Datenagnostische Erfassungsmodul
In diesem Artikel wird erläutert, wie Sie in Azure Data Factory datenagnostische Ingestion Engine-Szenarien mithilfe einer Kombination aus PowerApps, Azure Logic Apps und metadatengesteuerten Kopieraufgaben implementieren können.
Datenagnostische Erfassungsmodulszenarios konzentrieren sich in der Regel auf die Möglichkeit, nicht technische (nicht datentechnische) Benutzer*innen Datenressourcen in einem Data Lake für die weitere Verarbeitung zu veröffentlichen. Um dieses Szenario zu implementieren, müssen Sie über Onboardingfunktionen verfügen, die Folgendes aktivieren:
- Datenobjektregistrierung
- Workflowbereitstellung und Metadatenerfassung
- Erfassungsplanung
Sie können sehen, wie diese Funktionen interagieren:
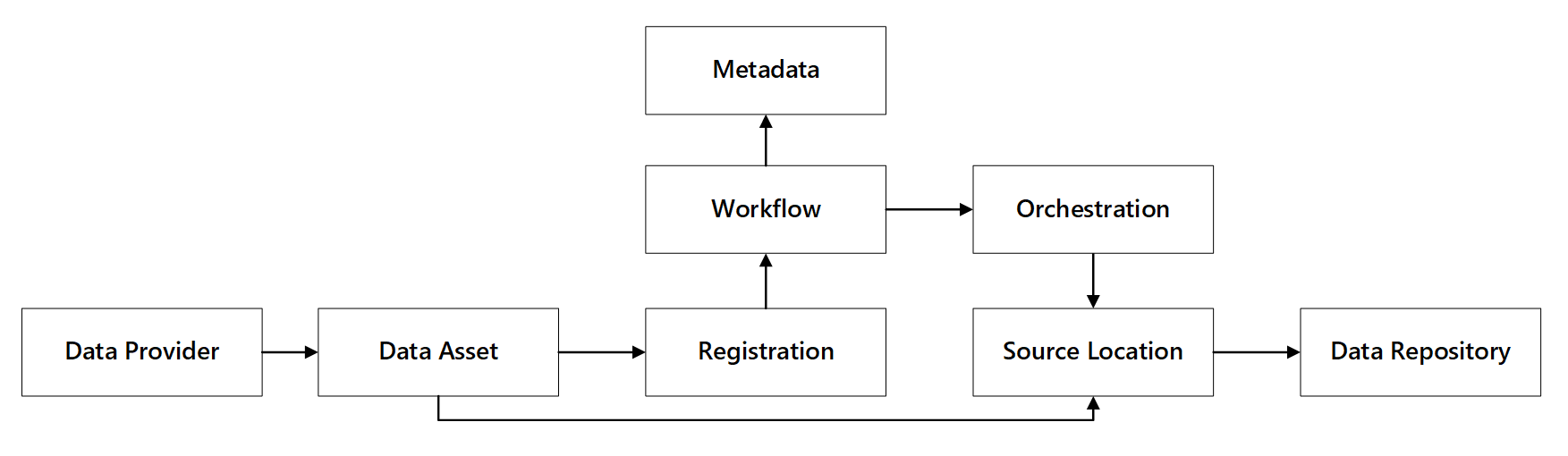
Abbildung 1: Interaktionen mit Datenregistrierungsfunktionen.
