Behandeln häufiger Probleme in Azure Cosmos DB for Apache Cassandra
GILT FÜR: ![]() Cassandra
Cassandra
Die API für Cassandra in Azure Cosmos DB ist eine Kompatibilitätsebene, die Wire Protocol-Unterstützung für die Open-Source-Datenbank Apache Cassandra bereitstellt.
In diesem Artikel werden häufige Fehler und deren Lösungen für Anwendungen beschrieben, die Azure Cosmos DB for Apache Cassandra verwenden. Wenn Ihr Fehler nicht aufgeführt ist und beim Ausführen eines unterstützten Vorgangs in Cassandra ein Fehler auftritt, der bei Verwendung von nativem Apache Cassandra jedoch nicht auftritt, erstellen Sie eine Azure-Supportanfrage.
Hinweis
Als vollständig verwalteter cloudnativer Dienst bietet Azure Cosmos DB Garantien für Verfügbarkeit, Durchsatz und Konsistenz für die API für Cassandra. Außerdem ermöglicht die API für Cassandra die Ausführung von Plattformvorgängen ohne Wartung und ein Patchen ohne Ausfallzeiten.
Diese Garantien sind in früheren Implementierungen von Apache Cassandra nicht möglich, sodass sich viele der Back-End-Vorgänge der API für Cassandra von Apache Cassandra unterscheiden. Zur Vermeidung häufiger Fehler werden bestimmte Einstellungen und Methoden empfohlen.
NoNodeAvailableException
Bei diesem Fehler handelt es sich um eine übergeordnete Wrapperausnahme mit einer Vielzahl möglicher Ursachen und innerer Ausnahmen, von denen viele mit dem Client zusammenhängen können.
Häufige Ursachen und Lösungen:
Leerlauftimeout von Azure Load Balancer-Instanzen: Dieses Problem kann auch in Form von
ClosedConnectionExceptionauftreten. Zur Behebung des Problems legen Sie die Keep-Alive-Einstellung im Treiber fest (siehe Aktivieren von Keep-Alive für den Java-Treiber) und erhöhen die Keep-Alive-Einstellungen in Ihrem Betriebssystem. Sie können auch das Leerlauftimeout in Azure Load Balancer anpassen.Ressourcenauslastung der Clientanwendung: Vergewissern Sie sich, dass die Clientcomputer über genügend Ressourcen verfügen, um die Anforderung abzuwickeln.
Verbindungsherstellung mit einem Host nicht möglich
Möglicherweise wird folgende Fehlermeldung angezeigt: „Cannot connect to any host, scheduling retry in 600000 milliseconds.“ (Es kann keine Verbindung mit einem Host hergestellt werden, Wiederholungsversuch in 600000 Millisekunden geplant.)
Dieser Fehler wird möglicherweise durch eine clientseitige SNAT-Auslastung (Source Network Address Translation, Übersetzung der Quellnetzwerkadresse) verursacht. Gehen Sie wie unter Verwenden von SNAT für ausgehende Verbindungen beschrieben vor, um dieses Problem auszuschließen.
Bei dem Fehler kann sich aber auch um ein Leerlauftimeoutproblem handeln. (Das Leerlauftimeout von Azure Load Balancer ist standardmäßig auf vier Minuten festgelegt.) Weitere Informationen finden Sie unter Leerlauftimeout für Load Balancer. Aktivieren Sie Keep-Alive für den Java-Treiber, und legen Sie das keepAlive-Intervall für das Betriebssystem auf weniger als vier Minuten fest.
Weitere Möglichkeiten zur Behandlung der Ausnahme finden Sie unter Problembehandlung bei NoHostAvailableException.
OverloadedException (Java)
Anforderungen werden gedrosselt, da die Gesamtanzahl der verbrauchten Anforderungseinheiten höher ist als die Anzahl der Anforderungseinheiten, die Sie für den Keyspace oder die Tabelle bereitgestellt haben.
