Referenz zum Konfigurationsschema des Daten-API-Generators
Für das Modul des Daten-API-Generators ist eine Konfigurationsdatei erforderlich. Die Konfigurationsdatei des Daten-API-Generators bietet einen strukturierten und umfassenden Ansatz zum Einrichten Ihrer API, wobei alles von Umgebungsvariablen bis hin zu entitätsspezifischen Konfigurationen beschrieben wird. Dieses JSON-formatierte Dokument beginnt mit einer $schema-Eigenschaft. Mit diesem Setup wird das Dokument überprüft.
Die Eigenschaften database-type und connection-string eine nahtlose Integration mit Datenbanksystemen, von Azure SQL-Datenbank zu Cosmos DB NoSQL-API, gewährleisten.
Die Konfigurationsdatei kann Optionen wie:
- Datenbankdienst- und Verbindungsinformationen
- Globale Konfigurationsoptionen und Laufzeitkonfigurationsoptionen
- Gruppe verfügbar gemachter Entitäten
- Authentifizierungsmethode
- Sicherheitsregeln, die für den Zugriff auf Identitäten erforderlich sind
- Namenszuordnungsregeln zwischen API und Datenbank
- Beziehungen zwischen Entitäten, die nicht abgeleitet werden können
- Eindeutige Features für bestimmte Datenbankdienste
Syntaxübersicht
Hier ist eine schnelle Aufschlüsselung der primären "Abschnitte" in einer Konfigurationsdatei.
{
"$schema": "...",
"data-source": { ... },
"data-source-files": [ ... ],
"runtime": {
"rest": { ... },
"graphql": { .. },
"host": { ... },
"cache": { ... },
"telemetry": { ... },
"pagination": { ... }
}
"entities": [ ... ]
}
Eigenschaften der obersten Ebene
Hier ist die Beschreibung der Eigenschaften der obersten Ebene in einem Tabellenformat:
| Eigentum | Beschreibung |
|---|---|
| $schema | Gibt das JSON-Schema für die Überprüfung an, um sicherzustellen, dass die Konfiguration dem erforderlichen Format entspricht. |
| Datenquellen- | Enthält die Details zum Datenbanktyp und der Verbindungszeichenfolge, die zum Herstellen der Datenbankverbindung erforderlich ist. |
| Datenquellendateien | Ein optionales Array, das andere Konfigurationsdateien angibt, die andere Datenquellen definieren können. |
| Laufzeit- | Konfiguriert Laufzeitverhalten und -einstellungen, einschließlich Untereigenschaften für REST-, GraphQL-, Host-, Cache-und Telemetrie-. |
| Entitäten | Definiert den Satz von Entitäten (Datenbanktabellen, Ansichten usw.), die über die API verfügbar gemacht werden, einschließlich ihrer Zuordnungen, Berechtigungenund Beziehungen. |
Beispielkonfigurationen
Hier ist eine Beispielkonfigurationsdatei, die nur erforderliche Eigenschaften für eine einzelne einfache Entität enthält. Dieses Beispiel soll ein minimales Szenario veranschaulichen.
{
"$schema": "https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json",
"data-source": {
"database-type": "mssql",
"connection-string": "@env('SQL_CONNECTION_STRING')"
},
"entities": {
"User": {
"source": "dbo.Users",
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
Ein Beispiel für ein komplexeres Szenario finden Sie in der End-to-End-Beispielkonfiguration.
Umgebungen
Die Konfigurationsdatei des Daten-API-Generators kann Szenarien unterstützen, in denen Sie mehrere Umgebungen unterstützen müssen, ähnlich wie die appSettings.json Datei in ASP.NET Core. Das Framework bietet drei gemeinsamen Umgebungswerte; Development, Stagingund Production; Sie können jedoch einen beliebigen Umgebungswert verwenden, den Sie auswählen. Die Umgebung, die der Daten-API-Generator verwendet, muss mithilfe der umgebungsvariablen DAB_ENVIRONMENT konfiguriert werden.
Betrachten Sie ein Beispiel, in dem Sie eine Basiskonfiguration und eine entwicklungsspezifische Konfiguration benötigen. In diesem Beispiel sind zwei Konfigurationsdateien erforderlich:
| Umwelt | |
|---|---|
| dab-config.json | Basis |
| dab-config.Development.json | Entwicklung |
Um die entwicklungsspezifische Konfiguration zu verwenden, müssen Sie die DAB_ENVIRONMENT Umgebungsvariable auf Developmentfestlegen.
Umgebungsspezifische Konfigurationsdateien überschreiben Eigenschaftswerte in der Basiskonfigurationsdatei. Wenn in diesem Beispiel der wert connection-string in beiden Dateien festgelegt wird, wird der Wert aus der *.Development.json Datei verwendet.
Lesen Sie diese Matrix, um besser zu verstehen, welcher Wert verwendet wird, je nachdem, wo dieser Wert in einer datei angegeben (oder nicht angegeben) ist.
| in der Basiskonfiguration angegeben |
In der Basiskonfiguration nicht angegeben | |
|---|---|---|
| in der aktuellen Umgebungskonfiguration angegeben | Aktuelle Umgebung | Aktuelle Umgebung |
| In der aktuellen Umgebungskonfiguration nicht angegeben | Basis | Nichts |
Ein Beispiel für die Verwendung mehrerer Konfigurationsdateien finden Sie unter Verwenden des Daten-API-Generators mit Umgebungen.
Konfigurationseigenschaften
Dieser Abschnitt enthält alle möglichen Konfigurationseigenschaften, die für eine Konfigurationsdatei verfügbar sind.
Schema
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
$root |
$schema |
Schnur | ✔️ Ja | Nichts |
Jede Konfigurationsdatei beginnt mit einer $schema-Eigenschaft und gibt das JSON-Schema zur Überprüfung an.
Format
{
"$schema": <string>
}
Beispiele
Schemadateien sind für Versionen 0.3.7-alpha ab bestimmten URLs verfügbar, um sicherzustellen, dass Sie die richtige Version oder das neueste verfügbare Schema verwenden.
https://github.com/Azure/data-api-builder/releases/download/<VERSION>-<suffix>/dab.draft.schema.json
Ersetzen Sie VERSION-suffix durch die gewünschte Version.
https://github.com/Azure/data-api-builder/releases/download/v0.3.7-alpha/dab.draft.schema.json
Die neueste Version des Schemas ist immer unter https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.jsonverfügbar.
Hier sind einige Beispiele für gültige Schemawerte.
| Version | URI | Beschreibung |
|---|---|---|
| 0.3.7-Alpha | https://github.com/Azure/data-api-builder/releases/download/v0.3.7-alpha/dab.draft.schema.json |
Verwendet das Konfigurationsschema aus einer Alphaversion des Tools. |
| 0.10.23 | https://github.com/Azure/data-api-builder/releases/download/v0.10.23/dab.draft.schema.json |
Verwendet das Konfigurationsschema für eine stabile Version des Tools. |
| Neueste | https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json |
Verwendet die neueste Version des Konfigurationsschemas. |
Anmerkung
Versionen des Daten-API-Generators vor 0.3.7-Alpha- weisen möglicherweise einen anderen Schema-URI auf.
Datenquelle
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
$root |
data-source |
Schnur | ✔️ Ja | Nichts |
Der abschnitt data-source definiert die Datenbank und den Zugriff auf die Datenbank über die Verbindungszeichenfolge. Außerdem werden Datenbankoptionen definiert. Die eigenschaft data-source konfiguriert die zum Herstellen einer Verbindung mit der Sicherungsdatenbank erforderlichen Anmeldeinformationen. Im abschnitt data-source wird die Back-End-Datenbankkonnektivität beschrieben, wobei sowohl die database-type als auch die connection-stringangegeben werden.
Format
{
"data-source": {
"database-type": <string>,
"connection-string": <string>,
// mssql-only
"options": {
"set-session-context": <true> (default) | <false>
},
// cosmosdb_nosql-only
"options": {
"database": <string>,
"container": <string>,
"schema": <string>
}
}
}
Eigenschaften
| Erforderlich | Art | |
|---|---|---|
database-type |
✔️ Ja | Enumerationszeichenfolge |
connection-string |
✔️ Ja | Schnur |
options |
❌ Nein | Objekt |
Datenbanktyp
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
data-source |
database-type |
Enumerationszeichenfolge | ✔️ Ja | Nichts |
Eine Enumerationszeichenfolge, die verwendet wird, um den Datenbanktyp anzugeben, der als Datenquelle verwendet werden soll.
Format
{
"data-source": {
"database-type": <string>
}
}
Typwerte
Die eigenschaft type gibt die Art der Back-End-Datenbank an.
| Art | Beschreibung | Min Version |
|---|---|---|
mssql |
Azure SQL-Datenbank | Nichts |
mssql |
Azure SQL MI | Nichts |
mssql |
SQL Server | SQL 2016 |
sqldw |
Azure SQL Data Warehouse | Nichts |
postgresql |
PostgreSQL | v11 |
mysql |
MySQL | v8 |
cosmosdb_nosql |
Azure Cosmos DB für NoSQL | Nichts |
cosmosdb_postgresql |
Azure Cosmos DB für PostgreSQL | Nichts |
Verbindungszeichenfolge
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
data-source |
connection-string |
Schnur | ✔️ Ja | Nichts |
Eine Zeichenfolge Wert, der eine gültige Verbindungszeichenfolge enthält, um eine Verbindung mit dem Zieldatenbankdienst herzustellen. Die ADO.NET Verbindungszeichenfolge zum Herstellen einer Verbindung mit der Back-End-Datenbank. Weitere Informationen finden Sie unter ADO.NET Verbindungszeichenfolgen.
Format
{
"data-source": {
"connection-string": <string>
}
}
Verbindungsresilienz
Der Daten-API-Generator führt datenbankanforderungen automatisch erneut durch, nachdem vorübergehende Fehler erkannt wurden. Die Wiederholungslogik folgt einer Exponential Backoff- Strategie, bei der die maximale Anzahl von Wiederholungen fünfist. Die Wiederholungsrücklaufdauer nach der Berechnung der nachfolgenden Anforderungen mithilfe dieser Formel (vorausgesetzt, der aktuelle Wiederholungsversuch ist r): $r^2$
Mit dieser Formel können Sie die Zeit für jeden Wiederholungsversuch in Sekunden berechnen.
| Nachschlag | |
|---|---|
| First | 2 |
| Second | 4 |
| Dritte | 8 |
| Fourth | 16 |
| fünfte | 32 |
Azure SQL und SQL Server
Der Daten-API-Generator verwendet die SqlClient-Bibliothek, um mithilfe der Verbindungszeichenfolge, die Sie in der Konfigurationsdatei bereitstellen, eine Verbindung mit Azure SQL oder SQL Server herzustellen. Hier finden Sie eine Liste aller unterstützten Verbindungszeichenfolgenoptionen: SqlConnection.ConnectionString-Eigenschaft.
Der Daten-API-Generator kann auch mit verwalteten Dienstidentitäten (MSI) eine Verbindung mit der Zieldatenbank herstellen, wenn der Daten-API-Generator in Azure gehostet wird. Die in DefaultAzureCredential Bibliothek definierte Azure.Identity wird verwendet, um eine Verbindung mithilfe bekannter Identitäten herzustellen, wenn Sie keinen Benutzernamen oder ein Kennwort in Ihrer Verbindungszeichenfolge angeben. Weitere Informationen finden Sie in DefaultAzureCredential Beispielen.
-
Vom Benutzer zugewiesene verwaltete Identität (UMI): Fügen Sie die Authentication und Benutzer-ID Eigenschaften an Ihre Verbindungszeichenfolge an, und ersetzen Sie dabei die Client-ID Ihrer vom Benutzer zugewiesenen verwalteten Identität:
Authentication=Active Directory Managed Identity; User Id=<UMI_CLIENT_ID>;. -
Vom System zugewiesene verwaltete Identität (SMI): Fügen Sie die eigenschaft Authentication an, und schließen Sie die UserId und Password Argumente aus Ihrer Verbindungszeichenfolge aus:
Authentication=Active Directory Managed Identity;. Das Fehlen der UserId und Password Verbindungszeichenfolgeneigenschaften signalisiert DAB zur Authentifizierung mithilfe einer vom System zugewiesenen verwalteten Identität.
Weitere Informationen zum Konfigurieren einer verwalteten Dienstidentität mit Azure SQL oder SQL Server finden Sie unter Verwaltete Identitäten in Microsoft Entra für Azure SQL.
Beispiele
Der für die Verbindungszeichenfolge verwendete Wert hängt größtenteils vom datenbankdienst ab, der in Ihrem Szenario verwendet wird. Sie können die Verbindungszeichenfolge immer in einer Umgebungsvariable speichern und mithilfe der @env()-Funktion darauf zugreifen.
| Wert | Beschreibung | |
|---|---|---|
| Verwenden des Azure SQL-Datenbankzeichenfolgenwerts | Server=<server-address>;Database=<name-of-database>;User ID=<username>;Password=<password>; |
Verbindungszeichenfolge mit einem Azure SQL-Datenbankkonto. Weitere Informationen finden Sie unter Azure SQL-Datenbankverbindungszeichenfolgen. |
| Verwenden der Azure-Datenbank für Den PostgreSQL-Zeichenfolgenwert | Server=<server-address>;Database=<name-of-database>;Port=5432;User Id=<username>;Password=<password>;Ssl Mode=Require; |
Verbindungszeichenfolge mit einem Azure-Datenbank für PostgreSQL-Konto. Weitere Informationen finden Sie unter Azure-Datenbank für PostgreSQL-Verbindungszeichenfolgen. |
| Verwenden von Azure Cosmos DB für noSQL-Zeichenfolgenwert | AccountEndpoint=<endpoint>;AccountKey=<key>; |
Verbindungszeichenfolge mit einem Azure Cosmos DB für NoSQL-Konto. Weitere Informationen finden Sie unter Azure Cosmos DB für NoSQL-Verbindungszeichenfolgen. |
| Verwenden der Azure-Datenbank für mySQL-Zeichenfolgenwert | Server=<server-address>;Database=<name-of-database>;User ID=<username>;Password=<password>;Sslmode=Required;SslCa=<path-to-certificate>; |
Verbindungszeichenfolge mit einem Azure-Datenbank für MySQL-Konto. Weitere Informationen finden Sie unter Azure-Datenbank für MySQL-Verbindungszeichenfolgen. |
| Access-Umgebungsvariablen | @env('SQL_CONNECTION_STRING') |
Greifen Sie auf eine Umgebungsvariable vom lokalen Computer zu. In diesem Beispiel wird auf die umgebungsvariable SQL_CONNECTION_STRING verwiesen. |
Trinkgeld
Vermeiden Sie als bewährte Methode das Speichern vertraulicher Informationen in Ihrer Konfigurationsdatei. Verwenden Sie nach Möglichkeit @env(), um auf Umgebungsvariablen zu verweisen. Weitere Informationen finden Sie unter @env() Funktion.
