Globale Datenverteilung mit Azure Cosmos DB: Hintergrundinformationen
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabelle
Tabelle
Azure Cosmos DB ist einer der Basisdienste in Azure und wird daher in sämtlichen Azure-Regionen weltweit (einschließlich der öffentlichen, Sovereign-, DoD- (Department of Defense) und Government-Clouds) bereitgestellt.
Auf einer hohen Ebene sind Azure Cosmos DB-Containerdaten horizontal in viele Replikat-Sets partitioniert, die Schreibvorgänge in jeder Region replizieren. Replikatsätze übertragen Schreibvorgänge dauerhaft mit Hilfe eines Mehrheitsquorums.
Jede Region enthält alle Datenpartitionen eines Azure Cosmos DB-Containers und kann Lesevorgänge zulassen sowie Schreibvorgänge, wenn Schreibvorgänge in mehreren Regionen zulässig sind. Wenn Ihr Azure Cosmos DB-Konto über N Azure-Regionen verteilt ist, gibt es mindestens N x 4 Kopien von allen Ihren Daten.
Innerhalb eines Rechenzentrums wird Azure Cosmos DB auf umfangreichen „Stamps“ von Computern, die jeweils über dedizierten lokalen Speicher verfügen, bereitgestellt und verwaltet. Innerhalb eines Datencenters wird Azure Cosmos DB in vielen Clustern bereitgestellt, die jeweils in der Lage sind, mehrere Generationen von Hardware auszuführen. Für Hochverfügbarkeit innerhalb einer Region werden die Computer in einem Cluster in der Regel auf 10–20 Fehlerdomänen aufgeteilt. Die folgende Abbildung zeigt die Systemtopologie von Azure Cosmos DB für die globale Verteilung:
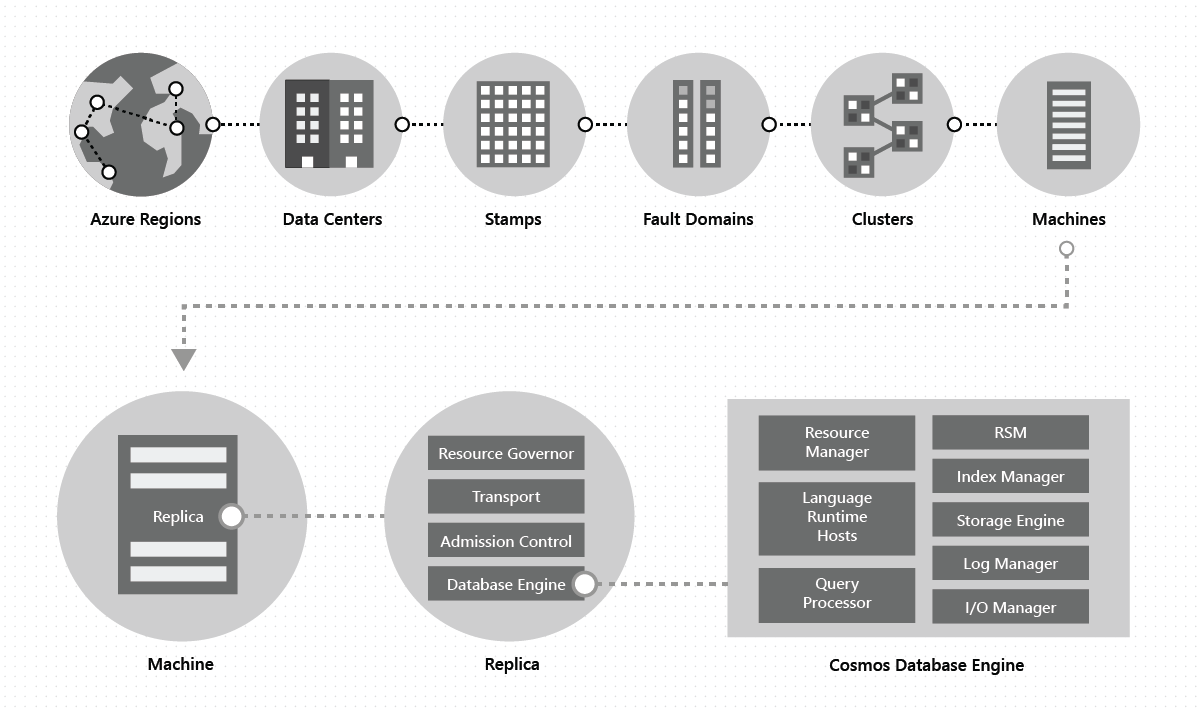
Die globale Verteilung in Azure Cosmos DB ist schlüsselfertig: Sie können jederzeit mit wenigen Klicks oder programmatisch mit einem einzigen API-Aufruf die mit Ihrer Azure Cosmos DB-Datenbank verbundenen geografischen Regionen hinzufügen oder entfernen. Eine Azure Cosmos DB-Datenbank besteht wiederum aus einer Reihe von Azure Cosmos DB-Containern. In Azure Cosmos DB dienen Container als logische Einheit für die Verteilung und Skalierung. Die Sammlungen, Tabellen