Designüberlegungen für Self-Serve-Datenplattformen
Datengitter ist ein spannender neuer Ansatz für das Design und die Entwicklung von Datenarchitekturen. Im Gegensatz zur herkömmlichen Datenarchitektur trennt Datengitter die Verantwortung zwischen funktionalen Datendomänen, die sich auf das Erstellen von Datenprodukten und ein Plattformteam konzentrieren, das sich auf technische Funktionen konzentriert. Diese Trennung von Zuständigkeiten muss sich in Ihrer Plattform widerspiegeln. Sie müssen ein Gleichgewicht zwischen der Bereitstellung von domänenagnostischen Funktionen und der Aktivierung Ihrer Domänenteams zum Modellieren, Verarbeiten und Verteilen ihrer Daten in Ihrer Organisation schaffen.
Das Auswählen der richtigen Ebene der Domänengranularität und -regeln zum Entkoppeln von Plattformen ist nicht einfach. Dieser Artikel enthält mehrere Szenarien, die Ihnen detaillierte Anleitungen bieten.
Analysen auf Cloudebene
Wenn Sie ein Datengitter mit Azure erstellen möchten, empfehlen wir Ihnen, Analysen auf Cloudebene zu übernehmen. Dieses Framework ist eine bereitstellungsfähige Referenzarchitektur und bietet Open-Source-Vorlagen und bewährte Methoden. Die Analysenstruktur auf Cloudebene verfügt über zwei Hauptbausteine, die für alle Bereitstellungsoptionen grundlegend sind:
- Zielzone für die Datenverwaltung: Die Grundlage Ihrer Datenarchitektur. Sie enthält alle kritischen Funktionen für die Datenverwaltung, z. B. Datenkatalog, Datenlinie, API-Katalog, Masterdatenverwaltung usw.
- Datenzielzonen: Abonnements, die Ihre Analyse- und KI-Lösungen hosten. Sie umfassen wichtige Funktionen zum Hosten einer Analyseplattform.
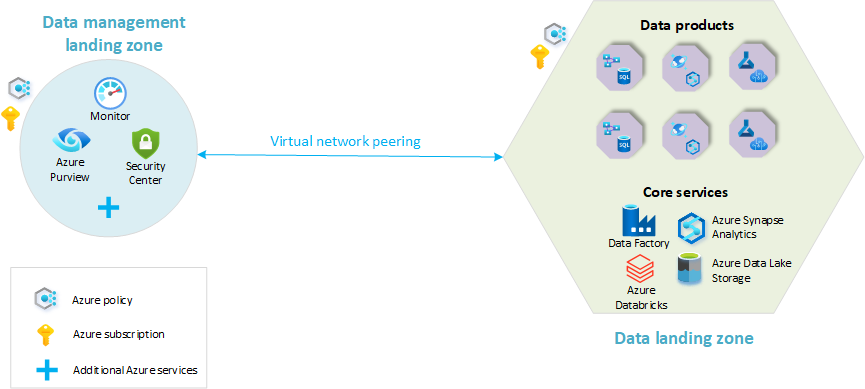
Im folgenden Diagramm finden Sie einen Überblick über eine Analyseplattform auf Cloudebene mit einer Datenverwaltungszielzone und einer einzelnen Datenzielzone. Nicht alle Azure-Dienste werden in der Abbildung dargestellt. Es wurde vereinfacht, um die Kernkonzepte der Ressourcenorganisation innerhalb der Architektur hervorzuheben.
Das cloudbasierte Analyseframework ist nicht explizit für die genaue Art der Datenarchitektur, die Sie bereitstellen müssen. Sie können es für viele gängige Analyselösungen auf Cloudebene verwenden, einschließlich (Enterprise) Data Warehouses, Datenseen, Datenseehäuser und Datengittern. Alle Beispiellösungen in diesem Artikel verwenden Datengitterarchitektur.
Sie müssen verstehen, dass alle Architekturen den Grundsätzen des Datennetzes entsprechen: Domain Ownership, Daten als Produkt, Self-Service-Datenplattform und föderierte Computer-Governance. Verschiedene Pfade können zu einem Datengitter führen. Es gibt keine eine richtige oder falsche Antwort. Sie müssen die richtigen Trade-Offs für die Anforderungen Ihrer Organisation vornehmen.
Einzelne Datenzielzone
Das einfachste Bereitstellungsmuster zum Erstellen einer Datengitterarchitektur umfasst eine Datenverwaltungszone und eine Datenzielzone. Die Datenarchitektur in einem solchen Szenario würde wie folgt aussehen:

In diesem Modell befinden sich alle Funktionsdatendomänen in derselben Datenzielzone. Ein einzelnes Abonnement enthält einen Standardsatz von Diensten. Ressourcengruppen trennen verschiedene Datendomänen und Datenprodukte. Standarddatendienste wie Azure Data Lake Store, Azure Logic Apps und Azure Synapse Analytics gelten für alle Domänen.
Alle Datendomänen folgen den Datengitterprinzipien: Daten folgen dem Domänenbesitz, und Daten werden wie Produkte behandelt. Die Plattform ist vollständig Self-Service, obwohl es begrenzte Variationen von Diensten gibt. Alle Domänen sollten sich stark an die gleichen Datenverwaltungsprinzipien halten und diesen entsprechen.
Diese Bereitstellungsoption kann für kleinere Unternehmen oder Greenfield-Projekte nützlich sein, die Datengitter nutzen möchten, aber nicht überkomplizierte Dinge. Dieser Einsatz kann auch als Ausgangspunkt für eine Organisation dienen, die plant, etwas Komplexeres aufzubauen. Planen Sie in diesem Fall die Erweiterung in mehrere Zielzonen zu einem späteren Zeitpunkt.
Quellsystem ausgerichtet und verbraucherorientierte Zielzonen
Im vorherigen Modell haben wir keine anderen Abonnements oder lokalen Anwendungen berücksichtigt. Sie können das vorherige Modell leicht ändern, indem Sie eine systemorientierte Quellzielzone hinzufügen, um alle eingehenden Daten zu verwalten. Das Onboarding von Daten ist ein schwieriger Prozess, sodass zwei Datenzielzonen nützlich sind. Das Onboarding bleibt eine der schwierigsten Teile der Verwendung von Daten in großen Bereichen. Das Onboarding erfordert häufig zusätzliche Tools zur Integration, da sich ihre Herausforderungen von der Integration unterscheiden. Es hilft, zwischen der Bereitstellung von Daten und dem Verbrauch von Daten zu unterscheiden.

In der Architektur auf der linken Seite dieses Diagramms erleichtern Dienste das Onboarding aller Daten, z. B. CDC, Dienste zum Abrufen von APIs oder Datenseediensten für dynamisches Erstellen von Datasets. Dienste in dieser Plattform können Daten von lokalen, Cloudumgebungen oder SaaS-Anbietern abrufen. Diese Art von Plattform hat in der Regel auch mehr Aufwand, da es mehr Kopplung mit zugrunde liegenden operativen Anwendungen gibt. Möglicherweise möchten Sie dies von jeder Datennutzung anders behandeln.
In der Architektur rechts neben dem Diagramm optimiert die Organisation den Verbrauch und verfügt über Dienste, die sich auf das Umwandeln von Daten in den Wert konzentrieren. Diese Dienste können maschinelles Lernen, Berichterstellung usw. enthalten.
Diese Architekturdomänen folgen allen Prinzipien des Datengitters. Domänen übernehmen Daten und dürfen Daten direkt an andere Domänen verteilen.
Hub- und generische und spezielle Datenzielzonen
Die nächste Bereitstellungsoption ist eine weitere Iteration des vorherigen Designs. Diese Bereitstellung folgt einer geregelten Gittertopologie: Daten werden über einen zentralen Hub verteilt, in dem Daten pro Domäne partitioniert werden, logisch isoliert und nicht integriert. Der Hub dieses Modells verwendet eine eigene (domänenagnostische) Datenzielzone und kann von einem zentralen Datengovernance-Team verwaltet werden, das überwacht, welche Daten auf welche anderen Domänen verteilt werden. Der Hub trägt auch Dienste, die das Onboarding von Daten erleichtern.

