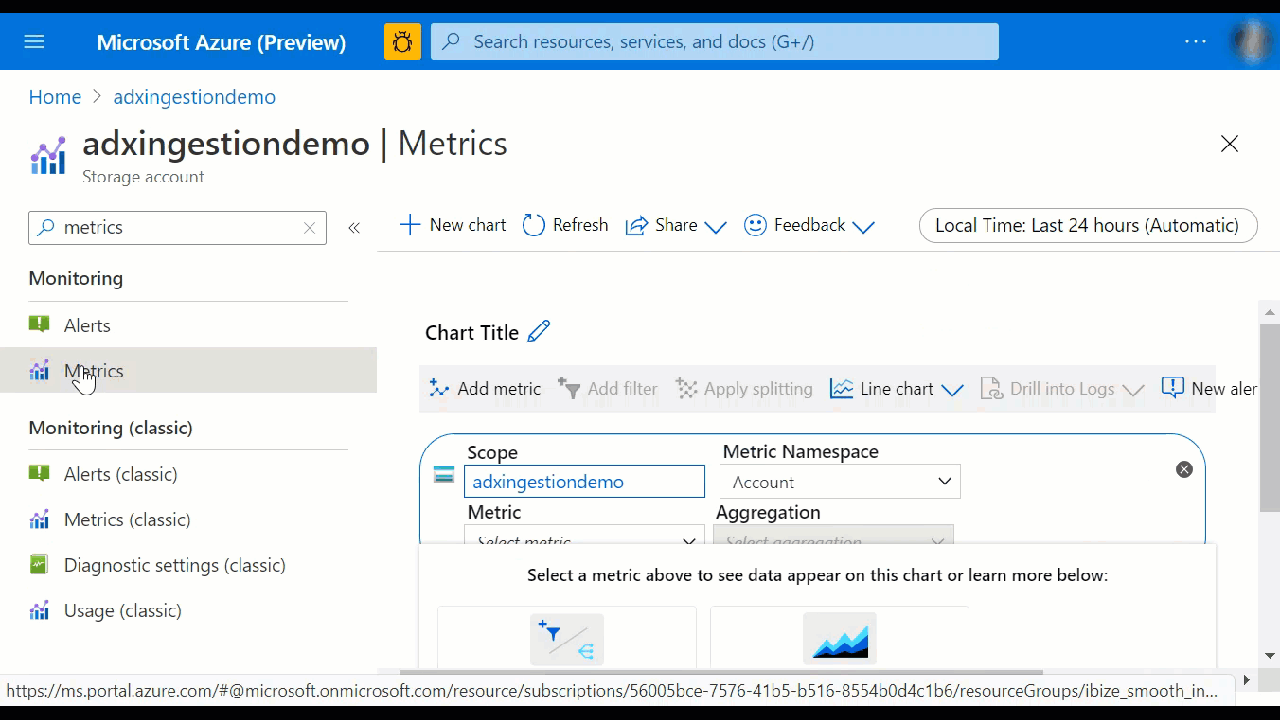
Verwenden des Bereichs „Metriken“
Wählen Sie im Bereich „Metriken“ bestimmte Metriken für die Nachverfolgung sowie die gewünschte Aggregierung Ihrer Daten aus, und erstellen Sie Metrikdiagramme für die Anzeige auf Ihrem Dashboard.
In der Auswahl für die Ressource und den Metriknamespace ist Ihr Azure Data Explorer-Cluster bereits ausgewählt. Die Zahlen in der folgenden Abbildung entsprechen der nummerierten Liste weiter unten. Sie führen durch die verschiedenen Optionen im Zusammenhang mit der Einrichtung und Anzeige Ihrer Metriken.