Das folgende Diagramm zeigt, wie Sie diesen Prozess mithilfe einer Kombination von Azure-Diensten implementieren:
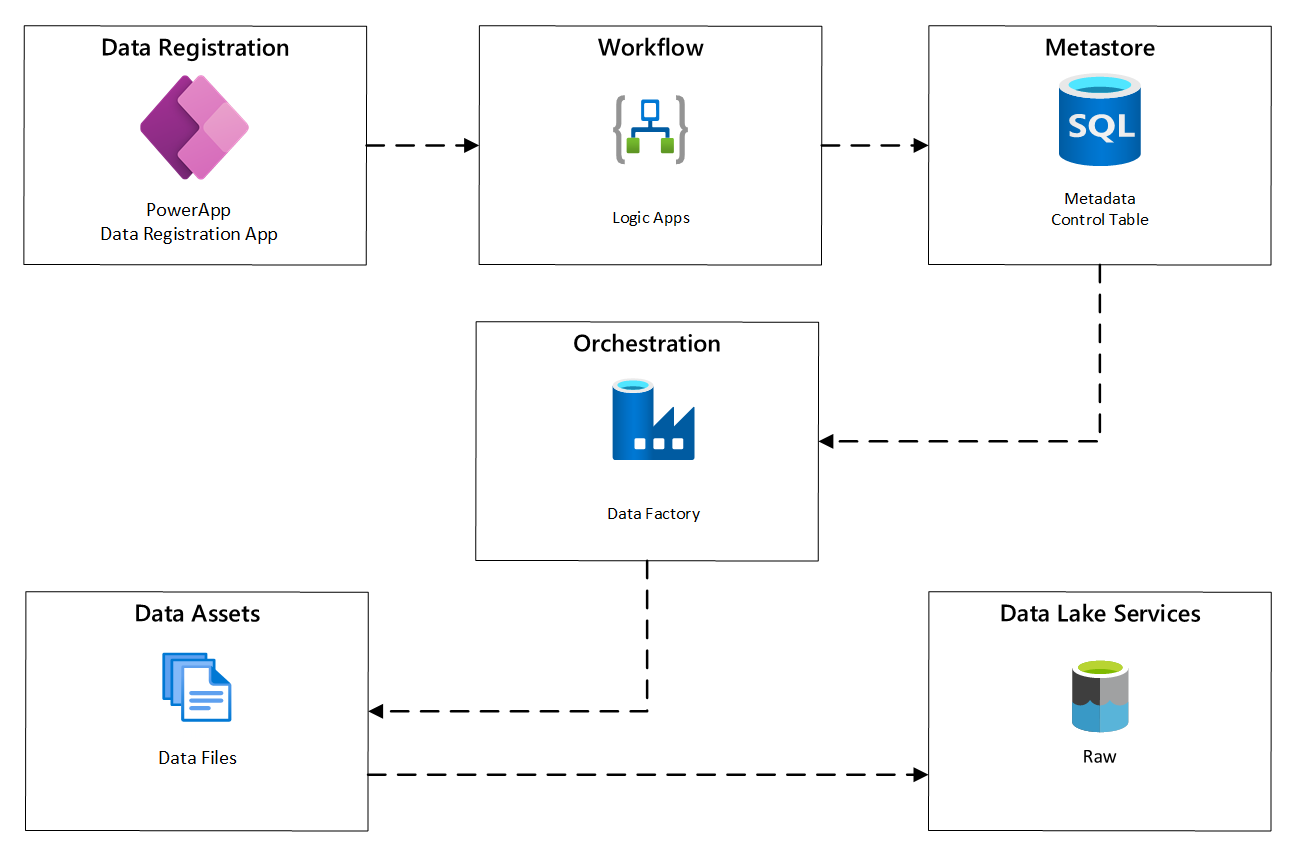
Abbildung 2: Automatisierter Erfassungsprozess.
Datenobjektregistrierung
Um die Metadaten bereitzustellen, die zum Steuern der automatisierten Erfassung verwendet werden, benötigen Sie die Registrierung von Datenobjekten. Die erfassten Informationen enthalten:
- Technische Informationen: Datenobjektname, Quellsystem, Typ, Format und Häufigkeit.
- Governanceinformationen: Besitzer*in, Verwalter*innen, Sichtbarkeit (zur Ermittlung) und Vertraulichkeit.
PowerApps wird verwendet, um Metadaten zu erfassen, die jede Datenressource beschreiben. Verwenden Sie eine modellgesteuerte App, um die Informationen einzugeben, die in einer benutzerdefinierten Dataverse-Tabelle beibehalten werden. Wenn Metadaten innerhalb von Dataverse erstellt oder aktualisiert werden, löst sie einen automatisierten Cloudfluss aus, der weitere Verarbeitungsschritte aufruft.
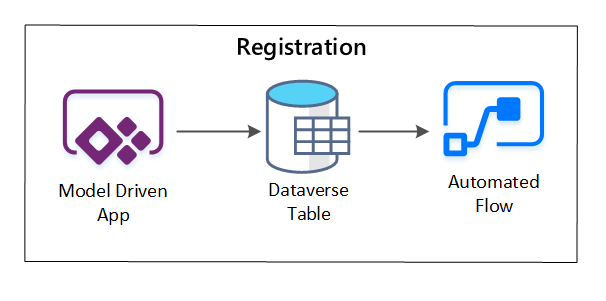
Abbildung 3: Registrierung von Datenobjekten.
