Partitionierung in Azure Cosmos DB for Apache Cassandra
GILT FÜR: ![]() Cassandra
Cassandra
In diesem Artikel wird beschrieben, wie die Partitionierung in Azure Cosmos DB for Apache Cassandra funktioniert.
Die API für Cassandra nutzt die Partitionierung, um einzelne Tabellen in einem Keyspace entsprechend den Leistungsanforderungen Ihrer Anwendung zu skalieren. Partitionen werden basierend auf dem Wert des Partitionsschlüssels erstellt, der jedem Datensatz in einer Tabelle zugeordnet ist. Alle Datensätze in einer Partition haben denselben Partitionsschlüsselwert. Azure Cosmos DB verwaltet die Platzierung von Partitionen physischer Ressourcen transparent und automatisch, um die Anforderungen an Skalierbarkeit und Leistung der Tabelle effizient zu erfüllen. Wenn sich die Anforderungen einer Anwendung an Durchsatz und Speicher erhöhen, verschiebt Azure Cosmos DB Daten, sodass sie auf eine größere Anzahl physischer Computer verteilt werden.
Aus Entwicklersicht erfolgt die Partitionierung für Azure Cosmos DB for Apache Cassandra identisch wie für natives Apache Cassandra. Im Hintergrund gibt es jedoch einige Unterschiede.
Unterschiede zwischen Apache Cassandra und Azure Cosmos DB
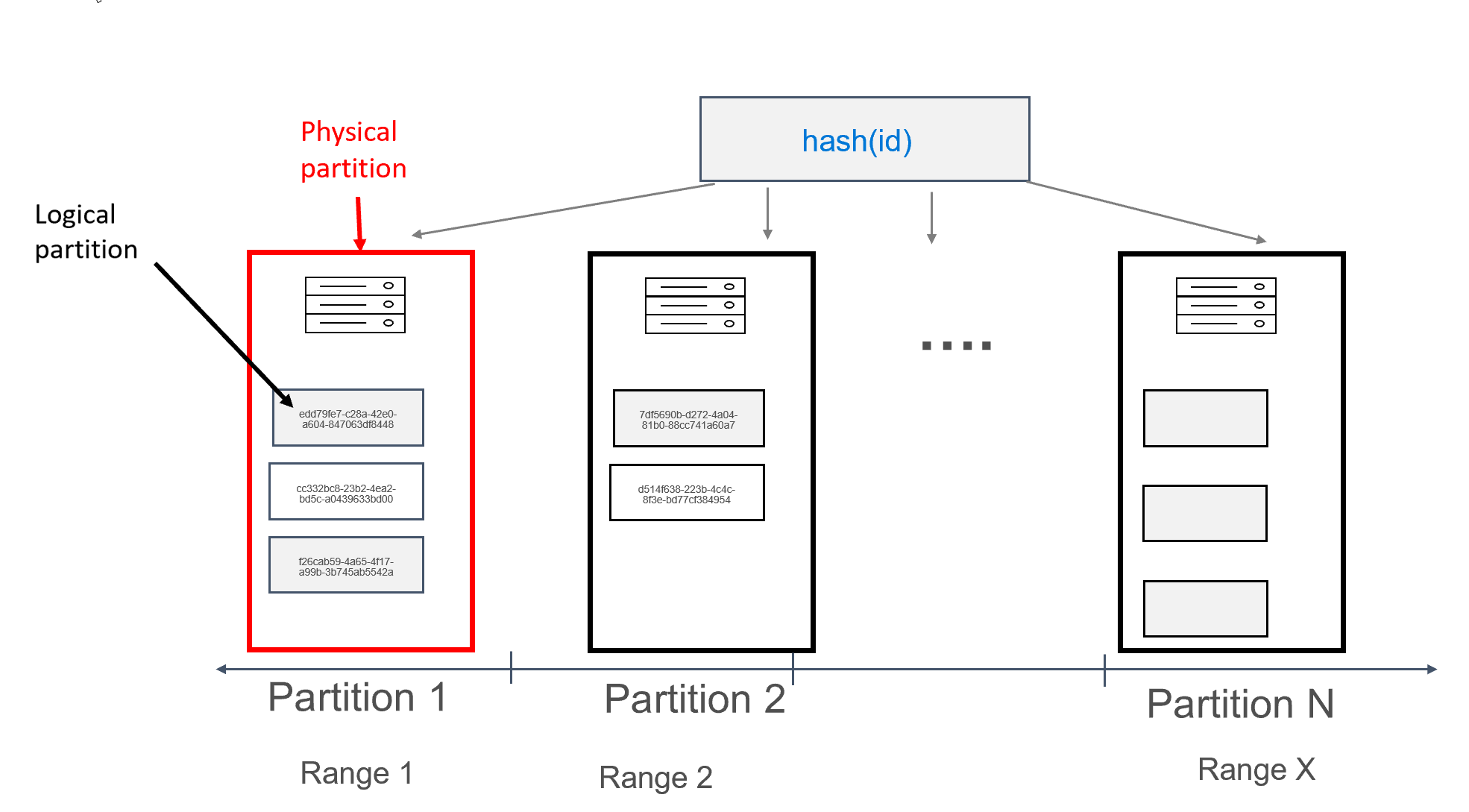
In Azure Cosmos DB wird jeder Computer, auf dem Partitionen gespeichert sind, als eine physische Partition bezeichnet. Die physische Partition ähnelt einem virtuellen Computer, einer dedizierten Compute-Einheit oder eine Gruppe physischer Ressourcen. Jede in dieser Compute-Einheit gespeicherte Partition wird in Azure Cosmos DB als logische Partition bezeichnet. Wenn Sie bereits mit Apache Cassandra vertraut sind, können Sie sich logische Partitionen wie reguläre Partitionen in Cassandra vorstellen.
