Abfragen von Daten in Azure Data Lake mit Azure Data Explorer
Azure Data Lake Storage ist eine hochgradig skalierbare und kostengünstige Data Lake-Lösung für Big Data-Analysen. Dank des leistungsstarken Dateisystems kombiniert mit immenser Skalierbarkeit und Profitabilität können Sie in kurzer Zeit aufschlussreiche Erkenntnisse gewinnen. Data Lake Storage Gen2 erweitert die Funktionen von Azure Blob Storage und ist für Analyseworkloads optimiert.
Azure Data Explorer ist in Azure Blob Storage und Azure Data Lake Storage (Gen1 und Gen2) integriert und bietet schnellen, zwischengespeicherten und indizierten Zugriff auf Daten, die in externen Speichern gespeichert sind. Sie können Daten analysieren und abfragen, ohne sie vorher in Azure Data Explorer erfassen zu müssen. Sie können auch erfasste und nicht erfasste externe Daten gleichzeitig abfragen. Weitere Informationen finden Sie unter Erstellen einer externen Tabelle mithilfe des Assistenten für Azure Data Explorer Web-UI. Eine kurze Übersicht finden Sie unter externe Tabellen.
Tipp
Zur Erzielung der besten Abfrageleistung ist die Datenerfassung in Azure Data Explorer erforderlich. Die Möglichkeit, externe Daten ohne vorherige Erfassung abzufragen, sollte nur für Verlaufsdaten oder selten abgefragte Daten genutzt werden. Optimieren Sie Ihre Abfrageleistung von externen Daten, um optimale Ergebnisse zu erzielen.
Erstellen einer externen Tabelle
Nehmen wir an, Sie haben viele CSV-Dateien, die historische Informationen zu Produkten enthalten, die in einem Lagerhaus aufbewahrt werden, und Sie möchten eine schnelle Analyse durchführen, um die fünf beliebtesten Produkte des letzten Jahres zu finden. In diesem Beispiel sehen die CSV-Dateien wie folgt aus:
| Timestamp | ProductId | productdescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3,5“ DS/HD Diskette |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Synthesizer |
| ... | ... | ... |
Die Dateien werden im Azure Blob Storage mycompanystorage in einem Container namens archivedproducts gespeichert, partitioniert nach Datum:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Um eine KQL-Abfrage direkt mit diesen CSV-Dateien auszuführen, verwenden Sie den Befehl .create external table, um eine externe Tabelle in Azure Data Explorer zu definieren. Weitere Informationen zu den Optionen des Befehls zum Erstellen externer Tabellen finden Sie unter Befehle für externe Tabellen.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
Die externe Tabelle ist jetzt im linken Bereich der Azure Data Explorer-Webbenutzeroberfläche sichtbar:
Berechtigungen für externe Tabellen
- Der Datenbankbenutzer kann eine externe Tabelle erstellen. Der Ersteller der Tabelle wird automatisch zum Tabellenadministrator.
- Der Cluster-, Datenbank- oder Tabellenadministrator kann eine vorhandene Tabelle bearbeiten.
- Alle Datenbankbenutzer oder -leser können eine externe Tabelle abfragen.
Abfragen einer externen Tabelle
Sobald eine externe Tabelle definiert ist, kann die external_table()-Funktion verwendet werden, um darauf zu verweisen. Bei dem Rest der Abfrage handelt es sich um die standardmäßige Kusto-Abfragesprache (KQL).
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Gemeinsames Abfragen externer und erfasster Daten
Externe Tabellen und Tabellen mit erfassten Daten können in derselben Abfrage abgefragt werden. Mit join oder union können Sie die externe Tabelle mit anderen Daten aus Azure Data Explorer, SQL Server-Instanzen oder anderen Quellen verknüpfen. Verwenden Sie eine let( ) statement, um einem externen Tabellenverweis einen Kurznamen zuzuweisen.
Im folgenden Beispiel ist Products eine Tabelle mit erfassten Daten, und ArchivedProducts ist eine externe Tabelle, die wir zuvor definiert haben:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Abfragen hierarchischer Datenformate
Azure Data Explorer ermöglicht das Abfragen hierarchischer Formate, z. B. JSON, Parquet, Avro und ORC. Um ein hierarchisches Datenschema einem externen Tabellenschema (falls es abweicht) zuzuordnen, verwenden Sie Befehle für die Zuordnung externer Tabellen. Wenn Sie beispielsweise JSON-Protokolldateien im folgenden Format abfragen möchten:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
Die Definition der externen Tabelle sieht wie folgt aus:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Definieren Sie eine JSON-Zuordnung, die Datenfelder zu den Definitionsfeldern der externen Tabelle zuordnet:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Wenn Sie die externe Tabelle abfragen, wird die Zuordnung aufgerufen, und relevante Daten werden den externen Tabellenspalten zugeordnet:
external_table('ApiCalls') | take 10
Weitere Informationen zur Zuordnungssyntax finden Sie unter Datenzuordnungen.
Abfragen der externen Tabelle TaxiRides im Cluster „help“
Verwenden Sie den Testcluster namens help, um verschiedene Azure Data Explorer-Funktionen auszuprobieren. Der Cluster help enthält eine externe Tabellendefinition für ein New York City Taxi-Dataset, das Milliarden von Taxifahrten enthält.