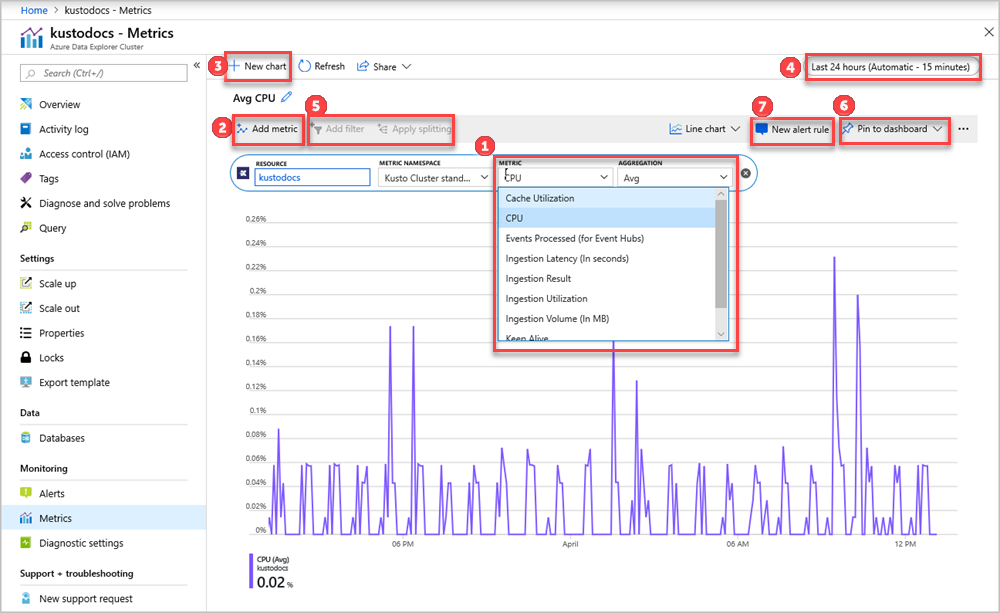
- Wählen Sie zum Erstellen eines Metrikdiagramms den Namen der Metrik und die relevante Aggregation pro Metrik aus. Weitere Informationen zu verschiedenen Metriken finden Sie unter unterstützte Azure Data Explorer-Metriken.
- Wählen Sie Metrik hinzufügen aus, um mehrere Metriken im gleichen Diagramm anzuzeigen.
- Wählen Sie + Neues Diagramm aus, um mehrere Diagramme in einer einzelnen Ansicht anzuzeigen.
- Verwenden Sie die Zeitauswahl, um den Zeitbereich zu ändern (Standardeinstellung: Letzte 24 Stunden).
- Verwenden Sie Filter hinzufügen und Teilung anwenden für Metriken, die über Dimensionen verfügen.
- Wählen Sie die Option An Dashboard anheften, um Ihre Diagrammkonfiguration den Dashboards hinzuzufügen, damit Sie die Anzeige erneut verwenden können.
- Legen Sie die Option Neue Warnungsregel fest, um Ihre Metriken mit den festgelegten Kriterien zu visualisieren. Die neue Warnungsregel enthält Ihre Dimensionen für Zielressource, Metrik, Teilung und Filter aus dem Diagramm. Ändern Sie diese Einstellungen im Bereich für die Erstellung von Warnungsregeln.
Unterstützte Azure Data Explorer-Metriken
Die Azure Data Explorer-Metriken geben Aufschluss über die Gesamtleistung und die Verwendung Ihrer Ressourcen und liefern Informationen zu bestimmten Aktionen wie Erfassung oder Abfrage. Die Metriken in diesem Artikel wurden nach Verwendungstyp gruppiert.
Die Metriktypen umfassen Folgendes:
- Clustermetriken
- Exportieren von Metriken
- Erfassungsmetriken
- Metriken der Streamingerfassung
- Abfragemetriken
- Metriken der materialisierten Sicht
Eine alphabetische Liste der Azure Monitor-Metriken für Azure Data Explorer finden Sie in den unterstützten Metriken für Azure Data Explorer-Cluster.