Apache Cassandra empfiehlt für die Datenmenge, die in einer Partition gespeichert werden kann, eine Größenbeschränkung von 100 MB. Die API für Cassandra für Azure Cosmos DB lässt bis zu 20 GB Daten pro logischer Partition und bis zu 30 GB Daten pro physischer Partition zu. In Azure Cosmos DB wird die in der physischen Partition verfügbare Computekapazität im Gegensatz zu Apache Cassandra mithilfe der speziellen Metrik Anforderungseinheit ausgedrückt, sodass Sie Ihre Workload nach Anforderungen pro Sekunde (Lese- oder Schreibvorgänge) und nicht nach Kernen, Arbeitsspeicher oder IOPS definieren. Dies vereinfacht die Kapazitätsplanung, sofern Sie die Kosten der einzelnen Anforderungen verstanden haben. Für jede physische Partition können bis zu 10.000 RUs an Computekapazität bereitgestellt werden. Weitere Informationen zu Skalierbarkeitsoptionen finden Sie im Artikel zur elastischen Skalierung in der API für Cassandra.
In Azure Cosmos DB besteht jede physische Partition aus einem Satz von Replikaten (auch als Replikatgruppen bezeichnet), wobei jede Partition mindestens 4 Replikate aufweist. Bei Apache Cassandra können Sie im Gegensatz dazu zwar einen Replikationsfaktor von 1 festlegen, dies führt jedoch zu einer geringeren Verfügbarkeit, wenn der einzige Knoten mit den Daten ausfällt. In der API für Cassandra ist der Replikationsfaktor stets 4 (Quorum von 3). Azure Cosmos DB verwaltet Replikatgruppen automatisch, während sie in Apache Cassandra mithilfe verschiedener Tools verwaltet werden müssen.
Apache Cassandra verfügt über ein Konzept von Token, bei denen es sich um Hashwerte von Partitionsschlüsseln handelt. Die Token basieren auf einem murmur3-64-Byte-Hash mit Werten im Bereich von –2^63 bis –2^63 – 1. Dieser Bereich wird in Apache Cassandra meist als „Tokenring“ bezeichnet. Der Tokenring ist in Tokenbereiche unterteilt, und diese Bereiche werden unter den Knoten in einem nativen Apache Cassandra-Cluster aufgeteilt. In Azure Cosmos DB wird die Partitionierung auf ähnliche Weise implementiert, mit der Ausnahme, dass ein anderer Hashalgorithmus und ein größerer interner Tokenring verwendet wird. Extern machen wir jedoch denselben Tokenbereich verfügbar wie Apache Cassandra, d. h. -2^63 to -2^63 - 1.
