Entwerfen einer mehrinstanzenfähigen Datenbank unter Verwendung von Azure Cosmos DB for PostgreSQL
GILT FÜR: ![]() Azure Cosmos DB for PostgreSQL (unterstützt von der Citus-Datenbankerweiterung auf PostgreSQL)
Azure Cosmos DB for PostgreSQL (unterstützt von der Citus-Datenbankerweiterung auf PostgreSQL)
In diesem Tutorial verwenden Sie Azure Cosmos DB for PostgreSQL, um Folgendes zu lernen:
- Erstellen eines Clusters
- Verwenden des psql-Hilfsprogramms zum Erstellen eines Schemas
- Knotenübergreifende Shard-Tabellen
- Erfassen von Beispieldaten
- Abfragen von Mandantendaten
- Teilen von Daten zwischen Mandanten
- Mandantenweises Anpassen des Schemas
Voraussetzungen
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Erstellen eines Clusters
Melden Sie sich beim Azure-Portal an, und führen Sie die folgenden Schritte aus, um einen Azure Cosmos DB for PostgreSQL-Cluster zu erstellen:
Rufen Sie im Azure-Portal Azure Cosmos DB for PostgreSQL-Cluster erstellen auf.

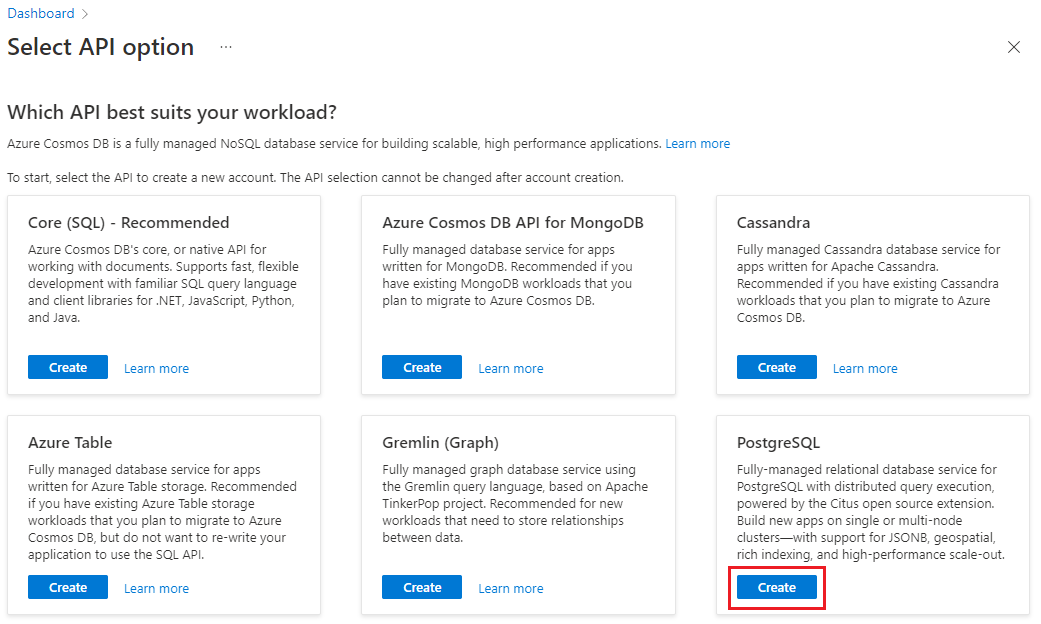
Gehen Sie im Formular Azure Cosmos DB for PostgreSQL-Cluster erstellen wie folgt vor:
Geben Sie die Informationen auf der Registerkarte Grundlagen ein.