Clustermetriken
Die Clustermetriken dienen zum Nachverfolgen der allgemeinen Integrität des Clusters. Hierzu zählen beispielsweise die Ressourcen- und Erfassungsverwendung sowie die Reaktionsfähigkeit.
| Metrik | Einheit | Aggregation | Beschreibung der Metrik | Dimensionen |
|---|---|---|---|---|
| Cacheauslastung (veraltet) | Percent | Avg, Max, Min | Der Prozentsatz der zugeordneten Cacheressourcen, die derzeit vom Cluster verwendet werden. Cache ist die Größe der SSD, die für die Benutzeraktivität gemäß der definierten Cacherichtlinie zugeordnet wird. Eine durchschnittliche Cacheauslastung von 80 % oder weniger ist für einen Cluster ein tragbarer Zustand. Wenn die durchschnittliche Cacheauslastung 80 Prozent übersteigt, sollte der Cluster auf einen datenspeicheroptimierten Tarif hochskaliert oder auf mehr Instanzen aufskaliert werden. Alternativ hierzu können Sie die Cacherichtlinie anpassen (weniger Tage im Cache). Falls die Cacheauslastung über 100 % liegt, übersteigt die Größe der zwischenzuspeichernden Daten die Gesamtgröße des Caches im Cluster. Diese Metrik ist veraltet und wird nur zum Zweck der Abwärtskompatibilität bereitgestellt. Verwenden Sie stattdessen die Metrik „Cacheauslastungsfaktor“. |
Keine |
| Cacheauslastungsfaktor | Percent | Avg, Max, Min | Der Prozentsatz des verwendeten Speicherplatzes, der für den hot cache im Cluster reserviert ist. 100 % bedeutet, dass der für heiße Daten zugewiesene Speicherplatz optimal ausgelastet ist. Es ist keine Aktion erforderlich, und der Cluster ist in Ordnung. Weniger als 100 % bedeutet, dass der für heiße Daten zugewiesene Speicherplatz nicht vollständig ausgelastet ist. Mehr als 100 % bedeutet, dass der Speicherplatz des Clusters nicht groß genug für die heißen Daten ist, wie durch Ihre Zwischenspeicherungsrichtlinien definiert. Um sicherzustellen, dass ausreichend Speicherplatz für alle heißen Daten verfügbar ist, muss die Menge der heißen Daten reduziert werden, oder der Cluster muss aufskaliert werden. Es wird empfohlen, die automatische Skalierung zu aktivieren. |
Keine |
| CPU | Percent | Avg, Max, Min | Der Prozentsatz der zugeordneten Computeressourcen, die derzeit von Computern im Cluster verwendet werden. Eine durchschnittliche CPU-Auslastung von 80 % ist für einen Cluster ein tragbarer Zustand. Der Maximalwert der CPU beträgt 100 %. Dies bedeutet, dass es keine weiteren Computeressourcen zum Verarbeiten von Daten gibt. Wenn die Leistung eines Clusters nicht gut ist, sollten Sie den Maximalwert der CPU überprüfen, um zu ermitteln, ob bestimmte CPUs blockiert sind. |
Keine |
| Datenerfassungsauslastung | Percent | Avg, Max, Min | Der Prozentsatz der tatsächlichen Ressourcen, die zum Aufnehmen von Daten aus den zugeordneten Gesamtressourcen in der Kapazitätsrichtlinie verwendet werden, um die Aufnahme durchzuführen. Die Standardrichtlinie für die Kapazität umfasst nicht mehr als 512 gleichzeitige Erfassungsvorgänge oder 75 % der Clusterressourcen, die für die Erfassung genutzt werden. Eine durchschnittliche Erfassungsauslastung von 80 % oder weniger ist für einen Cluster ein tragbarer Zustand. Der Maximalwert der Erfassungsauslastung beträgt 100 %. Dies bedeutet, dass die gesamte Erfassungskapazität des Clusters genutzt wird und unter Umständen eine Erfassungswarteschlange entsteht. |
Keine |
| InstanceCount | Anzahl | Avg | Die Gesamtzahl der Instanzen. | |