In diesen Beispielen wird lediglich veranschaulicht, wie jeder Datenbanktyp konfiguriert werden kann. Ihr Szenario kann eindeutig sein, aber dieses Beispiel ist ein guter Ausgangspunkt. Ersetzen Sie die Platzhalter wie myserver, myDataBase, myloginund myPassword durch die tatsächlichen Werte, die für Ihre Umgebung spezifisch sind.
mssql"data-source": { "database-type": "mssql", "connection-string": "$env('my-connection-string')", "options": { "set-session-context": true } }-
Typisches Verbindungszeichenfolgenformat:
"Server=tcp:myserver.database.windows.net,1433;Initial Catalog=myDataBase;Persist Security Info=False;User ID=mylogin;Password=myPassword;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;"
-
Typisches Verbindungszeichenfolgenformat:
postgresql"data-source": { "database-type": "postgresql", "connection-string": "$env('my-connection-string')" }-
Typisches Verbindungszeichenfolgenformat:
"Host=myserver.postgres.database.azure.com;Database=myDataBase;Username=mylogin@myserver;Password=myPassword;"
-
Typisches Verbindungszeichenfolgenformat:
mysql"data-source": { "database-type": "mysql", "connection-string": "$env('my-connection-string')" }-
Typisches Verbindungszeichenfolgenformat:
"Server=myserver.mysql.database.azure.com;Database=myDataBase;Uid=mylogin@myserver;Pwd=myPassword;"
-
Typisches Verbindungszeichenfolgenformat:
cosmosdb_nosql"data-source": { "database-type": "cosmosdb_nosql", "connection-string": "$env('my-connection-string')", "options": { "database": "Your_CosmosDB_Database_Name", "container": "Your_CosmosDB_Container_Name", "schema": "Path_to_Your_GraphQL_Schema_File" } }-
Typisches Verbindungszeichenfolgenformat:
"AccountEndpoint=https://mycosmosdb.documents.azure.com:443/;AccountKey=myAccountKey;"
-
Typisches Verbindungszeichenfolgenformat:
cosmosdb_postgresql"data-source": { "database-type": "cosmosdb_postgresql", "connection-string": "$env('my-connection-string')" }-
Typisches Verbindungszeichenfolgenformat:
"Host=mycosmosdb.postgres.database.azure.com;Database=myDataBase;Username=mylogin@mycosmosdb;Password=myPassword;Port=5432;SSL Mode=Require;"
-
Typisches Verbindungszeichenfolgenformat:
Anmerkung
Die angegebenen "Optionen" wie database, containerund schema sind spezifisch für die NoSQL-API von Azure Cosmos DB und nicht für die PostgreSQL-API. Für Azure Cosmos DB mit der PostgreSQL-API würden die "Optionen" nicht database, containeroder schema wie im NoSQL-Setup enthalten.
Optionen
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
data-source |
options |
Objekt | ❌ Nein | Nichts |
Ein optionaler Abschnitt mit zusätzlichen Schlüsselwertparametern für bestimmte Datenbankverbindungen.
Ob der options Abschnitt erforderlich ist oder nicht, hängt weitgehend vom verwendeten Datenbankdienst ab.
Format
{
"data-source": {
"options": {
"<key-name>": <string>
}
}
}
options: { set-session-context: boolean }
Für Azure SQL und SQL Server kann der Daten-API-Generator SESSION_CONTEXT nutzen, um vom Benutzer angegebene Metadaten an die zugrunde liegende Datenbank zu senden. Solche Metadaten stehen dem Daten-API-Generator aufgrund der im Zugriffstoken vorhandenen Ansprüche zur Verfügung. Die SESSION_CONTEXT Daten sind während der Datenbankverbindung für die Datenbank verfügbar, bis diese Verbindung geschlossen ist. Weitere Informationen finden Sie unter Sitzungskontext.
Beispiel für eine gespeicherte SQL-Prozedur:
CREATE PROC GetUser @userId INT AS
BEGIN
-- Check if the current user has access to the requested userId
IF SESSION_CONTEXT(N'user_role') = 'admin'
OR SESSION_CONTEXT(N'user_id') = @userId
BEGIN
SELECT Id, Name, Age, IsAdmin
FROM Users
WHERE Id = @userId;
END
ELSE
BEGIN
RAISERROR('Unauthorized access', 16, 1);
END
END;
JSON-Konfiguration (Beispiel):
{
"$schema": "https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json",
"data-source": {
"database-type": "mssql",
"connection-string": "@env('SQL_CONNECTION_STRING')",
"options": {
"set-session-context": true
}
},
"entities": {
"User": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
},
"permissions": [
{
"role": "authenticated",
"actions": ["execute"]
}
]
}
}
}
Erklärung:
Gespeicherte Prozedur (
GetUser):- Die Prozedur überprüft die
SESSION_CONTEXT, um zu überprüfen, ob der Aufrufer die Rolleadminhat oder mit dem bereitgestelltenuserIdübereinstimmt. - Nicht autorisierter Zugriff führt zu einem Fehler.
- Die Prozedur überprüft die
JSON-Konfiguration:
-
set-session-contextist aktiviert, benutzermetadaten vom Zugriffstoken an die Datenbank zu übergeben. - Die
parameters-Eigenschaft ordnet denuserIdParameter zu, der von der gespeicherten Prozedur benötigt wird. - Der
permissions-Block stellt sicher, dass nur authentifizierte Benutzer die gespeicherte Prozedur ausführen können.
-
Datenquellendateien
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
$root |
data-source-files |
Zeichenfolgenarray | ❌ Nein | Nichts |
Der Daten-API-Generator unterstützt mehrere Konfigurationsdateien für unterschiedliche Datenquellen, wobei eine Datei auf oberster Ebene runtime Einstellungen verwaltet wird. Alle Konfigurationen verwenden dasselbe Schema, sodass runtime Einstellungen in einer Datei ohne Fehler zulässig sind. Untergeordnete Konfigurationen werden automatisch zusammengeführt, aber Zirkelbezüge sollten vermieden werden. Entitäten können in separate Dateien aufgeteilt werden, um eine bessere Verwaltung zu ermöglichen, aber Beziehungen zwischen Entitäten müssen sich in derselben Datei befinden.
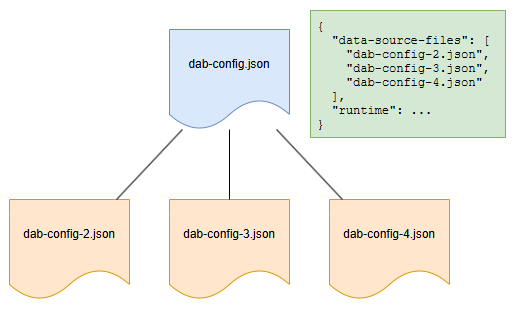
Format
{
"data-source-files": [ <string> ]
}
Überlegungen zur Konfigurationsdatei
- Jede Konfigurationsdatei muss die eigenschaft
data-sourceenthalten. - Jede Konfigurationsdatei muss die eigenschaft
entitiesenthalten. - Die einstellung
runtimewird nur aus der Konfigurationsdatei der obersten Ebene verwendet, auch wenn sie in anderen Dateien enthalten ist. - Untergeordnete Konfigurationsdateien können auch eigene untergeordnete Dateien enthalten.
- Konfigurationsdateien können nach Bedarf in Unterordnern organisiert werden.
- Entitätsnamen müssen für alle Konfigurationsdateien eindeutig sein.
- Beziehungen zwischen Entitäten in verschiedenen Konfigurationsdateien werden nicht unterstützt.
Beispiele
{
"data-source-files": [
"dab-config-2.json"
]
}
{
"data-source-files": [
"dab-config-2.json",
"dab-config-3.json"
]
}
Die Syntax des Unterordners wird ebenfalls unterstützt:
{
"data-source-files": [
"dab-config-2.json",
"my-folder/dab-config-3.json",
"my-folder/my-other-folder/dab-config-4.json"
]
}
Laufzeit
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
$root |
runtime |
Objekt | ✔️ Ja | Nichts |
Im Abschnitt runtime werden Optionen beschrieben, die das Laufzeitverhalten und die Einstellungen für alle verfügbar gemachten Entitäten beeinflussen.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api),
"enabled": <true> (default) | <false>,
"request-body-strict": <true> (default) | <false>
},
"graphql": {
"path": <string> (default: /graphql),
"enabled": <true> (default) | <false>,
"allow-introspection": <true> (default) | <false>
},
"host": {
"mode": "production" (default) | "development",
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
},
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
},
"cache": {
"enabled": <true> | <false> (default),
"ttl-seconds": <integer; default: 5>
},
"pagination": {
"max-page-size": <integer; default: 100000>,
"default-page-size": <integer; default: 100>,
"max-response-size-mb": <integer; default: 158>
},
"telemetry": {
"application-insights": {
"connection-string": <string>,
"enabled": <true> | <false> (default)
}
}
}
Eigenschaften
| Erforderlich | Art | |
|---|---|---|
rest |
❌ Nein | Objekt |
graphql |
❌ Nein | Objekt |
host |
❌ Nein | Objekt |
cache |
❌ Nein | Objekt |
Beispiele
Hier ist ein Beispiel für einen Laufzeitabschnitt mit mehreren gängigen Standardparametern angegeben.
{
"runtime": {
"rest": {
"enabled": true,
"path": "/api",
"request-body-strict": true
},
"graphql": {
"enabled": true,
"path": "/graphql",
"allow-introspection": true
},
"host": {
"mode": "development",
"cors": {
"allow-credentials": false,
"origins": [
"*"
]
},
"authentication": {
"provider": "StaticWebApps",
"jwt": {
"audience": "<client-id>",
"issuer": "<identity-provider-issuer-uri>"
}
}
},
"cache": {
"enabled": true,
"ttl-seconds": 5
},
"pagination": {
"max-page-size": -1 | <integer; default: 100000>,
"default-page-size": -1 | <integer; default: 100>,
"max-response-size-mb": <integer; default: 158>
},
"telemetry": {
"application-insights": {
"connection-string": "<connection-string>",
"enabled": true
}
}
}
}
GraphQL (Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime |
graphql |
Objekt | ❌ Nein | Nichts |
Dieses Objekt definiert, ob GraphQL aktiviert ist und der Name[s] verwendet wird, um die Entität als GraphQL-Typ verfügbar zu machen. Dieses Objekt ist optional und wird nur verwendet, wenn der Standardname oder die Standardeinstellungen nicht ausreichen. In diesem Abschnitt werden die globalen Einstellungen für den GraphQL-Endpunkt beschrieben.
Format
{
"runtime": {
"graphql": {
"path": <string> (default: /graphql),
"enabled": <true> (default) | <false>,
"depth-limit": <integer; default: none>,
"allow-introspection": <true> (default) | <false>,
"multiple-mutations": <object>
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
enabled |
❌ Nein | boolesch | STIMMT |
path |
❌ Nein | Schnur | /graphql (Standard) |
allow-introspection |
❌ Nein | boolesch | STIMMT |
multiple-mutations |
❌ Nein | Objekt | { create: { enabled: false } } |
Aktiviert (GraphQL-Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.graphql |
enabled |
boolesch | ❌ Nein | Nichts |
Definiert, ob die GraphQL-Endpunkte global aktiviert oder deaktiviert werden sollen. Wenn dies global deaktiviert ist, wären keine Entitäten unabhängig von den einzelnen Entitätseinstellungen über GraphQL-Anforderungen zugänglich.
Format
{
"runtime": {
"graphql": {
"enabled": <true> (default) | <false>
}
}
}
Beispiele
In diesem Beispiel ist der GraphQL-Endpunkt für alle Entitäten deaktiviert.
{
"runtime": {
"graphql": {
"enabled": false
}
}
}
Tiefengrenzwert (GraphQL-Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.graphql |
depth-limit |
ganze Zahl | ❌ Nein | Nichts |
Die maximal zulässige Abfragetiefe einer Abfrage.
Die Fähigkeit von GraphQL, geschachtelte Abfragen basierend auf Beziehungsdefinitionen zu verarbeiten, ist ein unglaubliches Feature, mit dem Benutzer komplexe, verwandte Daten in einer einzelnen Abfrage abrufen können. Da Benutzer jedoch weiterhin geschachtelte Abfragen hinzufügen, erhöht sich die Komplexität der Abfrage, was schließlich die Leistung und Zuverlässigkeit der Datenbank und des API-Endpunkts beeinträchtigen kann. Um diese Situation zu verwalten, legt die runtime/graphql/depth-limit-Eigenschaft die maximal zulässige Tiefe einer GraphQL-Abfrage (und Mutation) fest. Diese Eigenschaft ermöglicht Es Entwicklern, ein Gleichgewicht zu erzielen, sodass Benutzer die Vorteile geschachtelter Abfragen genießen können, während Beschränkungen gesetzt werden, um Szenarien zu verhindern, die die Leistung und Qualität des Systems gefährden könnten.
Beispiele
{
"runtime": {
"graphql": {
"depth-limit": 2
}
}
}
Pfad (GraphQL-Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.graphql |
path |
Schnur | ❌ Nein | "/graphql" |
Definiert den URL-Pfad, in dem der GraphQL-Endpunkt verfügbar gemacht wird. Wenn dieser Parameter beispielsweise auf /graphqlfestgelegt ist, wird der GraphQL-Endpunkt als /graphqlverfügbar gemacht. Standardmäßig ist der Pfad /graphql.
Wichtig
Unterpfade sind für diese Eigenschaft nicht zulässig. Ein angepasster Pfadwert für den GraphQL-Endpunkt ist derzeit nicht verfügbar.
Format
{
"runtime": {
"graphql": {
"path": <string> (default: /graphql)
}
}
}
Beispiele
In diesem Beispiel ist der GraphQL-Stamm-URI /query.
{
"runtime": {
"graphql": {
"path": "/query"
}
}
}
Introspection zulassen (GraphQL-Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.graphql |
allow-introspection |
boolesch | ❌ Nein | STIMMT |
Dieses boolesche Flag steuert die Möglichkeit, Schemaintrospection-Abfragen für den GraphQL-Endpunkt auszuführen. Das Aktivieren der Introspektion ermöglicht Clients das Abfragen des Schemas nach Informationen über die verfügbaren Datentypen, die Arten von Abfragen, die sie ausführen können, und die verfügbaren Mutationen.
Dieses Feature ist während der Entwicklung hilfreich, um die Struktur der GraphQL-API und für Tools zu verstehen, die automatisch Abfragen generiert. Für Produktionsumgebungen ist es jedoch möglicherweise deaktiviert, die Schemadetails der API zu verdecken und die Sicherheit zu verbessern. Standardmäßig ist die Introspektion aktiviert, sodass das GraphQL-Schema sofort und umfassend erforscht werden kann.
Format
{
"runtime": {
"graphql": {
"allow-introspection": <true> (default) | <false>
}
}
}
Beispiele
In diesem Beispiel ist die Introspection deaktiviert.
{
"runtime": {
"graphql": {
"allow-introspection": false
}
}
}
Mehrere Mutationen (GraphQL-Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.graphql |
multiple-mutations |
Objekt | ❌ Nein | Nichts |
Konfiguriert alle mehrere Mutationsvorgänge für die GraphQL-Laufzeit.
Anmerkung
Standardmäßig sind mehrere Mutationen nicht aktiviert und müssen explizit für die Aktivierung konfiguriert werden.
Format
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": <true> (default) | <false>
}
}
}
}
}
Eigenschaften
| Erforderlich | Art | |
|---|---|---|
create |
❌ Nein | Objekt |
Mehrere Mutationen – Erstellen (GraphQL-Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.graphql.multiple-mutations |
create |
boolesch | ❌ Nein | FALSCH |
Konfiguriert mehrere Erstellungsvorgänge für die GraphQL-Laufzeit.
Format
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": <true> (default) | <false>
}
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
enabled |
✔️ Ja | boolesch | STIMMT |
Beispiele
Im Folgenden wird veranschaulicht, wie Sie mehrere Mutationen in der GraphQL-Laufzeit aktivieren und verwenden. In diesem Fall ist der create Vorgang so konfiguriert, dass die Erstellung mehrerer Datensätze in einer einzigen Anforderung ermöglicht wird, indem die runtime.graphql.multiple-mutations.create.enabled-Eigenschaft auf truefestgelegt wird.