Sie sollten ggf. den Durchsatz, der einem Keyspace oder einer Tabelle zugewiesen ist, über das Azure-Portal skalieren (weitere Informationen finden Sie unter Elastisches Skalieren eines Azure Cosmos DB for Apache Cassandra-Kontos) oder eine Wiederholungsrichtlinie implementieren.
Informationen zu Java finden Sie unter den Beispielen für Wiederholungslogik für den v3.x-Treiber und den v4.x-Treiber. Weitere Informationen finden Sie auch unter Azure Cosmos DB for Apache Cassandra-Erweiterungen für Java.
OverloadedException trotz ausreichendem Durchsatz
Das System scheint Anforderungen zu drosseln, obwohl genügend Durchsatz für das Anforderungsvolumen oder die verbrauchten Anforderungseinheiten bereitgestellt wird. Es gibt zwei mögliche Ursachen:
Vorgänge auf Schemaebene: Die API für Cassandra implementiert bei Vorgängen auf Schemaebene (CREATE TABLE, ALTER TABLE, DROP TABLE) ein Budget für den Systemdurchsatz. Dieses Budget sollte für Schemavorgänge in einem Produktionssystem ausreichen. Bei einer sehr großen Anzahl von Vorgängen auf Schemaebene wird dieser Grenzwert möglicherweise überschritten.
Da das Budget nicht benutzergesteuert ist, sollte ggf. die Anzahl der ausgeführten Schemavorgänge verringert werden. Wenn das Problem dadurch nicht behoben wird oder diese Aktion für Ihre Workload nicht möglich ist, erstellen Sie eine Azure-Supportanfrage.
Datenschiefe: Wenn Durchsatz über die API für Cassandra bereitgestellt wird, wird er gleichmäßig auf physische Partitionen aufgeteilt, und jede physische Partition hat eine Obergrenze. Wenn bei Ihnen eine große Datenmenge von einer bestimmten Partition eingefügt oder abgefragt wird, kann es trotz Bereitstellung eines hohen Gesamtdurchsatzes (Anforderungseinheiten) für diese Tabelle zu einer Ratenbegrenzung kommen.
Überprüfen Sie Ihr Datenmodell, und vergewissern Sie sich, dass keine übermäßige Schiefe vorhanden ist, die zu heißen Partitionen führen kann.
Zeitweilige Verbindungsfehler (Java)
Die Verbindung wird unerwartet getrennt, oder es tritt ein Timeout auf.
Die Apache Cassandra-Treiber für Java bieten zwei native Richtlinien für die erneute Verbindungsherstellung: ExponentialReconnectionPolicy und ConstantReconnectionPolicy. Der Standardwert ist ExponentialReconnectionPolicy. Für Azure Cosmos DB for Apache Cassandra wird jedoch ConstantReconnectionPolicy mit einer Verzögerung von zwei Sekunden empfohlen.
Weitere Informationen finden Sie in der Dokumentation für den Java 4.x-Treiber, in der Dokumentation für den Java 3.x-Treiber oder in den Beispielen unter Konfigurieren von ReconnectionPolicy für die Java-Treiber.
Fehler im Zusammenhang mit der Lastenausgleichsrichtlinie
Möglicherweise haben Sie eine Lastenausgleichsrichtlinie in v3.x des Java-DataStax-Treibers implementiert und dabei Code wie den folgenden verwendet:
cluster = Cluster.builder()
.addContactPoint(cassandraHost)
.withPort(cassandraPort)
.withCredentials(cassandraUsername, cassandraPassword)
.withPoolingOptions(new PoolingOptions() .setConnectionsPerHost(HostDistance.LOCAL, 1, 2)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32000).setMaxQueueSize(Integer.MAX_VALUE))
.withSSL(sslOptions)
.withLoadBalancingPolicy(DCAwareRoundRobinPolicy.builder().withLocalDc("West US").build())
.withQueryOptions(new QueryOptions().setConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM))
.withSocketOptions(getSocketOptions())
.build();
Wenn der Wert für withLocalDc() nicht dem Rechenzentrum am Kontaktpunkt entspricht, tritt möglicherweise der folgende vorübergehende Fehler auf: com.datastax.driver.core.exceptions.NoHostAvailableException: All host(s) tried for query failed (no host was tried).