| Keep-Alive | Anzahl | Avg | Dient zum Nachverfolgen der Reaktionsfähigkeit des Clusters. Für einen Cluster mit höchster Reaktionsfähigkeit wird der Wert 1 zurückgegeben, und für einen blockierten oder getrennten Cluster lautet der Wert 0. |
|
| Gesamtanzahl gedrosselter Befehle | Anzahl | Avg, Max, Min, Sum | Die Anzahl der gedrosselten (abgelehnten) Befehle im Cluster, da die maximal zulässige Anzahl gleichzeitiger (paralleler) Befehle erreicht wurde. | Keine |
| Gesamtanzahl von Erweiterungen | Anzahl | Avg, Max, Min, Sum | Die Gesamtanzahl der Datenausdehnungen im Cluster. Änderungen an dieser Metrik können massive Datenstrukturänderungen und eine hohe Auslastung des Clusters mit sich bringen, da das Zusammenführen von Datenerweiterungen eine CPU-intensive Aktivität ist. |
Keine |
| Follower-Latenz | Millisekunden | Avg, Max, Min | Die Follower-Datenbanken synchronisieren Änderungen in den Leader-Datenbanken. Aufgrund der Synchronisierung gibt es bei der Datenverfügbarkeit eine Zeitverzögerung von einigen Sekunden bis zu einigen Minuten. Diese Metrik misst die Zeitverzögerung. Die Zeitverzögerung hängt von mehreren Faktoren ab: Gesamtgröße und Rate der erfassten Daten in der Leader-Datenbank, Anzahl der Datenbanken, denen gefolgt wird, Rate der internen Vorgänge, die in der Leader-Datenbank ausgeführt werden (Zusammenführen/Neuerstellen). Dies ist eine Metrik auf Clusterebene: Die Follower erfassen Metadaten aller Datenbanken, denen gefolgt wird. Diese Metrik stellt die Latenz des Prozesses dar. |
Keine |
Exportieren von Metriken
Exportmetriken dienen zum Nachverfolgen der allgemeinen Integrität und Leistung von Exportvorgängen anhand von Aspekten wie Verzögerung, Ergebnissen, Anzahl von Datensätzen und Auslastung.
| Metrik | Einheit | Aggregation | Beschreibung der Metrik | Dimensionen |
|---|---|---|---|---|
| Fortlaufender Export – Anzahl der exportierten Datensätze | Anzahl | Summe | Die Anzahl exportierter Datensätze in allen Aufträgen mit fortlaufendem Export. | ContinuousExportName |
| Fortlaufender Export – maximale Verzögerung | Anzahl | Max | Die Verzögerung (in Minuten), die von Aufträgen mit fortlaufendem Export im Cluster gemeldet wurde. | Keine |
| Fortlaufender Export – ausstehende Anzahl | Anzahl | Max | Die Anzahl ausstehender Aufträge mit fortlaufendem Export. Diese Aufträge sind ausführungsbereit, befinden sich aber in einer Warteschlange (möglicherweise aufgrund von unzureichender Kapazität). | |
| Fortlaufender Export – Ergebnis | Anzahl | Anzahl | Das Ergebnis (Fehler/Erfolg) der einzelnen Ausführungen des fortlaufenden Exports. | ContinuousExportName |
| Exportauslastung | Percent | Max | Die verwendete Exportkapazität, aus der gesamten Exportkapazität im Cluster (zwischen 0 und 100). | Keine |
Erfassungsmetriken
Erfassungsmetriken dienen zum Nachverfolgen der allgemeinen Integrität und Leistung von Erfassungsvorgängen anhand von Aspekten wie Wartezeit, Ergebnissen und Volumen. Verfeinern Sie Ihre Analyse wie folgt:
- Wenden Sie Filter auf Diagramme an, um partielle Daten nach Dimensionen darzustellen. Untersuchen Sie beispielsweise die Erfassung in einem bestimmten
Database-Element. - Wenden Sie die Teilung auf ein Diagramm an, um Daten nach verschiedenen Komponenten zu visualisieren. Dieser Vorgang ist nützlich für die Analyse von Metriken, die in den einzelnen Schritten der Erfassungspipeline gemeldet werden, z. B.
