Überwachen von normalisierten RU/s für einen Azure Cosmos DB-Container oder ein Azure Cosmos DB-Konto
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabelle
Tabelle
Azure Monitor für Azure Cosmos DB verfügt über eine Metrikansicht zum Überwachen Ihres Kontos und zum Erstellen von Dashboards. Weil die Azure Cosmos DB-Metriken standardmäßig erfasst werden, müssen Sie bei diesem Feature nichts explizit aktivieren oder konfigurieren.
Metrikdefinition
Die Metrik Normalisierter RU-Verbrauch ist eine Metrik zwischen 0 % und 100 %, mit der die Auslastung des bereitgestellten Durchsatzes für eine Datenbank oder einen Container gemessen wird. Die Metrik wird in Intervallen von einer Minute ausgegeben und ist als maximale Auslastung der RU/s über alle Partitionsschlüsselbereiche im Zeitintervall definiert. Jeder Partitionsschlüsselbereich ist einer physischen Partition zugeordnet und wird zugewiesen, um Daten für einen Bereich möglicher Hashwerte zu speichern. Im Allgemeinen gilt: Je höher der Prozentsatz der normalisierten RU, desto stärker haben Sie den bereitgestellten Durchsatz genutzt. Mit der Metrik kann auch die Auslastung einzelner Partitionsschlüsselbereiche für eine Datenbank oder einen Container angezeigt werden.
Hier ein Beispiel: Sie haben einen Container, für den Sie einen maximalen Durchsatz für die Autoskalierung von 20.000 RU/s festgelegt haben (Skalierung zwischen 2000 und 20.000 RU/s), und Sie haben zwei Partitionsschlüsselbereiche (physische Partitionen) P1 und P2. Da Azure Cosmos DB den bereitgestellten Durchsatz gleichmäßig auf alle Partitionsschlüsselbereiche verteilt, können P1 und P2 jeweils zwischen 1000 und 10.000 RU/s skaliert werden. Angenommen, bei einem Intervall von einer Minute hat in einer bestimmten Sekunde P1 6000 Anforderungseinheiten und P2 8000 Anforderungseinheiten verbraucht. Der normalisierte RU-Verbrauch von P1 beträgt 60 % und von P2 80 %. Der gesamte normalisierte RU-Verbrauch des gesamten Containers beträgt MAX(60 %, 80 %) = 80 %.
Wenn Sie den Verbrauch von Anforderungseinheiten pro Sekunde zusammen mit dem Vorgangstyp sehen möchten, können Sie das optionale Feature Diagnoseprotokolle verwenden und die Tabelle PartitionKeyRUConsumption abfragen. Um einen allgemeinen Überblick über die Vorgänge und Statuscodes zu erhalten, die Ihre Anwendung auf der Azure Cosmos DB-Ressource ausführt, können Sie die integrierte Azure Monitor-Metrik Anforderungen gesamt (API für NoSQL), Mongo-Anforderungen, Gremlin-Anforderungen oder Cassandra-Anforderungen verwenden. Später können Sie diese Anforderungen nach dem Statuscode 429 filtern und nach Vorgangstyp aufteilen.
Was zu erwarten und zu tun ist, wenn der Wert für normalisierte RU/s höher ist
Wenn der normalisierte RU-Verbrauch für den angegebenen Partitionsschlüsselbereich 100 % erreicht und ein Client in diesem Zeitfenster von einer Sekunde weiterhin Anforderungen an diesen Bereich sendet, wird ein Ratenbegrenzungsfehler (429) gemeldet.
Das bedeutet nicht unbedingt, dass ein Problem mit Ihrer Ressource vorliegt. Die SDKs des Azure Cosmos DB-Clients und Datenimporttools wie Azure Data Factory und BulkExecutor-Bibliothek wiederholen beim Fehlercode 429 Anforderungen automatisch. 9 Wiederholungsversuche sind die Regel. Daher enthalten Metriken möglicherweise den Fehler mit dem Code 429, die aber möglicherweise nicht einmal an Ihre Anwendung zurückgegeben werden.
