Retrieval-Augmented Generation (RAG) mit Azure Cosmos DB for MongoDB (vCore)
Im sich schnell entwickelnden Bereich der generativen KI haben LLMs (Large Language Models) wie GPT-3.5 die Verarbeitung natürlicher Sprachen transformiert. Ein neuer Trend in der KI ist jedoch die Verwendung von Vektorspeichern, die eine wichtige Rolle bei der Verbesserung von KI-Anwendungen spielen.
In diesem Tutorial erfahren Sie, wie Sie Azure Cosmos DB for MongoDB (vCore), LangChain und OpenAI verwenden, um die Retrieval-Augmented Generation (RAG) für eine überlegene KI-Leistung zu implementieren. Außerdem werden LLMs und ihre Einschränkungen erläutert. Wir untersuchen das schnell angenommene Paradigma der „Retrieval-Augmented Generation“ (RAG) und besprechen kurz das LangChain-Framework und Azure OpenAI-Modelle. Schließlich integrieren wir diese Konzepte in eine echte Anwendung. Am Ende werden die Leser ein solides Verständnis dieser Konzepte haben.
Grundlegendes zu großen Sprachmodellen (Large Language Models, LLMs) und deren Einschränkungen
Große Sprachmodelle (LLMs) sind fortschrittliche Deep-Neural-Network-Modelle, die mit umfangreichen Textdatasets trainiert wurden, sodass sie Text menschenähnlich verstehen und generieren können. Während LLMs revolutionär bei der Verarbeitung natürlicher Sprache sind, weisen sie inhärente Einschränkungen auf:
- Halluzinationen: LLMs erzeugen manchmal inhaltlich falsche oder nicht gegroundete Informationen, die als „Halluzinationen“ bezeichnet werden.
- Veraltete Daten: LLMs werden mit statischen Datasets trainiert, die möglicherweise nicht die neuesten Informationen enthalten, was ihre aktuelle Relevanz einschränkt.
- Kein Zugriff auf lokale Daten des Benutzers: LLMs haben keinen direkten Zugriff auf personenbezogene oder lokalisierte Daten, was ihre Fähigkeit einschränkt, personalisierte Antworten bereitzustellen.
- Tokengrenzwerte: LLMs verfügen über einen Tokengrenzwert pro Interaktion, wodurch die Textmenge eingeschränkt wird, die sie gleichzeitig verarbeiten können. gpt-3.5-turbo von OpenAI hat beispielsweise einen Tokengrenzwert von 4096.
Nutzen von Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) ist eine Architektur, die für die Überwindung von LLM-Einschränkungen konzipiert ist. RAG verwendet die Vektorsuche, um relevante Dokumente basierend auf einer Eingabeabfrage abzurufen und diese Dokumente als Kontext für das LLM bereitzustellen, um genauere Antworten zu generieren. Anstatt sich ausschließlich auf vortrainierte Muster zu verlassen, verbessert RAG die Reaktionen durch die Einbeziehung aktueller relevanter Informationen. Dieser Ansatz hilft bei Folgendem:
- Halluzinationen minimieren: Antworten basieren auf Fakten.
- Für aktuelle Informationen sorgen: Die aktuellsten Daten werden abgerufen, um aktuelle Antworten sicherzustellen.
- Externe Datenbanken nutzen: Obwohl RAG keinen direkten Zugriff auf personenbezogene Daten gewährt, ist die Integration mit externen, benutzerspezifischen Wissensdatenbanken möglich.
- Tokennutzung optimieren: Indem RAG sich auf die relevantesten Dokumente konzentriert, wird die Tokennutzung effizienter.
In diesem Tutorial wird veranschaulicht, wie RAG mithilfe von Azure Cosmos DB for MongoDB (vCore) implementiert werden kann, um eine auf Ihre Daten zugeschnittene Frage-Antwort-Anwendung zu erstellen.