Konfigurationsbeispiel
Diese Konfiguration ermöglicht mehrere create Mutationen:
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": true
}
}
}
},
"entities": {
"User": {
"source": "dbo.Users",
"permissions": [
{
"role": "anonymous",
"actions": ["create"]
}
]
}
}
}
GraphQL-Mutation (Beispiel)
Mit der oben genannten Konfiguration erstellt die folgende Mutation mehrere User Datensätze in einem einzigen Vorgang:
mutation {
createUsers(input: [
{ name: "Alice", age: 30, isAdmin: true },
{ name: "Bob", age: 25, isAdmin: false },
{ name: "Charlie", age: 35, isAdmin: true }
]) {
id
name
age
isAdmin
}
}
REST (Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime |
rest |
Objekt | ❌ Nein | Nichts |
In diesem Abschnitt werden die globalen Einstellungen für die REST-Endpunkte beschrieben. Diese Einstellungen dienen als Standardwerte für alle Entitäten, können aber in ihren jeweiligen Konfigurationen pro Entität außer Kraft gesetzt werden.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api),
"enabled": <true> (default) | <false>,
"request-body-strict": <true> (default) | <false>
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
enabled |
❌ Nein | boolesch | STIMMT |
path |
❌ Nein | Schnur | /API |
request-body-strict |
❌ Nein | boolesch | STIMMT |
Aktiviert (REST-Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.rest |
enabled |
boolesch | ❌ Nein | Nichts |
Ein boolesches Flag, das die globale Verfügbarkeit von REST-Endpunkten bestimmt. Wenn diese Option deaktiviert ist, können entitäten unabhängig von den einzelnen Entitätseinstellungen nicht über REST zugegriffen werden.
Format
{
"runtime": {
"rest": {
"enabled": <true> (default) | <false>,
}
}
}
Beispiele
In diesem Beispiel ist der REST-API-Endpunkt für alle Entitäten deaktiviert.
{
"runtime": {
"rest": {
"enabled": false
}
}
}
Pfad (REST-Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.rest |
path |
Schnur | ❌ Nein | "/api" |
Legt den URL-Pfad für den Zugriff auf alle verfügbar gemachten REST-Endpunkte fest. Wenn Sie z. B. path auf /api festlegen, kann der REST-Endpunkt auf /api/<entity>zugegriffen werden. Unterpfade sind nicht zulässig. Dieses Feld ist optional, wobei /api als Standard festgelegt ist.
Anmerkung
Beim Bereitstellen des Daten-API-Generators mithilfe von Static Web Apps (Vorschau) fügt der Azure-Dienst automatisch den zusätzlichen Unterpfad /data-api in die URL ein. Dieses Verhalten stellt die Kompatibilität mit vorhandenen Statischen Web App-Features sicher. Der resultierende Endpunkt wäre /data-api/api/<entity>. Dies ist nur für statische Web-Apps relevant.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api)
}
}
}
Wichtig
Der vom Benutzer bereitgestellte Unterpfade ist für diese Eigenschaft nicht zulässig.
Beispiele
In diesem Beispiel ist der STAMM-REST-API-URI /data.
{
"runtime": {
"rest": {
"path": "/data"
}
}
}
Trinkgeld
Wenn Sie eine Author Entität definieren, wäre der Endpunkt für diese Entität /data/Author.
Anforderungstext Strict (REST-Runtime)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.rest |
request-body-strict |
boolesch | ❌ Nein | STIMMT |
Diese Einstellung steuert, wie streng der Anforderungstext für REST-Mutationsvorgänge (z. B. POST, PUT, PATCH) überprüft wird.
-
true(Standard): Zusätzliche Felder im Anforderungstext, die tabellenspalten nicht zugeordnet sind, führen zu einerBadRequestAusnahme. -
false: Zusätzliche Felder werden ignoriert, und nur gültige Spalten werden verarbeitet.
Diese Einstellung nicht auf GET Anforderungen angewendet, da der Anforderungstext immer ignoriert wird.
Verhalten mit bestimmten Spaltenkonfigurationen
- Spalten mit einem Standardwert() werden während
INSERTnur ignoriert, wenn ihr Wert in der Nutzlastnullist. Spalten mit einer Standardeinstellung() werden unabhängig vom Nutzlastwert währendUPDATEnicht ignoriert. - Berechnete Spalten werden immer ignoriert.
- Automatisch generierte Spalten werden immer ignoriert.
Format
{
"runtime": {
"rest": {
"request-body-strict": <true> (default) | <false>
}
}
}
Beispiele
CREATE TABLE Users (
Id INT PRIMARY KEY IDENTITY,
Name NVARCHAR(50) NOT NULL,
Age INT DEFAULT 18,
IsAdmin BIT DEFAULT 0,
IsMinor AS IIF(Age <= 18, 1, 0)
);
Beispielkonfiguration
{
"runtime": {
"rest": {
"request-body-strict": false
}
}
}
INSERT-Verhalten mit request-body-strict: false
Anforderungsnutzlast:
{
"Id": 999,
"Name": "Alice",
"Age": null,
"IsAdmin": null,
"IsMinor": false,
"ExtraField": "ignored"
}
resultierende Insert-Anweisung:
INSERT INTO Users (Name) VALUES ('Alice');
-- Default values for Age (18) and IsAdmin (0) are applied by the database.
-- IsMinor is ignored because it’s a computed column.
-- ExtraField is ignored.
-- The database generates the Id value.
Antwortnutzlast:
{
"Id": 1, // Auto-generated by the database
"Name": "Alice",
"Age": 18, // Default applied
"IsAdmin": false, // Default applied
"IsMinor": true // Computed
}
UPDATE-Verhalten mit request-body-strict: false
Anforderungsnutzlast:
{
"Id": 1,
"Name": "Alice Updated",
"Age": null, // explicitely set to 'null'
"IsMinor": true, // ignored because computed
"ExtraField": "ignored"
}
resultierende Update-Anweisung:
UPDATE Users
SET Name = 'Alice Updated', Age = NULL
WHERE Id = 1;
-- IsMinor and ExtraField are ignored.
Antwortnutzlast:
{
"Id": 1,
"Name": "Alice Updated",
"Age": null,
"IsAdmin": false,
"IsMinor": false // Recomputed by the database (false when age is `null`)
}
Host (Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime |
host |
Objekt | ❌ Nein | Nichts |
Der Abschnitt host innerhalb der Laufzeitkonfiguration stellt Einstellungen bereit, die für die Betriebsumgebung des Daten-API-Generators von entscheidender Bedeutung sind. Zu diesen Einstellungen gehören Betriebsmodi, CORS-Konfiguration und Authentifizierungsdetails.
Format
{
"runtime": {
"host": {
"mode": "production" (default) | "development",
"max-response-size-mb": <integer; default: 158>,
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
},
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
mode |
❌ Nein | Enumerationszeichenfolge | Produktion |
cors |
❌ Nein | Objekt | Nichts |
authentication |
❌ Nein | Objekt | Nichts |
Beispiele
Hier sehen Sie ein Beispiel für eine laufzeit, die für das Entwicklungshosting konfiguriert ist.
{
"runtime": {
"host": {
"mode": "development",
"cors": {
"allow-credentials": false,
"origins": ["*"]
},
"authentication": {
"provider": "Simulator"
}
}
}
}
Modus (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host |
mode |
Schnur | ❌ Nein | "Produktion" |
Definiert, ob das Daten-API-Generatormodul im modus development oder production ausgeführt werden soll. Der Standardwert ist production.
In der Regel werden die zugrunde liegenden Datenbankfehler ausführlich verfügbar gemacht, indem die Standarddetailebene für Protokolle auf Debug festgelegt wird, wenn sie in der Entwicklung ausgeführt werden. In der Produktion wird die Detailstufe für Protokolle auf Errorfestgelegt.
Trinkgeld
Die Standardprotokollebene kann mithilfe von dab start --LogLevel <level-of-detail>weiter außer Kraft gesetzt werden. Weitere Informationen finden Sie unter Befehlszeilenschnittstellenreferenz (CLI).
Format
{
"runtime": {
"host": {
"mode": "production" (default) | "development"
}
}
}
Werte
Hier ist eine Liste der zulässigen Werte für diese Eigenschaft:
| Beschreibung | |
|---|---|
production |
Verwendung beim Hosten in der Produktion in Azure |
development |
Verwendung in der Entwicklung auf einem lokalen Computer |
Verhaltensweisen
- Nur im
developmentModus ist Swagger verfügbar. - Nur im
developmentModus ist Banana Cake Pop verfügbar.
Maximale Antwortgröße (Runtime)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host |
max-response-size-mb |
ganze Zahl | ❌ Nein | 158 |
Legt die maximale Größe (in Megabyte) für ein bestimmtes Ergebnis fest. Mit dieser Einstellung können Benutzer die Datenmenge konfigurieren, die der Speicher ihrer Hostplattform beim Streamen von Daten aus den zugrunde liegenden Datenquellen verarbeiten kann.
Wenn Benutzer große Resultsets anfordern, kann sie den Datenbank- und Daten-API-Generator belasten. Um dies zu beheben, ermöglicht max-response-size-mb Entwicklern, die maximale Antwortgröße in Megabyte zu begrenzen, da die Datenströme aus der Datenquelle. Dieser Grenzwert basiert auf der Gesamtdatengröße, nicht auf der Anzahl der Zeilen. Da Spalten in der Größe variieren können, können einige Spalten (z. B. Text, Binärdatei, XML oder JSON) bis zu 2 GB umfassen, wodurch einzelne Zeilen potenziell sehr groß sind. Diese Einstellung hilft Entwicklern, ihre Endpunkte zu schützen, indem Sie Die Antwortgrößen verschließen und Systemüberladungen verhindern und gleichzeitig die Flexibilität für unterschiedliche Datentypen beibehalten.
Zulässige Werte
| Wert | Ergebnis |
|---|---|
null |
Wird standardmäßig auf 158 MB festgelegt, wenn das Objekt nicht festgelegt oder explizit auf nullfestgelegt ist. |
integer |
Jede positive 32-Bit-Ganzzahl wird unterstützt. |
< 0 |
Nicht unterstützt. Überprüfungsfehler treten auf, wenn sie auf weniger als 1 MB festgelegt sind. |
Format
{
"runtime": {
"host": {
"max-response-size-mb": <integer; default: 158>
}
}
}
CORS (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host |
cors |
Objekt | ❌ Nein | Nichts |
CorS-Einstellungen (Cross-Origin Resource Sharing) für den Host des Daten-API-Generatormoduls.
Format
{
"runtime": {
"host": {
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
}
}
}
}
Eigenschaften
| Erforderlich | Art | |
|---|---|---|
allow-credentials |
❌ Nein | boolesch |
origins |
❌ Nein | Zeichenfolgenarray |
Zulassen von Anmeldeinformationen (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host.cors |
allow-credentials |
boolesch | ❌ Nein | FALSCH |
Bei "true" wird der Access-Control-Allow-Credentials CORS-Header festgelegt.
Anmerkung
Weitere Informationen zur Access-Control-Allow-Credentials CORS-Header finden Sie unter MDN Web Docs CORS Reference.
Format
{
"runtime": {
"host": {
"cors": {
"allow-credentials": <true> (default) | <false>
}
}
}
}
Ursprünge (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host.cors |
origins |
Zeichenfolgenarray | ❌ Nein | Nichts |
Legt ein Array mit einer Liste zulässiger Ursprünge für CORS fest. Diese Einstellung ermöglicht den *-Wildcard für alle Ursprünge.
Format
{
"runtime": {
"host": {
"cors": {
"origins": ["<array-of-strings>"]
}
}
}
}
Beispiele
Hier ist ein Beispiel für einen Host, der CORS ohne Anmeldeinformationen von allen Ursprüngen zulässt.
{
"runtime": {
"host": {
"cors": {
"allow-credentials": false,
"origins": ["*"]
}
}
}
}
Authentifizierung (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host |
authentication |
Objekt | ❌ Nein | Nichts |
Konfiguriert die Authentifizierung für den Daten-API-Generator-Host.
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<string>",
"issuer": "<string>"
}
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
provider |
❌ Nein | Enumerationszeichenfolge | StaticWebApps |
jwt |
❌ Nein | Objekt | Nichts |
Authentifizierung und Kundenverantwortung
Der Daten-API-Generator ist so konzipiert, dass er in einer breiteren Sicherheitspipeline ausgeführt wird, und es gibt wichtige Schritte zum Konfigurieren, bevor Anforderungen verarbeitet werden. Es ist wichtig zu verstehen, dass der Daten-API-Generator den direkten Aufrufer (z. B. Ihre Webanwendung) nicht authentifiziert, sondern den Endbenutzer basierend auf einem gültigen JWT-Token, das von einem vertrauenswürdigen Identitätsanbieter bereitgestellt wird (z. B. Entra-ID). Wenn eine Anforderung den Daten-API-Generator erreicht, wird davon ausgegangen, dass das JWT-Token gültig ist, und überprüft es anhand der von Ihnen konfigurierten Voraussetzungen, z. B. bestimmte Ansprüche. Autorisierungsregeln werden dann angewendet, um zu bestimmen, auf was der Benutzer zugreifen oder ändern kann.
Sobald die Autorisierung erfolgreich ist, führt der Daten-API-Generator die Anforderung mithilfe des kontos aus, das in der Verbindungszeichenfolge angegeben ist. Da für dieses Konto häufig erhöhte Berechtigungen zum Verarbeiten verschiedener Benutzeranforderungen erforderlich sind, ist es wichtig, seine Zugriffsrechte zu minimieren, um das Risiko zu verringern. Es wird empfohlen, Ihre Architektur zu schützen, indem Sie eine private Verknüpfung zwischen Ihrer Front-End-Webanwendung und dem API-Endpunkt konfigurieren und den Computer, auf dem daten-API-Generator gehostet wird, härten. Diese Maßnahmen tragen dazu bei, dass Ihre Umgebung sicher bleibt, Ihre Daten zu schützen und Sicherheitsrisiken zu minimieren, die ausgenutzt werden können, um auf vertrauliche Informationen zuzugreifen, sie zu ändern oder zu exfiltrieren.
Anbieter (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host.authentication |
provider |
Schnur | ❌ Nein | "StaticWebApps" |
Die authentication.provider Einstellung innerhalb der host Konfiguration definiert die Vom Daten-API-Generator verwendete Authentifizierungsmethode. Sie bestimmt, wie die API die Identität von Benutzern oder Diensten überprüft, die versuchen, auf ihre Ressourcen zuzugreifen. Diese Einstellung ermöglicht Flexibilität bei der Bereitstellung und Integration, indem verschiedene Authentifizierungsmechanismen unterstützt werden, die auf verschiedene Umgebungen und Sicherheitsanforderungen zugeschnitten sind.
| Anbieter | Beschreibung |
|---|---|
StaticWebApps |
Weist den Daten-API-Generator an, nach einer Reihe von HTTP-Headern zu suchen, die nur vorhanden sind, wenn sie in einer Statischen Web Apps-Umgebung ausgeführt werden. |
AppService |
Wenn die Laufzeit in Azure AppService mit aktivierter und konfigurierter AppService-Authentifizierung (EasyAuth) gehostet wird. |
AzureAd |
Microsoft Entra Identity muss so konfiguriert werden, dass eine an den Daten-API-Generator (die Server-App) gesendete Anforderung authentifiziert werden kann. Weitere Informationen finden Sie unter Microsoft Entra ID-Authentifizierung. |
Simulator |
Ein konfigurierbarer Authentifizierungsanbieter, der das Daten-API-Generatormodul anweist, alle Anforderungen als authentifiziert zu behandeln. Weitere Informationen finden Sie unter lokalen Authentifizierung. |
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...
