Verwenden von Follower-Datenbanken
Mit der Funktion „Follower-Datenbank“ können Sie eine Datenbank, die sich in einem anderen Cluster befindet, an Ihren Azure Data Explorer-Cluster anfügen. Die Follower-Datenbank wird im schreibgeschützten Modus angefügt, sodass Sie die Daten anzeigen und Abfragen für die Daten ausführen können, die in der Leader-Datenbank erfasst wurden. Die Follower-Datenbank synchronisiert Änderungen in den Leader-Datenbanken. Aufgrund der Synchronisierung gibt es bei der Datenverfügbarkeit eine Zeitverzögerung von einigen Sekunden bis zu einigen Minuten. Die Länge der Zeitverzögerung hängt von der Gesamtgröße der Metadaten in der Leader-Datenbank ab. Die Leader- und Follower-Datenbanken verwenden dasselbe Speicherkonto zum Abrufen der Daten. Der Speicher befindet sich im Besitz der Leader-Datenbank. Die Follower-Datenbank zeigt die Daten an, ohne sie erfassen zu müssen. Da die angefügte Datenbank eine schreibgeschützte Datenbank ist, können die Daten, Tabellen und Richtlinien in der Datenbank nicht geändert werden, mit Ausnahme der Cacherichtlinie, Prinzipale und Berechtigungen. Angefügte Datenbanken können nicht gelöscht werden. Zum Löschen müssen sie zunächst vom Leader- oder Follower-Cluster getrennt werden.
Das Anfügen einer Datenbank an einen anderen Cluster mithilfe der Follower-Funktion wird als Infrastruktur zum Freigeben von Daten zwischen Organisationen und Teams verwendet. Die Funktion ist nützlich, um Computeressourcen zu trennen und so eine Produktionsumgebung vor nicht produktionsbezogenen Anwendungsfällen zu schützen. Follower können auch verwendet werden, um die Kosten eines Azure Data Explorer-Clusters demjenigen zuzuordnen, der Abfragen für die Daten ausführt.
Codebeispiele, die auf früheren SDK-Versionen basieren, finden Sie im archivierten Artikel.
Welche Datenbanken wird gefolgt?
- Ein Cluster kann einer Datenbank, mehreren Datenbanken oder allen Datenbanken eines Leader-Clusters folgen.
- Ein einzelner Cluster kann Datenbanken von mehreren Leader-Clustern folgen.
- Ein Cluster kann sowohl Follower- als auch Leader-Datenbanken enthalten.
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
- Ein Azure Data Explorer-Cluster und eine Azure Data Explorer-Cluster-Datenbank für den Leader und den Follower. Erstellen eines Clusters und einer Datenbank
- Die Leader-Datenbank muss Daten enthalten. Das Erfassen von Daten ist mithilfe einer der verschiedenen Methoden möglich, die unter Übersicht über die Datenerfassung erläutert werden.
Anfügen einer Datenbank
Es gibt verschiedene Methoden zum Anfügen einer Datenbank. In diesem Artikel wird das Anfügen einer Datenbank mithilfe von C#, Python, PowerShell oder einer Azure Resource Manager-Vorlage beschrieben. Zum Anfügen einer Datenbank benötigen Sie einen Benutzer, eine Gruppe, einen Dienstprinzipal oder eine verwaltete Identität mit mindestens der Rolle „Mitwirkender“ für den Leader-Cluster und den Follower-Cluster. Sie können Rollenzuweisungen mit dem Azure-Portal, PowerShell, der Azure CLI und einer ARM-Vorlage hinzufügen oder entfernen. Weitere Informationen zur rollenbasierten Zugriffssteuerung in Azure (Role-Based Access Control, RBAC) und zu den verschiedenen Rollen finden Sie hier und hier.
Hinweis
Die Voraberstellung einer Follower-Datenbank ist nicht erforderlich, da während des Anfügevorgangs eine erstellt wird.