Übersicht über die Anwendungsarchitektur
Das folgende Architekturdiagramm veranschaulicht die wichtigsten Komponenten unserer RAG-Implementierung:
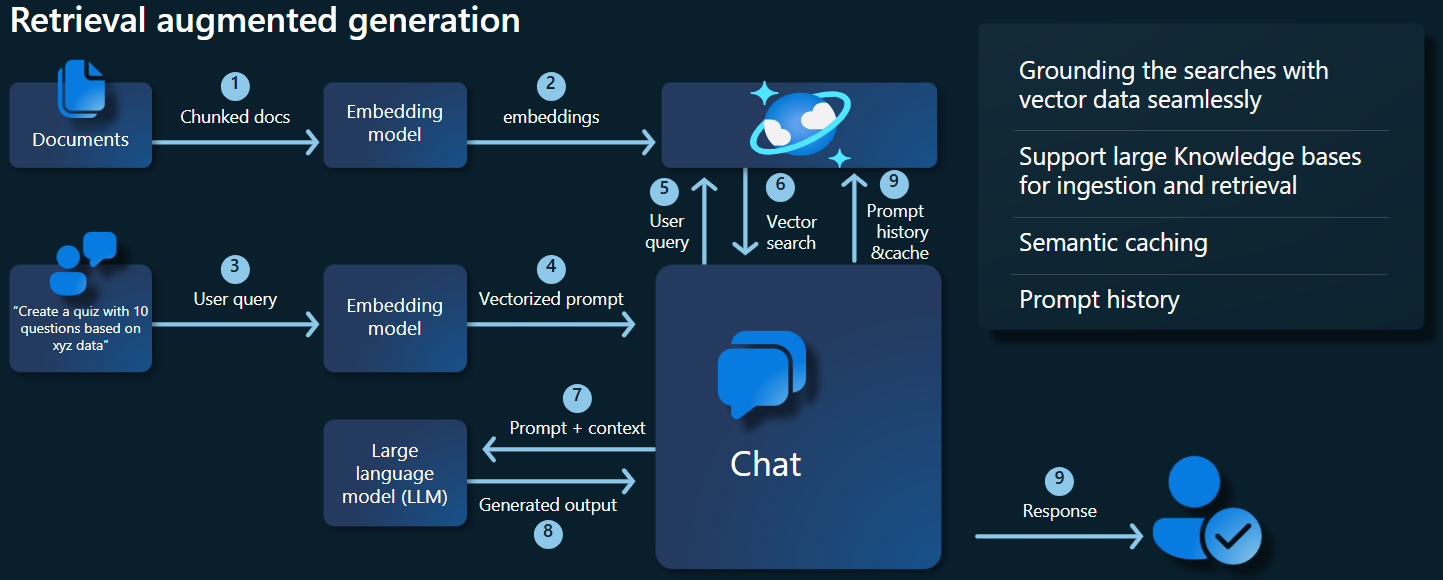
Wichtige Komponenten und Frameworks
Wir besprechen nun die verschiedenen Frameworks, Modelle und Komponenten, die in diesem Tutorial verwendet werden, und betonen ihre Rollen und Nuancen.
Azure Cosmos DB for MongoDB (vCore)
Azure Cosmos DB for MongoDB (vCore) unterstützt semantische Ähnlichkeitssuchen, die für KI-gesteuerte Anwendungen unerlässlich sind. Damit können Daten in verschiedenen Formaten als Vektoreinbettungen dargestellt werden, die zusammen mit Quelldaten und Metadaten gespeichert werden können. Mithilfe eines Nearest-Neighbor-Algorithmus, z. B. Hierarchical Navigable Small World (HNSW), können diese Einbettungen für schnelle semantische Ähnlichkeitssuchen abgefragt werden.
LangChain-Framework
LangChain vereinfacht die Erstellung von LLM-Anwendungen, indem eine Standardschnittstelle für Ketten, mehrere Toolintegrationen und End-to-End-Ketten für allgemeine Aufgaben bereitgestellt wird. Es ermöglicht KI-Entwicklern das Erstellen von LLM-Anwendungen, die externe Datenquellen nutzen.