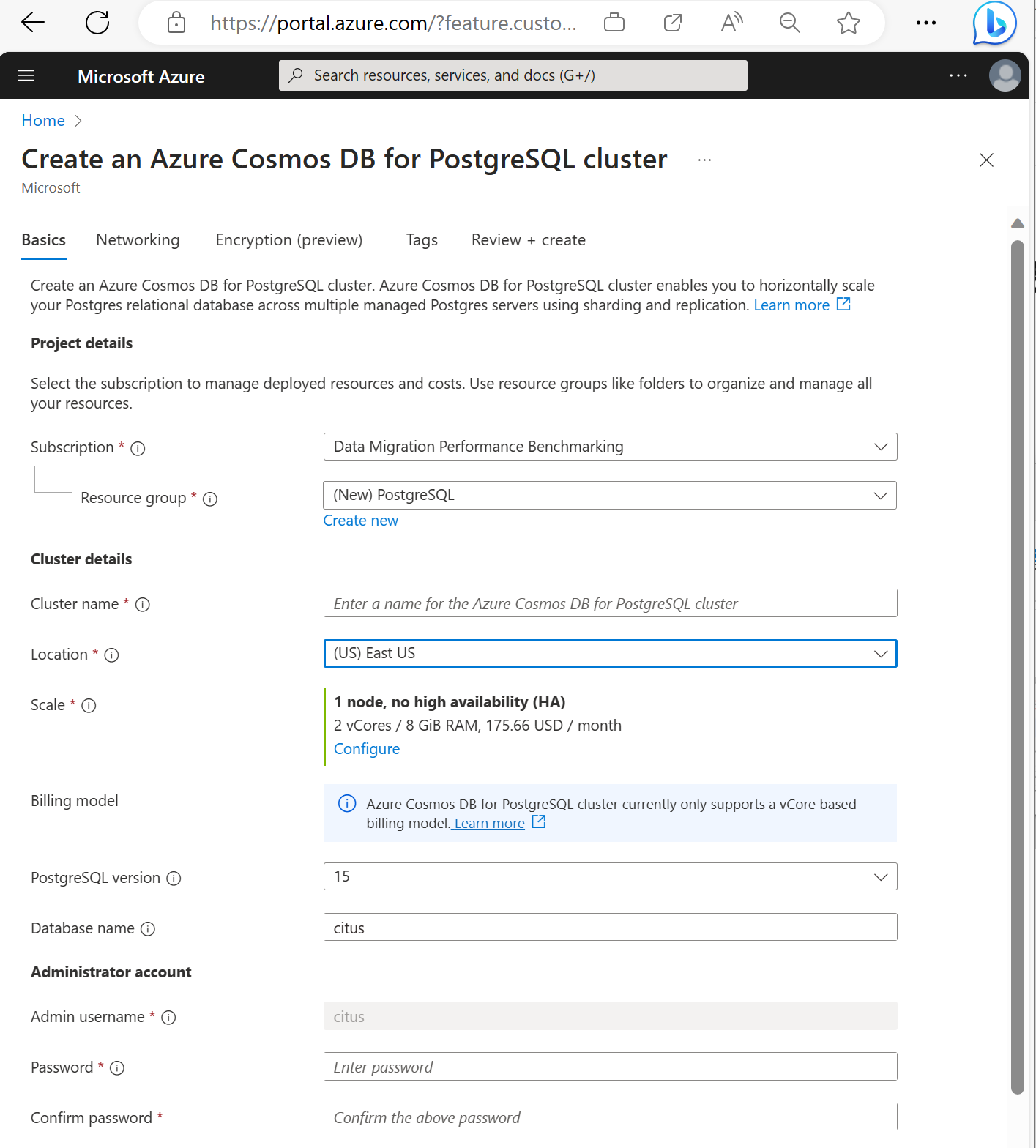
Die meisten Optionen sind selbsterklärend, denken Sie jedoch an Folgendes:
- Der Clustername bestimmt den DNS-Namen, den Ihre Anwendungen zum Herstellen einer Verbindung verwenden. Geben Sie den Namen im Format
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.coman. - Sie können eine höhere PostgreSQL-Version wie 15 auswählen. Azure Cosmos DB für PostgreSQL unterstützt immer die neueste Citus-Version für die ausgewählte Postgres-Hauptversion.
- Der Administratorbenutzername muss den Wert
citusaufweisen. - Sie können den Datenbanknamen auf dem Standardwert „citus“ belassen oder einen eigenen Datenbanknamen festlegen. Nach der Clusterbereitstellung können Sie den Namen der Datenbank nicht mehr ändern.
- Der Clustername bestimmt den DNS-Namen, den Ihre Anwendungen zum Herstellen einer Verbindung verwenden. Geben Sie den Namen im Format
Wählen Sie am unteren Rand des Bildschirms Weiter: Netzwerk aus.
Wählen Sie auf dem Bildschirm Netzwerk die Option Von Azure-Diensten und -Ressourcen in Azure aus öffentlichen Zugriff auf diesen Cluster gestatten aus.
