Verwalten von Indizierungsrichtlinien in Azure Cosmos DB
In Azure Cosmos DB werden Daten gemäß Indizierungsrichtlinien indiziert, die für jeden Container definiert sind. Die standardmäßige Indizierungsrichtlinie für neu erstellte Container erzwingt Bereichsindizes für jede Zeichenfolge oder Zahl. Sie können diese Richtlinie mit Ihrer eigenen benutzerdefinierten Indizierungsrichtlinie überschreiben.
Hinweis
Die in diesem Artikel beschriebene Methode zur Aktualisierung von Indizierungsrichtlinien gilt nur für Azure Cosmos DB for NoSQL. Unter Azure Cosmos DB for MongoDB und Sekundäre Indizierung in Azure Cosmos DB for Apache Cassandra erfahren Sie mehr über die Indizierung.
Beispiele für Indizierungsrichtlinien
Hier sehen Sie einige Beispiele für Indizierungsrichtlinien im JSON-Format. Sie stehen im Azure-Portal im JSON-Format zur Verfügung. Die gleichen Parameter können über die Azure CLI oder ein beliebiges SDK festgelegt werden.
Deaktivierungsrichtlinie zum selektiven Ausschließen einiger Eigenschaftspfade
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
Aktivierungsrichtlinie zum selektiven Einschließen einiger Eigenschaftspfade
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
Hinweis
Es wird allgemein empfohlen, eine Opt-Out-Indizierungsrichtlinie zu verwenden. Azure Cosmos DB indiziert proaktiv alle neuen Eigenschaften, die einem Datenmodell hinzugefügt werden.
Verwenden eines räumlichen Index nur für einen bestimmten Eigenschaftspfad
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
Beispiele für Vektorindizierungsrichtlinien
Über das Ein- oder Ausschließen von Pfaden für einzelne Eigenschaften hinaus können Sie auch einen Vektorindex angeben. Im Allgemeinen sollten Vektorindizes angegeben werden, wenn die VectorDistance-Systemfunktion verwendet wird, um die Ähnlichkeit zwischen einem Abfragevektor und einer Vektoreigenschaft zu messen.
Hinweis
Bevor Sie fortfahren, müssen Sie die Vektorindizierung und -suche in Azure Cosmos DB for NoSQL aktivieren.
Wichtig
Eine Vektorindizierungsrichtlinie muss sich im selben Pfad befinden, der in der Vektorrichtlinie des Containers definiert ist. Weitere Informationen zu Vektorrichtlinien für Container.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
},
{
"path": "/vector/*"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
Wichtig
Dieser Vektorpfad wurde dem Abschnitt „excludedPaths“ der Indizierungsrichtlinie hinzugefügt, um eine optimierte Leistung für das Einfügen sicherzustellen. Wenn der Vektorpfad nicht zu „excludedPaths“ hinzugefügt wird, führt dies zu einer höheren RU-Belastung und Latenz für Vektoreinfügungen.
Wichtig
Derzeit sind Vektorrichtlinien und Vektorindizes nach der Erstellung unveränderlich. Um Änderungen vorzunehmen, erstellen Sie eine neue Sammlung.
Sie können die folgenden Typen von Vektorindexrichtlinien definieren:
| Typ | Beschreibung | Max. Abmessungen |
|---|---|---|
flat |
Speichert Vektoren im selben Index wie andere indizierte Eigenschaften. | 505 |
quantizedFlat |
Quantisiert (komprimiert) Vektoren vor dem Speichern im Index. Dies kann die Latenz und den Durchsatz auf Kosten einer geringeren Genauigkeit verbessern. | 4096 |
diskANN |
Erstellt einen Index basierend auf DiskANN für schnelle und effiziente Näherungssuche. | 4096 |
Die Indextypen flat und quantizedFlat verwenden den Index von Azure Cosmos DB, um die einzelnen Vektoren während einer Vektorsuche zu speichern und zu lesen. Vektorsuchen mit einem flat-Index sind Brute-Force-Suchvorgänge und generieren eine Genauigkeit von 100 %. Es gibt jedoch eine Einschränkung der 505-Dimensionen für Vektoren in einem flachen Index.