Im Allgemeinen gilt für eine Workload in der Produktion: Wenn 1-5 % der Anforderungen den Fehlercode 429 aufweisen und die End-to-End-Latenz akzeptabel ist, ist dies ein gutes Zeichen dafür, dass die RU/s vollständig genutzt werden. In diesem Fall bedeutet eine Metrik für normalisierten RU-Verbrauch von 100 % lediglich, dass in einer bestimmten Sekunde mindestens ein Partitionsschlüsselbereich den gesamten bereitgestellten Durchsatz verwendet hat. Dies ist akzeptabel, da die Gesamtanzahl der Fehlercodes 429 immer noch gering ist. Es ist keine weitere Aktion erforderlich.
Um festzustellen, welcher Prozentsatz der Anforderungen an Ihre Datenbank oder Ihren Container zum Fehlercode 429 geführt hat, navigieren Sie auf Ihrem Azure Cosmos DB-Kontoblatt zu Insights>Anforderungen>Anforderungen gesamt nach Statuscode. Filtern Sie nach einer bestimmten Datenbank und einem bestimmten Container. Verwenden Sie für die API für Gremlin die Metrik Gremlin-Anforderungen.
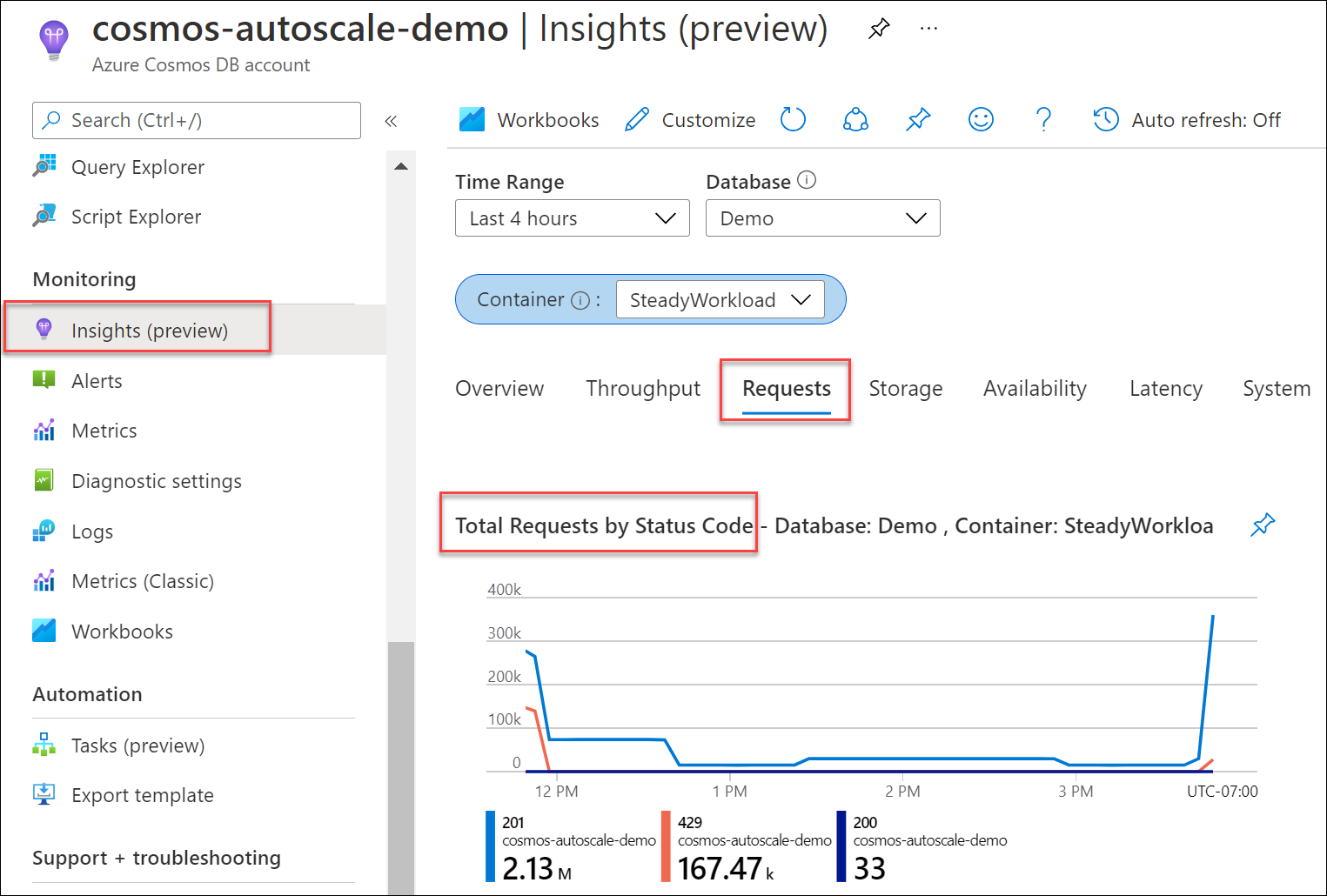
Wenn die Metrik für normalisierten RU-Verbrauch über mehrere Partitionsschlüsselbereiche hinweg konstant 100 % beträgt und die Anzahl der Fehlercodes 429 einen Wert von 5 % übersteigt, empfiehlt es sich, den Durchsatz zu erhöhen. Anhand der Azure Monitor-Metriken und der Azure Monitor-Diagnoseprotokolle können Sie herausfinden, welche Vorgänge einen hohen Verbrauch haben und wie hoch deren Spitzenauslastung ist. Folgen Sie den bewährten Methoden für das Skalieren des bereitgestellten Durchsatzes (RU/Sekunde).
