Modellieren von Echtzeitanalyse-Apps in Azure Cosmos DB for PostgreSQL
GILT FÜR: ![]() Azure Cosmos DB for PostgreSQL (unterstützt von der Citus-Datenbankerweiterung auf PostgreSQL)
Azure Cosmos DB for PostgreSQL (unterstützt von der Citus-Datenbankerweiterung auf PostgreSQL)
Kolocieren großer Tabellen mit Shardschlüssel
Um den Shardschlüssel für eine operative Echtzeitanalyse-App auszuwählen, befolgen Sie die folgenden Richtlinien:
- Wählen Sie eine Spalte aus, die in großen Tabellen häufig verwendet wird
- Wählen Sie eine Spalte aus, die eine natürliche Dimension in den Daten oder ein zentrales Element der Anwendung ist. Einige Beispiele:
- In der Finanzwelt würde eine Anwendung, die Sicherheitstrends analysiert, wahrscheinlich
security_idverwenden. - In einem Benutzeranalysen-Workload, in dem Sie Website-Nutzungsmetriken analysieren möchten, wäre
user_ideine gute Verteilungsspalte
- In der Finanzwelt würde eine Anwendung, die Sicherheitstrends analysiert, wahrscheinlich
Indem Sie große Tabellen verlagern, können Sie SQL Abfragen parallel zu Workerknoten herunterpushen. Durch das Herunterpushen von Abfragen wird verhindert, dass Daten zwischen Knoten über dem Netzwerk verschoben werden. Vorgänge wie JOINs, Aggregate, Rollups, Filter, LIMITs können effizient ausgeführt werden.
Um parallel verteilte Abfragen in kolocierten Tabellen zu visualisieren, sollten Sie dieses Diagramm in Betracht ziehen:
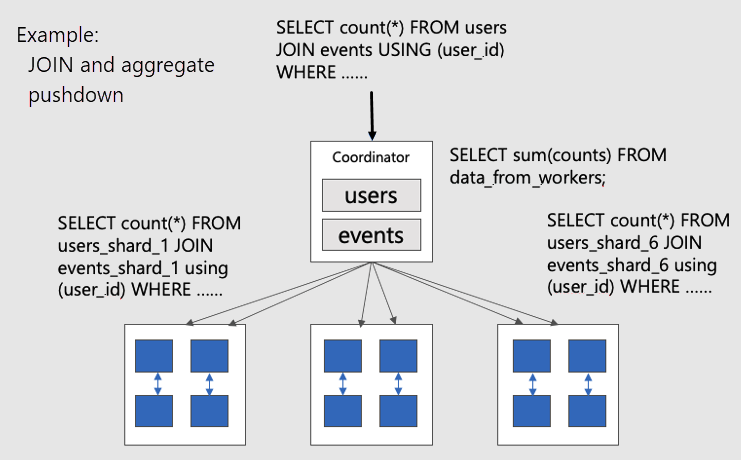
Die Tabellen users und events werden beide durch user_id horizontal partitioniert, sodass verwandte Zeilen für dieselbe Benutzer-ID zusammen auf demselben Workerknoten platziert werden. Die SQL JOINs können passieren, ohne Informationen zwischen Workern zu ziehen.
Optimales Datenmodell für Echtzeit-Apps
Fahren wir mit dem Beispiel einer App fort, die Benutzerwebsitebesuche und -metriken analysiert. Es gibt zwei "Fakten"-Tabellen – Benutzer und Ereignisse – und andere kleinere "Dimensions"-Tabellen.
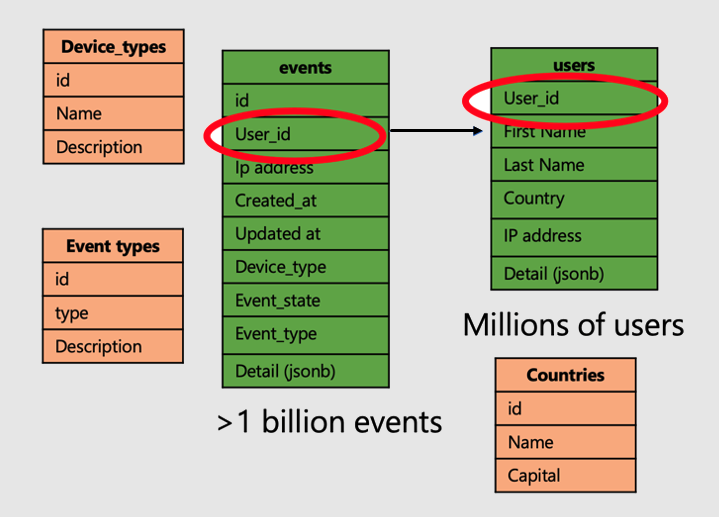
Führen Sie die folgenden Schritte aus, um die Superleistung verteilter Tabellen auf Azure Cosmos DB for PostgreSQL anzuwenden:
- Verteilen Sie große Faktentabellen auf einer gemeinsamen Spalte. In unserem Fall werden Benutzer und Ereignisse auf
user_idverteilt. - Markieren Sie die kleinen/Dimensionstabellen (
device_types,countriesund `event_types) als Verweistabellen. - Achten Sie darauf, die Verteilungsspalte in primäre, eindeutige und Fremdschlüsseleinschränkungen für verteilte Tabellen einzuschließen. Die Spalte kann dazu führen, dass die Schlüssel zusammengesetzt werden. Es müssen Schlüssel für Referenztabellen aktualisiert werden.
- Wenn Sie große verteilte Tabellen verknüpfen, müssen Sie sie unbedingt mit dem Shardschlüssel verknüpfen.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
Nächste Schritte
Jetzt haben Sie die Datenmodellierung für skalierbare Apps abgeschlossen. Der nächste Schritt besteht darin, die Datenbank mithilfe der Programmiersprache Ihrer Wahl zu verbinden und abzufragen.