Bereitstellungsworkflow/Metadatenerfassung
In der Bereitstellungsworkflowstufe überprüfen und beibehalten Sie Daten, die in der Registrierungsstufe im Metastore gesammelt wurden. Sowohl technische als auch geschäftliche Validierungsschritte werden ausgeführt, einschließlich:
- Überprüfung des Eingabedatenfeeds
- Auslösen des Genehmigungsworkflows
- Logikverarbeitung zum Auslösen der Persistenz von Metadaten im Metadatenspeicher
- Aktivitätsüberwachung
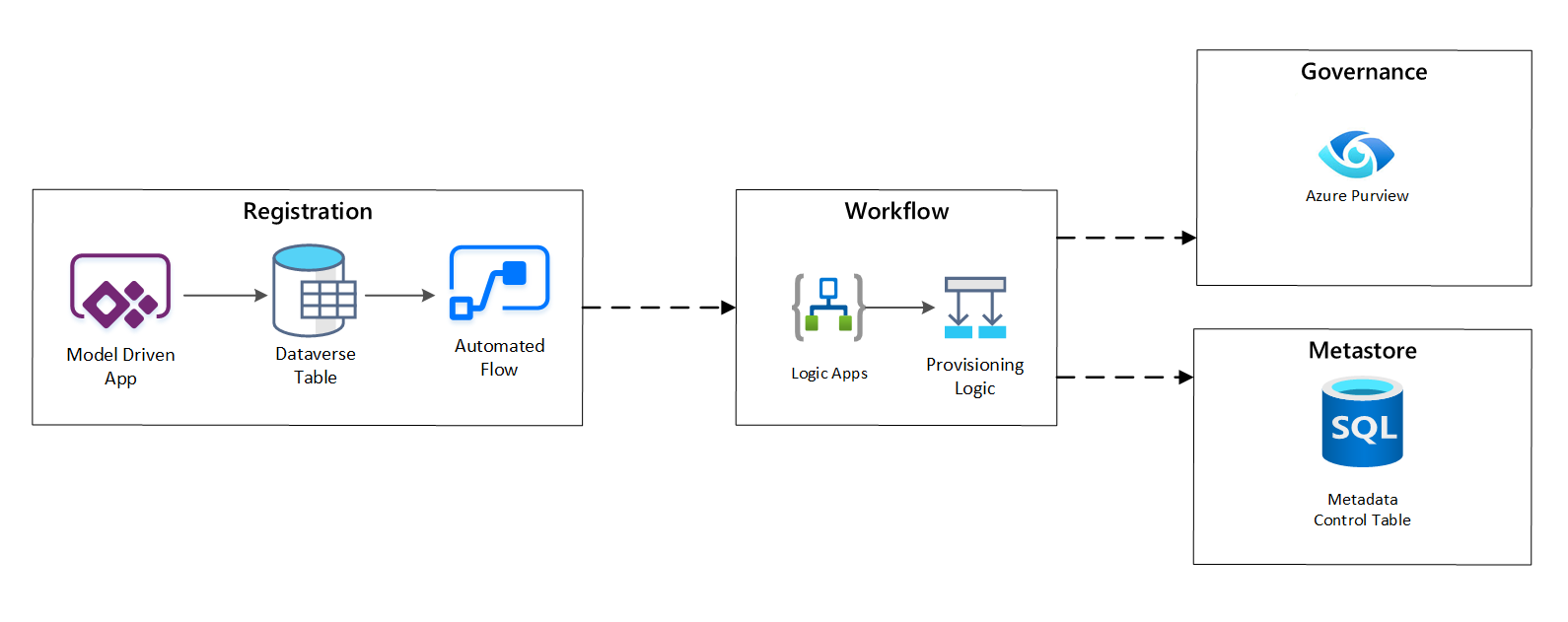
Abbildung 4: Registrierungsworkflow.
Nachdem die Erfassungsanforderungen genehmigt wurden, verwendet der Workflow die Microsoft Purview-REST-API, um die Quellen in Microsoft Purview einzufügen.