Blobs received.
| Metrik | Einheit | Aggregation | Beschreibung der Metrik | Dimensionen |
|---|---|---|---|---|
| Batchblob – Anzahl | Anzahl | Avg, Max, Min | Die Anzahl der Datenquellen in einem abgeschlossenen Batch für die Aufnahme. | Datenbank |
| Batchdauer | Sekunden | Avg, Max, Min | Dauer der Batchverarbeitungsphase im Erfassungsflow | Datenbank |
| Batchgröße | Byte | Avg, Max, Min | Die nicht komprimierte erwartete Datengröße in einem aggregierten Batch für die Aufnahme. | Datenbank |
| Verarbeitete Batches | Anzahl | Sum, Max, Min | Die Anzahl der für die Aufnahme abgeschlossenen Batches. Batching Type: Der Trigger zum Versiegeln eines Batchs. Eine vollständige Liste der Batchverarbeitungstypen finden Sie hier. |
Datenbank, Batchverarbeitungstyp |
| Empfangene Blobs | Anzahl | Sum, Max, Min | Die Anzahl der Blobs, die von einem Eingabedatenstrom von einer Komponente empfangen wurden. Verwenden Sie Teilung anwenden, um die einzelnen Komponenten zu analysieren. |
Datenbank, Komponententyp, Komponentenname |
| Verarbeitete Blobs | Anzahl | Sum, Max, Min | Die Anzahl der von einer Komponente verarbeiteten Blobs Verwenden Sie Teilung anwenden, um die einzelnen Komponenten zu analysieren. |
Datenbank, Komponententyp, Komponentenname |
| Gelöschte Blobs | Anzahl | Sum, Max, Min | Die Anzahl der Blobs, die dauerhaft von einer Komponente verworfen wurden. Für jeden dieser Blobs wird eine Metrik vom Typ Ingestion result mit der Fehlerursache gesendet. Verwenden Sie Teilung anwenden, um die einzelnen Komponenten zu analysieren. |
Datenbank, Komponententyp, Komponentenname |
| Wartezeit bei der Ermittlung | Sekunden | Avg | Die Zeit zwischen dem Einreihen von Daten in die Warteschlange und der Erkennung durch die Datenverbindungen. Diese Zeit ist nicht in der Metrik Phasenlatenz oder Erfassungslatenz enthalten. Die Ermittlungslatenz kann in den folgenden Situationen steigen:
|
Komponententyp, Komponentenname |
| Empfangene Ereignisse | Anzahl | Sum, Max, Min | Die Anzahl der Ereignisse, die von Datenverbindungen aus dem Eingabedatenstrom empfangen werden. | Komponententyp, Komponentenname |
| Verarbeitete Ereignisse | Anzahl | Sum, Max, Min | Die Anzahl der von den Datenverbindungen verarbeiteten Ereignisse | Komponententyp, Komponentenname |
| Gelöschte Ereignisse | Anzahl | Sum, Max, Min | Die Anzahl der Ereignisse, die dauerhaft durch Datenverbindungen verworfen wurden. Für jedes dieser Ereignisse wird eine Metrik vom Typ Ingestion result mit der Fehlerursache gesendet. |
Komponententyp, Komponentenname |
| Latenz bei der Erfassung | Sekunden | Avg, Max, Min | Die Latenz der aufgenommenen Daten ab dem Zeitpunkt, zu dem die Daten im Cluster empfangen wurden, bis sie für die Abfrage bereit ist. Der Zeitraum der Erfassungslatenz richtet sich nach dem Erfassungsszenario.Ingestion Kind: Streamingerfassung oder Erfassung in Warteschlange |