und Diagramme, die Sie erstellen, sind (intern) nur Azure Cosmos DB-Container. Container sind vollständig schemaunabhängig und stellen einen Gültigkeitsbereich für eine Abfrage dar. Die Daten in einem Azure Cosmos DB-Container werden bei der Erfassung automatisch indiziert. Durch die automatische Indizierung können Benutzer die Daten abfragen, ohne sich um das Schema oder die Indexverwaltung kümmern zu müssen, was besonders in einem global verteilten Setup hilfreich ist.
In einer bestimmten Region werden die Daten in einem Container mithilfe eines Partitionsschlüssels, den Sie angeben, verteilt und transparent von den zugrunde liegenden physischen Partitionen (lokale Verteilung) verwaltet.
Jede physische Partition wird außerdem über geografische Regionen repliziert (globale Verteilung).
Wenn eine App den Durchsatz in einem Azure Cosmos DB-Container mithilfe von Azure Cosmos DB elastisch skaliert oder zusätzlichen Speicher verbraucht, verarbeitet Azure Cosmos DB die Vorgänge zur Partitionsverwaltung (z. B. Teilen, Klonen, Löschen usw.) in sämtlichen Regionen transparent. Unabhängig von Skalierung, Verteilung oder Ausfällen stellt Azure Cosmos DB weiterhin ein einzelnes Systemimage der Daten in den Containern bereit, die global auf eine beliebige Anzahl von Regionen verteilt sind.
Wie in der folgenden Abbildung gezeigt wird, sind die Daten in einem Container über zwei Dimensionen verteilt – innerhalb einer Region und regionsübergreifend, weltweit:
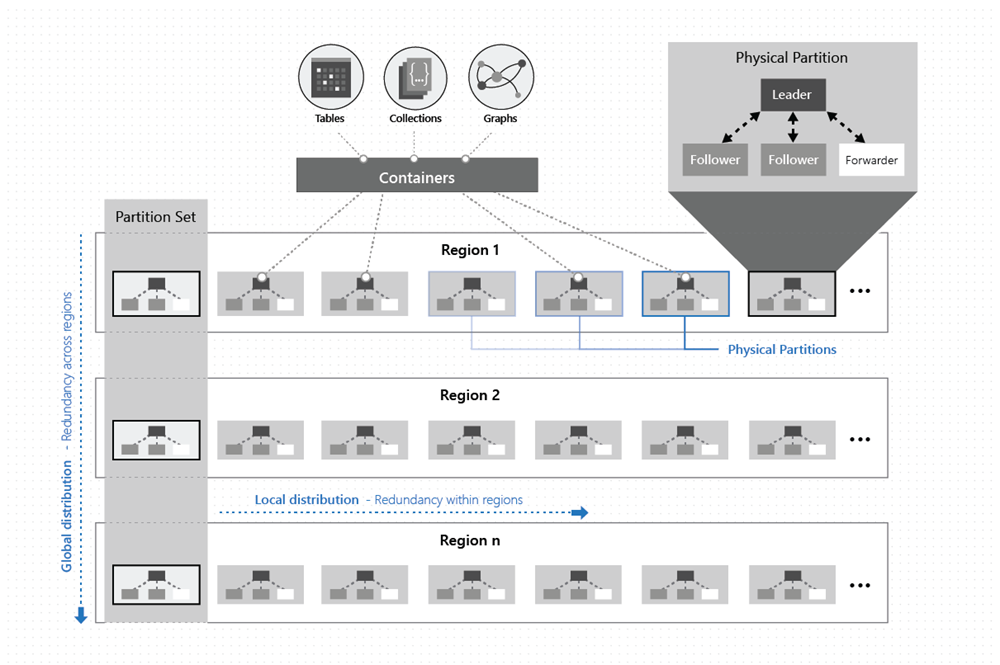
Eine physische Partition wird durch eine Gruppe von Replikaten implementiert, die als Replikatgruppe bezeichnet wird. Jeder Computer hostet Hunderte von Replikaten für verschiedene physische Partitionen innerhalb eines festen Satzes von Prozessen, wie in der Abbildung oben gezeigt. Die zu den physischen Partitionen gehörenden Replikate werden dynamisch und mit Lastenausgleich auf die Computer in einem Cluster sowie die Rechenzentren in einer Region verteilt.