Es ist nicht immer der Fall, dass ein Ratenbegrenzungsfehler vom Typ 429 angezeigt wird, nur weil die normalisierte RU 100 % erreicht hat. Der Grund dafür ist, dass die normalisierte RU ein einzelner Wert ist, der die maximale Auslastung über alle Partitionsschlüsselbereiche darstellt. Ein Partitionsschlüsselbereich ist möglicherweise ausgelastet, aber die anderen Bereiche können die Anforderungen problemlos verarbeiten. Beispielsweise führt ein einzelner Vorgang wie eine gespeicherte Prozedur, die alle RU/s für einen Partitionsschlüsselbereich verbraucht, zu einer kurzen Spitze in der Metrik für normalisierten RU-Verbrauch. In solchen Fällen gibt es keine unmittelbaren Ratenbegrenzungsfehler, wenn die Gesamtanforderungsrate niedrig ist oder Anforderungen an andere Partitionen in verschiedenen Partitionsschlüsselbereichen gestellt werden.
Erfahren Sie mehr über das Interpretieren und Debuggen von Ratenbegrenzungsfehlern des Typs 429.
Überwachen auf heiße Partitionen
Die Metrik für normalisierten RU-Verbrauch kann verwendet werden, um zu überwachen, ob Ihre Workload über eine heiße Partition verfügt. Es kommt zu einer heißen Partition, wenn mindestens ein logischer Partitionsschlüssel aufgrund eines höheren Anforderungsvolumens einen unverhältnismäßig großen Teil der gesamten RU/s beansprucht. Dies kann durch einen Partitionsschlüsselentwurf verursacht werden, aufgrund dessen Anforderungen nicht gleichmäßig verteilt werden. In diesem Fall werden viele Anforderungen an eine kleine Teilmenge logischer Partitionen gerichtet (dies bedeutet Partitionsschlüsselbereiche), die „heiß“ werden. Da sich alle Daten für eine logische Partition in einem Partitionsschlüsselbereich befinden und die gesamten RU/s gleichmäßig auf alle Partitionsschlüsselbereiche verteilt werden, kann eine heiße Partition zu Fehlern vom Typ 429 und ineffizienter Verwendung des Durchsatzes führen.
Ermitteln, ob eine heiße Partition vorliegt
Um zu überprüfen, ob eine heiße Partition vorliegt, wechseln Sie zu Erkenntnisse>Durchsatz>Normalisierter RU-Verbrauch (%) nach PartitionKeyRangeID. Filtern Sie nach einer bestimmten Datenbank und einem bestimmten Container.
Jede PartitionKeyRangeId ist einer physischen Partition zugeordnet. Wenn es eine PartitionKeyRangeId gibt, die einen deutlich höheren normalisierten RU-Verbrauch als die anderen aufweist (die z. B. konstant bei 100 % liegt, während andere Partitionen einen Wert von höchstens 30 % aufweisen), kann dies ein Zeichen für eine heiße Partition sein.