Freigabe auf Tabellenebene
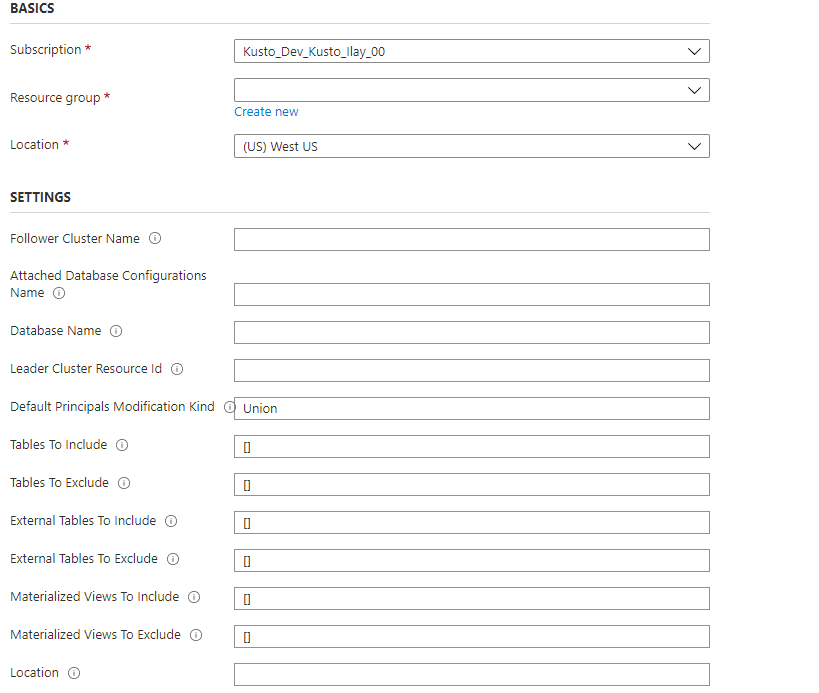
Beim Anfügen der Datenbank wird auch allen Tabellen, externen Tabellen und materialisierten Sichten gefolgt. Sie können bestimmte Tabellen/externe Tabellen/materialisierte Sichten freigeben, indem Sie TableLevelSharingProperties konfigurieren.
„TableLevelSharingProperties“ enthält acht Zeichenfolgenarrays: tablesToInclude, tablesToExclude, externalTablesToInclude, externalTablesToExclude, materializedViewsToInclude, materializedViewsToExclude, functionsToInclude und functionsToExclude. Die maximale Anzahl von Einträgen in allen Arrays zusammen beträgt 100.
Hinweis
- Die Freigabe auf Tabellenebene wird nicht unterstützt, wenn die Notation „*“ (alle Datenbanken) verwendet wird.
- Wenn materialisierte Sichten einbezogen werden, werden auch ihre Quelltabellen einbezogen.
Beispiele
Das folgende Beispiel umfasst alle Tabellen. Standardmäßig wird allen Tabellen ohne die Schreibweise „*“ gefolgt:
tablesToInclude = []
Das folgende Beispiel umfasst alle Funktionen. Standardmäßig wird allen Funktionen ohne die Schreibweise „*“ gefolgt:
functionsToInclude = []
Das folgende Beispiel umfasst alle Tabellen mit Namen, die mit „Logs“ beginnen:
tablesToInclude = ["Logs*"]
Das folgende Beispiel umfasst alle externen Tabellen:
externalTablesToExclude = ["*"]
Das folgende Beispiel enthält alle materialisierten Ansichten:
materializedViewsToExclude=["*"]
Außer Kraft setzen der Datenbank
Wenn Sie möchten, können Sie den Datenbanknamen im Follower-Cluster vom Leader-Cluster unterscheiden. Sie können beispielsweise denselben Datenbanknamen aus mehreren Leader-Clustern an einen Follower-Cluster anfügen. Um einen anderen Datenbanknamen anzugeben, konfigurieren Sie die Eigenschaften „DatabaseNameOverride“ oder „DatabaseNamePrefix“.