Ein Replikat gehört eindeutig zu einem Azure Cosmos DB-Mandanten. Jedes Replikat hostet eine Instanz der Datenbank-Engine von Azure Cosmos DB, die die Ressourcen und die zugehörigen Indizes verwaltet. Die Datenbank-Engine von Azure Cosmos DB arbeitet nach einem ARS-basierten (Atom Record Sequence) Typsystem. Die Engine ist unabhängig von jeglichem Schema und verwischt damit die Grenzen zwischen der Struktur und den Instanzwerten von Datensätzen. Vollständige Schemaunabhängigkeit erreicht Azure Cosmos DB durch die automatische und effiziente Indizierung aller Elemente schon bei der Erfassung. Damit können Benutzer ihre global verteilten Daten abfragen, ohne sich um das Schema oder die Indexverwaltung kümmern zu müssen.
Die Datenbank-Engine von Azure Cosmos DB besteht aus Komponenten. Dazu gehören die Implementierung verschiedener Koordinationselemente, Language Runtimes, der Abfrageprozessor und die Untersysteme, die für die transaktionale Speicherung und Indizierung der Daten verantwortlich sind. Zu Gewährleistung von Dauerhaftigkeit und Hochverfügbarkeit speichert die Datenbank-Engine ihre Daten und ihren Index auf SSD-Datenträgern und repliziert sie mit anderen Instanzen der Datenbank-Engine innerhalb der Replikatgruppen. Größere Mandanten benötigen mehr Durchsatz und Speicherplatz und verfügen daher über größere und/oder mehr Replikate. Jede Komponente des Systems ist vollständig asynchron: Kein Thread wird jemals gesperrt, und jeder Thread verrichtet kurzfristige Aufgaben, die keine unnötigen Threadwechsel erfordern. Ratenlimits und Rückstaus werden auf den gesamten Stapel von der Erfassungssteuerung bis zu allen E/A-Pfaden aufgeteilt. Die Azure Cosmos DB-Datenbank-Engine ist darauf ausgelegt, Parallelität präzise zu steuern und für einen hohen Durchsatz zu sorgen und dabei minimale Systemressourcen zu verbrauchen.
Die globale Verteilung von Azure Cosmos DB beruht auf zwei wichtigen Abstraktionen: Replikatgruppen und Partitionsgruppen. Eine Replikatgruppe ist ein modularer Lego-Stein für die Steuerung, und eine Partitionsgruppe ist eine dynamische Überlagerung einer oder mehrerer geografisch verteilter physischer Partitionen. Damit Sie verstehen können, wie die globale Verteilung funktioniert, müssen Sie diese beiden Abstraktionen verstanden haben.
Replikatgruppen
Eine physische Partition ist eine selbst verwaltete Gruppe von Replikaten mit dynamischem Lastenausgleich, die auf mehrere Fehlerdomänen (als „Replikatgruppe“ bezeichnet) verteilt sind. Die Gruppe implementiert gemeinsam das Protokoll mit dem replizierten Zustand des Computers, damit die Daten in der physischen Partition hochverfügbar, dauerhaft und konsistent bleiben. Die Mitgliedschaft N in der Replikatgruppe ist dynamisch: Sie variiert basierend auf den Ausfällen, Verwaltungsvorgängen und der Zeit für die Neuerstellung/Wiederherstellung von fehlerhaften Replikaten zwischen NMin und NMax. Je nach der Art der Mitgliedschaftsänderung konfiguriert das Replikationsmodell auch die Quorumgröße für Lese- und Schreibvorgänge neu. Für eine einheitliche Verteilung des Durchsatzes, der einer bestimmten physischen Partition zugewiesen ist, gelten zwei Paradigmen:
Zum einen ist der Aufwand für die Verarbeitung der Schreibanforderungen an den Leader höher als die Kosten für die Anwendung von Updates auf die Follower. Aus diesem Grund werden dem Leader mehr Systemressourcen als den Followern zugewiesen.