Implementieren Sie CosmosLoadBalancingPolicy. Damit dies funktioniert, müssen Sie möglicherweise DataStax mithilfe des folgenden Codes aktualisieren:
LoadBalancingPolicy loadBalancingPolicy = new CosmosLoadBalancingPolicy.Builder().withWriteDC("West US").withReadDC("West US").build();
Fehler beim Zählvorgang für eine große Tabelle
Wenn select count(*) from table oder ein ähnlicher Befehl für eine große Anzahl von Zeilen ausgeführt wird, tritt ein Servertimeout auf.
Wenn Sie einen lokalen CQLSH-Client verwenden, ändern Sie die Einstellung --connect-timeout oder --request-timeout zu ändern. Weitere Informationen finden Sie unter cqlsh: die CQL-Shell.
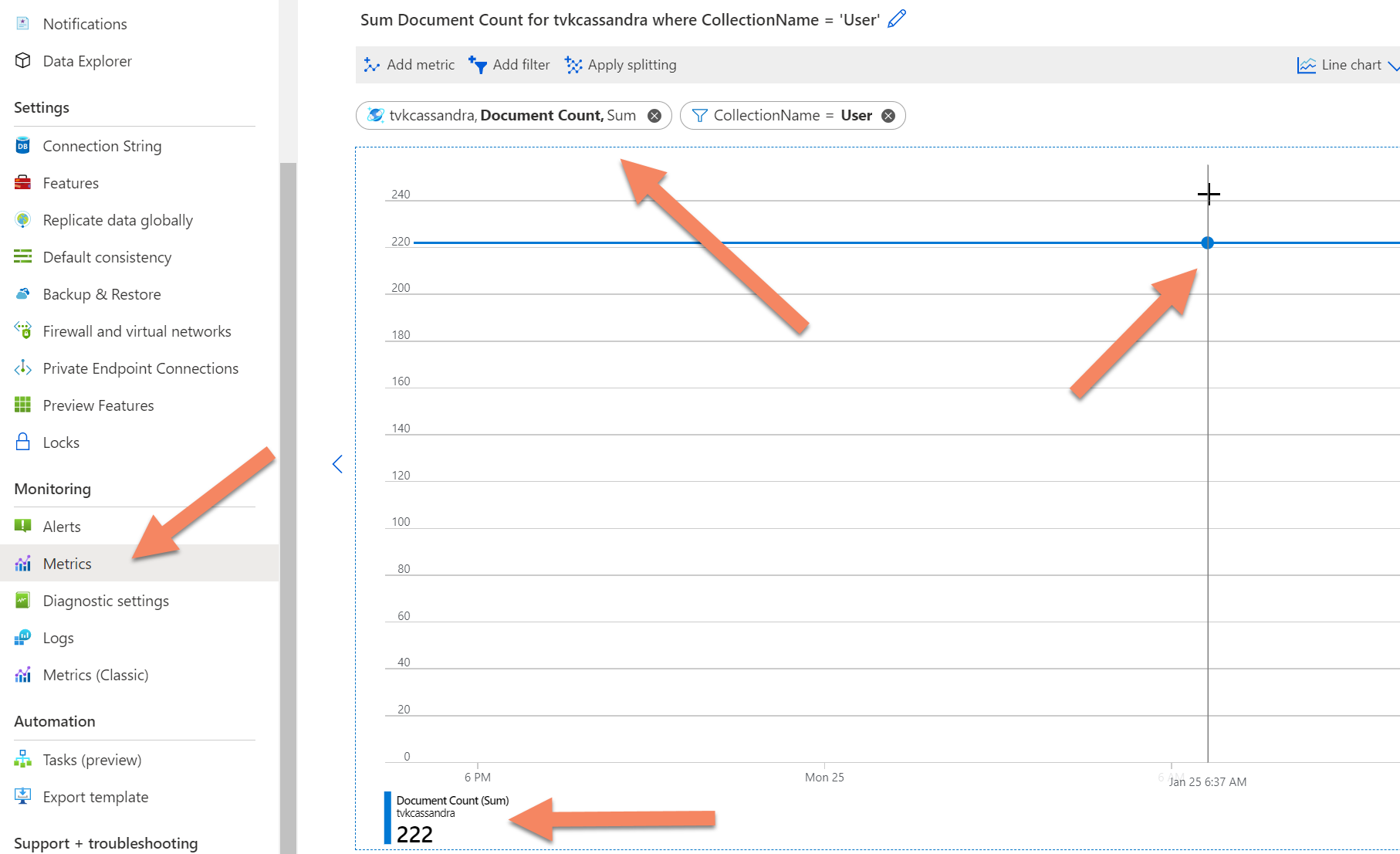
Sollte trotzdem weiterhin ein Timeout für den Zählvorgang auftreten, können Sie die Anzahl von Datensätzen über die Telemetriedaten des Azure Cosmos DB-Back-Ends abrufen. Wählen Sie hierzu im Azure-Portal auf der Registerkarte „Metriken“ die Metrik document count aus, und fügen Sie dann einen Filter für die Datenbank oder Sammlung (Entsprechung der Tabelle in Azure Cosmos DB) hinzu. In dem resultierenden Graphen können Sie dann auf den Zeitpunkt zeigen, für den Sie die Anzahl von Datensätzen ermitteln möchten.
Konfigurieren von ReconnectionPolicy für den Java-Treiber
Version 3.x
Bei Version 3.x des Java-Treibers konfigurieren Sie die Richtlinie für Verbindungswiederholungen beim Erstellen eines Clusterobjekts:
import com.datastax.driver.core.policies.ConstantReconnectionPolicy;
Cluster.builder()
.withReconnectionPolicy(new ConstantReconnectionPolicy(2000))