Erstellen der externen Tabelle TaxiRides
In diesem Abschnitt wird Abfragen angezeigt, mit der externe Tabelle TaxiRides im Cluster help erstellt wurde. Da diese Tabelle bereits erstellt wurde, können Sie diesen Abschnitt überspringen und direkt zum Abschnitt Abfragen von Daten der externen Tabelle TaxiRides wechseln.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Sie finden die erstellte Tabelle TaxiRides, indem Sie sich den linken Bereich der Azure Data Explorer-Webbenutzeroberfläche ansehen:
Abfragen von Daten der externen Tabelle TaxiRides
Melden Sie sich bei https://dataexplorer.azure.com/clusters/help/databases/Samples an.
Abfragen der externen Tabelle TaxiRides ohne Partitionierung
Führen Sie diese Abfrage in der externen Tabelle TaxiRides aus, um Fahrten für jeden Wochentag im gesamten Dataset anzuzeigen.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Diese Abfrage zeigt den Wochentag mit den meisten Fahrten. Da die Daten nicht partitioniert sind, kann es bis zu mehrere Minuten dauern, bis die Abfrage Ergebnisse zurückgibt.
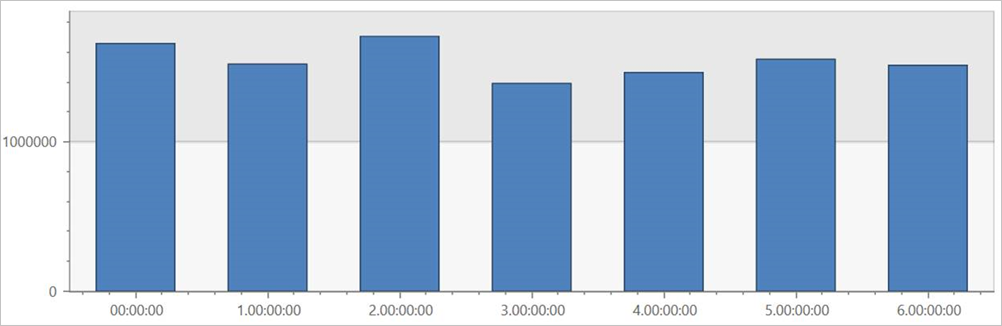
Abfragen der externen Tabelle „TaxiRides“ mit Partitionierung
Führen Sie diese Abfrage für die externe Tabelle TaxiRides aus, um die im Januar 2017 genutzten Taxiarten (gelb oder grün) darzustellen.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Diese Abfrage verwendet Partitionierung, wodurch Ausführungszeit und Leistung optimiert werden. Die Abfrage filtert eine partitionierte Spalte („pickup_datetime“) und gibt die Ergebnisse in wenigen Sekunden zurück.
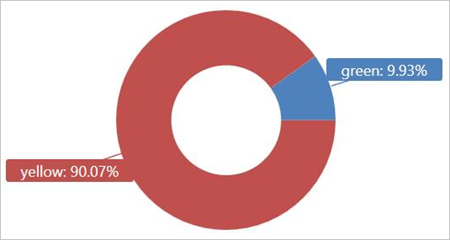
Sie können weitere Abfragen zur Ausführung für die externe Tabelle TaxiRides schreiben und weitere Erkenntnisse über die Daten gewinnen.
Optimieren der Abfrageleistung
Optimieren Sie die Abfrageleistung im Lake anhand der folgenden bewährten Methoden für das Abfragen externer Daten.
Datenformat
- Verwenden Sie aus den folgenden Gründen ein spaltenares Format für analytische Abfragen:
- Nur die für eine Abfrage relevanten Spalten können gelesen werden.
- Die Codierungsverfahren für Spalten können die Datengröße erheblich verringern.
- Azure Data Explorer unterstützt die Spaltenformate Parquet und ORC. Das Parquet-Format wird wegen seiner optimierten Implementierung empfohlen.
Azure-Region
Überprüfen Sie, ob sich die externen Daten in derselben Azure-Region wie Ihr Azure Data Explorer-Cluster befinden. Diese Einrichtung reduziert die Kosten und die Zeit für den Datenabruf.
Dateigröße
Die optimale Dateigröße beträgt Hunderte MB (bis zu 1 GB) pro Datei. Vermeiden Sie eine große Anzahl kleiner Dateien, die unnötigen Mehraufwand bedeuten, z. B. durch eine Verlangsamung der Dateienumeration und Einschränkungen bei der Verwendung des Spaltenformats. Die Anzahl der Dateien sollte größer als die Anzahl der CPU-Kerne in Ihrem Azure Data Explorer-Cluster sein.
Komprimierung
Verwenden Sie Komprimierung, um die Datenmenge zu reduzieren, die vom Remotespeicher abgerufen wird. Verwenden Sie für das Parquet-Format den internen Parquet-Komprimierungsmechanismus, der Spaltengruppen separat komprimiert, sodass sie einzeln gelesen werden können. Wenn Sie die Verwendung des Komprimierungsmechanismus überprüfen möchten, vergewissern Sie sich, dass die Dateien wie folgt benannt wurden: <Dateiname>.gz.parquet oder <Dateiname>.snappy.parquet und nicht <Dateiname>.parquet.gz.
Partitionierung
Organisieren Sie Ihre Daten mithilfe von „Ordner“partitionen, mit deren Hilfe bei der Abfrage irrelevante Pfade übersprungen werden können. Berücksichtigen Sie bei der Partitionierung die Dateigröße und allgemeine Filter in Ihren Abfragen, wie z. B. Zeitstempel oder Mandanten-ID.
Größe des virtuellen Computers
Wählen Sie VM-SKUs mit mehr Kernen und höherem Netzwerkdurchsatz aus (Arbeitsspeicher ist weniger wichtig). Weitere Informationen finden Sie unter Auswählen der passenden VM-SKU für Ihren Azure Data Explorer-Cluster.