Der quantizedFlat-Index speichert quantisierte oder komprimierte Vektoren im Index. Vektorsuchen mit dem quantizedFlat-Index sind ebenfalls Brute-Force-Suchvorgänge, ihre Genauigkeit kann jedoch etwas niedriger als 100 % sein, da die Vektoren vor dem Hinzufügen zum Index quantisiert werden. Vektorsuchen mit quantized flat sollten jedoch eine geringere Latenz, einen höheren Durchsatz und niedrigere RU-Kosten als Vektorsuchen in einem flat-Index aufweisen. Dies ist eine gute Option für Szenarien, in denen Sie Abfragefilter verwenden, um die Vektorsuche auf einen relativ kleinen Satz von Vektoren einzugrenzen.
Der diskANN-Index ist ein separater Index, der speziell für Vektoren mit DiskANN definiert ist, einer Suite von Hochleistungsalgorithmen für die Vektorindizierung, die von Microsoft Research entwickelt wurden. DiskANN-Indizes können eine der niedrigsten Latenzen, die höchste Abfragerate pro Sekunde (Query-per-second, QPS) und die niedrigsten RU-Kosten für Abfragen mit hoher Genauigkeit bieten. Da DiskANN jedoch ein ANN-Index (Approximate Nearest Neighbors) ist, kann die Genauigkeit niedriger sein als bei quantizedFlat oder flat.
Die Indizes diskANN und quantizedFlat akzeptieren optionale Indexerstellungsparameter, mit denen die Genauigkeit und Latenz für jeden ungefähren nächsten Nachbarn (ANN) im Vektorindex ausbalanciert werden können.
quantizationByteSize: legt die Größe (in Byte) für die Produktquantisierung fest. Min=1, Standard=dynamic (System entscheidet), Max=512. Das Festlegen eines höheren Werts kann zu einer höheren Genauigkeit bei Vektorsuchen führen, aber mit höheren RU-Kosten und höherer Latenz. Dies gilt für die IndextypenquantizedFlatundDiskANNgleichermaßen.indexingSearchListSize: legt fest, wie viele Vektoren während der Indexerstellung durchsucht werden sollen. Min=10, Standard=100, Max=500. Das Festlegen eines höheren Werts kann zu einer höheren Genauigkeit bei Vektorsuchen führen, aber auch zu einer längeren Indexerstellungszeit und höheren Latenz bei der Vektorerfassung. Dies gilt nur für den IndextypDiskANN.
Beispiele für Richtlinien zur Tupelindizierung
In diesem Beispiel für eine Indizierungsrichtlinie wird ein Tupelindex für „events.name“ und „events.category“ definiert.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{"path":"/*"},
{"path":"/events/[]/{name,category}/?"}
],
"excludedPaths":[],
"compositeIndexes":[]
}
Der obige Index wird für die folgende Abfrage verwendet.
SELECT *
FROM root r
WHERE
EXISTS (SELECT VALUE 1 FROM ev IN r.events
WHERE ev.name = ‘M&M’ AND ev.category = ‘Candy’)
Zusammengesetzte Indizierung – Richtlinienbeispiele
Über das Einschließen oder Ausschließen von Pfaden für einzelne Eigenschaften hinaus können Sie auch einen zusammengesetzten Index angeben. Um eine Abfrage auszuführen, die eine ORDER BY-Klausel für mehrere Eigenschaften aufweist, ist ein zusammengesetzter Index für diese Eigenschaften erforderlich. Wenn die Abfrage Filter zusammen mit der Sortierung nach mehreren Eigenschaften enthält, benötigen Sie möglicherweise mehr als einen zusammengesetzten Index.
Außerdem bedeuten zusammengesetzte Indizes einen Leistungsvorteil für Abfragen, die über mehrere Filter oder sowohl über einen Filter als auch eine ORDER BY-Klausel verfügen.
Hinweis
Zusammengesetzte Pfade weisen die implizite Angabe /? auf, weil nur der Skalarwert unter diesem Pfad indiziert wird. Der Platzhalter /* wird in zusammengesetzten Pfaden nicht unterstützt. Sie sollten in einem zusammengesetzten Pfad weder /? noch /* angeben. Bei zusammengesetzten Pfaden wird auch zwischen Groß- und Kleinschreibung unterschieden.