Erfassungsart |
| Ergebnis der Datenerfassung | Anzahl | Summe | Die Gesamtzahl der Quellen, die fehlgeschlagen sind oder erfolgreich aufgenommen werden konnten.Status: Success bei einer erfolgreichen Erfassung, oder die Fehlerkategorie bei Fehlern. Eine vollständige Liste mit den möglichen Fehlerkategorien finden Sie unter Erfassungsfehlercodes in Azure Data Explorer. Failure Status Type: Gibt an, ob der Fehler dauerhafter oder vorübergehender Art ist. Bei einer erfolgreichen Erfassung wird None für diese Dimension angegeben.Hinweis:
|
Status, Fehlerstatustyp |
| Datenerfassungsvolumen (in Bytes) | Anzahl | Max, Sum | Die Gesamtgröße der im Cluster erfassten Daten (in Bytes) vor der Komprimierung. | Datenbank |
| Länge der Warteschlange | Anzahl | Avg | Die Anzahl ausstehender Nachrichten in der Eingabewarteschlange einer Komponente. Die Batchverarbeitungs-Manager-Komponente enthält eine Nachricht pro Blob. Die Erfassungs-Manager-Komponente enthält eine Nachricht pro Blob. Ein Batch ist ein einzelner Erfassungsbefehl mit einem oder mehreren Blobs. | Komponententyp |
| Älteste Nachricht in Warteschlange | Sekunden | Avg | Die Zeit in Sekunden ab dem Zeitpunkt, zu dem die älteste Nachricht in der Eingabewarteschlange einer Komponente eingefügt wurde. | Komponententyp |
| Größe der empfangenen Daten in Bytes | Byte | Avg, Sum | Die Größe der Daten, die von Datenverbindungen aus dem Eingabedatenstrom empfangen werden. | Komponententyp, Komponentenname |
| Phasenlatenz | Sekunden | Avg | Die Zeit, ab der eine Nachricht vom Azure-Daten-Explorer akzeptiert wird, bis der Inhalt von einer Aufnahmekomponente zur Verarbeitung empfangen wird. Verwenden Sie die Option Filter anwenden, und wählen Sie Komponententyp >StorageEngine aus, um die gesamte Erfassungslatenz anzuzeigen. |
Datenbank, Komponententyp |
Streamingerfassungsmetriken
Streamingerfassungsmetriken verfolgen Streamingerfassungsdaten sowie Anforderungsrate, Dauer und Ergebnisse nach.
| Metrik | Einheit | Aggregation | Beschreibung der Metrik | Dimensionen |
|---|---|---|---|---|
| Datenrate der Streamingerfassung | Anzahl | RateRequestsPerSecond | Das Gesamtvolumen der daten, die an den Cluster aufgenommen wurden. | Keine |
| Dauer der Streamingerfassung | Millisekunden | Avg, Max, Min | Die Gesamtdauer aller Streamingerfassungsanforderungen | Keine |
| Anforderungsrate der Streamingerfassung | Anzahl | Count, Avg, Max, Min, Sum | Die Gesamtanzahl der Streaming-Aufnahmeanforderungen. | Keine |
| Ergebnis der Streamingerfassung | Anzahl | Avg | Die Gesamtanzahl der Streaming-Aufnahmeanforderungen nach Ergebnistyp. | Ergebnis |
Abfragemetriken
Abfrageleistungsmetriken verfolgen die Abfragedauer und Gesamtanzahl gleichzeitiger oder gedrosselter Abfragen nach.