Detaillierter Workflow für Onboarding-Datenprodukte
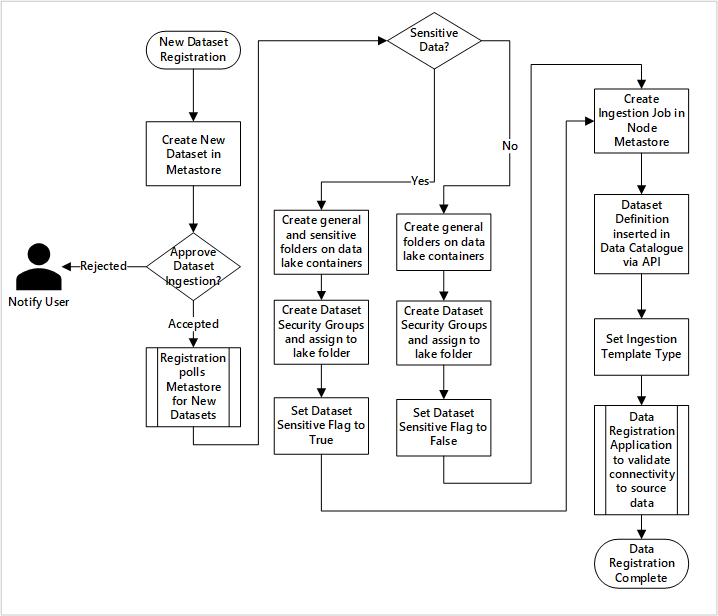 aufgenommen werden
aufgenommen werden
Abbildung 5: Wie neue Datensätze aufgenommen werden (automatisiert).
Abbildung 5 zeigt den detaillierten Registrierungsprozess zum Automatisieren der Erfassung neuer Datenquellen:
- Quellendetails werden registriert, einschließlich Produktions- und Data Factory-Umgebungen.
- Datenstruktur-, Format- und Qualitätseinschränkungen werden erfasst.
- Datenanwendungsteams sollten angeben, ob es sich um sensible Daten handelt (personenbezogene Daten). Diese Klassifizierung bestimmt den Prozess, in dem Data Lake-Ordner erstellt werden, um Rohdaten, angereicherte und kuratierte Daten zu erfassen. Die Quellnamen nennen rohe und angereicherte Daten und die Datenproduktnamen kuratierte Daten.
- Dienstprinzipal- und Sicherheitsgruppen werden zum Erfassen und Erteilen des Zugriffs auf ein Dataset erstellt.
- Ein Erfassungsauftrag wird in der Datenzielzone Data Factory Metastore erstellt.
- Eine API fügt die Datendefinition in Microsoft Purview ein.
- Abhängig von der Validierung der Datenquelle und der Genehmigung durch das Betriebsteam werden Details in einem Data Factory Metastore veröffentlicht.
Erfassungsplanung
Innerhalb von Azure Data Factory bieten metadatengesteuerte Kopieraufgaben Funktionen, mit denen die Orchestrierungspipelines von Zeilen innerhalb einer in Azure SQL-Datenbank gespeicherten Steuertabelle gesteuert werden können. Sie können das Tool zum Kopieren von Daten verwenden, um metadatengesteuerte Pipelines vorab zu erstellen.
Nachdem eine Pipeline erstellt wurde, fügt Ihr Bereitstellungsworkflow Einträge zur Steuertabelle hinzu, um die Erfassung aus Quellen zu unterstützen, die durch die Metadaten zur Registrierung von Datenobjekten identifiziert wurden. Die Pipelines der Azure Data Factory und die Azure SQL-Datenbank, die Ihren Steuertabellen-Metastore enthalten, können beide innerhalb jeder Datenzielzone vorhanden sein, um neue Datenquellen zu erstellen und sie in Datenzielzonen zu erfassen.