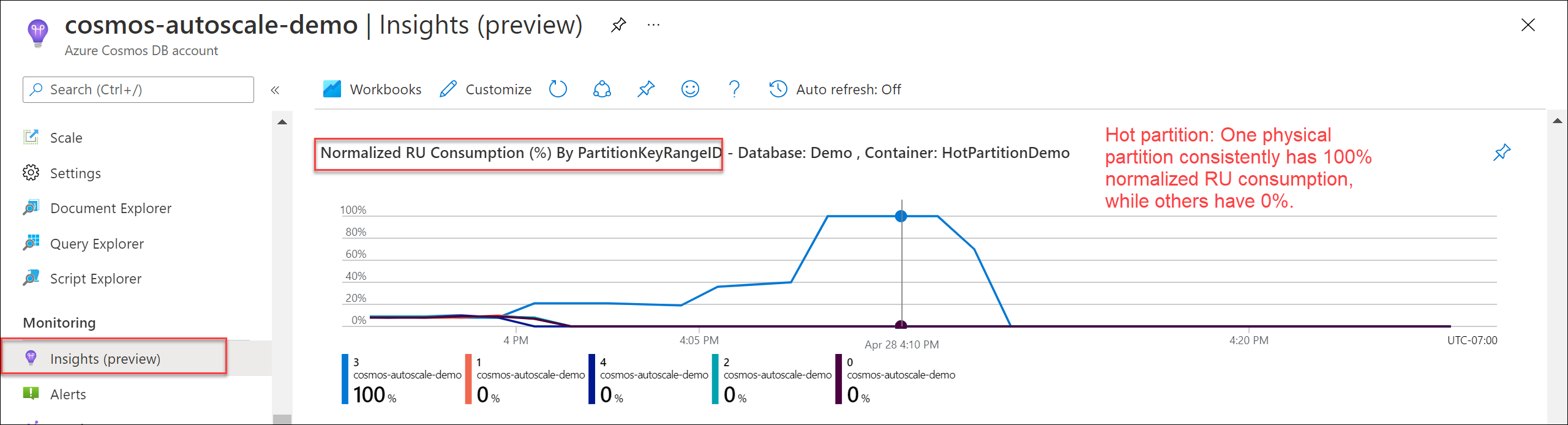
Informationen zur Ermittlung der logischen Partitionen, die die meisten RU/s verbrauchen, sowie empfohlene Lösungen finden Sie im Artikel Diagnostizieren und Behandeln von Problemen im Zusammenhang mit der Azure Cosmos DB-Ausnahme „Zu hohe Anforderungsrate“ (429).
Normalisierter RU-Verbrauch und Autoskalierung
Die Metrik für normalisierten RU-Verbrauch wird mit 100 % angezeigt, wenn mindestens ein Partitionsschlüsselbereich alle zugeordneten RU/s in einer bestimmten Sekunde im Zeitintervall verwendet. Häufig ergibt sich die Frage, warum der normalisierte RU-Verbrauch bei 100 % liegt, aber Azure Cosmos DB die RU/s nicht mithilfe der Autoskalierung auf den maximalen Durchsatz skaliert hat?
Hinweis
Die nachstehenden Informationen beschreiben die aktuelle Implementierung von Autoskalierung und können sich in Zukunft noch ändern.
Bei der Verwendung von Autoskalierung skaliert Azure Cosmos DB die RU/s nur auf den maximalen Durchsatz, wenn der normalisierte RU-Verbrauch für einen anhaltenden und kontinuierlichen Zeitraum in einem Intervall von fünf Sekunden bei 100 % liegt. Dadurch wird eine für den Benutzer kostengünstige Skalierungsstrategie sichergestellt und unnötige Skalierungen (verbunden mit höheren Kosten) bei einzelnen, kurzzeitigen Auslastungsspitzen vermieden. Bei kurzzeitigen Auslastungsspitzen skaliert das System in der Regel auf einen Wert hoch, der zwar oberhalb der zuvor skalierten RU/s, aber unterhalb der maximalen Anzahl liegt.