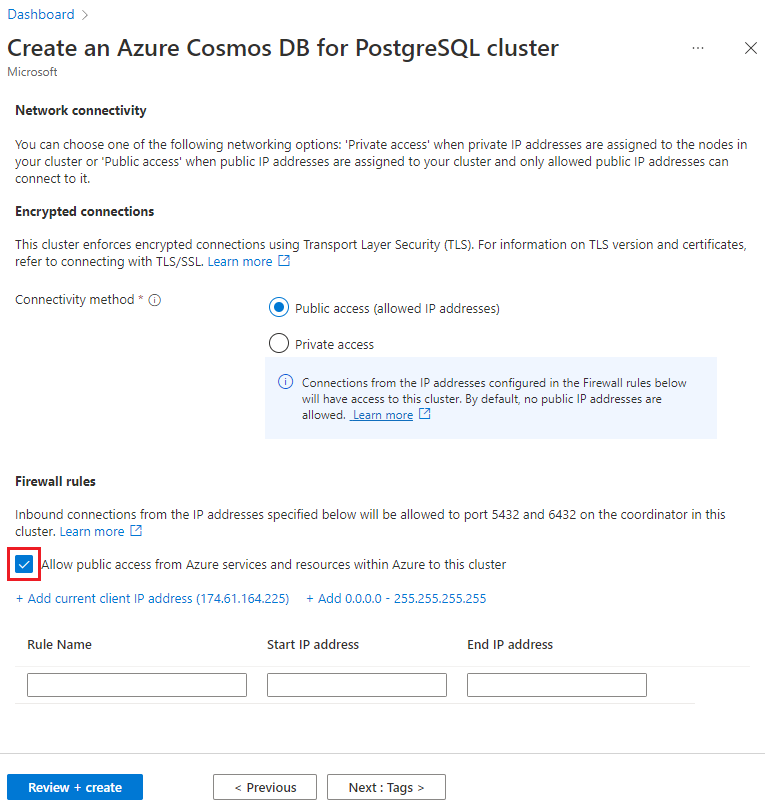
Wählen Sie Überprüfen und erstellen und nach bestandener Überprüfung Erstellen aus, um den Cluster zu erstellen.
Die Bereitstellung dauert einige Minuten. Die Seite leitet Sie zur Überwachung der Bereitstellung weiter. Wählen Sie Zu Ressource wechseln aus, wenn sich der Status von Bereitstellung wird ausgeführt in Ihre Bereitstellung wurde abgeschlossen. ändert.
Verwenden des psql-Hilfsprogramms zum Erstellen eines Schemas
Nachdem Sie mithilfe von psql eine Verbindung mit Azure Cosmos DB for PostgreSQL hergestellt haben, können Sie einige einfache Aufgaben ausführen. Dieses Tutorial führt Sie durch die Erstellung einer Web-App, die Werbetreibenden das Nachverfolgen ihrer Kampagnen ermöglicht.
Die App kann von mehreren Firmen verwendet werden, erstellen wir also eine Tabelle, die die Firmen enthält, und eine weitere für ihre Kampagnen. Führen Sie in der psql-Konsole diese Befehle aus:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Jede Kampagne zahlt für die Ausführung von Werbeeinblendungen. Fügen Sie außerdem eine Tabelle für Werbeeinblendungen hinzu, indem Sie nach dem Code oben den folgenden Code in psql ausführen:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Schließlich verfolgen wir die Statistiken über Klicks und Eindrücke für die einzelnen Werbeeinblendungen nach:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Sie können jetzt die neu erstellten Tabellen in der Liste der Tabellen in psql anzeigen, indem Sie dies ausführen:
\dt
Mehrmandantenfähige Anwendungen können Eindeutigkeit nur mandantenweise durchsetzen; dies ist der Grund dafür, warum alle Primär- und Fremdschlüssel die Firmen-ID enthalten.
Knotenübergreifende Shard-Tabellen
Eine Azure Cosmos DB for PostgreSQL-Bereitstellung speichert Tabellenzeilen basierend auf dem Wert einer vom Benutzer zugeordneten Spalte auf verschiedenen Knoten. Diese „Verteilungsspalte“ gibt an, welcher Mandant welche Zeilen besitzt.
Legen wir die Verteilungsspalte auf „company_id“ fest, den Mandantenbezeichner. Führen Sie in psql diese Funktionen aus:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Wichtig
Die Verteilung von Tabellen oder die Verwendung von schemabasiertem Sharding ist erforderlich, um die Vorteile der Leistungsfeatures von Azure Cosmos DB for PostgreSQL zu nutzen. Wenn Sie keine Tabellen oder Schemas verteilen, können Workerknoten nicht beim Ausführen von Abfragen helfen, die ihre Daten betreffen.