Zum anderen wird das Lesequorum für eine bestimmte Konsistenzstufe so weit wie möglich ausschließlich aus Followerreplikaten zusammengestellt. Wir vermeiden es, den Leiter zu kontaktieren, um Lesungen durchzuführen, es sei denn, dies ist erforderlich. Wir nutzen eine Reihe von Ideen aus der Forschung zur Beziehung zwischen Last und Kapazität in quorumbasierten Systemen für die fünf Konsistenzmodelle, die von Azure Cosmos DB unterstützt werden.
Partitionsgruppen
Eine Gruppe physischer Partitionen (jeweils eine aus jeder für die Azure Cosmos DB-Datenbank konfigurierten Region) dient der Verwaltung derselben Schlüsselsätze, die in allen konfigurierten Regionen repliziert werden. Dieses höhere Koordinationselement wird als Partitionsgruppe bezeichnet. Es stellt eine geografisch verteilte, dynamische Überlagerung der physischen Partitionen für die Verwaltung eines bestimmten Schlüsselsatzes dar. Während der Gültigkeitsbereich einer physischen Partition (einer Replikatgruppe) auf einen Cluster beschränkt ist, kann eine Partitionsgruppe Cluster, Rechenzentren und geografische Regionen überschreiten, wie die folgende Abbildung zeigt:
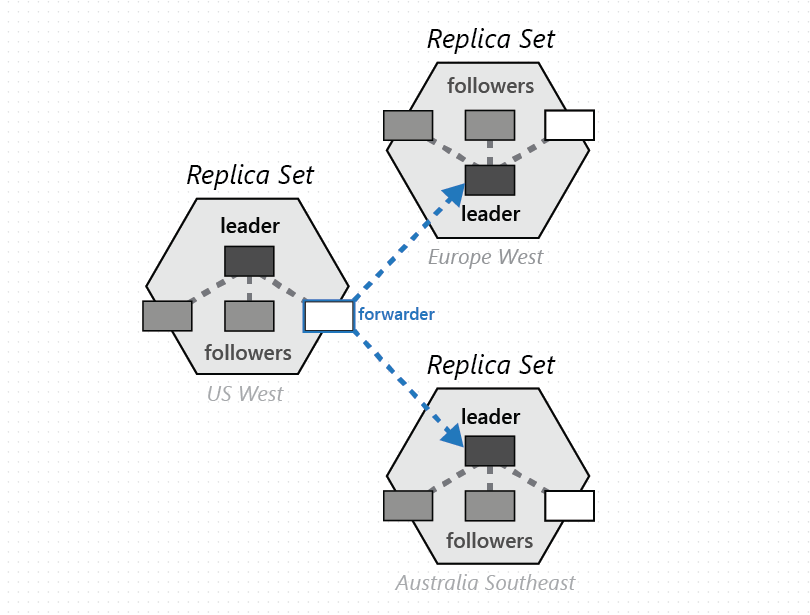
Sie können sich eine Partitionsgruppe als eine geografisch verteilte „Superreplikatgruppe“ vorstellen, die mehrere Replikatgruppen mit denselben Schlüsselsätzen umfasst. Wie bei einer Replikatgruppe ist auch bei einer Partitionsgruppe die Mitgliedschaft dynamisch. Sie variiert in Abhängigkeit von impliziten Vorgängen zur Verwaltung physischer Partitionen beim Hinzufügen/Entfernen von Partitionen in einer Partitionsgruppe (wenn Sie z. B. den Durchsatz in einem Container aufskalieren, in Ihrer Azure Cosmos DB-Datenbank eine Region hinzufügen/entfernen, oder bei Ausfällen). Damit die einzelnen Partitionen (einer Partitionsgruppe) die festgelegte Mitgliedschaft in der eigenen Replikatgruppe verwalten können, ist die Mitgliedschaft vollständig dezentralisiert und hochverfügbar angelegt. Während der Neukonfiguration einer Partitionsgruppe wird auch die Topologie der Überlagerung zwischen physischen Partitionen eingerichtet. Die Topologie wird dynamisch basierend auf der Konsistenzstufe, dem geografischen Abstand und der zwischen den physischen Quell- und Zielpartitionen verfügbaren Netzwerkbandbreite ausgewählt.