Hier ein Beispiel: Sie verfügen über einen Container mit einem maximalen Durchsatz für die Autoskalierung von 20.000 RU/s (Skalierung zwischen 2000 und 20.000 RU/s) und zwei Partitionsschlüsselbereichen. Jeder Partitionsschlüsselbereich kann zwischen 1000 und 10.000 RU/s skaliert werden. Da die Autoskalierung alle erforderlichen Ressourcen vorab bereitstellt, können Sie jederzeit bis zu 20.000 RU/s verwenden. Angenommen, Sie haben eine zeitweilige Datenverkehrsspitze, bei der die Verwendung eines der Partitionsschlüsselbereiche für eine einzige Sekunde 10.000 RU/s beträgt. In den darauffolgenden Sekunden geht die Verwendung wieder auf 1000 RU/s zurück. Da die Metrik für normalisierten RU-Verbrauch die höchste Auslastung in dem Zeitraum für alle Partitionen anzeigt, liegt sie bei 100 %. Da die Auslastung jedoch nur für eine Sekunde den Wert 100 % erreichte, nimmt die Autoskalierung keine automatische Skalierung auf das Maximum vor.
Daher können Sie weiterhin die gesamten verfügbaren RU/s verwenden, obwohl die Autoskalierung keine Skalierung auf das Maximum durchführt. Zur Überprüfung ihres RU/s-Verbrauchs können Sie das optionale Feature für Diagnoseprotokolle verwenden, um den gesamten RU/s-Verbrauch pro Sekunde für alle Partitionsschlüsselbereiche abzufragen.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