Anfügen einer Datenbank mithilfe von C#
Erforderliche NuGet-Pakete
- Installieren Sie Azure.ResourceManager.Kusto.
- Installieren Sie Azure.Identity für die Authentifizierung.
C#-Beispiel
var tenantId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx"; //Directory (tenant) ID
var clientId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx"; //Application ID
var clientSecret = "PlaceholderClientSecret"; //Client Secret
var followerSubscriptionId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx";
var credentials = new ClientSecretCredential(tenantId, clientId, clientSecret);
var resourceManagementClient = new ArmClient(credentials, followerSubscriptionId);
var followerResourceGroupName = "followerResourceGroup";
var followerClusterName = "follower";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(followerResourceGroupName)).Value;
var cluster = (await resourceGroup.GetKustoClusterAsync(followerClusterName)).Value;
var attachedDatabaseConfigurations = cluster.GetKustoAttachedDatabaseConfigurations();
var attachedDatabaseConfigurationName = "attachedDatabaseConfiguration"
var leaderSubscriptionId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx";
var leaderResourceGroup = "leaderResourceGroup";
var leaderClusterName = "leader";
var attachedDatabaseConfigurationData = new KustoAttachedDatabaseConfigurationData
{
ClusterResourceId = new ResourceIdentifier($"/subscriptions/{leaderSubscriptionId}/resourceGroups/{leaderResourceGroup}/providers/Microsoft.Kusto/Clusters/{leaderClusterName}"),
DatabaseName = "<databaseName>", // Can be a specific database name in a leader cluster or * for all databases
DefaultPrincipalsModificationKind = KustoDatabaseDefaultPrincipalsModificationKind.Union,
Location = AzureLocation.NorthCentralUS
};
// Table level sharing properties are not supported when using '*' all databases notation.
if (attachedDatabaseConfigurationData.DatabaseName != "*")
{
// Set up the table level sharing properties - the following is just an example.
attachedDatabaseConfigurationData.TableLevelSharingProperties = new KustoDatabaseTableLevelSharingProperties();
attachedDatabaseConfigurationData.TableLevelSharingProperties.TablesToInclude.Add("table1");
attachedDatabaseConfigurationData.TableLevelSharingProperties.TablesToExclude.Add("table2");
attachedDatabaseConfigurationData.TableLevelSharingProperties.ExternalTablesToExclude.Add("exTable1");
attachedDatabaseConfigurationData.TableLevelSharingProperties.ExternalTablesToInclude.Add("exTable2");
attachedDatabaseConfigurationData.TableLevelSharingProperties.MaterializedViewsToInclude.Add("matTable1");
attachedDatabaseConfigurationData.TableLevelSharingProperties.MaterializedViewsToExclude.Add("matTable2");
attachedDatabaseConfigurationData.TableLevelSharingProperties.FunctionsToInclude.Add("func1");
attachedDatabaseConfigurationData.TableLevelSharingProperties.FunctionsToExclude.Add("func2");
}
await attachedDatabaseConfigurations.CreateOrUpdateAsync(WaitUntil.Completed, attachedDatabaseConfigurationName, attachedDatabaseConfigurationData);
Überprüfen, ob die Datenbank erfolgreich angehängt wurde
Um zu überprüfen, ob die Datenbank erfolgreich angefügt wurde, suchen Sie im Azure-Portal nach angefügten Datenbanken. Sie können das erfolgreiche Anfügen der Datenbanken im Follower- oder Leader-Cluster überprüfen.