Der Dienst ermöglicht es Ihnen, Ihre Azure Cosmos DB-Datenbanken mit einer einzelnen oder mit mehreren Schreibregionen zu konfigurieren. Je nach Ihrer Auswahl werden die Partitionsgruppen so konfiguriert, dass sie Schreibanforderungen in genau einer oder in allen Regionen zulassen. Das System nutzt ein geschachteltes Konsensprotokoll mit zwei Ebenen: Eine Ebene agiert in den Replikaten einer Replikatgruppe einer physischen Partition, die Schreibanforderungen akzeptiert, und die andere agiert auf der Ebene der Partitionsgruppe, um alle committeten Schreibvorgänge in der Partitionsgruppe zu garantierten. Dieser geschachtelte Multiebenenkonsens ist sehr wichtig für die Implementierung unserer strikten SLAs für Hochverfügbarkeit sowie der Konsistenzmodelle, die Azure Cosmos DB den Kunden bietet.
Konfliktlösung
Unser Ansatz zur Updateverteilung, Konfliktlösung und Ursachenverfolgung beruht auf der Vorarbeit zu epidemischen Algorithmen und dem Bayou-System. Teile dieser Ideen haben überlebt und stellen einen passenden Referenzrahmen für die Beschreibung des Systementwurfs von Azure Cosmos DB dar, sie haben aber auch eine erhebliche Transformation durchlaufen, während sie auf das Azure Cosmos DB-System übertragen wurden. Diese Anpassungen waren erforderlich, da bei früheren Systemen weder die Ressourcenverwaltung noch die angestrebte Zielskalierung von Azure Cosmos DB noch die erforderlichen Funktionen (z. B. Konsistenz mit begrenzter Veraltung) gegeben waren. Auch konnten ohne die Änderungen die strikten und umfassenden SLAs von Azure Cosmos DB für die Kunden nicht erreicht werden.
Denken Sie sich daran, dass eine Partitionsgruppe über mehrere Regionen verteilt ist und das Replikationsprotokoll (für Schreibvorgänge für mehrere Regionen) von Azure Cosmos DB bei der Replikation der Daten auf den physischen Partitionen einer Partitionsgruppe befolgt. Jede physische Partition (einer Partitionsgruppe) akzeptiert Schreibanforderungen und verarbeitet Leseanforderungen in der Regel für die Clients in derselben Region. Die von einer physischen Partition akzeptierten Schreibanforderungen innerhalb einer Region werden dauerhaft committet und innerhalb der physischen Partition hochverfügbar gemacht, bevor sie dem Client bestätigt werden. Dies sind vorläufige Schreibvorgänge, die über einen Anti-Entropie-Kanal an andere physische Partitionen in der Partitionsgruppe übermittelt werden. Clients können über einen Anforderungsheader vorläufige oder committete Schreibvorgänge anfordern. Die Anti-Entropie-Übertragung ist (einschließlich ihrer Häufigkeit) dynamisch. Sie basiert auf der Topologie der Partitionsgruppe, der regionalen Nähe der physischen Partitionen und der konfigurierten Konsistenzstufe. Innerhalb einer Partitionsgruppe befolgt Azure Cosmos DB ein Schema mit einem primären Commit mit einer dynamisch ausgewählten Vermittlungspartition. Die Vermittlungsauswahl ist dynamisch und ein integraler Bestandteil der Neukonfiguration der Partitionsgruppe basierend auf der Topologie der Überlagerung. Für die committeten Schreibvorgänge (einschließlich mehrzeiliger/Batchupdates) wird die Sortierung garantiert.