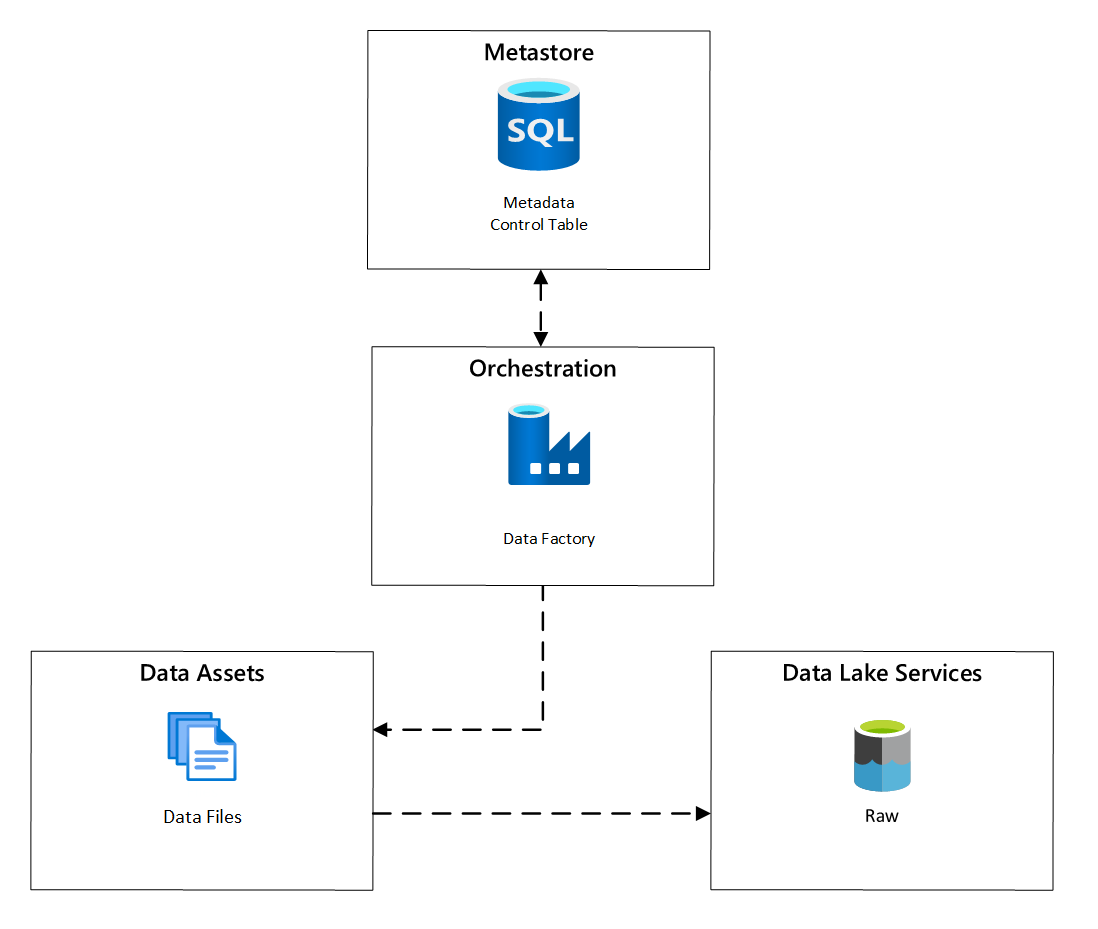
Abbildung 6: Planung der Datenobjekterfassung.
Detaillierter Workflow zum Aufnehmen neuer Datenquellen
Das folgende Diagramm zeigt, wie registrierte Datenquellen in einem SQL-Datenbankmetastore der Data Factory abgerufen werden und wie Daten zuerst aufgenommen werden:
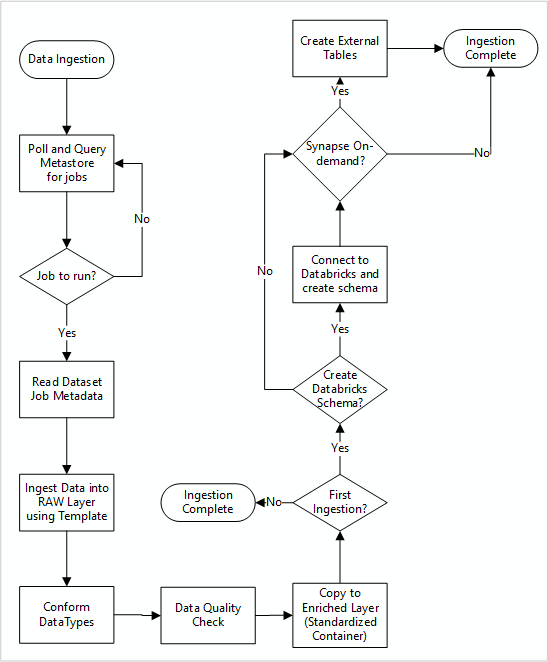 aufgenommen werden
aufgenommen werden
Ihre Data Factory-Eingabe-Hauptpipeline liest Konfigurationen aus einem SQL-Datenbankmetastore der Data Factory, dann läuft sie iterativ mit den richtigen Parametern. Daten werden von der Quelle in die Rohschicht in Azure Data Lake mit wenig bis gar keiner Änderung bewegt. Die Datenform wird basierend auf Ihrem Data Factory-Metastore überprüft. Die Dateiformate werden entweder in das Apache Parquet- oder das Avro-Format konvertiert und dann in die angereicherte Ebene kopiert.
