Beschleunigung von Big-Data-Echtzeitanalysen mit dem Spark-Connector
Gilt für: ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Hinweis
Ab September 2020 wird dieser Connector nicht mehr aktiv verwaltet. Allerdings ist jetzt der Apache Spark-Connector für SQL Server und Azure SQL verfügbar, der Unterstützung für Python- und R-Bindungen, eine einfachere Benutzeroberfläche für das Masseneinfügen von Daten und viele weitere Verbesserungen bietet. Es wird dringend empfohlen, den neuen Connector zu testen und anstelle dieses Connectors zu verwenden. Die Informationen zum alten Connector (diese Seite) werden nur zu Archivierungszwecken beibehalten.
Der Spark-Connector ermöglicht die Verwendung von Datenbanken in Azure SQL-Datenbank, Azure SQL Managed Instance und SQL Server als Eingabedatenquelle oder Ausgabedatensenke für Spark-Aufträge. So können transaktionale Echtzeitdaten in der Big Data-Analyse genutzt und Ergebnisse für Ad-hoc-Abfragen oder Berichterstellung dauerhaft gespeichert werden. Im Vergleich zum integrierten JDBC-Connector bietet dieser Connector die Möglichkeit, Daten per Massenvorgang in die Datenbank einzufügen. Dies führt zu einer erheblichen Leistungssteigerung: Daten können gegenüber einer zeilenweisen Einfügung 10- bis 20-mal schneller eingefügt werden. Der Spark-Connector unterstützt die Authentifizierung mit Microsoft Entra ID (früher Azure Active Directory), um eine Verbindung zu Azure SQL Datenbank und Azure SQL Managed Instance herzustellen, sodass Sie Ihre Datenbank über Azure Databricks mithilfe Ihres Microsoft Entra-Kontos verbinden können. Mit dem integrierten JDBC-Connector werden ähnliche Schnittstellen bereitgestellt. Die Migration Ihrer vorhandenen Spark-Aufträge zu diesem neuen Connector ist sehr einfach durchzuführen.
Hinweis
Microsoft Entra ID war zuvor als Azure Active Directory (Azure AD) bekannt.
Herunterladen und Erstellen eines Spark-Connectors
Das GitHub-Repository für den alten Connector, auf das zuvor von dieser Seite verwiesen wurde, wird nicht aktiv verwaltet. Es wird stattdessen empfohlen, den neuen Connector zu testen und zu verwenden.
Offiziell unterstützte Versionen
| Komponente | Version |
|---|---|
| Apache Spark | 2.0.2 oder höher |
| Scala | 2.10 oder höher |
| Microsoft JDBC-Treiber für SQL Server | 6.2 oder höher |
| Microsoft SQL Server | SQL Server 2008 oder höher |
| Azure SQL-Datenbank | Unterstützt |
| Verwaltete Azure SQL-Instanz | Unterstützt |
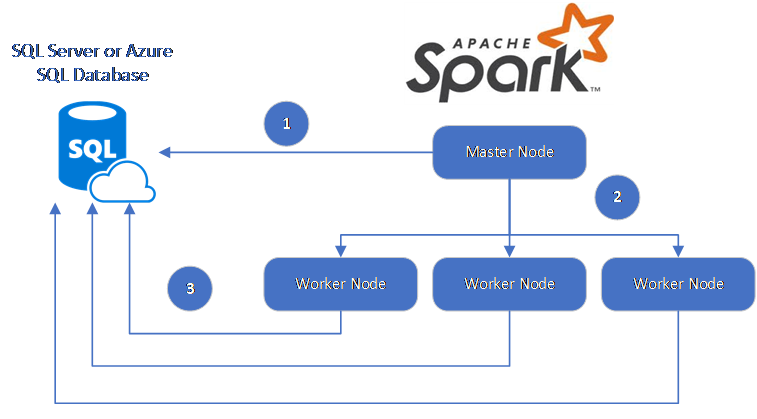
Der Spark-Connector verwendet den Microsoft JDBC-Treiber für SQL Server zum Verschieben von Daten zwischen Spark-Workerknoten und Datenbanken:
Der Datenfluss ist wie folgt:
- Der Spark-Masterknoten stellt eine Verbindung mit Datenbanken in SQL-Datenbank oder SQL Server her und lädt Daten aus einer bestimmten Tabelle oder unter Verwendung einer bestimmten SQL-Abfrage.