Wichtige Aspekte von LangChain:
- Ketten: Komponentensequenzen, die bestimmte Aufgaben lösen
- Komponenten: Module wie LLM-Wrapper, Vektorspeicherwrapper, Promptvorlagen, Datenladeprogramme, Textteiler und Retriever
- Modularität: Vereinfacht Entwicklung, Debugging und Wartung
- Beliebtheit: Ein Open-Source-Projekt, das schnell an Akzeptanz gewinnt und weiterentwickelt wird, um den Benutzeranforderungen gerecht zu werden
Azure App Services-Benutzeroberfläche
App Services ist eine robuste Plattform zum Erstellen benutzerfreundlicher Webbenutzeroberflächen für generative KI-Anwendungen. In diesem Lernprogramm wird Azure App Services verwendet, um eine interaktive Webbenutzeroberfläche für die Anwendung zu erstellen.
OpenAI-Modelle
OpenAI ist führend in der KI-Forschung und bietet verschiedene Modelle für die Sprachgenerierung, Textvektorisierung, Bilderstellung und Audio-zu-Text-Konvertierung. In diesem Lernprogramm verwenden wir OpenAI-Einbettungs- und Sprachmodelle, die für das Verständnis und die Generierung sprachbasierter Anwendungen von entscheidender Bedeutung sind.
Einbettungsmodelle und Sprachgenerierungsmodelle
| Kategorie | Texteinbettungsmodell | Sprachmodell |
|---|---|---|
| Kostenträger | Konvertiert Text in Vektoreinbettungen | Versteht und generiert natürliche Sprache |
| Funktion | Wandelt Textdaten in hochdimensionale Zahlenarrays um, wobei die semantische Bedeutung des Texts erfasst wird | Versteht und erzeugt menschenähnlichen Text, der auf einer bestimmten Eingabe basiert |
| Output | Zahlenarray (Vektoreinbettungen) | Text, Antworten, Übersetzungen, Code usw. |
| Beispielausgabe | Jede Einbettung stellt die semantische Bedeutung des Texts in numerischer Form dar, wobei eine vom Modell festgelegte Dimensionalität angegeben wird. Beispielsweise generiert text-embedding-ada-002 Vektoren mit 1536 Dimensionen. |
Kontextbezogener und kohärenter Text, der basierend auf der bereitgestellten Eingabe generiert wird. Beispielsweise kann gpt-3.5-turbo Antworten auf Fragen generieren, Text übersetzen, Code schreiben und vieles mehr. |
| Typische Anwendungsfälle | – Semantische Suche | – Chatbots |
| – Empfehlungssysteme | – Automatisierte Inhaltserstellung | |
| – Clustering und Klassifizierung von Textdaten | – Sprachübersetzung | |
| – Informationsabruf | – Zusammenfassung | |
| Datendarstellung | Numerische Darstellung (Einbettungen) | Text in natürlicher Sprache |
| Dimensionalität | Die Länge des Arrays entspricht der Anzahl der Dimensionen im Einbettungsraum, z. B. 1536 Dimensionen. | In der Regel als Abfolge von Token dargestellt, wobei der Kontext die Länge bestimmt. |
Hauptkomponenten der Anwendung
- Azure Cosmos DB for MongoDB (vCore): Speichern und Abfragen von Vektoreinbettungen
- LangChain: Erstellen des LLM-Workflows der Anwendung Nutzt Tools wie:
- Dokumentladeprogramm: Zum Laden und Verarbeiten von Dokumenten aus einem Verzeichnis
- Vektorspeicherintegration: Zum Speichern und Abfragen von Vektoreinbettungen in Azure Cosmos DB
- AzureCosmosDBVectorSearch: Wrapper um Cosmos DB-Vektorsuche
- Azure App Services: Erstellen der Benutzeroberfläche für die Cosmic Food-App
- Azure OpenAI: Implementierung von LLM- und Einbettungsmodellen, einschließlich:
- text-embedding-ada-002: Ein Texteinbettungsmodell, das Text in Vektoreinbettungen mit 1536 Dimensionen konvertiert
- gpt-3.5-turbo: Ein Sprachmodell zum Verständnis und zur Generierung natürlicher Sprache
Einrichten der Umgebung
Führen Sie die folgenden Schritte aus, um die Retrieval-Augmented Generation (RAG) mithilfe von Azure Cosmos DB for MongoDB (vCore) zu optimieren:
- Erstellen Sie die folgenden Ressourcen in Microsoft Azure:
- Azure Cosmos DB for MongoDB (vCore)-Cluster: Lesen Sie das Schnellstarthandbuch.