Erfassen von Beispieldaten
Laden Sie jetzt außerhalb von psql, an einer normalen Befehlszeile, Beispieldatasets herunter:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Führen Sie – jetzt wieder in psql – ein Massenladen der Daten aus. Achten Sie darauf, psql in dem gleichen Verzeichnis auszuführen, in das Sie die Datendateien heruntergeladen hatten.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Diese Daten werden jetzt über die Workerknoten verteilt.
Abfragen von Mandantendaten
Wenn die Anwendung Daten für einen einzelnen Mandanten anfordert, kann die Datenbank die Abfrage auf einem einzelnen Workerknoten ausführen. Abfragen für einzelne Mandanten führen eine Filterung nach einer einzelnen Mandanten-ID durch. Beispielsweise filtert die folgende Abfrage company_id = 5 nach Werbeeinblendungen und Eindrücken. Versuchen Sie, sie in psql auszuführen, um die Ergebnisse anzuzeigen.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Teilen von Daten zwischen Mandanten
Bis jetzt wurden alle Tabellen von company_id verteilt. Einige Daten „gehören“ jedoch nicht unbedingt einem bestimmten Mandanten und können gemeinsam genutzt werden. Beispielsweise ist es denkbar, dass alle Firmen auf der Plattform für Beispielwerbeeinblendungen geografische Informationen für ihre Zielgruppe auf der Grundlage der IP-Adressen abrufen möchten.
Erstellen Sie eine Tabelle zum Speichern von gemeinsam verwendeten geografischen Informationen. Führen Sie die folgenden Befehle in psql aus:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Machen Sie als Nächstes geo_ips zu einer „Verweistabelle“, und speichern Sie eine Kopie der Tabelle auf jedem Workerknoten.
SELECT create_reference_table('geo_ips');
Laden Sie sie mit Beispieldaten. Achten Sie darauf, diesen Befehl in psql in dem Verzeichnis auszuführen, in das Sie das Dataset heruntergeladen hatten.
\copy geo_ips from 'geo_ips.csv' with csv
Das Verknüpfen der Klicktabelle mit „geo_ips“ ist auf allen Knoten wirksam. Hier ist ein Join, um die Standorte aller Personen zu finden, die auf Anzeige 290 geklickt haben. Versuchen Sie, die Abfrage in psql auszuführen.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Mandantenweises Anpassen des Schemas
Für jeden Mandanten kann es erforderlich sein, besondere Informationen zu speichern, die von anderen nicht benötigt werden. Allerdings verwenden alle Mandanten eine gemeinsame Infrastruktur mit einem identischen Datenbankschema. Wo können die zusätzlichen Daten untergebracht werden?
Ein Trick besteht darin, einen Spaltentyp mit offenem Ende zu verwenden, wie JSONB von PostgreSQL. Unser Schema weist ein JSONB-Feld in clicks mit dem Namen user_data auf.
Eine Firma (z.B. Firma 5) kann die Spalte verwenden, um nachzuverfolgen, ob der Benutzer von einem mobilen Gerät aus zugreift.
Mit dieser Abfrage finden Sie heraus, wer öfter klickt – mobile oder herkömmliche Benutzer:
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Wir können diese Abfrage für eine einzelne Firma optimieren, indem wir einen Teilindex erstellen.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Allgemeiner ausgedrückt können wir GIN-Indizes für alle Schlüssel und Wert in der Spalte erstellen.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Bereinigen von Ressourcen
In den vorherigen Schritten haben Sie Azure-Ressourcen in einem Cluster erstellt. Wenn Sie diese Ressourcen nicht mehr benötigen, löschen Sie den Cluster. Wählen Sie auf der Seite Übersicht für Ihren Cluster die Schaltfläche Löschen aus. Bestätigen Sie den Namen des Clusters, wenn Sie auf einer Popupseite dazu aufgefordert werden, und klicken Sie abschließend auf die Schaltfläche Löschen.
Nächste Schritte
In diesem Tutorial haben Sie erfahren, wie Sie einen Cluster bereitstellen. Sie haben mithilfe von psql eine Verbindung mit ihr hergestellt, haben ein Schema erstellt und Daten verteilt. Sie haben gelernt, Daten sowohl innerhalb von als auch zwischen Mandanten abzufragen und das Schema mandantenweise anzupassen.
- Weitere Informationen zu Clusterknotentypen
- Bestimmen der besten Anfangsgröße für Ihren Cluster