Zusammengesetzter Index, definiert für (name asc, age desc)
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Der zusammengesetzte Index für Name und Alter ist für die folgenden Abfragen erforderlich:
Abfrage 1:
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
Abfrage 2:
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
Dieser zusammengesetzte Index ist für die folgenden Abfragen von Vorteil und optimiert die Filter:
Abfrage 3:
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
Abfrage 4:
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
Zusammengesetzter Index, definiert für (name ASC, age ASC) und (name ASC, age DESC)
Sie können innerhalb der gleichen Indizierungsrichtlinie mehrere zusammengesetzte Indizes definieren.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Zusammengesetzter Index, definiert für (name ASC, age ASC)
Die Angabe der Reihenfolge ist optional. Ohne Angabe ist die Reihenfolge aufsteigend.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
Alle Eigenschaftspfade ausschließen, aber Indizierung aktiv lassen
Sie können diese Richtlinie verwenden, wenn das Feature „Gültigkeitsdauer“ (Time-to-Live, TTL) aktiv ist, aber keine anderen Indizes erforderlich sind (um Azure Cosmos DB als reinen Schlüsselwertspeicher zu verwenden).
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
Keine Indizierung
Diese Richtlinie deaktiviert die Indizierung. Wenn indexingMode auf none festgelegt ist, können Sie keine Gültigkeitsdauer für den Container festlegen.
{
"indexingMode": "none"
}
Aktualisieren der Indizierungsrichtlinie
In Azure Cosmos DB kann die Indizierungsrichtlinie mit den folgenden Methoden aktualisiert werden:
- Über das Azure-Portal
- Verwenden der Azure-Befehlszeilenschnittstelle
- PowerShell
- Ein SDK verwenden
Eine Aktualisierung der Indizierungsrichtlinie löst eine Indextransformation aus. Der Status dieser Transformation kann auch über die SDKs nachverfolgt werden.
Hinweis
Wenn Sie die Indizierungsrichtlinie aktualisieren, werden Schreibvorgänge in Azure Cosmos DB ohne Unterbrechung durchführt. Erfahren Sie mehr über Indizierungstransformationen.
Wichtig
Das Entfernen eines Index hat sofortige Auswirkungen, während das Hinzufügen eines neuen Index einige Zeit in Anspruch nimmt, da hierbei eine Indizierungstransformation erforderlich ist. Wenn Sie einen Index durch einen anderen ersetzen (z. B. einen Index für eine einzelne Eigenschaft durch einen zusammengesetzten Index), fügen Sie zuerst den neuen Index hinzu, und warten Sie dann, bis die Indextransformation abgeschlossen ist, bevor Sie den vorherigen Index aus der Indizierungsrichtlinie entfernen. Andernfalls hat dies negative Auswirkungen auf Ihre Fähigkeit, den vorherigen Index abzufragen, und kann aktive Workloads unterbrechen, die auf den vorherigen Index verweisen.