- Der Spark-Masterknoten verteilt die Daten zur Transformation auf die Workerknoten.
- Der Workerknoten stellt eine Verbindung mit Datenbanken her, die mit SQL-Datenbank und SQL Server verbunden sind, und schreibt Daten in die Datenbank. Benutzer könne auswählen, ob sie die Daten Zeile für Zeile oder in einem Massenvorgang einfügen möchten.
Das folgende Diagramm veranschaulicht den Datenfluss.
Erstellen des Spark-Connectors
Derzeit wird für das Connectorprojekt Maven verwendet. Sie können Folgendes ausführen, um den Connector ohne Abhängigkeiten zu erstellen:
- „mvn clean package“
- Download der aktuellen JAR-Versionen aus dem release-Ordner
- Integrieren der SQL-Datenbank-Spark-JAR-Datei
Herstellen einer Verbindung und Lesen von Daten mit dem Spark-Connector
Sie können aus einem Spark-Auftrag eine Verbindung mit Datenbanken in SQL-Datenbank und SQL Server herstellen, um Daten zu lesen oder zu schreiben. Alternativ können Sie eine DML- oder DDL-Abfrage in Datenbanken in SQL-Datenbank oder SQL Server ausführen.
Lesen von Daten aus Azure SQL und SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Lesen von Daten aus Azure SQL und SQL Server unter Angabe einer SQL-Abfrage
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Schreiben von Daten in Azure SQL und SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Ausführen einer DML- oder DDL-Abfrage in Azure SQL und SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Herstellen einer Verbindung von Spark mithilfe der Microsoft Entra-Authentifizierung
Sie können mithilfe der Microsoft Entra-Authentifizierung eine Verbindung mit SQL-Datenbank und SQL Managed Instance herstellen. Verwenden Sie die Microsoft Entra-Authentifizierung zur zentralen Verwaltung von Identitäten von Datenbankbenutzer*innen und als Alternative zur SQL-Authentifizierung.
Verbindungsherstellung im Authentifizierungsmodus „ActiveDirectoryPassword“
Anforderung an die Einrichtung
Wenn Sie den Authentifizierungsmodus „ActiveDirectoryPassword“ verwenden, müssen Sie microsoft-authentication-library-for-java und zugehörige Abhängigkeiten herunterladen und in den Java-Buildpfad einschließen.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Herstellen einer Verbindung über ein Zugriffstoken
Anforderung an die Einrichtung
Wenn Sie den auf einem Zugriffstoken basierenden Authentifizierungsmodus verwenden, müssen Sie microsoft-authentication-library-for-java und zugehörige Abhängigkeiten herunterladen und in den Java-Buildpfad einschließen.
Unter Verwenden der Microsoft Entra-Authentifizierung finden Sie Informationen dazu, wie Sie ein Zugriffstoken für Ihre Datenbank in Azure SQL-Datenbank oder Azure SQL Managed Instance abrufen.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Schreiben von Daten per Masseneinfügung
Der herkömmliche JDBC-Connector schreibt Daten zeilenweise in die Datenbank. Mit dem Spark-Connector können Sie Daten per Masseneinfügung in Azure SQL und SQL Server schreiben. Dies führt zu einer erheblich verbesserten Schreibleistung beim Laden großer Datasets oder beim Laden von Daten in Tabellen, in denen ein ColumStore-Index verwenden wird.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Nächste Schritte
Laden Sie – sofern noch nicht geschehen – den Spark-Connector aus dem GitHub-Repository azure-sqldb-spark herunter, und sehen Sie sich die zusätzlichen Ressourcen im Repository an:
Es kann auch nützlich sein, den Leitfaden zu Apache Spark SQL, DataFrames und Datasets Guide (in englischer Sprache) und die Azure Databricks-Dokumentation zu lesen.