.build();
Version 4.x
Bei Version 4.x des Java-Treibers konfigurieren Sie die Richtlinie für Verbindungswiederholungen durch Überschreiben der Einstellungen in der Datei reference.conf:
datastax-java-driver {
advanced {
reconnection-policy{
# The driver provides two implementations out of the box: ExponentialReconnectionPolicy and
# ConstantReconnectionPolicy. We recommend ConstantReconnectionPolicy for API for Cassandra, with
# base-delay of 2 seconds.
class = ConstantReconnectionPolicy
base-delay = 2 second
}
}
Aktivieren von Keep-Alive für den Java-Treiber
Version 3.x
Bei Version 3.x des Java-Treibers legen Sie die Keep-Alive-Einstellung beim Erstellen eines Clusterobjekts fest. Sie müssen anschließend sicherstellen, dass Keep-Alive im Betriebssystem aktiviert ist:
import java.net.SocketOptions;
SocketOptions options = new SocketOptions();
options.setKeepAlive(true);
cluster = Cluster.builder().addContactPoints(contactPoints).withPort(port)
.withCredentials(cassandraUsername, cassandraPassword)
.withSocketOptions(options)
.build();
Version 4.x
Bei Version 4.x des Java-Treibers legen Sie die Keep-Alive-Einstellung durch Überschreiben der Einstellungen in reference.conf fest. Sie müssen anschließend sicherstellen, dass Keep-Alive im Betriebssystem aktiviert ist:
datastax-java-driver {
advanced {
socket{
keep-alive = true
}
}
Nächste Schritte
- Erfahren Sie mehr über unterstützte Features in Azure Cosmos DB for Apache Cassandra.
- Erfahren Sie, wie Sie vom nativen Apache Cassandra zu Azure Cosmos DB for Apache Cassandra migrieren.