- Azure OpenAI-Ressource mit:
- Einbettungsmodellimplementierung (z. B.
text-embedding-ada-002) - Chatmodellimplementierung (z. B.
gpt-35-turbo)
- Einbettungsmodellimplementierung (z. B.
Beispieldokumente
In diesem Tutorial laden wir eine einzelne Textdatei mit Dokument. Diese Dateien sollten in einem Verzeichnis mit dem Namen data im Ordner src gespeichert werden. Der Inhalt der Datei lautet wie folgt:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Laden von Dokumenten
Legen Sie die Verbindungszeichenfolge, den Datenbanknamen, den Sammlungsnamen und den Index für Cosmos DB for MongoDB (vCore) fest:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Initialisieren Sie den Einbettungsclient.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Erstellen Sie Einbettungen aus den Daten, speichern Sie sie in der Datenbank, und geben Sie eine Verbindung mit Ihrem Vektorspeicher zurück, Cosmos DB for MongoDB (vCore).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Erstellen Sie den folgenden HNSW-Vektorindex für die Sammlung (Name des Indexes muss mit dem obigen identisch sein).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Durchführen der Vektorsuche mit Cosmos DB for MongoDB (vCore)
Stellen Sie eine Verbindung mit Ihrem Vektorspeicher her.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Definieren Sie eine Funktion, die die semantische Ähnlichkeitssuche mithilfe der Cosmos DB-Vektorsuche für eine Abfrage durchführt (Codeschnipsel ist nur eine Testfunktion).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Initialisieren Sie den Chatclient, um eine RAG-Funktion zu implementieren.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Erstellen Sie eine RAG-Funktion.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Konvertieren Sie den Vektorspeicher in einen Retriever, der basierend auf angegebenen Parametern nach relevanten Dokumenten suchen kann.