Die erfassten Daten werden mit einem Azure Databricks Data Science and Engineering Workspace verbunden, und eine Datendefinition wird in der Datenzielzone Apache Hive Metastore erstellt.
Wenn Sie einen Azure Synapse serverlosen SQL Pool verwenden müssen, um Daten verfügbar zu machen, sollte Ihre benutzerdefinierte Lösung Ansichten über die Daten im Lake erstellen.
Wenn Sie die Verschlüsselung auf Zeilenebene oder Spaltenebene benötigen, sollte Ihre benutzerdefinierte Lösung Daten in Ihrem Data Lake landen, und Daten direkt in interne Tabellen in den SQL-Pools erfassen und entsprechende Sicherheit für die SQL-Pools einrichten.
Erfasste Metadaten
Wenn Sie die automatisierte Datenaufnahme verwenden, können Sie die zugehörigen Metadaten abfragen und Dashboards erstellen, um:
- Verfolgen Sie Aufträge und neueste Datenlade-Zeitstempel für Datenprodukte im Zusammenhang mit ihren Funktionen nach.
- Nachverfolgen verfügbarer Datenprodukte.
- Vergrößern Sie Datenvolumina.
- Erhalten Sie Echtzeitupdates zu Auftragsfehlern.
Betriebsmetadaten können zur Nachverfolgung verwendet werden:
- Aufträge, Auftragsschritte und ihre Abhängigkeiten.
- Arbeitsleistung und Leistungshistorie.
- Datenvolumenwachstum.
- Auftragsfehler.
- Änderungen der Quellmetadaten.
- Geschäftsfunktionen, die von Datenprodukten abhängen.
Verwenden Sie die REST-API von Microsoft Purview, um Daten zu ermitteln
Microsoft Purview-REST-APIs sollten zum Registrieren von Daten während der ersten Datenaufnahme verwendet werden. Sie können die APIs verwenden, um Daten kurz nachdem sie aufgenommen wurden in Ihren Datenkatalog zu übermitteln.
Weitere Informationen finden Sie unter Wie man Microsoft Purview-REST-APIs verwendet.
Registrieren von Datenquellen
Verwenden Sie den folgenden API-Aufruf, um neue Datenquellen zu registrieren:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
URI-Parameter für die Datenquelle:
| Name | Erforderlich | Typ | Beschreibung |
|---|---|---|---|
accountName |
Wahr | Zeichenfolge | Name des Microsoft Purview-Kontos |
dataSourceName |
Wahr | Zeichenfolge | Name der Datenquelle |
Verwenden Sie die REST-API von Microsoft Purview für die Registrierung
Die folgenden Beispiele zeigen, wie Sie die Microsoft Purview-REST-API zum Registrieren von Datenquellen mit Nutzlasten verwenden:
Registrieren einer Azure Data Lake Storage Gen2-Datenquelle:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Registrieren einer SQL-Datenbankdatenquelle:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Anmerkung
<collection-name> ist eine aktuelle Sammlung, die in einem Microsoft Purview-Konto vorhanden ist.
Einen Scan erstellen
Erfahren Sie, wie Sie Anmeldeinformationen zum Authentifizieren von Quellen in Microsoft Purview erstellen können, bevor Sie einen Scan einrichten und ausführen.
Verwenden Sie den folgenden API-Aufruf zum Scannen von Datenquellen:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
URI-Parameter für einen Scan:
| Name | Erforderlich | Typ | Beschreibung |
|---|---|---|---|
accountName |
Wahr | Zeichenfolge | Name des Microsoft Purview-Kontos |
dataSourceName |
Wahr | Zeichenfolge | Name der Datenquelle |
newScanName |
Wahr | Zeichenfolge | Name des neuen Scans |
Verwenden Sie die REST-API von Microsoft Purview zum Scannen.
Die folgenden Beispiele zeigen, wie Sie die Microsoft Purview REST-API verwenden können, um Datenquellen mit Nutzlasten zu scannen:
Azure Data Lake Storage Gen2 Datenquelle scannen:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Scannen einer SQL-Datenbankdatenquelle:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Verwenden Sie den folgenden API-Aufruf zum Scannen von Datenquellen:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run