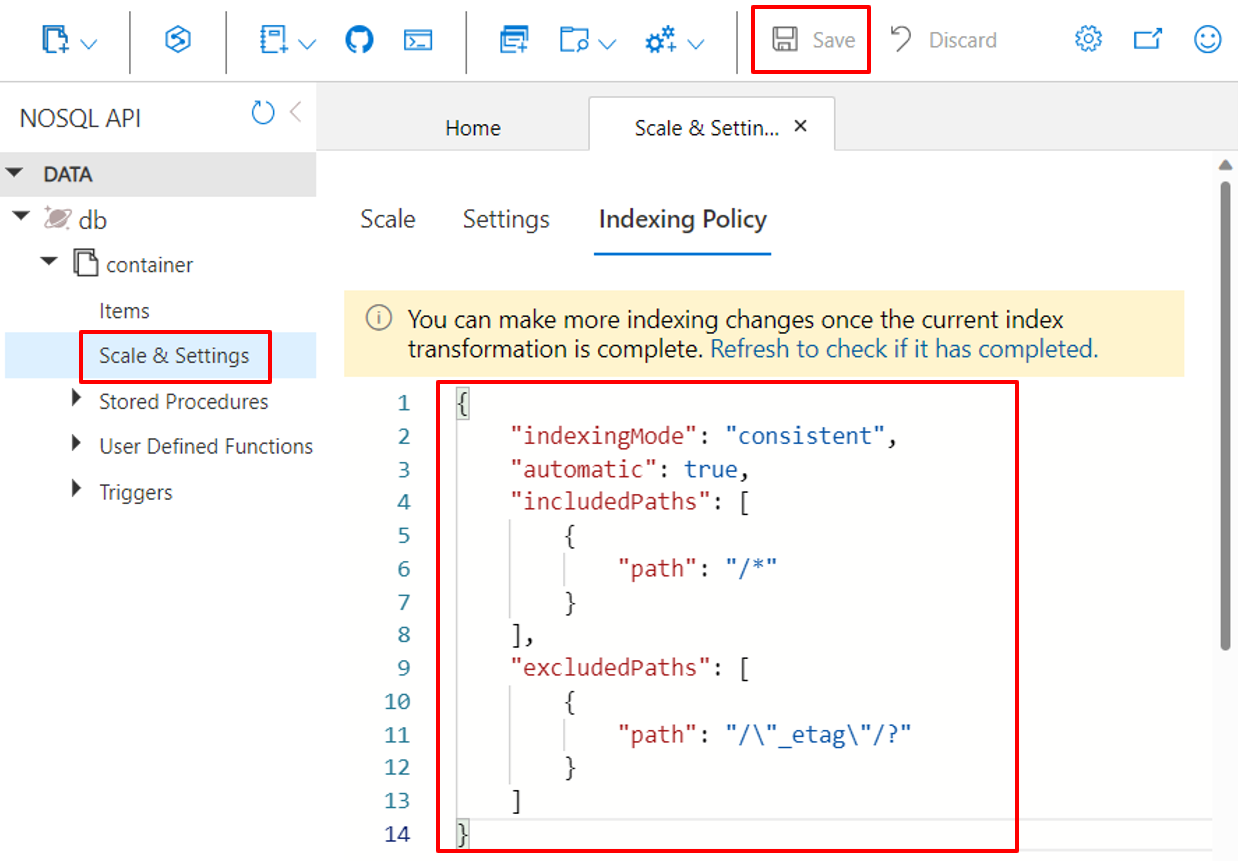
Verwenden des Azure-Portals
Azure Cosmos DB-Container speichern ihre Indizierungsrichtlinie als JSON-Dokument, das im Azure-Portal direkt bearbeitet werden kann.
Melden Sie sich beim Azure-Portal an.
Erstellen Sie ein neues Azure Cosmos DB-Konto, oder wählen Sie ein bereits vorhandenes Konto aus.
Öffnen Sie den Bereich Daten-Explorer, und wählen Sie den gewünschten Container aus.
Wählen Sie Skalierung & Einstellungen aus.
Ändern Sie das JSON-Dokument für die Indizierungsrichtlinie, wie in diesen Beispielen gezeigt.
Wählen Sie Speichern aus, wenn Sie fertig sind.
Verwenden der Azure-CLI
Informationen zum Erstellen eines Containers mit einer benutzerdefinierten Indexrichtlinie finden Sie unter Erstellen eines Containers mit einer benutzerdefinierten Indexrichtlinie mithilfe der CLI.
Verwenden von PowerShell
Informationen zum Erstellen eines Containers mit einer benutzerdefinierten Indexrichtlinie finden Sie unter Erstellen eines Containers mit einer benutzerdefinierten Indexrichtlinie mithilfe von PowerShell.
Verwenden des .NET SDK
Das ContainerProperties-Objekt aus dem .NET SDK v3 macht eine IndexingPolicy-Eigenschaft verfügbar, mit der Sie IndexingMode ändern sowie IncludedPaths und ExcludedPaths hinzufügen oder entfernen können. Weitere Informationen finden Sie unter Schnellstart: Azure Cosmos DB for NoSQL-Clientbibliothek für .NET.