Wir nutzen codierte Vektoruhren (mit Regions-ID und logischen Taktungen für die einzelnen Konsensstufen der Replikat- bzw. Partitionsgruppe) für die Ursachenverfolgung und Versionsvektoren für das Erkennen und Beheben von Updatekonflikten. Die Topologie und der Peerauswahlalgorithmus sollen sicherstellen, dass für die Versionsvektoren nur ein fester und sehr geringer Mehraufwand in Bezug auf Speicher und Netzwerk entsteht. Der Algorithmus garantiert strikte Konvergenz.
Für Azure Cosmos DB-Datenbanken, die mit mehreren Schreibregionen konfiguriert wurden, stellt das System Entwicklern eine Reihe flexibler automatischer Richtlinien für die Konfliktlösung bereit, einschließlich:
- Letzter Schreibvorgang gewinnt (Last-Write-Wins, LWW) nutzt standardmäßig eine vom System definierte Zeitstempeleigenschaft (die auf dem Protokoll zur Zeitsynchronisierung basiert). Azure Cosmos DB erlaubt auch die Angabe einer anderen benutzerdefinierten numerischen Eigenschaft für die Konfliktlösung.
- Anwendungsdefinierte (benutzerdefinierte) Richtlinie zur Konfliktlösung (über Mergeprozeduren ausgedrückt), die durch die Anwendung angegeben wird und dafür vorgesehen ist, Konflikte anwendungsdefiniert semantisch zu lösen. Diese Prozeduren werden bei Erkennung eines Schreib-Schreib-Konflikts im Rahmen einer Datenbanktransaktion auf Serverseite aufgerufen. Das System garantiert genau eine Ausführung der Mergeprozedur im Rahmen des Commitprotokolls. Ihnen stehen viele Konfliktlösungsbeispiele zum Testen zur Auswahl.
Konsistenzmodelle
Unabhängig davon, ob Sie Ihre Azure Cosmos DB-Datenbank mit einer Schreibregion oder mehreren Schreibregionen konfigurieren, können Sie unter fünf genau definierten Konsistenzmodellen wählen. Mit mehreren Schreibregionen sollten die folgenden Aspekte von Konsistenzstufen berücksichtigt werden:
Die Konsistenz mit begrenzter Veraltung garantiert, dass alle Lesevorgänge innerhalb von k Präfixen oder t Sekunden nach dem letzten Schreibvorgang in einer der Regionen liegen. Darüber hinaus werden für Lesevorgänge mit Konsistenz mit begrenzter Veraltung Monotonie und konsistente Präfixe garantiert. Das Anti-Entropie-Protokoll wird mit Ratenlimit ausgeführt. Es stellt sicher, dass die Präfixe sich nicht anhäufen und dass der Rückstau bei den Schreibanforderungen nicht angewandt werden muss. Sitzungskonsistenz garantiert monotone Lesevorgänge, monotone Schreibvorgänge, Lesen eigener Schreibvorgänge (RYOW), Write-Follows-Read und konsistente Präfixe weltweit. Für die mit starker Konsistenz konfigurierten Datenbanken gelten die Vorteile (geringe Schreiblatenz, hohe Schreibverfügbarkeit) mehrerer Schreibregionen aufgrund der Regionen übergreifenden synchronen Replikation nicht.
Die Semantik der fünf Konsistenzmodelle in Azure Cosmos DB wird hier beschrieben und hier mathematisch anhand einer TLA+-Spezifikation auf hoher Ebene erläutert.
Nächste Schritte
Als nächstes erfahren Sie, wie Sie die globale Verteilung konfigurieren, indem Sie die folgenden Artikel verwenden:
- Hinzufügen/Entfernen von Regionen für Ihr Datenbankkonto
- Erstellen einer benutzerdefinierten Konfliktlösungsrichtlinie
- Versuchen Sie, die Kapazitätsplanung für eine Migration zu Azure Cosmos DB durchzuführen? Sie können Informationen zu Ihrem vorhandenen Datenbankcluster für die Kapazitätsplanung verwenden.
- Wenn Sie nur die Anzahl der virtuellen Kerne und Server in Ihrem vorhandenen Datenbankcluster kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mithilfe von virtuellen Kernen oder virtuellen CPUs
- Wenn Sie die typischen Anforderungsraten für Ihre aktuelle Datenbankworkload kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mit dem Azure Cosmos DB-Kapazitätsplaner