}
}
}
}
Werte
Hier ist eine Liste der zulässigen Werte für diese Eigenschaft:
| Beschreibung | |
|---|---|
StaticWebApps |
Azure Static Web Apps |
AppService |
Azure App Service |
AzureAD |
Microsoft Entra-ID |
Simulator |
Simulator |
JSON-Webtoken (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host.authentication |
jwt |
Objekt | ❌ Nein | Nichts |
Wenn der Authentifizierungsanbieter auf AzureAD (Microsoft Entra ID) festgelegt ist, ist dieser Abschnitt erforderlich, um die Zielgruppe und Aussteller für das JSOn Web Tokens (JWT)-Token anzugeben. Diese Daten werden verwendet, um die Token für Ihren Microsoft Entra-Mandanten zu überprüfen.
Erforderlich, wenn der Authentifizierungsanbieter für die Microsoft Entra-ID AzureAD ist. In diesem Abschnitt müssen die audience und issuer angegeben werden, um das empfangene JWT-Token anhand des vorgesehenen AzureAD Mandanten für die Authentifizierung zu überprüfen.
| Einstellung | Beschreibung |
|---|---|
| Publikum | Identifiziert den vorgesehenen Empfänger des Tokens; In der Regel wird der in Microsoft Entra Identity (oder Ihrem Identitätsanbieter) registrierte Anwendungsbezeichner registriert, um sicherzustellen, dass das Token tatsächlich für Ihre Anwendung ausgestellt wurde. |
| Emittent | Gibt die URL der ausstellenden Behörde an, bei der es sich um den Tokendienst handelt, der das JWT ausgestellt hat. Diese URL sollte mit der Aussteller-URL des Identitätsanbieters übereinstimmen, aus der das JWT abgerufen wurde, wodurch der Ursprung des Tokens überprüft wird. |
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
audience |
❌ Nein | Schnur | Nichts |
issuer |
❌ Nein | Schnur | Nichts |
Beispiele
Der Daten-API-Generator (DAB) bietet flexible Authentifizierungsunterstützung, integration in Microsoft Entra Identity und benutzerdefinierte JSON Web Token (JWT)-Server. In dieser Abbildung stellt der JWT Server den Authentifizierungsdienst dar, der JWT-Token bei erfolgreicher Anmeldung an Clients ausgibt. Der Client übergibt dann das Token an DAB, das seine Ansprüche und Eigenschaften abfragen kann.
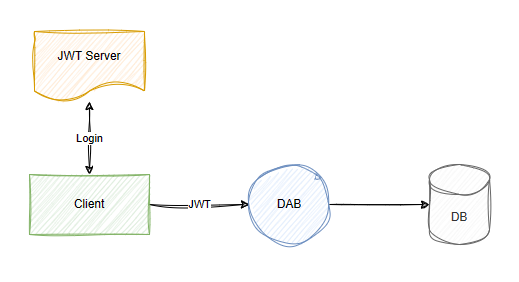
Im Folgenden sind Beispiele für die host Eigenschaft aufgeführt, die verschiedene Architekturoptionen bietet, die Sie in Ihrer Lösung treffen können.
Azure Static Web Apps
{
"host": {
"mode": "development",
"cors": {
"origins": ["https://dev.example.com"],
"credentials": true
},
"authentication": {
"provider": "StaticWebApps"
}
}
}
Mit StaticWebAppserwartet der Daten-API-Generator, dass Azure Static Web Apps die Anforderung authentifiziert, und der X-MS-CLIENT-PRINCIPAL HTTP-Header vorhanden ist.
Azure App Service
{
"host": {
"mode": "production",
"cors": {
"origins": [ "https://api.example.com" ],
"credentials": false
},
"authentication": {
"provider": "AppService",
"jwt": {
"audience": "9e7d452b-7e23-4300-8053-55fbf243b673",
"issuer": "https://example-appservice-auth.com"
}
}
}
}
Die Authentifizierung wird an einen unterstützten Identitätsanbieter delegiert, bei dem Zugriffstoken ausgestellt werden kann. Ein erworbenes Zugriffstoken muss in eingehende Anforderungen an den Daten-API-Generator eingeschlossen werden. Der Daten-API-Generator überprüft dann alle präsentierten Zugriffstoken, um sicherzustellen, dass der Daten-API-Generator die beabsichtigte Zielgruppe des Tokens war.
Microsoft Entra-ID
{
"host": {
"mode": "production",
"cors": {
"origins": [ "https://api.example.com" ],
"credentials": true
},
"authentication": {
"provider": "AzureAD",
"jwt": {
"audience": "c123d456-a789-0abc-a12b-3c4d56e78f90",
"issuer": "https://login.microsoftonline.com/98765f43-21ba-400c-a5de-1f2a3d4e5f6a/v2.0"
}
}
}
}
Simulator (nur Entwicklung)
{
"host": {
"mode": "development",
"authentication": {
"provider": "Simulator"
}
}
}
Zielgruppe (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host.authentication.jwt |
audience |
Schnur | ❌ Nein | Nichts |
Zielgruppe für das JWT-Token.
Format
{
"runtime": {
"host": {
"authentication": {
"jwt": {
"audience": "<client-id>"
}
}
}
}
}
Aussteller (Hostlaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.host.authentication.jwt |
issuer |
Schnur | ❌ Nein | Nichts |
Aussteller für das JWT-Token.
Format
{
"runtime": {
"host": {
"authentication": {
"jwt": {
"issuer": "<issuer-url>"
}
}
}
}
}
Paginierung (Runtime)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime |
pagination |
Objekt | ❌ Nein | Nichts |
Konfiguriert Paginierungsgrenzwerte für REST- und GraphQL-Endpunkte.
Format
{
"runtime": {
"pagination": {
"max-page-size": <integer; default: 100000>,
"default-page-size": <integer; default: 100>
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
max-page-size |
❌ Nein | ganze Zahl | 100,000 |
default-page-size |
❌ Nein | ganze Zahl | 100 |
Beispielkonfiguration
{
"runtime": {
"pagination": {
"max-page-size": 1000,
"default-page-size": 2
}
},
"entities": {
"Users": {
"source": "dbo.Users",
"permissions": [
{
"actions": ["read"],
"role": "anonymous"
}
]
}
}
}
REST-Paginierung (Beispiel)
In diesem Beispiel würde das Ausgeben der REST GET-Anforderung https://localhost:5001/api/users zwei Datensätze im value Array zurückgeben, da die default-page-size auf 2 festgelegt ist. Wenn weitere Ergebnisse vorhanden sind, enthält der Daten-API-Generator eine nextLink in der Antwort. Die nextLink enthält einen $after Parameter zum Abrufen der nächsten Datenseite.
Bitten:
GET https://localhost:5001/api/users
Antwort:
{
"value": [
{
"Id": 1,
"Name": "Alice",
"Age": 30,
"IsAdmin": true,
"IsMinor": false
},
{
"Id": 2,
"Name": "Bob",
"Age": 17,
"IsAdmin": false,
"IsMinor": true
}
],
"nextLink": "https://localhost:5001/api/users?$after=W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI=="
}
Mit dem nextLinkkann der Client den nächsten Satz von Ergebnissen abrufen.
GraphQL-Paginierung (Beispiel)
Verwenden Sie für GraphQL die Felder hasNextPage und endCursor für die Paginierung. Diese Felder geben an, ob weitere Ergebnisse verfügbar sind und einen Cursor zum Abrufen der nächsten Seite bereitstellen.
Frage:
query {
users {
items {
Id
Name
Age
IsAdmin
IsMinor
}
hasNextPage
endCursor
}
}
Antwort:
{
"data": {
"users": {
"items": [
{
"Id": 1,
"Name": "Alice",
"Age": 30,
"IsAdmin": true,
"IsMinor": false
},
{
"Id": 2,
"Name": "Bob",
"Age": 17,
"IsAdmin": false,
"IsMinor": true
}
],
"hasNextPage": true,
"endCursor": "W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI=="
}
}
}
Um die nächste Seite abzurufen, fügen Sie den endCursor Wert in die nächste Abfrage ein:
Abfrage mit Cursor:
query {
users(after: "W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI==") {
items {
Id
Name
Age
IsAdmin
IsMinor
}
hasNextPage
endCursor
}
}
Anpassen des Seitenformats
REST und GraphQL ermöglichen das Anpassen der Anzahl der Ergebnisse pro Abfrage mithilfe von $limit (REST) oder first (GraphQL).
$limit
/
first Wert |
Benehmen |
|---|---|
-1 |
Der Standardwert lautet max-page-size. |
< max-page-size |
Beschränkt die Ergebnisse auf den angegebenen Wert. |
0 oder < -1 |
Nicht unterstützt. |
> max-page-size |
Bei max-page-sizegedeckelt. |
Beispiel-REST-Abfrage:
GET https://localhost:5001/api/users?$limit=5
Beispiel für GraphQL-Abfrage:
query {
users(first: 5) {
items {
Id
Name
Age
IsAdmin
IsMinor
}
}
}
Maximale Seitengröße (Paginierungslaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.pagination |
max-page-size |
Int | ❌ Nein | 100,000 |
Legt die maximale Anzahl von Datensätzen auf oberster Ebene fest, die von REST oder GraphQL zurückgegeben werden. Wenn ein Benutzer mehr als max-page-sizeanfordert, werden die Ergebnisse auf max-page-sizebegrenzt.
Zulässige Werte
| Wert | Ergebnis |
|---|---|
-1 |
Standardmäßig wird der maximal unterstützte Wert verwendet. |
integer |
Jede positive 32-Bit-Ganzzahl wird unterstützt. |
< -1 |
Nicht unterstützt. |
0 |
Nicht unterstützt. |
Format
{
"runtime": {
"pagination": {
"max-page-size": <integer; default: 100000>
}
}
}
Standardseitengröße (Paginierungslaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.pagination |
default-page-size |
Int | ❌ Nein | 100 |
Legt die Standardanzahl der Datensätze der obersten Ebene fest, die zurückgegeben werden, wenn die Paginierung aktiviert ist, aber keine explizite Seitengröße bereitgestellt wird.
Zulässige Werte
| Wert | Ergebnis |
|---|---|
-1 |
Standardmäßig wird die aktuelle max-page-size Einstellung festgelegt. |
integer |
Eine positive ganze Zahl kleiner als die aktuelle max-page-size. |
< -1 |
Nicht unterstützt. |
0 |
Nicht unterstützt. |
Cache (Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime |
cache |
Objekt | ❌ Nein | Nichts |
Aktiviert und konfiguriert die Zwischenspeicherung für die gesamte Laufzeit.
Format
{
"runtime": {
"cache": <object>
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
enabled |
❌ Nein | boolesch | Nichts |
ttl-seconds |
❌ Nein | ganze Zahl | 5 |
Beispiele
In diesem Beispiel ist der Cache aktiviert und die Elemente laufen nach 30 Sekunden ab.
{
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 30
}
}
}
Aktiviert (Cachelaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.cache |
enabled |
boolesch | ❌ Nein | FALSCH |
Ermöglicht die globale Zwischenspeicherung für alle Entitäten. Der Standardwert lautet false.
Format
{
"runtime": {
"cache": {
"enabled": <boolean>
}
}
}
Beispiele
In diesem Beispiel ist der Cache deaktiviert.
{
"runtime": {
"cache": {
"enabled": false
}
}
}
TTL in Sekunden (Cachelaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.cache |
ttl-seconds |
ganze Zahl | ❌ Nein | 5 |
Konfiguriert den TTL-Wert (Time-to-Live) in Sekunden für zwischengespeicherte Elemente. Nach Ablauf dieser Zeit werden Elemente automatisch aus dem Cache gelöscht. Der Standardwert ist 5 Sekunden.
Format
{
"runtime": {
"cache": {
"ttl-seconds": <integer>
}
}
}
Beispiele
In diesem Beispiel ist der Cache global aktiviert und alle Elemente laufen nach 15 Sekunden ab.
{
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 15
}
}
}
Telemetrie (Laufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime |
telemetry |
Objekt | ❌ Nein | Nichts |
Diese Eigenschaft konfiguriert Application Insights, um API-Protokolle zu zentralisieren. Erfahren Sie mehr .
Format
{
"runtime": {
"telemetry": {
"application-insights": {
"enabled": <true; default: true> | <false>,
"connection-string": <string>
}
}
}
}
Application Insights (Telemetrielaufzeit)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.telemetry |
application-insights |
Objekt | ✔️ Ja | Nichts |
Aktiviert (Application Insights-Telemetrie)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.telemetry.application-insights |
enabled |
boolesch | ❌ Nein | STIMMT |
Verbindungszeichenfolge (Application Insights-Telemetrie)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
runtime.telemetry.application-insights |
connection-string |
Schnur | ✔️ Ja | Nichts |
Entitäten
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
$root |
entities |
Objekt | ✔️ Ja | Nichts |
Der entities Abschnitt dient als Kern der Konfigurationsdatei, wobei eine Brücke zwischen Datenbankobjekten und den entsprechenden API-Endpunkten eingerichtet wird. In diesem Abschnitt werden Datenbankobjekte den verfügbar gemachten Endpunkten zugeordnet. Dieser Abschnitt enthält auch eigenschaftenzuordnung und Berechtigungsdefinition. Jede verfügbar gemachte Entität wird in einem dedizierten Objekt definiert. Der Eigenschaftsname des Objekts wird als Name der Entität verwendet, die verfügbar gemacht werden soll.
In diesem Abschnitt wird definiert, wie jede Entität in der Datenbank in der API dargestellt wird, einschließlich Eigenschaftenzuordnungen und Berechtigungen. Jede Entität wird innerhalb ihres eigenen Unterabschnitts gekapselt, wobei der Name der Entität als Schlüssel für den Verweis in der gesamten Konfiguration fungiert.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true; default: true> | <false>,
"path": <string; default: "<entity-name>">,
"methods": <array of strings; default: ["GET", "POST"]>
},
"graphql": {
"enabled": <true; default: true> | <false>,
"type": {
"singular": <string>,
"plural": <string>
},
"operation": <"query" | "mutation"; default: "query">
},
"source": {
"object": <string>,
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>,
"parameters": {
"<parameter-name>": <string | number | boolean>
}
},
"mappings": {
"<database-field-name>": <string>
},
"relationships": {
"<relationship-name>": {
"cardinality": <"one" | "many">,
"target.entity": <string>,
"source.fields": <array of strings>,
"target.fields": <array of strings>,
"linking.object": <string>,
"linking.source.fields": <array of strings>,
"linking.target.fields": <array of strings>
}
},
"permissions": [
{
"role": <"anonymous" | "authenticated" | "custom-role-name">,
"actions": <array of strings>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": {
"database": <string>
}
}
]
}
}
}
Eigenschaften
| Erforderlich | Art | |
|---|---|---|
source |
✔️ Ja | Objekt |
permissions |
✔️ Ja | Anordnung |
rest |
❌ Nein | Objekt |
graphql |
❌ Nein | Objekt |
mappings |
❌ Nein | Objekt |
relationships |
❌ Nein | Objekt |
cache |
❌ Nein | Objekt |
Beispiele
Dieses JSON-Objekt weist beispielsweise den Daten-API-Generator an, eine GraphQL-Entität namens User und einen REST-Endpunkt verfügbar zu machen, der über den /User Pfad erreichbar ist. Die dbo.User Datenbanktabelle unterstützt die Entität und die Konfiguration ermöglicht es jedem, anonym auf den Endpunkt zuzugreifen.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
In diesem Beispiel wird die User Entität deklariert. Dieser Name User wird an einer beliebigen Stelle in der Konfigurationsdatei verwendet, auf die Entitäten verwiesen werden. Andernfalls ist der Entitätsname für die Endpunkte nicht relevant.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table",
"key-fields": ["Id"],
"parameters": {} // only when source.type = stored-procedure
},
"rest": {
"enabled": true,
"path": "/users",
"methods": [] // only when source.type = stored-procedure
},
"graphql": {
"enabled": true,
"type": {
"singular": "User",
"plural": "Users"
},
"operation": "query"
},
"mappings": {
"id": "Id",
"name": "Name",
"age": "Age",
"isAdmin": "IsAdmin"
},
"permissions": [
{
"role": "authenticated",
"actions": ["read"], // "execute" only when source.type = stored-procedure
"fields": {
"include": ["id", "name", "age", "isAdmin"],
"exclude": []
},
"policy": {
"database": "@claims.userId eq @item.id"
}
},
{
"role": "admin",
"actions": ["create", "read", "update", "delete"],
"fields": {
"include": ["*"],
"exclude": []
},
"policy": {
"database": "@claims.userRole eq 'UserAdmin'"
}
}
]
}
}
}
Quelle
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity} |
source |
Objekt | ✔️ Ja | Nichts |
Die {entity}.source Konfiguration verbindet die API-verfügbar gemachte Entität und das zugrunde liegende Datenbankobjekt. Diese Eigenschaft gibt die Datenbanktabelle, Ansicht oder gespeicherte Prozedur an, die die Entität darstellt, und stellt eine direkte Verknüpfung für den Datenabruf und die Bearbeitung her.