Primary key (Primärschlüssel)
Für alle Tabellen in der API für Cassandra muss ein primary key definiert sein. Die Syntax für einen Primärschlüssel ist unten dargestellt:
column_name cql_type_definition PRIMARY KEY
Angenommen, Sie möchten eine Benutzertabelle erstellen, in der Nachrichten für verschiedene Benutzer gespeichert werden:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
Bei diesem Entwurf wurde das Feld id als Primärschlüssel definiert. Der Primärschlüssel fungiert als Bezeichner für den Datensatz in der Tabelle und wird darüber hinaus in Azure Cosmos DB auch als Partitionsschlüssel verwendet. Wenn der Primärschlüssel auf die beschriebene Weise definiert ist, gibt es in jeder Partition nur einen einzelnen Datensatz. Dies führt beim Schreiben von Daten in die Datenbank zu einer perfekt horizontalen und skalierbaren Verteilung und eignet sich damit ideal für Anwendungsfälle mit Schlüsselwertsuchen. Die Anwendung sollte beim Lesen von Daten aus der Tabelle den Primärschlüssel angeben, um die Leseleistung zu maximieren.
Zusammengesetzter Primärschlüssel
Apache Cassandra bietet auch das Konzept von compound keys. Ein zusammengesetzter primary key besteht aus mehreren Spalten. Die erste Spalte ist der partition key, und alle weiteren Spalten sind clustering keys. Die Syntax für den compound primary key ist unten dargestellt:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Angenommen, Sie möchten den oben beschriebenen Entwurf ändern, um Nachrichten für einen bestimmten Benutzer effizient abrufen zu können:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
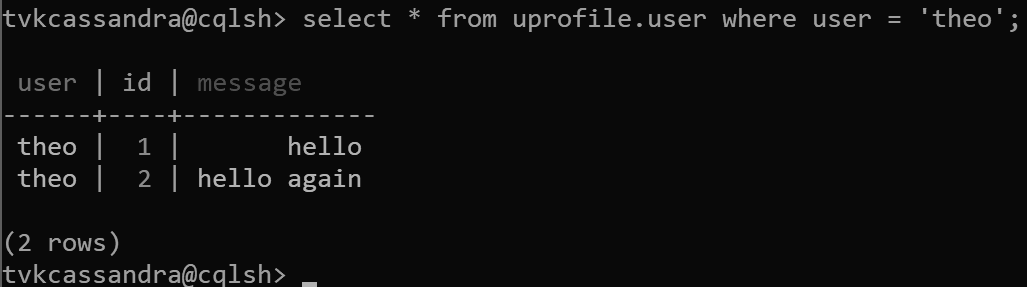
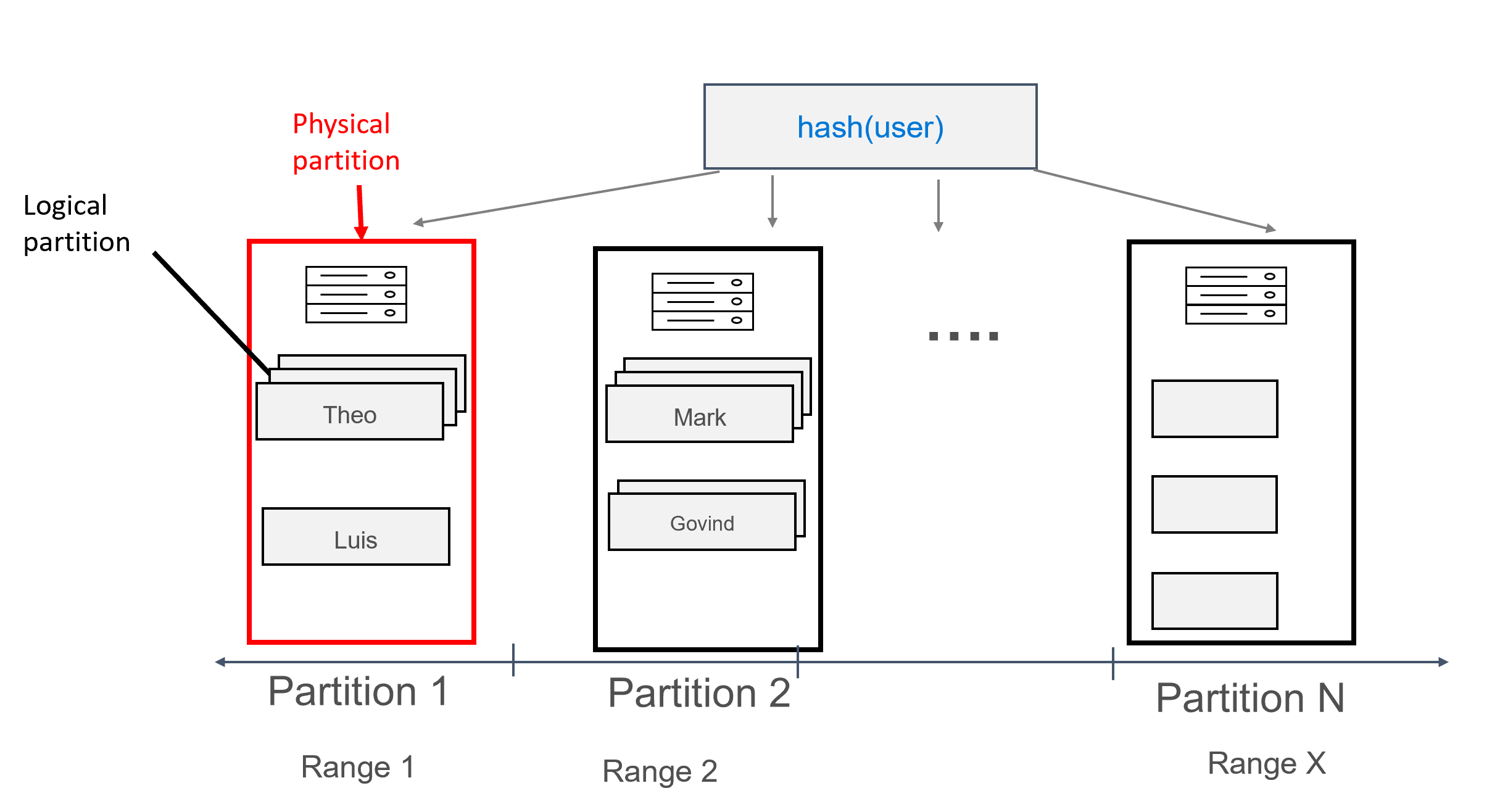
In diesem Entwurf definieren Sie nun user als Partitionsschlüssel und id als Clusteringschlüssel. Sie können beliebig viele Clusteringschlüssel definieren, aber jeder Wert (oder jede Kombination von Werten) für den Clusteringschlüssel muss eindeutig sein, damit derselben Partition mehrere Datensätze hinzugefügt werden können. Beispiel:
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Wenn Daten zurückgegeben werden, werden diese, wie in Apache Cassandra erwartet, nach dem Clusteringschlüssel sortiert:
Warnung
Stellen Sie beim Abfragen von Daten in einer Tabelle mit einem zusammengesetzten Primärschlüssel sicher, dass Sie explizit einen sekundären Index für den Partitionsschlüssel hinzufügen, wenn Sie nach dem Partitionsschlüssel und anderen nicht indizierten Feldern (abgesehen vom Clusterschlüssel) filtern möchten:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB for Apache Cassandra wendet standardmäßig keine Indizes auf Partitionsschlüssel an, und der Index in diesem Szenario kann die Abfrageleistung erheblich verbessern. Weitere Informationen finden Sie in unserem Artikel zur sekundären Indizierung.
Mit einem solchen Datenmodell können jeder Partition mehrere Datensätze gruppiert nach Benutzer zugewiesen werden. Sie können daher eine Abfrage ausgeben, die durch den partition key (in diesem Fall user) effizient weitergeleitet wird, um alle Nachrichten für einen bestimmten Benutzer abzurufen.
Zusammengesetzter Partitionsschlüssel
Zusammengesetzte Partitionsschlüssel funktionieren im Wesentlichen genauso wie zusammengesetzte Schlüssel, mit dem Unterschied, dass Sie mehrere Spalten als einen zusammengesetzten Partitionsschlüssel angeben können. Die Syntax zusammengesetzter Partitionsschlüssel wird unten dargestellt:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Sie können z. B. mit der folgenden eindeutigen Kombination aus firstname und lastname den Partitionsschlüssel bilden und id als Clusteringschlüssel verwenden:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Nächste Schritte
- Erfahren Sie mehr über Partitionierung und horizontale Skalierung in Azure Cosmos DB.
- Erfahren Sie mehr über den bereitgestellten Durchsatz in Azure Cosmos DB.
- Erfahren Sie mehr über die globale Verteilung in Azure Cosmos DB.