Überprüfen des Follower-Clusters
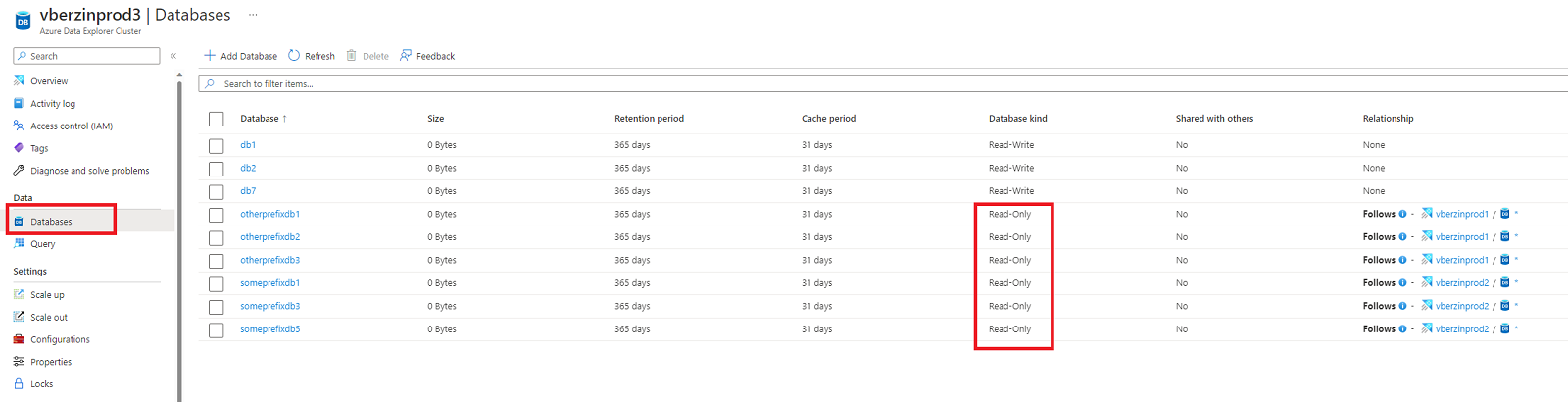
Navigieren Sie zum Follower-Cluster, und wählen Sie Datenbanken aus.
Suchen Sie in der Datenbankliste nach neuen schreibgeschützten Datenbanken.
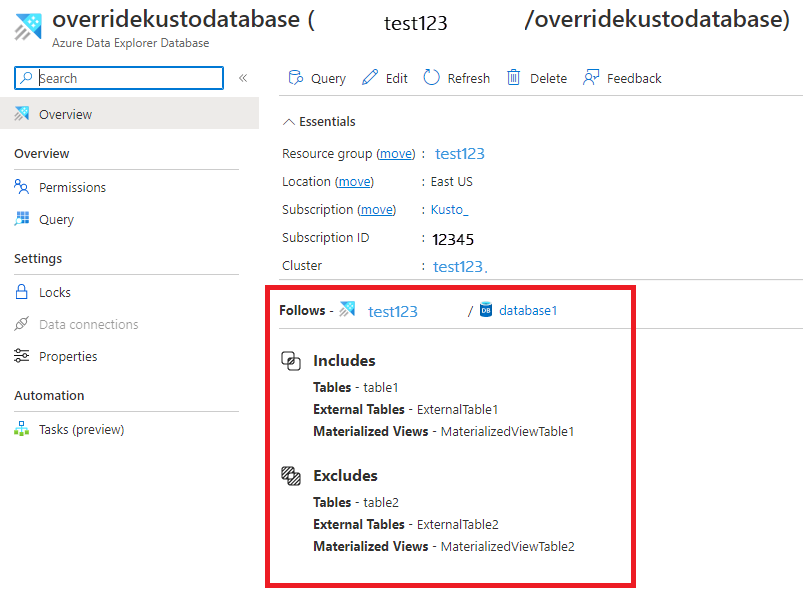
Sie können diese Liste auch auf der Übersichtsseite der Datenbank anzeigen:

Überprüfen des Leader-Clusters
Navigieren Sie zum Leader-Cluster, und wählen Sie Datenbanken aus.