Für einfache Szenarien, in denen die Entität direkt einer einzelnen Datenbanktabelle zugeordnet ist, benötigt die Quelleigenschaft nur den Namen dieses Datenbankobjekts. Diese Einfachheit erleichtert die schnelle Einrichtung für häufige Anwendungsfälle: "source": "dbo.User".
Format
{
"entities": {
"<entity-name>": {
"source": {
"object": <string>,
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>,
"parameters": { // only when source.type = stored-procedure
"<name>": <string | number | boolean>
}
}
}
}
}
Eigenschaften
| Erforderlich | Art | |
|---|---|---|
object |
✔️ Ja | Schnur |
type |
✔️ Ja | Enumerationszeichenfolge |
parameters |
❌ Nein | Objekt |
key-fields |
❌ Nein | Zeichenfolgenarray |
Beispiele
1. Einfache Tabellenzuordnung:
In diesem Beispiel wird gezeigt, wie sie eine User Entität einer Quelltabelle dbo.Userszuordnen.
SQL-
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
Configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
2. Beispiel für gespeicherte Prozedur:
In diesem Beispiel wird gezeigt, wie sie eine User Entität einem Quellproc-dbo.GetUserszuordnen.
SQL-
CREATE PROCEDURE GetUsers
@IsAdmin BIT
AS
SELECT Id, Name, Age, IsAdmin
FROM dbo.Users
WHERE IsAdmin = @IsAdmin;
Configuration
{
"entities": {
"User": {
"source": {
"type": "stored-procedure",
"object": "GetUsers",
"parameters": {
"IsAdmin": "boolean"
}
},
"mappings": {
"Id": "id",
"Name": "name",
"Age": "age",
"IsAdmin": "isAdmin"
}
}
}
}
Die eigenschaft mappings ist für gespeicherte Prozeduren optional.
Objekt
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.source |
object |
Schnur | ✔️ Ja | Nichts |
Name des zu verwendenden Datenbankobjekts. Wenn das Objekt zum dbo Schema gehört, ist die Angabe des Schemas optional. Darüber hinaus können eckige Klammern um Objektnamen (z. B. [dbo].[Users] vs. dbo.Users) verwendet oder weggelassen werden.
Beispiele
SQL-
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
Configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
alternative Schreibweise ohne Schema und Klammern:
Wenn sich die Tabelle im dbo-Schema befindet, können Sie das Schema oder die Klammern weglassen:
{
"entities": {
"User": {
"source": {
"object": "Users",
"type": "table"
}
}
}
}
Typ (Entitäten)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.source |
type |
Schnur | ✔️ Ja | Nichts |
Die type-Eigenschaft identifiziert den Typ des Datenbankobjekts hinter der Entität, einschließlich view, tableund stored-procedure. Diese Eigenschaft ist erforderlich und hat keinen Standardwert.
Format
{
"entities": {
"<entity-name>": {
"type": <"view" | "stored-procedure" | "table">
}
}
}
Werte
| Wert | Beschreibung |
|---|---|
table |
Stellt eine Tabelle dar. |
stored-procedure |
Stellt eine gespeicherte Prozedur dar. |
view |
Stellt eine Ansicht dar. |
Beispiele
1. Tabellenbeispiel:
SQL-
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
Configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
2. Ansichtsbeispiel:
SQL-
CREATE VIEW dbo.AdminUsers AS
SELECT Id, Name, Age
FROM dbo.Users
WHERE IsAdmin = 1;
Configuration
{
"entities": {
"AdminUsers": {
"source": {
"object": "dbo.AdminUsers",
"type": "view",
"key-fields": ["Id"]
},
"mappings": {
"Id": "id",
"Name": "name",
"Age": "age"
}
}
}
}
Hinweis: Angeben von key-fields ist für Ansichten wichtig, da sie keine inhärenten Primärschlüssel aufweisen.
3. Beispiel für gespeicherte Prozedur:
SQL-
CREATE PROCEDURE dbo.GetUsers (@IsAdmin BIT)
AS
SELECT Id, Name, Age, IsAdmin
FROM dbo.Users
WHERE IsAdmin = @IsAdmin;
Configuration
{
"entities": {
"User": {
"source": {
"type": "stored-procedure",
"object": "GetUsers",
"parameters": {
"IsAdmin": "boolean"
}
}
}
}
}
Schlüsselfelder
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.source |
key-fields |
Zeichenfolgenarray | ❌ Nein | Nichts |
Die {entity}.key-fields-Eigenschaft ist besonders für Entitäten erforderlich, die von Ansichten unterstützt werden, sodass der Daten-API-Generator weiß, wie ein einzelnes Element identifiziert und zurückgegeben wird. Wenn type auf view festgelegt ist, ohne key-fieldsanzugeben, lehnt das Modul den Start ab. Diese Eigenschaft ist mit Tabellen und gespeicherten Prozeduren zulässig, wird jedoch in diesen Fällen nicht verwendet.
Wichtig
Diese Eigenschaft ist erforderlich, wenn der Objekttyp ein viewist.
Format
{
"entities": {
"<entity-name>": {
"source": {
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>
}
}
}
}
Beispiel: Ansicht mit Schlüsselfeldern
In diesem Beispiel wird die dbo.AdminUsers Ansicht mit Id verwendet, die als Schlüsselfeld angegeben ist.
SQL-
CREATE VIEW dbo.AdminUsers AS
SELECT Id, Name, Age
FROM dbo.Users
WHERE IsAdmin = 1;
Configuration
{
"entities": {
"AdminUsers": {
"source": {
"object": "dbo.AdminUsers",
"type": "view",
"key-fields": ["Id"]
}
}
}
}
Parameter
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.source |
parameters |
Objekt | ❌ Nein | Nichts |
Die parameters-Eigenschaft innerhalb entities.{entity}.source wird für Entitäten verwendet, die von gespeicherten Prozeduren unterstützt werden. Sie stellt eine ordnungsgemäße Zuordnung von Parameternamen und Datentypen sicher, die von der gespeicherten Prozedur benötigt werden.
Wichtig
Die parameters-Eigenschaft ist erforderlich, wenn die type des Objekts stored-procedure ist und der Parameter erforderlich ist.
Format
{
"entities": {
"<entity-name>": {
"source": {
"type": "stored-procedure",
"parameters": {
"<parameter-name-1>": <string | number | boolean>,
"<parameter-name-2>": <string | number | boolean>
}
}
}
}
}
Beispiel 1: Gespeicherte Prozedur ohne Parameter
SQL-
CREATE PROCEDURE dbo.GetUsers AS
SELECT Id, Name, Age, IsAdmin FROM dbo.Users;
Configuration
{
"entities": {
"Users": {
"source": {
"object": "dbo.GetUsers",
"type": "stored-procedure"
}
}
}
}
Beispiel 2: Gespeicherte Prozedur mit Parametern
SQL-
CREATE PROCEDURE dbo.GetUser (@userId INT) AS
SELECT Id, Name, Age, IsAdmin FROM dbo.Users
WHERE Id = @userId;
Configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
}
}
}
}
Erlaubnisse
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity} |
permissions |
Objekt | ✔️ Ja | Nichts |
In diesem Abschnitt wird definiert, wer auf die zugehörige Entität zugreifen kann und welche Aktionen zulässig sind. Berechtigungen werden in Bezug auf Rollen und CRUD-Vorgänge definiert: create, read, updateund delete. Im Abschnitt permissions wird angegeben, welche Rollen auf die zugehörige Entität zugreifen können und welche Aktionen verwendet werden.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"actions": ["create", "read", "update", "delete", "execute", "*"]
}
]
}
}
}
| Aktion | Beschreibung |
|---|---|
create |
Ermöglicht das Erstellen eines neuen Datensatzes in der Entität. |
read |
Ermöglicht das Lesen oder Abrufen von Datensätzen aus der Entität. |
update |
Ermöglicht das Aktualisieren vorhandener Datensätze in der Entität. |
delete |
Ermöglicht das Löschen von Datensätzen aus der Entität. |
execute |
Ermöglicht das Ausführen einer gespeicherten Prozedur oder eines gespeicherten Vorgangs. |
* |
Gewährt alle anwendbaren CRUD-Vorgänge. |
Beispiele
Beispiel 1: Anonyme Rolle für die Benutzerentität
In diesem Beispiel wird die anonymous Rolle mit Zugriff auf alle möglichen Aktionen für die entität User definiert.
{
"entities": {
"User": {
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
Beispiel 2: Gemischte Aktionen für anonyme Rollen
In diesem Beispiel wird gezeigt, wie Zeichenfolgen- und Objektarrayaktionen für die entität User kombiniert werden.
{
"entities": {
"User": {
"permissions": [
{
"role": "anonymous",
"actions": [
{ "action": "read" },
"create"
]
}
]
}
}
}
anonyme Rolle: Ermöglicht anonymen Benutzern das Lesen aller Felder mit Ausnahme eines hypothetischen vertraulichen Felds (z. B. secret-field). Die Verwendung von "include": ["*"] mit "exclude": ["secret-field"] blendet secret-field aus, während der Zugriff auf alle anderen Felder zulässig ist.
Authentifizierte Rolle: Ermöglicht authentifizierten Benutzern das Lesen und Aktualisieren bestimmter Felder. Beispielsweise können explizit id, nameund age, jedoch mit Ausnahme von isAdmin veranschaulichen, wie Ausschlüsse Einschlüsse außer Kraft setzen.
Administratorrolle: Administratoren können alle Vorgänge (*) für alle Felder ohne Ausschlüsse ausführen. Das Angeben von "include": ["*"] mit einem leeren "exclude": [] Array gewährt Zugriff auf alle Felder.
Diese Konfiguration:
"fields": {
"include": [],
"exclude": []
}
ist effektiv identisch mit:
"fields": {
"include": ["*"],
"exclude": []
}
Berücksichtigen Sie außerdem dieses Setup:
"fields": {
"include": [],
"exclude": ["*"]
}
Dadurch werden keine Felder explizit eingeschlossen, und alle Felder werden ausgeschlossen, wodurch der Zugriff in der Regel vollständig eingeschränkt wird.
praktische Verwendung: Eine solche Konfiguration kann kontraintuitiv erscheinen, da sie den Zugriff auf alle Felder einschränkt. Es kann jedoch in Szenarien verwendet werden, in denen eine Rolle bestimmte Aktionen ausführt (z. B. das Erstellen einer Entität), ohne auf ihre Daten zuzugreifen.
Dasselbe Verhalten, aber mit unterschiedlicher Syntax, wäre:
"fields": {
"include": ["Id", "Name"],
"exclude": ["*"]
}
Dieses Setup versucht, nur Id- und Name Felder einzuschließen, schließt jedoch alle Felder aufgrund des Wildcards in excludeaus.
Eine weitere Möglichkeit, dieselbe Logik auszudrücken, wäre:
"fields": {
"include": ["Id", "Name"],
"exclude": ["Id", "Name"]
}
Da exclude Vorrang vor includehat, bedeutet die Angabe exclude: ["*"], dass alle Felder ausgeschlossen werden, auch diejenigen in include. Daher könnte diese Konfiguration auf den ersten Blick verhindern, dass auf Felder zugegriffen werden kann.
Die umgekehrte: Wenn die Absicht besteht, nur zugriff auf Id- und Name-Felder zu gewähren, ist es klarer und zuverlässiger, nur diese Felder im abschnitt include anzugeben, ohne einen Ausschluss-Wildcard zu verwenden:
"fields": {
"include": ["Id", "Name"],
"exclude": []
}
Eigenschaften
| Erforderlich | Art | |
|---|---|---|
role |
✔️ Ja | Schnur |
actions (Zeichenfolgenarray)oder actions (Objektarray) |
✔️ Ja | Objekt- oder Zeichenfolgenarray |
Rolle
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.permissions |
role |
Schnur | ✔️ Ja | Nichts |
Zeichenfolge mit dem Namen der Rolle, für die die definierte Berechtigung gilt. Rollen legen den Berechtigungskontext fest, in dem eine Anforderung ausgeführt werden soll. Für jede Entität, die in der Laufzeitkonfiguration definiert ist, können Sie eine Reihe von Rollen und zugehörigen Berechtigungen definieren, die bestimmen, wie auf die Entität über REST- und GraphQL-Endpunkte zugegriffen werden kann. Rollen sind nicht additiv.
Der Daten-API-Generator wertet Anforderungen im Kontext einer einzelnen Rolle aus:
| Rolle | Beschreibung |
|---|---|
anonymous |
Es wird kein Zugriffstoken angezeigt. |
authenticated |
Ein gültiges Zugriffstoken wird angezeigt. |
<custom-role> |
Ein gültiges Zugriffstoken wird angezeigt, und der X-MS-API-ROLE HTTP-Header gibt eine Rolle an, die im Token vorhanden ist. |
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <"anonymous" | "authenticated" | "custom-role">,
"actions": ["create", "read", "update", "delete", "execute", "*"],
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
}
}
]
}
}
}
Beispiele
In diesem Beispiel wird eine Rolle namens reader mit nur read Berechtigungen für die entität User definiert.
{
"entities": {
"User": {
"permissions": [
{
"role": "reader",
"actions": ["read"]
}
]
}
}
}
Sie können <custom-role> verwenden, wenn ein gültiges Zugriffstoken angezeigt wird, und der X-MS-API-ROLE HTTP-Header enthalten ist, wobei eine Benutzerrolle angegeben wird, die auch im Rollenanspruch des Zugriffstokens enthalten ist. Nachfolgend finden Sie Beispiele für GET-Anforderungen an die User Entität, einschließlich des Autorisierungs bearertokens und des X-MS-API-ROLE Headers, auf der REST-Endpunktbasis /api bei localhost unter Verwendung verschiedener Sprachen.
GET https://localhost:5001/api/User
Authorization: Bearer <your_access_token>
X-MS-API-ROLE: custom-role
Aktionen (Zeichenfolgenarray)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.permissions |
actions |
oneOf [string, array] | ✔️ Ja | Nichts |
Ein Array von Zeichenfolgenwerten, die angeben, welche Vorgänge für die zugeordnete Rolle zulässig sind. Bei table und view Datenbankobjekten können Rollen eine beliebige Kombination aus create, read, updateoder delete Aktionen verwenden. Bei gespeicherten Prozeduren können Rollen nur die execute Aktion haben.
| Aktion | SQL-Vorgang |
|---|---|
* |
Wildcard, einschließlich Ausführung |
create |
Einfügen einer oder mehrerer Zeilen |
read |
Auswählen einer oder mehrerer Zeilen |
update |
Ändern einer oder mehrerer Zeilen |
delete |
Löschen einer oder mehrerer Zeilen |
execute |
Führt eine gespeicherte Prozedur aus. |
Anmerkung
Bei gespeicherten Prozeduren wird die Aktion "Wildcard(*) nur auf die execute Aktion erweitert. Für Tabellen und Ansichten wird sie auf create, read, updateund deleteerweitert.