Verwenden Sie für Domänen, die Standarddienste zum Nutzen, Analysieren und Erstellen neuer Daten benötigen, generische Datenzielzone. Ein einzelnes Abonnement enthält einen Standardsatz von Diensten. Wenden Sie auch die Datenvirtualisierung an, da die meisten Ihrer Datenprodukte bereits im Hub beibehalten werden, und Sie benötigen keine weiteren Datenduplizierungen.
Diese Bereitstellung ermöglicht „Specials“: zusätzliche Zielzonen, die Sie bereitstellen können, wenn es nicht möglich ist, Domänen logisch zu gruppieren. Sie können benötigt werden, wenn regionale oder rechtliche Grenzen gelten oder wenn Ihre Domänen eindeutige und kontrastierende Anforderungen haben. Möglicherweise benötigen Sie sie auch in Situationen, in denen eine starke globale Tochterverwaltung mit Ausnahmen für überseeische Aktivitäten angewendet wird.
Wenn Ihre Organisation steuern muss, welche Daten verteilt und genutzt werden, ist die Hubbereitstellung eine gute Option. Es ist auch eine Option, wenn Sie Zeitvarianten und nicht veränderliche Bedenken für große Datenverbraucher behandeln. Sie können das Design von Datenprodukten stark standardisieren, so dass Ihre Domains Zeitreisen und Wiederauslieferungen durchführen können. Dieses Modell ist besonders in der Finanzbranche üblich.
Funktions- und regional ausgerichtete Datenzielzonen
Die Bereitstellung mehrerer Datenzielzonen kann Ihnen helfen, funktionale Domains basierend auf Zusammenhalt und Effizienz für die Arbeit und Freigabe von Daten zu gruppieren. Alle Ihre Datenzielzonen entsprechen der gleichen Überwachung und Kontrolle, aber Sie können immer noch Flexibilität und Entwurfsänderungen zwischen verschiedenen Datenzielzonen haben.

Bestimmen Sie die Funktionsdatendomänen, die Sie für eine freigegebene Datenzielzone logisch gruppieren möchten. Sie können z. B. die gleichen Vorlagen implementieren, wenn Sie regionale Grenzen haben. Das Eigentum, die Sicherheit oder die rechtlichen Grenzen können die Trennung von Domains erzwingen. Flexibilität, das Tempo des Wandels und die Trennung oder den Verkauf Ihrer Funktionen sind auch wichtige zu berücksichtigende Faktoren.
Weitere Anleitungen und bewährte Methoden finden Sie unter Datendomänen.
Verschiedene Zielzonen funktionieren nicht allein. Sie können eine Verbindung zu Datenseen herstellen, die in anderen Zonen gehostet werden. Dadurch können Domänen in Ihrem Unternehmen zusammenarbeiten. Sie können auch mehrsprachige Persistenz anwenden, um verschiedene Datenspeichertechnologien zu kombinieren. Mehrsprachige Persistenz ermöglicht es Ihren Domänen, Daten von anderen Domänen direkt zu lesen, ohne Daten zu duplizieren.
Wenn Sie mehrere Datenzielzonen bereitstellen, wissen Sie, dass der Verwaltungsaufwand an jede Datenzielzone angefügt ist. Sie müssen das VNet-Peering zwischen allen Datenzielzonen anwenden, Sie müssen zusätzliche private Endpunkte verwalten und so weiter.
Die Bereitstellung mehrerer Datenzielzonen ist eine gute Option, wenn Ihre Datenarchitektur groß ist. Sie können Ihrer Architektur weitere Zielzonen hinzufügen, um allgemeine Anforderungen verschiedener Domänen zu erfüllen. Diese zusätzlichen Zielzonen stellen über das Peering virtueller Netzwerke eine Verbindung mit der Datenverwaltungszielzone und allen anderen Zielzonen her. Mit Peering können Sie Datensätze und Ressourcen über Ihre Zielzonen hinweg gemeinsam nutzen. Durch das Teilen von Daten über separate Zonen können Sie Workloads auf Ihre Azure-Abonnements und -Ressourcen verteilen. Dieser Ansatz hilft organisch, das Datengitter zu implementieren.
Großes Unternehmen, das unterschiedliche Datenverwaltungszonen erfordert
Große Unternehmen, die auf globaler Ebene tätig sind, können zwischen verschiedenen Teilen ihrer Organisation einen Kontrast zur Datenverwaltung haben. Sie können mehrere Datenverwaltungs- und Datenzielzonen zusammen bereitstellen, um dieses Problem zu beheben. Das folgende Diagramm zeigt ein Beispiel für diese Art von Architektur:

Mehrere Zielzonen für die Datenverwaltung sollten Ihre Aufwand- und Integrationskomplexität rechtfertigen. Beispielsweise kann eine andere Datenverwaltungszielzone für Situationen sinnvoll sein, in denen die (Meta-)Daten Ihrer Organisation nicht von allen außerhalb Ihrer Organisation gesehen werden dürfen.
Zusammenfassung
Der Übergang zu Datengittern ist ein kultureller Wandel, der Nuancen, Kompromisse und Überlegungen erfordert. Sie können Analysen auf Cloudebene verwenden, um bewährte Methoden und ausführbare Ressourcen zu erhalten. Die Referenzarchitekturen dieses Artikels bieten Ausgangspunkte für den Start Ihrer Implementierung.