Überprüfen Sie, ob die relevanten Datenbanken unter FREIGEGEBEN FÜR WEITERE PERSONEN> mit Ja gekennzeichnet sind.
Schalten Sie den Beziehungslink um, um Details anzuzeigen.
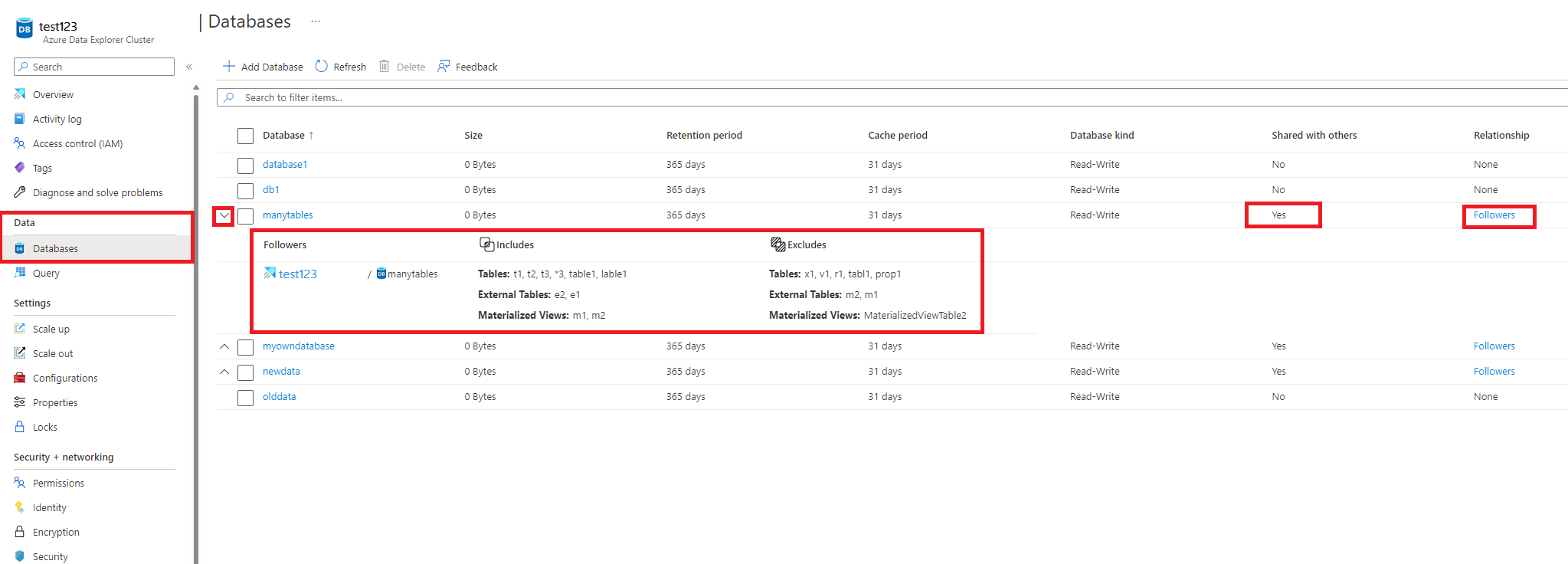
Sie können dies auch auf der Übersichtsseite der Datenbank anzeigen:
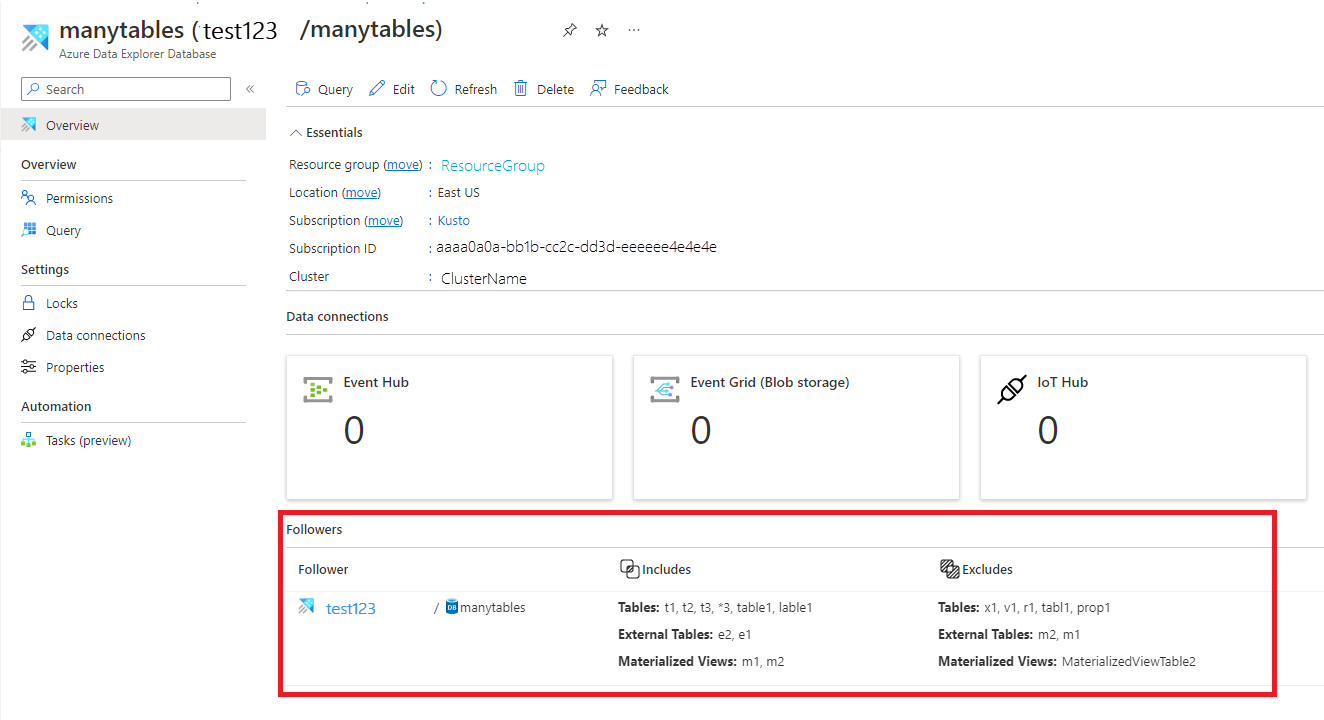
Trennen der Follower-Datenbank
Hinweis
Zum Trennen einer Datenbank auf Follower- oder Leader-Seite benötigen Sie einen Benutzer, eine Gruppe, einen Dienstprinzipal oder eine verwaltete Identität mit mindestens der Rolle „Mitwirkender“ für den Cluster, von dem Sie die Datenbank trennen. Im Beispiel unten wird ein Dienstprinzipal verwendet.