Beispiele
In diesem Beispiel werden create und read Berechtigungen für eine Rolle namens contributor und delete Berechtigungen für eine Rolle namens auditor für die entität User erteilt.
{
"entities": {
"User": {
"permissions": [
{
"role": "auditor",
"actions": ["delete"]
},
{
"role": "contributor",
"actions": ["read", "create"]
}
]
}
}
}
Ein weiteres Beispiel:
{
"entities": {
"User": {
"permissions": [
{
"role": "contributor",
"actions": ["read", "create"]
}
]
}
}
}
Aktionen (Objektarray)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.permissions |
actions |
Zeichenfolgenarray | ✔️ Ja | Nichts |
Ein Array von Aktionsobjekten, die zulässige Vorgänge für die zugeordnete Rolle enthalten. Für table- und view-Objekte können Rollen eine beliebige Kombination aus create, read, updateoder deleteverwenden. Für gespeicherte Prozeduren ist nur execute zulässig.
Anmerkung
Bei gespeicherten Prozeduren wird die Wildcardaktion (*) nur auf executeerweitert. Bei Tabellen/Ansichten wird sie auf create, read, updateund deleteerweitert.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": <array of strings>,
"policy": <object>
}
]
}
]
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
action |
✔️ Ja | Schnur | Nichts |
fields |
❌ Nein | Zeichenfolgenarray | Nichts |
policy |
❌ Nein | Objekt | Nichts |
Beispiel
In diesem Beispiel wird nur read Berechtigung für die rolle auditor für die entität User gewährt, wobei Feld- und Richtlinieneinschränkungen gelten.
{
"entities": {
"User": {
"permissions": [
{
"role": "auditor",
"actions": [
{
"action": "read",
"fields": {
"include": ["*"],
"exclude": ["last_login"]
},
"policy": {
"database": "@item.IsAdmin eq false"
}
}
]
}
]
}
}
}
Aktion
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.permissions.actions[] |
action |
Schnur | ✔️ Ja | Nichts |
Gibt den für das Datenbankobjekt zulässigen spezifischen Vorgang an.
Werte
| Tabellen | Ansichten | Gespeicherte Prozeduren | Beschreibung | |
|---|---|---|---|---|
create |
✔️ Ja | ✔️ Ja | ❌ Nein | Neue Elemente erstellen |
read |
✔️ Ja | ✔️ Ja | ❌ Nein | Vorhandene Elemente lesen |
update |
✔️ Ja | ✔️ Ja | ❌ Nein | Aktualisieren oder Ersetzen von Elementen |
delete |
✔️ Ja | ✔️ Ja | ❌ Nein | Elemente löschen |
execute |
❌ Nein | ❌ Nein | ✔️ Ja | Ausführen von programmgesteuerten Vorgängen |
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": "<role>",
"actions": [
{
"action": "<string>",
"fields": {
"include": [/* fields */],
"exclude": [/* fields */]
},
"policy": {
"database": "<predicate>"
}
}
]
}
]
}
}
}
Beispiel
Hier ist ein Beispiel, in dem anonymous Benutzer eine gespeicherte Prozedur execute und aus der User Tabelle read können.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read"
}
]
}
]
},
"GetUser": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "execute"
}
]
}
]
}
}
}
Felder
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.permissions.actions[] |
fields |
Objekt | ❌ Nein | Nichts |
Granulare Spezifikationen, auf welche spezifischen Felder zugriff auf das Datenbankobjekt zulässig sind. Die Rollenkonfiguration ist ein Objekttyp mit zwei internen Eigenschaften, include und exclude. Diese Werte unterstützen die granulare Definition der Datenbankspalten (Felder) im Abschnitt fields.
Format
{
"entities": {
<string>: {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": <object>
}
]
}
]
}
}
}
Beispiele
In diesem Beispiel darf die rolle anonymous aus allen Feldern mit Ausnahme von idlesen, aber beim Erstellen eines Elements alle Felder verwenden.
{
"entities": {
"Author": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"fields": {
"include": [ "*" ],
"exclude": [ "id" ]
}
},
{ "action": "create" }
]
}
]
}
}
}
Schließen Sie die Zusammenarbeit ein und schließen Sie sie aus. Der im Abschnitt * Abschnitt include wildcard include gibt alle Felder an. Die im Abschnitt exclude aufgeführten Felder haben Vorrang vor Feldern, die im Abschnitt include angegeben sind. Die Definition wird in alle Felder mit Ausnahme des Felds "last_updated" enthalten
"Book": {
"source": "books",
"permissions": [
{
"role": "anonymous",
"actions": [ "read" ],
// Include All Except Specific Fields
"fields": {
"include": [ "*" ],
"exclude": [ "secret-field" ]
}
},
{
"role": "authenticated",
"actions": [ "read", "update" ],
// Explicit Include and Exclude
"fields": {
"include": [ "id", "title", "secret-field" ],
"exclude": [ "secret-field" ]
}
},
{
"role": "author",
"actions": [ "*" ],
// Include All With No Exclusions (default)
"fields": {
"include": ["*"],
"exclude": []
}
}
]
}
Politik
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.permissions.actions[] |
policy |
Objekt | ❌ Nein | Nichts |
Der policy Abschnitt, der pro actiondefiniert ist, definiert Sicherheitsregeln auf Elementebene (Datenbankrichtlinien), die die von einer Anforderung zurückgegebenen Ergebnisse einschränken. Der Unterabschnitt database zeigt den Datenbankrichtlinienausdruck an, der während der Anforderungsausführung ausgewertet wird.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": <object>,
"policy": {
"database": <string>
}
}
]
}
]
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
database |
✔️ Ja | Schnur | Nichts |
Beschreibung
Die database-Richtlinie: ein OData-artiger Ausdruck, der in ein Abfrage-Prädikat der Datenbank übersetzt wird, einschließlich Operatoren wie eq, ltund gt. Damit Ergebnisse für eine Anforderung zurückgegeben werden können, muss das Abfragedrädikat der Anforderung, das aus einer Datenbankrichtlinie aufgelöst wurde, bei der Ausführung für die Datenbank auf true ausgewertet werden.
| Beispielelementrichtlinie | Prädikat |
|---|---|
@item.OwnerId eq 2000 |
WHERE Table.OwnerId = 2000 |
@item.OwnerId gt 2000 |
WHERE Table.OwnerId > 2000 |
@item.OwnerId lt 2000 |
WHERE Table.OwnerId < 2000 |
Ein
predicateist ein Ausdruck, der als WAHR oder FALSCH ausgewertet wird. Prädikate werden in der Suchbedingung WHERE Klauseln und HAVING Klauseln, die Verknüpfungsbedingungen FROM Klauseln und andere Konstrukte verwendet, bei denen ein boolescher Wert erforderlich ist. (Microsoft Learn-Dokumentation)
Datenbankrichtlinie
Zwei Arten von Direktiven können zum Verwalten von Datenbankrichtlinien beim Erstellen eines Datenbankrichtlinienausdrucks verwendet werden:
| Richtlinie | Beschreibung |
|---|---|
@claims |
Zugreifen auf einen Anspruch innerhalb des in der Anforderung bereitgestellten überprüften Zugriffstokens |
@item |
Stellt ein Feld der Entität dar, für die die Datenbankrichtlinie definiert ist. |
Anmerkung
Wenn Azure Static Web Apps Authentication (EasyAuth) konfiguriert ist, stehen eine begrenzte Anzahl von Anspruchstypen zur Verwendung in Datenbankrichtlinien zur Verfügung: identityProvider, userId, userDetailsund userRoles. Weitere Informationen finden Sie in der Dokumentation Clientprinzipaldaten von Azure Static Web App Dokumentation.
Hier sind einige Beispieldatenbankrichtlinien:
@claims.userId eq @item.OwnerId@claims.userId gt @item.OwnerId@claims.userId lt @item.OwnerId
Der Daten-API-Generator vergleicht den Wert des UserId Anspruchs mit dem Wert des Datenbankfelds OwnerId. Die Ergebnisnutzlast enthält nur Datensätze, die sowohl die Anforderungsmetadaten als auch den Datenbankrichtlinienausdruck erfüllen.
Begrenzungen
Datenbankrichtlinien werden für Tabellen und Ansichten unterstützt. Gespeicherte Prozeduren können nicht mit Richtlinien konfiguriert werden.
Datenbankrichtlinien verhindern nicht, dass Anforderungen innerhalb der Datenbank ausgeführt werden. Dieses Verhalten liegt daran, dass sie in den generierten Abfragen, die an das Datenbankmodul übergeben werden, als Prädikate aufgelöst werden.
Datenbankrichtlinien werden nur für die actionserstellen, lese-, Update-und löschenunterstützt. Da es in einem Aufruf einer gespeicherten Prozedur kein Prädikat gibt, können sie nicht angefügt werden.
Unterstützte OData-ähnliche Operatoren
| Operator | Beschreibung | Beispielsyntax |
|---|---|---|
and |
LogischeS UND | "@item.status eq 'active' and @item.age gt 18" |
or |
LogischeS ODER | "@item.region eq 'US' or @item.region eq 'EU'" |
eq |
Gleich | "@item.type eq 'employee'" |
gt |
Größer als | "@item.salary gt 50000" |
lt |
Weniger als | "@item.experience lt 5" |
Weitere Informationen finden Sie unter binäre Operatoren.
| Operator | Beschreibung | Beispielsyntax |
|---|---|---|
- |
Negate (numerisch) | "@item.balance lt -100" |
not |
Logisches Negate (NOT) | "not @item.status eq 'inactive'" |
Weitere Informationen finden Sie unter unäre Operatoren.
Einschränkungen für Entitätsfeldnamen
-
Regeln: Muss mit einem Buchstaben oder Unterstrich beginnen (
_), gefolgt von bis zu 127 Buchstaben, Unterstrichen (_) oder Ziffern (0-9). - Auswirkung: Felder, die nicht diesen Regeln entsprechen, können nicht direkt in Datenbankrichtlinien verwendet werden.
-
Lösungs-: Verwenden Sie den Abschnitt
mappings, um Aliase für Felder zu erstellen, die diese Benennungskonventionen nicht erfüllen; Zuordnungen stellen sicher, dass alle Felder in Richtlinienausdrücke eingeschlossen werden können.
Verwenden von mappings für nichtkonformierende Felder
Wenn ihre Entitätsfeldnamen nicht den OData-Syntaxregeln entsprechen oder Sie diese aus anderen Gründen einfach aliasen möchten, können Sie Aliase im Abschnitt mappings Ihrer Konfiguration definieren.
{
"entities": {
"<entity-name>": {
"mappings": {
"<field-1-name>": <string>,
"<field-2-name>": <string>,
"<field-3-name>": <string>
}
}
}
}
In diesem Beispiel ist field-1-name der ursprüngliche Datenbankfeldname, der nicht den OData-Benennungskonventionen entspricht. Durch das Erstellen einer Zuordnung zu field-1-name und field-1-alias kann dieses Feld ohne Probleme in Datenbankrichtlinienausdrücken referenziert werden. Dieser Ansatz hilft nicht nur bei der Einhaltung der OData-Benennungskonventionen, sondern verbessert auch die Klarheit und Barrierefreiheit Ihres Datenmodells sowohl in GraphQL- als auch RESTful-Endpunkten.
Beispiele
Erwägen Sie eine Entität namens Employee innerhalb einer Daten-API-Konfiguration, die sowohl Ansprüche als auch Elementdirektiven verwendet. Dadurch wird sichergestellt, dass der Datenzugriff sicher basierend auf Benutzerrollen und Entitätsbesitz verwaltet wird:
{
"entities": {
"Employee": {
"source": {
"object": "HRUNITS",
"type": "table",
"key-fields": ["employee NUM"],
"parameters": {}
},
"mappings": {
"employee NUM": "EmployeeId",
"employee Name": "EmployeeName",
"department COID": "DepartmentId"
},
"policy": {
"database": "@claims.role eq 'HR' or @claims.userId eq @item.EmployeeId"
}
}
}
}
Entitätsdefinition: Die Employee Entität ist für REST- und GraphQL-Schnittstellen konfiguriert, die angibt, dass ihre Daten über diese Endpunkte abgefragt oder bearbeitet werden können.
Quellkonfiguration: Identifiziert die HRUNITS in der Datenbank, wobei employee NUM als Schlüsselfeld verwendet wird.
Zuordnungen: Aliase werden verwendet, um employee NUM, employee Nameund department COIDEmployeeId, EmployeeNamebzw. DepartmentId, die Feldnamen zu vereinfachen und möglicherweise vertrauliche Datenbankschemadetails zu verschleiern.
Richtlinienanwendung: Der Abschnitt policy wendet eine Datenbankrichtlinie mithilfe eines OData-ähnlichen Ausdrucks an. Diese Richtlinie schränkt den Datenzugriff auf Benutzer mit der Hr-Rolle (@claims.role eq 'HR') oder auf Benutzer ein, deren UserId Anspruch mit EmployeeId übereinstimmt – dem Feldalias – in der Datenbank (@claims.userId eq @item.EmployeeId). Sie stellt sicher, dass Mitarbeiter nur auf ihre eigenen Datensätze zugreifen können, es sei denn, sie gehören zur Personalabteilung. Richtlinien können die Sicherheit auf Zeilenebene basierend auf dynamischen Bedingungen erzwingen.
Datenbank
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.permissions.actions.policy |
database |
Objekt | ✔️ Ja | Nichts |
Der policy Abschnitt, der pro actiondefiniert ist, definiert Sicherheitsregeln auf Elementebene (Datenbankrichtlinien), die die von einer Anforderung zurückgegebenen Ergebnisse einschränken. Der Unterabschnitt database zeigt den Datenbankrichtlinienausdruck an, der während der Anforderungsausführung ausgewertet wird.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": {
"database": <string>
}
}
]
}
]
}
}
}
Diese Eigenschaft zeigt den Datenbankrichtlinienausdruck an, der während der Anforderungsausführung ausgewertet wird. Die Richtlinienzeichenfolge ist ein OData-Ausdruck, der in eine Abfrage übersetzt wird, die von der Datenbank ausgewertet wird. Beispielsweise wird der Richtlinienausdruck @item.OwnerId eq 2000 in das Abfrage-Prädikat WHERE <schema>.<object-name>.OwnerId = 2000übersetzt.
Anmerkung
Ein Prädikat ist ein Ausdruck, der auf TRUE, FALSEoder UNKNOWNausgewertet wird. Prädikate werden in:
- Die Suchbedingung von
WHEREKlauseln - Die Suchbedingung von
FROMKlauseln - Die Verknüpfungsbedingungen von
FROM-Klauseln - Andere Konstrukte, bei denen ein boolescher Wert erforderlich ist.
Weitere Informationen finden Sie unter Prädikate.
Damit Ergebnisse für eine Anforderung zurückgegeben werden können, muss das Abfragedrädikat der Anforderung, das aus einer Datenbankrichtlinie aufgelöst wurde, bei der Ausführung für die Datenbank auf true ausgewertet werden.
Zwei Arten von Direktiven können verwendet werden, um die Datenbankrichtlinie beim Erstellen eines Datenbankrichtlinienausdrucks zu verwalten:
| Beschreibung | |
|---|---|
@claims |
Greift auf einen Anspruch innerhalb des überprüften Zugriffstokens zu, das in der Anforderung bereitgestellt wird |
@item |
Stellt ein Feld der Entität dar, für die die Datenbankrichtlinie definiert ist. |
Anmerkung
Eine begrenzte Anzahl von Anspruchstypen ist für die Verwendung in Datenbankrichtlinien verfügbar, wenn die Azure Static Web Apps-Authentifizierung (EasyAuth) konfiguriert ist. Zu diesen Anspruchstypen gehören: identityProvider, userId, userDetailsund userRoles. Weitere Informationen finden Sie unter Azure Static Web Apps-Clientprinzipaldaten.