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Erstellen Sie eine Retrieverkette, der der Gesprächsverlauf bekannt ist, wodurch mithilfe des Modells azure_openai_chat und vector_store_retriever ein kontextbezogener Dokumentabruf sichergestellt wird.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Erstellen Sie eine Kette, die abgerufene Dokumente mithilfe des Sprachmodells (azure_openai_chat) und einem Prompt (context_prompt) zu einer kohärenten Antwort kombiniert.
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Erstellen Sie eine Kette, die den gesamten Abrufprozess verarbeitet, in dem die verlaufsbewusste Retrieverkette und die Dokumentkombinationskette integriert werden. Diese RAG-Kette kann ausgeführt werden, um kontextbezogene genaue Antworten abzurufen und zu generieren.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
Beispielausgaben
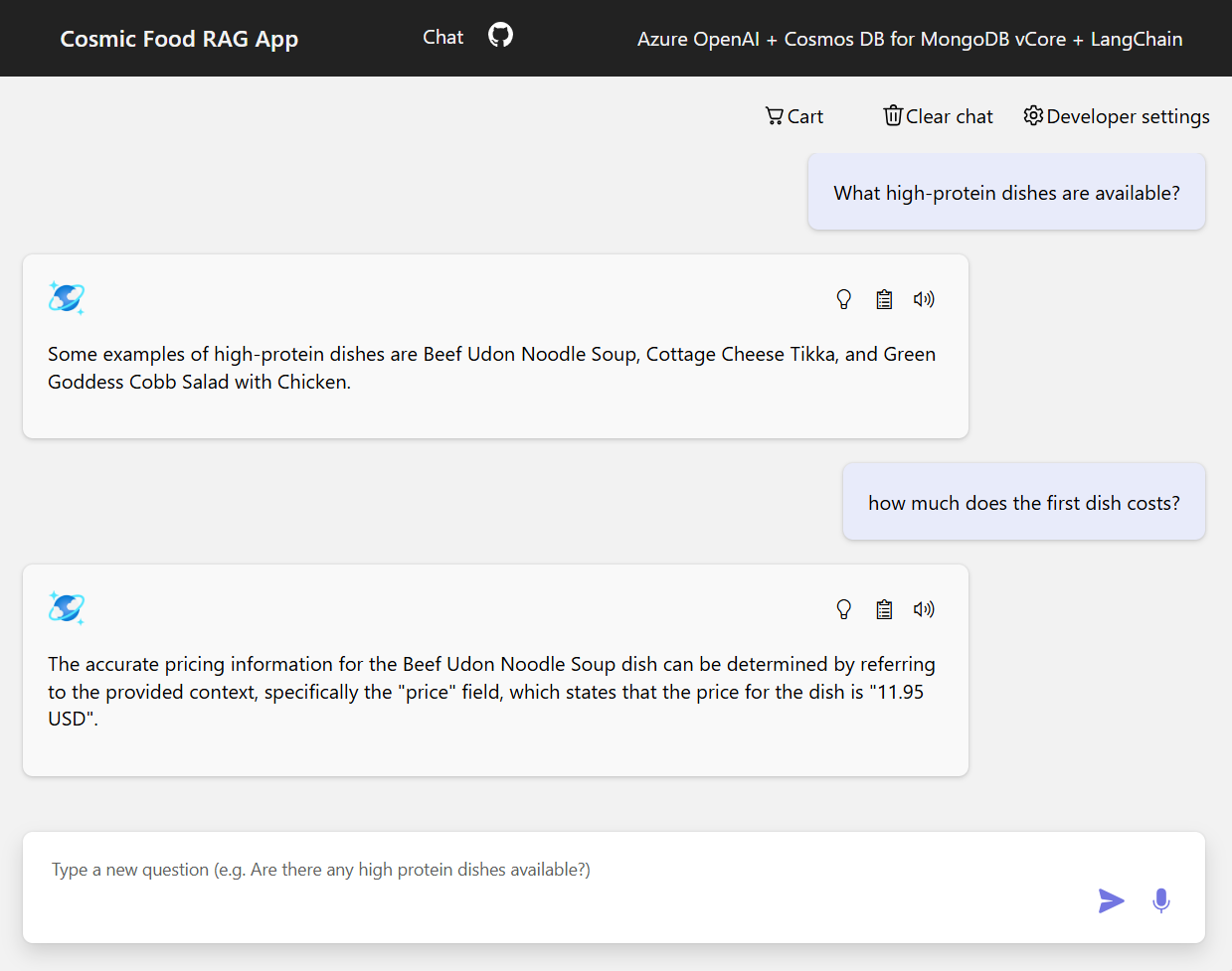
Der folgende Screenshot veranschaulicht die Ausgaben für verschiedene Fragen. Eine rein semantische Ähnlichkeitssuche gibt den Rohtext aus den Quelldokumenten zurück, während die Frage-Antwort-App mit der RAG-Architektur präzise und personalisierte Antworten generiert, indem abgerufene Dokumentinhalte mit dem Sprachmodell kombiniert werden.
Zusammenfassung
In diesem Tutorial haben wir untersucht, wie Sie eine Frage-Antwort-App erstellen, die mit Ihren privaten Daten interagiert, indem Cosmos DB als Vektorspeicher verwendet wird. Durch die Nutzung der RAG-Architektur mit LangChain und Azure OpenAI haben wir gezeigt, warum Vektorspeicher für LLM-Anwendungen essenziell sind.
RAG ist ein bedeutender Fortschritt in der KI, insbesondere bei der Verarbeitung natürlicher Sprache, und die Kombination dieser Technologien ermöglicht die Erstellung leistungsstarker KI-gesteuerter Anwendungen für verschiedene Anwendungsfälle.