Trennen der angefügten Follower-Datenbank vom Follower-Cluster mit C#**
Vom Follower-Cluster kann jede angefügte Follower-Datenbank wie folgt getrennt werden:
var tenantId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx"; //Directory (tenant) ID
var clientId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx"; //Application ID
var clientSecret = "PlaceholderClientSecret"; //Client Secret
var followerSubscriptionId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx";
var credentials = new ClientSecretCredential(tenantId, clientId, clientSecret);
var resourceManagementClient = new ArmClient(credentials, followerSubscriptionId);
var followerResourceGroupName = "testrg";
//The cluster and database attached database configuration are created as part of the prerequisites
var followerClusterName = "follower";
var attachedDatabaseConfigurationsName = "attachedDatabaseConfiguration";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(followerResourceGroupName)).Value;
var cluster = (await resourceGroup.GetKustoClusterAsync(followerClusterName)).Value;
var attachedDatabaseConfiguration = (await cluster.GetKustoAttachedDatabaseConfigurationAsync(attachedDatabaseConfigurationsName)).Value;
await attachedDatabaseConfiguration.DeleteAsync(WaitUntil.Completed);
Trennen der angefügten Follower-Datenbank vom Leader-Cluster mit C#
Vom Leader-Cluster kann jede angefügte Datenbank wie folgt getrennt werden:
var tenantId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx"; //Directory (tenant) ID
var clientId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx"; //Application ID
var clientSecret = "PlaceholderClientSecret"; //Client Secret
var leaderSubscriptionId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx";
var credentials = new ClientSecretCredential(tenantId, clientId, clientSecret);
var resourceManagementClient = new ArmClient(credentials, leaderSubscriptionId);
var leaderResourceGroupName = "testrg";
var leaderClusterName = "leader";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(leaderResourceGroupName)).Value;
var cluster = (await resourceGroup.GetKustoClusterAsync(leaderClusterName)).Value;
var followerSubscriptionId = "xxxxxxxx-xxxxx-xxxx-xxxx-xxxxxxxxx";
var followerResourceGroupName = "followerResourceGroup";
//The cluster and attached database configuration that are created as part of the Prerequisites
var followerClusterName = "follower";
var attachedDatabaseConfigurationsName = "attachedDatabaseConfiguration";
var followerDatabaseDefinition = new KustoFollowerDatabaseDefinition(
clusterResourceId: new ResourceIdentifier($"/subscriptions/{followerSubscriptionId}/resourceGroups/{followerResourceGroupName}/providers/Microsoft.Kusto/Clusters/{followerClusterName}"),
attachedDatabaseConfigurationName: attachedDatabaseConfigurationsName
);
await cluster.DetachFollowerDatabasesAsync(WaitUntil.Completed, followerDatabaseDefinition);
Verwalten von Prinzipalen, Berechtigungen und Cacherichtlinie
Verwalten von Prinzipalen
Wenn Sie eine Datenbank anfügen, geben Sie die Standardänderungsart für Prinzipale an. Der Standardeinstellung besteht darin, die autorisierten Überschreibungsprinzipale mit der Leader-Datenbanksammlung von autorisierten Prinzipalen zu kombinieren.
| Variante | Beschreibung |
|---|---|
| Union | Die angefügten Datenbankprinzipale umfassen immer die ursprünglichen Datenbankprinzipale und weitere neue Prinzipale, die der Follower-Datenbank hinzugefügt werden. |
| Ersetzen | Keine Vererbung von Prinzipalen aus der ursprünglichen Datenbank. Für die angefügte Datenbank müssen neue Prinzipale erstellt werden. |
| None | Die angefügten Datenbankprinzipale umfassen nur die Prinzipale der ursprünglichen Datenbank ohne weitere Prinzipale. |
Weitere Informationen zur Verwendung von Verwaltungsbefehlen zum Konfigurieren der autorisierten Prinzipale finden Sie unter Verwaltungsbefehle zum Verwalten eines Follower-Clusters.
Verwalten von Berechtigungen
Das Verwalten der Berechtigung für schreibgeschützte Datenbanken entspricht der Vorgehensweise bei allen Datenbanktypen. Informationen zum Zuweisen von Berechtigungen finden Sie unter Verwalten von Datenbankberechtigungen im Azure-Portal. Alternativ können Sie Verwaltungsbefehle zum Verwalten von Datenbanksicherheitsrollen verwenden.