Beispiele
Beispielsweise kann ein grundlegender Richtlinienausdruck auswerten, ob ein bestimmtes Feld innerhalb der Tabelle wahr ist. In diesem Beispiel wird ausgewertet, ob das feld soft_deletefalseist.
{
"entities": {
"Manuscripts": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"policy": {
"database": "@item.soft_delete eq false"
}
}
]
}
]
}
}
}
Prädikate können auch claims- und item Direktiventypen auswerten. In diesem Beispiel wird das feld UserId aus dem Zugriffstoken abgerufen und mit dem feld owner_id in der Zieldatenbanktabelle verglichen.
{
"entities": {
"Manuscript": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"policy": {
"database": "@claims.userId eq @item.owner_id"
}
}
]
}
]
}
}
}
Begrenzungen
- Datenbankrichtlinien werden für Tabellen und Ansichten unterstützt. Gespeicherte Prozeduren können nicht mit Richtlinien konfiguriert werden.
- Datenbankrichtlinien können nicht verwendet werden, um zu verhindern, dass eine Anforderung innerhalb einer Datenbank ausgeführt wird. Diese Einschränkung liegt daran, dass Datenbankrichtlinien als Abfrage-Prädikate in den generierten Datenbankabfragen aufgelöst werden. Das Datenbankmodul wertet diese Abfragen letztendlich aus.
- Datenbankrichtlinien werden nur für die
actionscreate,read,updateunddeleteunterstützt. - Die OData-Ausdruckssyntax der Datenbankrichtlinie unterstützt nur diese Szenarien.
- Binäre Operatoren, einschließlich, aber nicht beschränkt auf;
and,or,eq,gtundlt. Weitere Informationen finden Sie unterBinaryOperatorKind. - Unäre Operatoren wie die
-(negate) undnotOperatoren. Weitere Informationen finden Sie unterUnaryOperatorKind.
- Binäre Operatoren, einschließlich, aber nicht beschränkt auf;
- Datenbankrichtlinien haben auch Einschränkungen im Zusammenhang mit Feldnamen.
- Entitätsfeldnamen, die mit einem Buchstaben oder Unterstrich beginnen, gefolgt von höchstens 127 Buchstaben, Unterstrichen oder Ziffern.
- Diese Anforderung ist pro OData-Spezifikation. Weitere Informationen finden Sie unter OData Common Schema Definition Language.
Trinkgeld
Felder, die den genannten Einschränkungen nicht entsprechen, können in Datenbankrichtlinien nicht referenziert werden. Konfigurieren Sie als Problemumgehung die Entität mit einem Zuordnungsabschnitt, um den Feldern übereinstimmende Aliase zuzuweisen.
GraphQL (Entitäten)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity} |
graphql |
Objekt | ❌ Nein | Nichts |
Dieses Objekt definiert, ob GraphQL aktiviert ist und der Name[s] verwendet wird, um die Entität als GraphQL-Typ verfügbar zu machen. Dieses Objekt ist optional und wird nur verwendet, wenn der Standardname oder die Standardeinstellungen nicht ausreichen.
Dieses Segment bietet die Integration einer Entität in das GraphQL-Schema. Es ermöglicht Entwicklern, Standardwerte für die Entität in GraphQL anzugeben oder zu ändern. Durch diese Einrichtung wird sichergestellt, dass das Schema die beabsichtigten Struktur- und Benennungskonventionen genau widerspiegelt.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <true> (default) | <false>,
"type": {
"singular": <string>,
"plural": <string>
},
"operation": "query" (default) | "mutation"
}
}
}
}
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <boolean>,
"type": <string-or-object>,
"operation": "query" (default) | "mutation"
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
enabled |
❌ Nein | boolesch | Nichts |
type |
❌ Nein | Zeichenfolge oder Objekt | Nichts |
operation |
❌ Nein | Enumerationszeichenfolge | Nichts |
Beispiele
Diese beiden Beispiele sind funktional gleichwertig.
{
"entities": {
"Author": {
"graphql": true
}
}
}
{
"entities": {
"Author": {
"graphql": {
"enabled": true
}
}
}
}
In diesem Beispiel ist die definierte Entität Book, die angibt, dass wir mit einer Reihe von Daten im Zusammenhang mit Büchern in der Datenbank arbeiten. Die Konfiguration für die Book Entität im GraphQL-Segment bietet eine klare Struktur darüber, wie sie in einem GraphQL-Schema dargestellt und interagiert werden soll.
Enabled-Eigenschaft: Die entität Book wird über GraphQL ("enabled": true) verfügbar gemacht, was bedeutet, dass Entwickler und Benutzer Buchdaten über GraphQL-Vorgänge abfragen oder stummschalten können.
Type-Eigenschaft: Die Entität wird mit dem Singularnamen "Book" und dem Pluralnamen "Books" im GraphQL-Schema dargestellt. Diese Unterscheidung stellt sicher, dass das Schema beim Abfragen eines einzelnen Buchs oder mehrerer Bücher intuitiv benannte Typen (Book für einen einzelnen Eintrag, Books für eine Liste) bietet, um die Benutzerfreundlichkeit der API zu verbessern.
Operation-Eigenschaft: Der Vorgang ist auf "query"festgelegt, was angibt, dass die primäre Interaktion mit der Book Entität über GraphQL das Abfragen (Abrufen) von Daten anstelle der Stummschaltung (Erstellen, Aktualisieren oder Löschen) von Daten ist. Dieses Setup richtet sich an typische Verwendungsmuster, bei denen Buchdaten häufiger gelesen werden als geändert.
{
"entities": {
"Book": {
...
"graphql": {
"enabled": true,
"type": {
"singular": "Book",
"plural": "Books"
},
"operation": "query"
},
...
}
}
}
Typ (GraphQL-Entität)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.graphql |
type |
oneOf [string, object] | ❌ Nein | {entity-name} |
Diese Eigenschaft bestimmt die Benennungskonvention für eine Entität im GraphQL-Schema. Sie unterstützt sowohl skalare Zeichenfolgenwerte als auch Objekttypen. Der Objektwert gibt die Singular- und Pluralformen an. Diese Eigenschaft bietet eine präzise Kontrolle über die Lesbarkeit und Benutzererfahrung des Schemas.
Format
{
"entities": {
<entity-name>: {
"graphql": {
"type": <string>
}
}
}
}
{
"entities": {
<entity-name>: {
"graphql": {
"type": {
"singular": <string>,
"plural": <string>
}
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
singular |
❌ Nein | Schnur | Nichts |
plural |
❌ Nein | Schnur | N/A (Standard: Singular) |
Beispiele
Um noch mehr Kontrolle über den GraphQL-Typ zu erhalten, können Sie konfigurieren, wie der Singular- und Pluralname unabhängig voneinander dargestellt wird.
Wenn plural fehlt oder ausgelassen wird (z. B. skalarer Wert), versucht der Daten-API-Generator, den Namen automatisch zu pluralisieren, nach den englischen Regeln für die Pluralisierung (z. B. https://engdic.org/singular-and-plural-noun-rules-definitions-examples)
{
"entities" {
"<entity-name>": {
...
"graphql": {
...
"type": {
"singular": "User",
"plural": "Users"
}
}
}
}
}
Ein benutzerdefinierter Entitätsname kann mithilfe des type-Parameters mit einem Zeichenfolgenwert angegeben werden. In diesem Beispiel unterscheidet das Modul automatisch zwischen der Singular und den Pluralvarianten dieses Namens mithilfe gängiger englischer Regeln für die Pluralisierung.
{
"entities": {
"Author": {
"graphql": {
"type": "bookauthor"
}
}
}
}
Wenn Sie die Namen explizit angeben möchten, verwenden Sie die Eigenschaften type.singular und type.plural. In diesem Beispiel werden beide Namen explizit festgelegt.
{
"entities": {
"Author": {
"graphql": {
"type": {
"singular": "bookauthor",
"plural": "bookauthors"
}
}
}
}
}
Beide Beispiele sind funktional gleichwertig. Beide geben dieselbe JSON-Ausgabe für eine GraphQL-Abfrage zurück, die den bookauthors Entitätsnamen verwendet.
{
bookauthors {
items {
first_name
last_name
}
}
}
{
"data": {
"bookauthors": {
"items": [
{
"first_name": "Henry",
"last_name": "Ross"
},
{
"first_name": "Jacob",
"last_name": "Hancock"
},
...
]
}
}
}
Vorgang (GraphQL-Entität)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.graphql |
operation |
Enumerationszeichenfolge | ❌ Nein | Nichts |
Für Entitäten, die gespeicherten Prozeduren zugeordnet sind, bestimmt die operation-Eigenschaft den GraphQL-Vorgangstyp (Abfrage oder Mutation), auf den die gespeicherte Prozedur zugreifen kann. Diese Einstellung ermöglicht die logische Organisation des Schemas und die Einhaltung bewährter Methoden für GraphQL, ohne dass sich dies auf die Funktionalität auswirkt.
Anmerkung
Eine Entität wird als gespeicherte Prozedur angegeben, indem sie den wert der eigenschaft {entity}.type auf stored-procedurefestlegen. Bei einer gespeicherten Prozedur wird automatisch ein neuer GraphQL-Typ executeXXX erstellt. Mit der operation-Eigenschaft kann der Entwickler jedoch den Speicherort dieses Typs entweder in die mutation oder query Teile des Schemas umwandeln. Diese Eigenschaft ermöglicht die Schemahygene und es gibt keine funktionalen Auswirkungen, unabhängig von operation Wert.
Fehlt die standardeinstellung operation ist mutation.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"operation": "query" (default) | "mutation"
}
}
}
}
Werte
Hier ist eine Liste der zulässigen Werte für diese Eigenschaft:
| Beschreibung | |
|---|---|
query |
Die zugrunde liegende gespeicherte Prozedur wird als Abfrage verfügbar gemacht. |
mutation |
Die zugrunde liegende gespeicherte Prozedur wird als Mutation ausgesetzt. |
Beispiele
Wenn operationmutationist, würde das GraphQL-Schema wie folgt aussehen:
type Mutation {
executeGetCowrittenBooksByAuthor(
searchType: String = "S"
): [GetCowrittenBooksByAuthor!]!
}
Wenn operationqueryist, würde das GraphQL-Schema wie folgt aussehen:
Das GraphQL-Schema würde etwa wie folgt aussehen:
type Query {
executeGetCowrittenBooksByAuthor(
searchType: String = "S"
): [GetCowrittenBooksByAuthor!]!
}
Anmerkung
Die operation-Eigenschaft geht es nur um die Platzierung des Vorgangs im GraphQL-Schema, es ändert nicht das Verhalten des Vorgangs.
Aktiviert (GraphQL-Entität)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.graphql |
enabled |
boolesch | ❌ Nein | STIMMT |
Aktiviert oder deaktiviert den GraphQL-Endpunkt. Steuert, ob eine Entität über GraphQL-Endpunkte verfügbar ist. Durch das Umschalten der enabled-Eigenschaft können Entwickler Entitäten aus dem GraphQL-Schema selektiv verfügbar machen.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <true> (default) | <false>
}
}
}
}
REST (Entitäten)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity} |
rest |
Objekt | ❌ Nein | Nichts |
Der rest Abschnitt der Konfigurationsdatei ist für die Feinabstimmung der RESTful-Endpunkte für jede Datenbankentität vorgesehen. Diese Anpassungsfunktion stellt sicher, dass die verfügbar gemachte REST-API bestimmte Anforderungen erfüllt und sowohl die Hilfs- als auch die Integrationsfunktionen verbessert. Es behebt potenzielle Konflikte zwischen den standardmäßigen abgeleiteten Einstellungen und dem gewünschten Endpunktverhalten.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true> (default) | <false>,
"path": <string; default: "<entity-name>">,
"methods": <array of strings; default: ["GET", "POST"]>
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
enabled |
✔️ Ja | boolesch | STIMMT |
path |
❌ Nein | Schnur | /<entity-name> |
methods |
❌ Nein | Zeichenfolgenarray | ERHALTEN |
Beispiele
Diese beiden Beispiele sind funktional gleichwertig.
{
"entities": {
"Author": {
"source": {
"object": "dbo.authors",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
],
"rest": true
}
}
}
{
"entities": {
"Author": {
...
"rest": {
"enabled": true
}
}
}
}
Hier ist ein weiteres Beispiel für eine REST-Konfiguration für eine Entität.
{
"entities" {
"User": {
"rest": {
"enabled": true,
"path": "/User"
},
...
}
}
}
Aktiviert (REST-Entität)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.rest |
enabled |
boolesch | ❌ Nein | STIMMT |
Diese Eigenschaft dient als Umschaltfläche für die Sichtbarkeit von Entitäten innerhalb der REST-API. Durch Festlegen der enabled-Eigenschaft auf true oder falsekönnen Entwickler den Zugriff auf bestimmte Entitäten steuern, wodurch eine maßgeschneiderte API-Oberfläche aktiviert wird, die den Anforderungen an die Anwendungssicherheit und -funktionalität entspricht.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true> (default) | <false>
}
}
}
}
Pfad (REST-Entität)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.rest |
path |
Schnur | ❌ Nein | Nichts |
Die path-Eigenschaft gibt das URI-Segment an, das für den Zugriff auf eine Entität über die REST-API verwendet wird. Diese Anpassung ermöglicht aussagekräftigere oder vereinfachte Endpunktpfade, die über den Standardentitätsnamen hinausgehen, die API-Navigierbarkeit und die clientseitige Integration verbessern. Standardmäßig ist der Pfad /<entity-name>.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"path": <string; default: "<entity-name>">
}
}
}
}
Beispiele
In diesem Beispiel wird die Author Entität mithilfe des /auth Endpunkts verfügbar gemacht.
{
"entities": {
"Author": {
"rest": {
"path": "/auth"
}
}
}
}
Methoden (REST-Entität)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.rest |
methods |
Zeichenfolgenarray | ❌ Nein | Nichts |
Die methods-Eigenschaft, die speziell für gespeicherte Prozeduren gilt, definiert, auf welche HTTP-Verben (z. B. GET, POST) die Prozedur reagieren kann. Methoden ermöglichen eine präzise Kontrolle darüber, wie gespeicherte Prozeduren über die REST-API verfügbar gemacht werden, um die Kompatibilität mit RESTful-Standards und Clienterwartungen sicherzustellen. In diesem Abschnitt wird das Engagement der Plattform für Flexibilität und Entwicklersteuerung hervorgehoben, sodass präzises und intuitives API-Design auf die spezifischen Anforderungen jeder Anwendung zugeschnitten ist.
Wenn sie nicht angegeben oder fehlen, wird die methods Standardeinstellung POST.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"methods": ["GET" (default), "POST"]
}
}
}
}
Werte
Hier ist eine Liste der zulässigen Werte für diese Eigenschaft:
| Beschreibung | |
|---|---|
get |
Macht HTTP GET-Anforderungen verfügbar |
post |
Macht HTTP POST-Anforderungen verfügbar |
Beispiele
In diesem Beispiel wird das Modul angewiesen, dass die gespeicherte stp_get_bestselling_authors Prozedur nur HTTP GET Aktionen unterstützt.
{
"entities": {
"BestSellingAuthor": {
"source": {
"object": "dbo.stp_get_bestselling_authors",
"type": "stored-procedure",
"parameters": {
"depth": "number"
}
},
"rest": {
"path": "/best-selling-authors",
"methods": [ "get" ]
}
}
}
}
Zuordnungen (Entitäten)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity} |
mappings |
Objekt | ❌ Nein | Nichts |
Der mappings Abschnitt ermöglicht das Konfigurieren von Aliasen oder verfügbar gemachten Namen für Datenbankobjektfelder. Die konfigurierten offengelegten Namen gelten sowohl für die GraphQL- als auch für REST-Endpunkte.