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
Zum Nachverfolgen des Fortschritts der Indextransformation übergeben Sie ein RequestOptions-Objekt, das die PopulateQuotaInfo-Eigenschaft auf true festlegt. Rufen Sie den Wert aus dem x-ms-documentdb-collection-index-transformation-progress-Antwortheader ab.
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
Wenn Sie beim Erstellen eines neuen Containers eine benutzerdefinierte Indizierungsrichtlinie definieren, bietet die Fluent-API aus dem SDK V3 eine präzise und effiziente Möglichkeit zum Schreiben dieser Definition:
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
Verwenden des Java SDK
Das DocumentCollection-Objekt aus dem Java SDK macht die Methoden getIndexingPolicy() und setIndexingPolicy() verfügbar. Mit dem bearbeiteten IndexingPolicy-Objekt können Sie den Indizierungsmodus ändern sowie ein- und ausgeschlossene Pfade hinzufügen und entfernen. Weitere Informationen finden Sie unter Schnellstart: Erstellen einer Java-App zum Verwalten von Azure Cosmos DB for NoSQL.
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
Zum Nachverfolgen der Fortschritts der Indextransformation für einen Container übergeben Sie ein RequestOptions-Objekt, das anfordert, dass die Kontingentinformationen ausgefüllt werden. Rufen Sie den Wert aus dem x-ms-documentdb-collection-index-transformation-progress-Antwortheader ab.
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
Verwenden des Node.js SDK
Die ContainerDefinition-Schnittstelle aus dem Node.js SDK macht eine indexingPolicy-Eigenschaft verfügbar, mit der Sie indexingMode ändern sowie includedPaths und excludedPaths hinzufügen oder entfernen können. Weitere Informationen finden Sie unter Schnellstart: Azure Cosmos DB for NoSQL-Clientbibliothek für Node.js.
Rufen Sie Details des Containers ab:
const containerResponse = await client.database('database').container('container').read();
Legen Sie den Indizierungsmodus auf „Konsistent“ fest:
containerResponse.body.indexingPolicy.indexingMode = "consistent";
Fügen Sie einen eingeschlossenen Pfad mit einem räumlichen Index hinzu:
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
Fügen Sie einen ausgeschlossenen Pfad hinzu:
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
Aktualisieren Sie den Container mit Änderungen:
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
Zum Nachverfolgen des Fortschritts der Indextransformation auf einem Container, übergeben Sie ein RequestOptions-Objekt, das die populateQuotaInfo-Eigenschaft auf true festlegt. Rufen Sie den Wert aus dem x-ms-documentdb-collection-index-transformation-progress-Antwortheader ab.
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
Fügen Sie einen zusammengesetzten Index hinzu:
console.log("create container with composite indexes");
const containerDefWithCompositeIndexes = {
id: "containerWithCompositeIndexingPolicy",
indexingPolicy: {
automatic: true,
indexingMode: IndexingMode.consistent,
includedPaths: [
{
path: "/*",
},
],
excludedPaths: [
{
path: '/"systemMetadata"/*',
},
],
compositeIndexes: [
[
{ path: "/field", order: "ascending" },
{ path: "/key", order: "ascending" },
],
],
},
};
const containerWithCompositeIndexes = (
await database.containers.create(containerDefWithCompositeIndexes)
).container;
Verwenden des Python SDK
Wenn Sie das Python SDK V3 verwenden, wird die Containerkonfiguration als Wörterbuch verwaltet. Über dieses Wörterbuch können Sie auf die Indizierungsrichtlinie und alle ihre Attribute zugreifen. Weitere Informationen finden Sie unter Schnellstart: Azure Cosmos DB for NoSQL-Clientbibliothek für Python.
Rufen Sie Details des Containers ab:
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
Legen Sie den Indizierungsmodus auf „Konsistent“ fest:
container['indexingPolicy']['indexingMode'] = 'consistent'
Definieren Sie eine Indizierungsrichtlinie mit einem eingeschlossenen Pfad und einem räumlichen Index:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
Definieren Sie eine Indizierungsrichtlinie mit einem ausgeschlossenen Pfad:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
Fügen Sie einen zusammengesetzten Index hinzu:
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
Aktualisieren Sie den Container mit Änderungen:
response = client.ReplaceContainer(containerPath, container)