Im Allgemeinen gilt für eine Workload mit Autoskalierung: Wenn 1 bis 5 % der Anforderungen den Fehlercode 429 aufweisen und die End-to-End-Latenz akzeptabel ist, ist dies ein gutes Zeichen dafür, dass die RU/s vollständig genutzt werden. Selbst wenn der normalisierte RU-Verbrauch gelegentlich 100 % erreicht und die Autoskalierung nicht auf die maximale Anzahl von RU/s skaliert, ist dies in Ordnung, da die Gesamtanzahl der Fehlercodes 429 gering ist. Keine Aktion erforderlich.
Tipp
Wenn Sie Autoskalierung verwenden und feststellen, dass der normalisierte RU-Verbrauch konstant 100 % beträgt und durchgängig auf die maximale Anzahl von RU/s skaliert wird, ist dies ein Zeichen, dass die Verwendung des manuellen Durchsatzes kostengünstiger sein kann. Informationen dazu, ob die Autoskalierung oder der manuelle Durchsatz für Ihre Workload am besten geeignet ist, finden Sie im Artikel Auswählen zwischen standardmäßig (manuell) bereitgestelltem und automatisch skaliertem Durchsatz. Azure Cosmos DB sendet auch Azure Advisor-Empfehlungen auf der Grundlage Ihrer Workload-Muster, um entweder eine manuelle oder eine automatische Durchsatzskalierung zu empfehlen.
Anzeigen der Metrik für normalisierten Anforderungseinheitenverbrauch
Melden Sie sich beim Azure-Portal an.
Wählen Sie auf der Navigationsleiste auf der linken Seite die Option Monitor und anschließend Metrik aus.
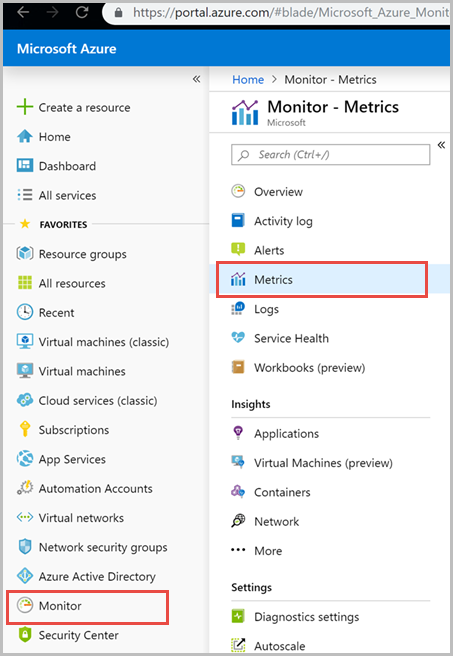
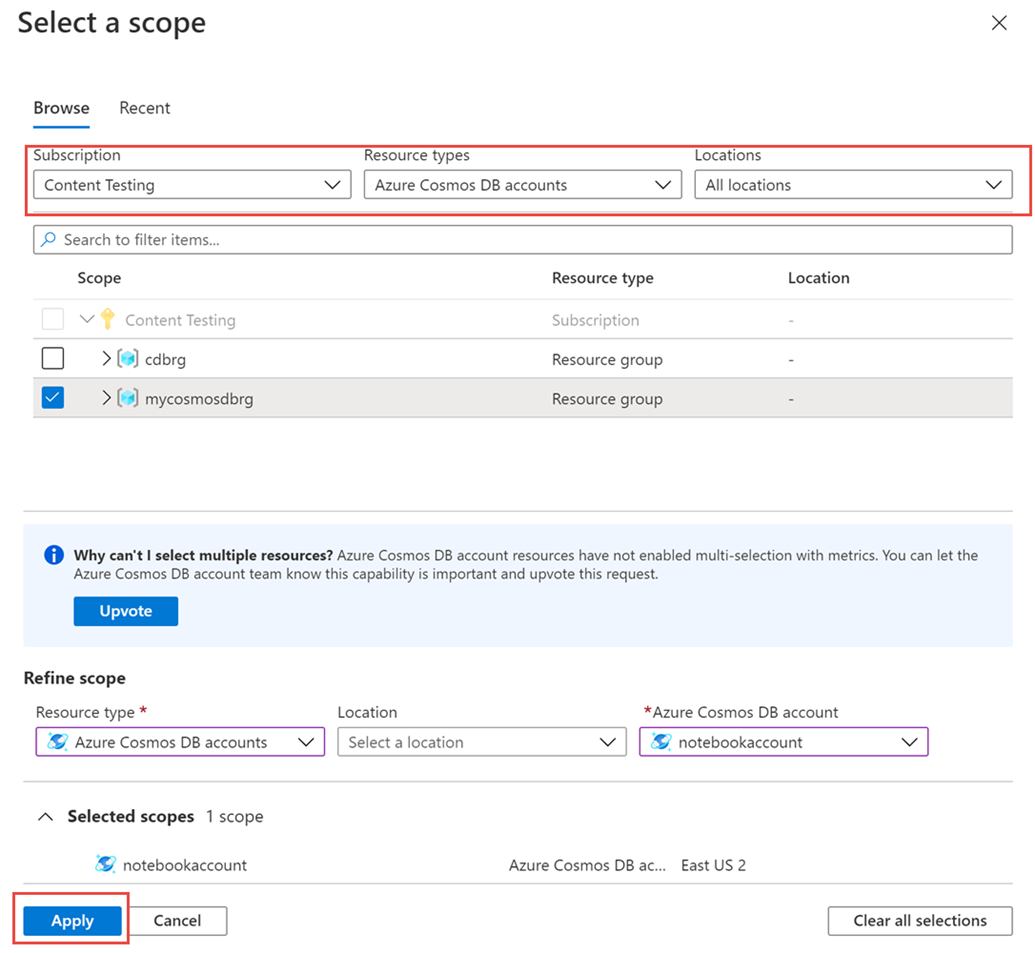
Klicken Sie im Bereich Metriken auf >Ressource auswählen>. Wählen Sie dann das erforderliche Abonnement und die Ressourcengruppe aus. Wählen Sie unter Ressourcentyp die Option Azure Cosmos DB-Konten aus. Wählen Sie dann eines der vorhandenen Azure Cosmos DB-Konten und anschließend Übernehmen aus.