Wichtig
Für Entitäten mit aktivierter GraphQL muss der konfigurierte Offengelegte Name den Benennungsanforderungen von GraphQL entsprechen. Weitere Informationen finden Sie unter Spezifikation von GraphQL-Namen.
Format
{
"entities": {
"<entity-name>": {
"mappings": {
"<field-1-name>": "<field-1-alias>",
"<field-2-name>": "<field-2-alias>",
"<field-3-name>": "<field-3-alias>"
}
}
}
}
Beispiele
In diesem Beispiel wird das feld sku_title aus dem Datenbankobjekt dbo.magazines mit dem Namen titleverfügbar gemacht. Ebenso wird das feld sku_status als status sowohl in REST- als auch in GraphQL-Endpunkten verfügbar gemacht.
{
"entities": {
"Magazine": {
...
"mappings": {
"sku_title": "title",
"sku_status": "status"
}
}
}
}
Hier sehen Sie ein weiteres Beispiel für Zuordnungen.
{
"entities": {
"Book": {
...
"mappings": {
"id": "BookID",
"title": "BookTitle",
"author": "AuthorName"
}
}
}
}
Zuordnungen: Das mappings-Objekt verknüpft die Datenbankfelder (BookID, BookTitle, AuthorName) mit intuitiveren oder standardisierten Namen (id, title, author), die extern verwendet werden. Dieser Alias dient mehreren Zwecken:
Klarheit und Konsistenz: Es ermöglicht die Verwendung klarer und konsistenter Benennungen in der GESAMTEN API, unabhängig vom zugrunde liegenden Datenbankschema. Beispielsweise wird
BookIDin der Datenbank alsidin der API dargestellt, sodass sie für Entwickler, die mit dem Endpunkt interagieren, intuitiver wird.GraphQL Compliance-: Durch die Bereitstellung eines Mechanismus für Aliasfeldnamen wird sichergestellt, dass die über die GraphQL-Schnittstelle verfügbar gemachten Namen den GraphQL-Benennungsanforderungen entsprechen. Die Aufmerksamkeit auf Namen ist wichtig, da GraphQL strenge Regeln zu Namen hat (z. B. keine Leerzeichen, muss mit einem Buchstaben oder Unterstrich beginnen usw.). Wenn beispielsweise ein Datenbankfeldname diese Kriterien nicht erfüllt, kann er über Zuordnungen zu einem kompatiblen Namen aliast werden.
Flexibilität: Mit diesem Aliasing wird eine Abstraktionsebene zwischen dem Datenbankschema und der API hinzugefügt, sodass Änderungen in einem hinzugefügt werden können, ohne dass Änderungen in der anderen erforderlich sind. Eine Änderung des Feldnamens in der Datenbank erfordert beispielsweise keine Aktualisierung der API-Dokumentation oder des clientseitigen Codes, wenn die Zuordnung konsistent bleibt.
Feldnamen-Obfuscation: Zuordnung ermöglicht die Verschleierung von Feldnamen, wodurch verhindert werden kann, dass nicht autorisierte Benutzer vertrauliche Informationen über das Datenbankschema oder die Art der gespeicherten Daten ableiten.
Schützen proprietärer Informationen: Durch das Umbenennen von Feldern können Sie auch proprietäre Namen oder Geschäftslogik schützen, die möglicherweise durch die ursprünglichen Feldnamen der Datenbank angedeutet werden.
Beziehungen (Entitäten)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity} |
relationships |
Objekt | ❌ Nein | Nichts |
Dieser Abschnitt enthält eine Reihe von Beziehungsdefinitionen, die zuordnen, wie Entitäten mit anderen verfügbar gemachten Entitäten zusammenhängen. Diese Beziehungsdefinitionen können optional auch Details zu den zugrunde liegenden Datenbankobjekten enthalten, die verwendet werden, um die Beziehungen zu unterstützen und zu erzwingen. In diesem Abschnitt definierte Objekte werden als GraphQL-Felder in der zugehörigen Entität verfügbar gemacht. Weitere Informationen finden Sie unter Aufschlüsselung von Daten-API-Generator-Beziehungen.
Anmerkung
Beziehungen sind nur für GraphQL-Abfragen relevant. REST-Endpunkte greifen jeweils nur auf eine Entität zu und können keine geschachtelten Typen zurückgeben.
Im abschnitt relationships wird beschrieben, wie Entitäten im Daten-API-Generator interagieren, wie Zuordnungen und potenzielle Datenbankunterstützung für diese Beziehungen beschrieben werden. Die relationship-name-Eigenschaft für jede Beziehung ist erforderlich und muss für alle Beziehungen für eine bestimmte Entität eindeutig sein. Benutzerdefinierte Namen stellen klare, identifizierbare Verbindungen sicher und verwalten die Integrität des GraphQL-Schemas, das aus diesen Konfigurationen generiert wird.
| Beziehung | Mächtigkeit | Beispiel |
|---|---|---|
| 1:n | many |
Eine Kategorieentität kann sich auf viele Todo-Entitäten beziehen. |
| n:1 | one |
Viele Todo-Entitäten können sich auf eine Kategorieentität beziehen. |
| n:n | many |
Eine Todo-Entität kann sich auf viele Benutzerentitäten beziehen, und eine Benutzerentität kann sich auf viele Todo-Entitäten beziehen. |
Format
{
"entities": {
"<entity-name>": {
"relationships": {
"<relationship-name>": {
"cardinality": "one" | "many",
"target.entity": "<string>",
"source.fields": ["<string>"],
"target.fields": ["<string>"],
"linking.object": "<string>",
"linking.source.fields": ["<string>"],
"linking.target.fields": ["<string>"]
}
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
cardinality |
✔️ Ja | Enumerationszeichenfolge | Nichts |
target.entity |
✔️ Ja | Schnur | Nichts |
source.fields |
❌ Nein | Zeichenfolgenarray | Nichts |
target.fields |
❌ Nein | Zeichenfolgenarray | Nichts |
linking.<object-or-entity> |
❌ Nein | Schnur | Nichts |
linking.source.fields |
❌ Nein | Zeichenfolgenarray | Nichts |
linking.target.fields |
❌ Nein | Zeichenfolgenarray | Nichts |
Beispiele
Beim Betrachten von Beziehungen ist es am besten, die Unterschiede zwischen 1:n-, m:1-und m:n- Beziehungen zu vergleichen.
1:n
Betrachten wir zunächst ein Beispiel für eine Beziehung mit der verfügbar gemachten Category Entität eine 1:n- Beziehung mit der Book Entität. Hier wird die Kardinalität auf manyfestgelegt. Jede Category kann mehrere verwandte Book Entitäten aufweisen, während jede Book Entität nur einer einzelnen Category Entität zugeordnet ist.
{
"entities": {
"Book": {
...
},
"Category": {
"relationships": {
"category_books": {
"cardinality": "many",
"target.entity": "Book",
"source.fields": [ "id" ],
"target.fields": [ "category_id" ]
}
}
}
}
}
In diesem Beispiel gibt die liste source.fields das id Feld der Quellentität (Category) an. Dieses Feld wird verwendet, um eine Verbindung mit dem zugehörigen Element in der entität target herzustellen. Umgekehrt gibt die target.fields-Liste das category_id Feld der Zielentität (Book) an. Dieses Feld wird verwendet, um eine Verbindung mit dem zugehörigen Element in der entität source herzustellen.
Mit dieser definierten Beziehung sollte das resultierende verfügbar gemachte GraphQL-Schema diesem Beispiel ähneln.
type Category
{
id: Int!
...
books: [BookConnection]!
}
n:1
Als Nächstes sollten Sie Book Entität kann eine einzelne verwandte Category Entität aufweisen. Die Category Entität kann mehrere verwandte Book Entitäten aufweisen.
{
"entities": {
"Book": {
"relationships": {
"books_category": {
"cardinality": "one",
"target.entity": "Category",
"source.fields": [ "category_id" ],
"target.fields": [ "id" ]
}
},
"Category": {
...
}
}
}
}
Hier gibt die liste source.fields an, dass das category_id Feld der Quellentität (Book) auf das id Feld der zugehörigen Zielentität (Category) verweist. Umgekehrt gibt die liste target.fields die umgekehrte Beziehung an. Mit dieser Beziehung enthält das resultierende GraphQL-Schema jetzt eine Zuordnung von Büchern zu Kategorien.
type Book
{
id: Int!
...
category: Category
}
n:n
Schließlich wird eine m: n-Beziehung mit einer Kardinalität von many und mehr Metadaten definiert, um zu definieren, welche Datenbankobjekte verwendet werden, um die Beziehung in der Sicherungsdatenbank zu erstellen. Hier kann die Book-Entität mehrere Author Entitäten aufweisen, und umgekehrt kann die Author Entität mehrere Book Entitäten aufweisen.
{
"entities": {
"Book": {
"relationships": {
...,
"books_authors": {
"cardinality": "many",
"target.entity": "Author",
"source.fields": [ "id" ],
"target.fields": [ "id" ],
"linking.object": "dbo.books_authors",
"linking.source.fields": [ "book_id" ],
"linking.target.fields": [ "author_id" ]
}
},
"Category": {
...
},
"Author": {
...
}
}
}
}
In diesem Beispiel geben die source.fields und target.fields beide an, dass die Beziehungstabelle den primären Bezeichner (id) der Quellentitäten (Book) und Zielentitäten (Author) verwendet. Das feld linking.object gibt an, dass die Beziehung im dbo.books_authors Datenbankobjekt definiert ist. Darüber hinaus gibt linking.source.fields an, dass das book_id Feld des verknüpfenden Objekts auf das id Feld der Book Entität verweist und linking.target.fields angibt, dass das author_id Feld des verknüpfenden Objekts auf das id Feld der Author Entität verweist.
Dieses Beispiel kann mithilfe eines GraphQL-Schemas wie in diesem Beispiel beschrieben werden.
type Book
{
id: Int!
...
authors: [AuthorConnection]!
}
type Author
{
id: Int!
...
books: [BookConnection]!
}
Mächtigkeit
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.relationships |
cardinality |
Schnur | ✔️ Ja | Nichts |
Gibt an, ob die aktuelle Quellentität nur mit einer einzelnen Instanz der Zielentität oder mehreren verknüpft ist.
Werte
Hier ist eine Liste der zulässigen Werte für diese Eigenschaft:
| Beschreibung | |
|---|---|
one |
Die Quelle bezieht sich nur auf einen Datensatz aus dem Ziel. |
many |
Die Quelle kann sich auf Null-zu-n-Datensätze aus dem Ziel beziehen. |
Zielentität
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.relationships |
target.entity |
Schnur | ✔️ Ja | Nichts |
Der Name der Entität, die an anderer Stelle in der Konfiguration definiert ist, die das Ziel der Beziehung ist.
Quellfelder
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.relationships |
source.fields |
Anordnung | ❌ Nein | Nichts |
Ein optionaler Parameter zum Definieren des Felds, das für die Zuordnung in der Quelle verwendet wird, Entität, die zum Herstellen einer Verbindung mit dem zugehörigen Element in der Zielentität verwendet wird.
Trinkgeld
Dieses Feld ist nicht erforderlich, wenn ein Fremdschlüssel Zurückhaltung der Datenbank zwischen den beiden Datenbankobjekten vorhanden ist, die verwendet werden können, um die Beziehung automatisch abzuleiten.
Zielfelder
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.relationships |
target.fields |
Anordnung | ❌ Nein | Nichts |
Ein optionaler Parameter zum Definieren des Felds, das für die Zuordnung im Ziel verwendet wird, Entität, die zum Herstellen einer Verbindung mit dem zugehörigen Element in der Quellentität verwendet wird.
Trinkgeld
Dieses Feld ist nicht erforderlich, wenn ein Fremdschlüssel Zurückhaltung der Datenbank zwischen den beiden Datenbankobjekten vorhanden ist, die verwendet werden können, um die Beziehung automatisch abzuleiten.
Verknüpfen eines Objekts oder einer Entität
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.object |
Schnur | ❌ Nein | Nichts |
Bei m:n-Beziehungen ist der Name des Datenbankobjekts oder der Entität, das die zum Definieren einer Beziehung zwischen zwei anderen Entitäten erforderlichen Daten enthält.
Verknüpfen von Quellfeldern
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.source.fields |
Anordnung | ❌ Nein | Nichts |
Der Name des Datenbankobjekts oder Entitätsfelds, das mit der Quellentität verknüpft ist.
Verknüpfen von Zielfeldern
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.target.fields |
Anordnung | ❌ Nein | Nichts |
Der Name des Datenbankobjekts oder Entitätsfelds, das mit der Zielentität verknüpft ist.
Cache (Entitäten)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.cache |
enabled |
boolesch | ❌ Nein | FALSCH |
Aktiviert und konfiguriert die Zwischenspeicherung für die Entität.
Format
You're right; the formatting doesn't match your style. Here’s the corrected version following your preferred documentation format:
```json
{
"entities": {
"<entity-name>": {
"cache": {
"enabled": <true> (default) | <false>,
"ttl-seconds": <integer; default: 5>
}
}
}
}
Eigenschaften
| Eigentum | Erforderlich | Art | Vorgabe |
|---|---|---|---|
enabled |
❌ Nein | boolesch | FALSCH |
ttl-seconds |
❌ Nein | ganze Zahl | 5 |
Beispiele
In diesem Beispiel ist der Cache aktiviert und die Elemente laufen nach 30 Sekunden ab.
{
"entities": {
"Author": {
"cache": {
"enabled": true,
"ttl-seconds": 30
}
}
}
}
Aktiviert (Cacheentität)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.{entity}.cache |
enabled |
boolesch | ❌ Nein | FALSCH |
Aktiviert das Zwischenspeichern für die Entität.
Unterstützung des Datenbankobjekts
| Objekttyp | Cacheunterstützung |
|---|---|
| Tisch | ✅ Ja |
| Ansehen | ✅ Ja |
| Gespeicherte Prozedur | ✖️ Nein |
| Container | ✖️ Nein |
HTTP-Headerunterstützung
| Anforderungsheader | Cacheunterstützung |
|---|---|
no-cache |
✖️ Nein |
no-store |
✖️ Nein |
max-age |
✖️ Nein |
public |
✖️ Nein |
private |
✖️ Nein |
etag |
✖️ Nein |
Format
{
"entities": {
"<entity-name>": {
"cache": {
"enabled": <boolean> (default: false)
}
}
}
}
Beispiele
In diesem Beispiel ist der Cache deaktiviert.
{
"entities": {
"Author": {
"cache": {
"enabled": false
}
}
}
}
TTL in Sekunden (Cacheentität)
| Elternteil | Eigentum | Art | Erforderlich | Vorgabe |
|---|---|---|---|---|
entities.cache |
ttl-seconds |
ganze Zahl | ❌ Nein | 5 |
Konfiguriert den TTL-Wert (Time-to-Live) in Sekunden für zwischengespeicherte Elemente. Nach Ablauf dieser Zeit werden Elemente automatisch aus dem Cache gelöscht. Der Standardwert ist 5 Sekunden.
Format
{
"entities": {
"<entity-name>": {
"cache": {
"ttl-seconds": <integer; inherited>
}
}
}
}
Beispiele
In diesem Beispiel ist der Cache aktiviert und die Elemente laufen nach 15 Sekunden ab. Wenn diese Einstellung weggelassen wird, erbt diese Einstellung die globale Einstellung oder den Standardwert.
{
"entities": {
"Author": {
"cache": {
"enabled": true,
"ttl-seconds": 15
}
}
}
}