| Metrik | Einheit | Aggregation | Beschreibung der Metrik | Dimensionen |
|---|---|---|---|---|
| Abfragedauer | Millisekunden | Avg, Min, Max, Sum | Die Gesamtzeit, bis Abfrageergebnisse empfangen werden (schließt keine Netzwerklatenz ein). | QueryStatus |
| QueryResult | Anzahl | Anzahl | Die Gesamtzahl der Abfragen. | QueryStatus |
| Gesamtanzahl gleichzeitiger Abfragen | Anzahl | Avg, Max, Min, Sum | Die Anzahl der Abfragen, die im Cluster parallel ausgeführt werden. Diese Metrik ist eine gute Möglichkeit, um die Auslastung des Clusters einzuschätzen. | Keine |
| Gesamtanzahl gedrosselter Abfragen | Anzahl | Avg, Max, Min, Sum | Die Anzahl der gedrosselten (abgelehnten) Abfragen im Cluster. Die maximal zulässige Anzahl gleichzeitiger (paralleler) Abfragen wird in der Richtlinie für die Anforderungsratenbegrenzung definiert. | Keine |
Metriken der materialisierten Sicht
| Metrik | Einheit | Aggregation | Beschreibung der Metrik | Dimensionen |
|---|---|---|---|---|
| MaterializedViewHealth | 1, 0 | Avg | Der Wert ist 1, wenn die Ansicht als fehlerfrei betrachtet wird, andernfalls 0. | Database, MaterializedViewName |
| MaterializedViewAgeSeconds | Sekunden | Avg | Das Alter (age) der Sicht ist definiert durch den aktuellen Zeitpunkt abzüglich des letzten Erfassungszeitpunkts, der von der Sicht verarbeitet wurde. Der Metrikwert ist die Zeit in Sekunden (je niedriger der Wert, desto „fehlerfreier“ die Sicht). |
Database, MaterializedViewName |
| MaterializedViewResult | 1 | Avg | Die Metrik enthält eine Result Dimension, die das Ergebnis des letzten Materialisierungszyklus angibt (details zu möglichen Werten finden Sie in der MaterializedViewResult-Metrik ). Der Metrikwert ist immer „1“. |
Database, MaterializedViewName, Result |
| MaterializedViewRecordsInDelta | Anzahl von Datensätzen | Avg | Die Anzahl von Datensätzen, die sich derzeit im nicht verarbeiteten Teil der Quelltabelle befinden. Weitere Informationen finden Sie im Abschnitt zur Funktionsweise von materialisierten Sichten. | Database, MaterializedViewName |
| MaterializedViewExtentsRebuild | Anzahl von Erweiterungen | Avg | Die Anzahl von Erweiterungen („Extents“), die während des Materialisierungszyklus Aktualisierungen benötigten. | Database, MaterializedViewName |
| MaterializedViewDataLoss | 1 | Max | Die Metrik wird ausgelöst, wenn nicht verarbeitete Quelldaten der Aufbewahrung nähern. Gibt an, dass die materialisierte Sicht fehlerhaft ist. | Database, MaterializedViewName, Kind |
Partitionierungsmetriken
Partitionierungsmetriken überwachen den Partitionierungsprozess für Tabellen mit einer Partitionierungsrichtlinie.
| Metrik | Einheit | Aggregation | Beschreibung der Metrik | Dimensionen |
|---|---|---|---|---|
| PartitioningPercentage | Percent | Durchschnitt, Minimum, Maximum | Der Prozentsatz der Datensätze, die relativ zur Gesamtzahl der Datensätze partitioniert wurden. | Database, Table |
| PartitioningPercentageHot | Percent | Durchschnitt, Minimum, Maximum | Der Prozentsatz der partitionierten Datensätze im Zusammenhang mit der Gesamtzahl der Datensätze (nur im "hot"-Cache). | Database, Table |
| ProcessedPartitionedRecords | Percent | Avg, Min, Max, Sum | Die Anzahl der im gemessenen Zeitfenster partitionierten Datensätze. | Database, Table |