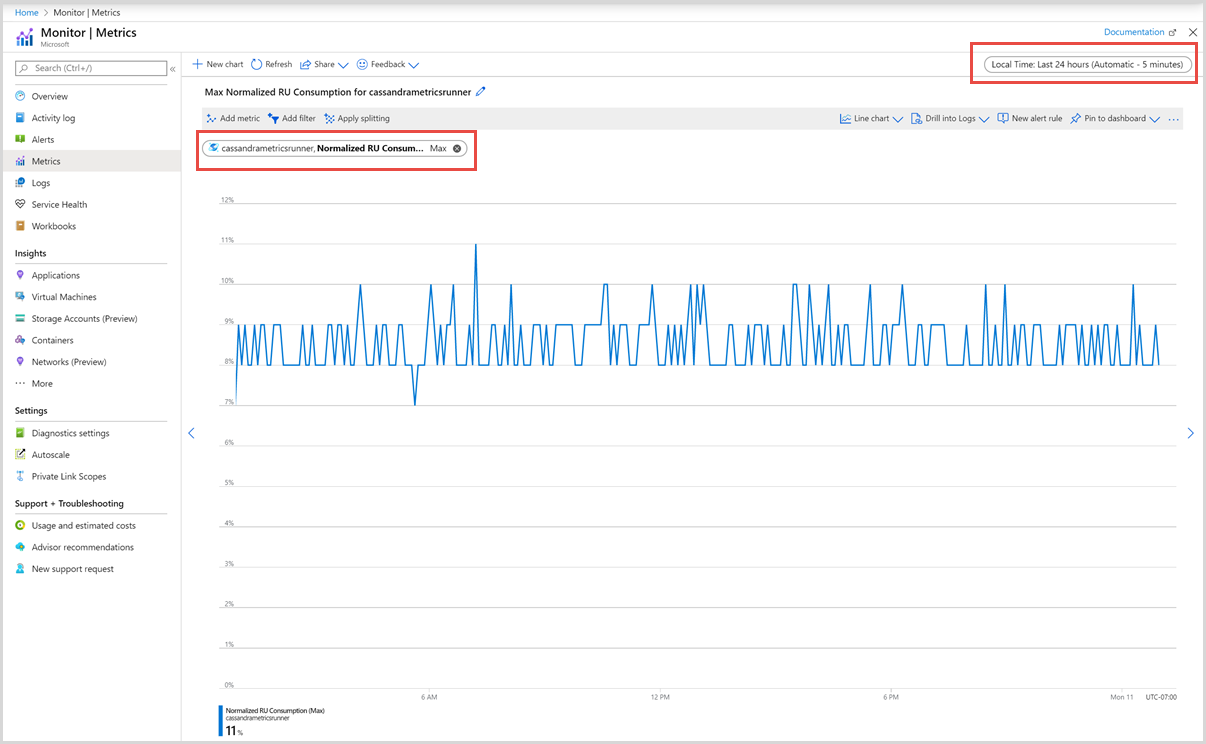
Als Nächstes können Sie eine Metrik aus der Liste der verfügbaren Metriken auswählen. Sie können spezifische Metriken für Anforderungseinheiten, Speicher, Wartezeit, Verfügbarkeit, Cassandra usw. auswählen. Ausführliche Informationen zu allen verfügbaren Metriken in dieser Liste finden Sie im Artikel Metriken nach Kategorie. In diesem Beispiel wählen wir die Metrik Normalisierter RU-Verbrauch und Max als Aggregationswert aus.
Zusätzlich zu diesen Angaben können Sie auch Zeitbereich und Zeitgranularität für die Metriken auswählen. Sie können Metriken maximal für die letzten 30 Tage anzeigen. Nach Anwendung des Filters wird ein darauf basierendes Diagramm angezeigt.
Filter für die Metrik für normalisierten RU-Verbrauch
Sie können Metriken und das angezeigte Diagramm auch nach bestimmten Werten für CollectionName, DatabaseName, PartitionKeyRangeID und Region filtern. Wählen Sie zum Filtern der Metriken Filter hinzufügen aus, und wählen Sie die erforderliche Eigenschaft (z. B. CollectionName) und den entsprechenden Wert aus, der Sie interessiert. Im Diagramm wird dann die Metrik für normalisierten RU-Verbrauch für den Container im ausgewählten Zeitraum angezeigt.
Sie können Metriken mit der Option Apply splitting (Aufteilung anwenden) gruppieren. Bei Datenbanken mit gemeinsam genutztem Durchsatz zeigt die normalisierte RU-Metrik nur Daten auf Datenbankebene an, es werden keine Daten pro Sammlung angezeigt. Bei einer Datenbank mit gemeinsam genutztem Durchsatz werden somit keine Daten angezeigt, wenn Sie die Aufteilung nach Sammlungsname anwenden.
Die normalisierte Metrik für den Verbrauch von Anforderungseinheiten für jeden Container wird wie in der folgenden Abbildung dargestellt angezeigt:

Nächste Schritte
- Überwachen der Azure Cosmos DB-Daten anhand der Diagnoseeinstellungen in Azure
- Überwachen von Azure Cosmos DB-Vorgängen auf Steuerungsebene
- Diagnostizieren und Behandeln von Problemen im Zusammenhang mit der Azure Cosmos DB-Ausnahme „Zu hohe Anforderungsrate“ (429)