Konfigurieren der Cacherichtlinie
Der Administrator der Follower-Datenbank kann die Cacherichtlinie der angefügten Datenbank oder einer der zugehörigen Tabellen im Hostingcluster ändern. Die Standardeinstellung besteht darin, die Quelldatenbank in der Leaderclusterdatenbank und Zwischenspeicherungsrichtlinien auf Tabellenebene mit den Richtlinien zu kombinieren, die in den Überschreibungsrichtlinien auf Datenbank- und Tabellenebene definiert sind. Sie können beispielsweise über eine 30-Tage-Cacherichtlinie für die Leader-Datenbank zur monatlichen Berichterstellung und eine 3-Tage-Cacherichtlinie für die Follower-Datenbank zum ausschließlichen Abfragen der aktuellen Daten für die Problembehandlung verfügen. Weitere Informationen zur Verwendung von Verwaltungsbefehlen zum Konfigurieren der Cacherichtlinie für die Follower-Datenbank oder -Tabelle finden Sie unter Verwaltungsbefehle zum Verwalten eines Follower-Clusters.
Hinweise
- Wenn allen Datenbanken vom Follower-Cluster gefolgt wird und Konflikte zwischen den Datenbanken von Leader-/Follower-Clustern auftreten, werden diese Konflikte wie folgt gelöst:
- Eine im Follower-Cluster erstellte Datenbank mit dem Namen DB hat Vorrang vor einer Datenbank mit demselben Namen, die im Leader-Cluster erstellt wurde. Daher muss die Datenbank DB im Follower-Cluster entfernt oder umbenannt werden, damit der Follower-Cluster die Datenbank DB des Leaders beinhalten kann.
- Eine Datenbank mit dem Namen DB, der mindestens zwei Leader-Cluster folgen, wird willkürlich aus einem Leader-Cluster ausgewählt, und ihr wird nicht mehr als einmal gefolgt.
- Befehle zum Anzeigen der Clusteraktivitätsprotokolle und des Verlaufs, die in einem Follower-Cluster ausgeführt werden, zeigen die Aktivität und den Verlauf für den Follower-Cluster. Ihre Resultsets enthalten nicht die Ergebnisse der Leader-Cluster.
- Beispiel: Mit einem Befehl vom Typ
.show queries, der für den Follower-Cluster ausgeführt wird, werden nur Abfragen angezeigt, die für Datenbanken ausgeführt wurden, denen der Follower-Cluster folgt. Abfragen, die für die gleiche Datenbank im Leader-Cluster ausgeführt wurden, werden nicht angezeigt.
- Beispiel: Mit einem Befehl vom Typ
Begrenzungen
- Die Leader- und Follower-Cluster müssen sich in derselben Region befinden.
- Wenn die Streamingerfassung für eine als Leader fungierende Datenbank verwendet wird, muss die Streamingerfassung auch für den Follower-Cluster aktiviert sein, um Streamingerfassungsdaten folgen zu können.
- Das Folgen eines Clusters mit Datenverschlüsselung mit vom Kunden verwalteten Schlüsseln (CMK) wird mit den folgenden Einschränkungen unterstützt:
- Weder der Follower-Cluster noch der Leader-Cluster folgen anderen Clustern.
- Wenn ein Follower-Cluster einem Leader-Cluster folgt, bei dem CMK aktiviert ist, und der Zugriff des Leaders auf den Schlüssel widerrufen wird, werden sowohl der Leader- als auch der Follower-Cluster angehalten. In diesem Fall können Sie entweder das CMK-Problem beheben und dann den Follower-Cluster fortsetzen oder die Follower-Datenbanken vom Follower-Cluster trennen und unabhängig vom Leader-Cluster fortsetzen.
- Sie können eine Datenbank, die an einen anderen Cluster angefügt ist, erst nach dem Trennen löschen.
- Sie können einen Cluster mit einer Datenbank, die an einen anderen Cluster angefügt ist, erst nach dem Trennen löschen.
- Eigenschaften für die Freigabe auf Tabellenebene werden nicht unterstützt, wenn allen Datenbanken gefolgt wird.
- Um externe Tabellen in Follower-Datenbanken abzufragen, die eine verwaltete Identität als Authentifizierungsmethode verwenden, muss die verwaltete Identität zum Follower-Cluster hinzugefügt werden. Diese Funktion funktioniert nicht, wenn die Leader- und Follower-Cluster in verschiedenen Mandanten bereitgestellt werden.