Kaufmodell für virtuelle Kerne: Azure SQL-Datenbank
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Artikel wird das Kaufmodell für virtuelle Kerne für Azure SQL-Datenbank erläutert.
Überblick
Ein virtueller Kern (V-Kern) repräsentiert eine logische CPU und bietet Ihnen die Möglichkeit, die physischen Hardwaremerkmale (z. B. Anzahl der Kerne, Arbeitsspeicher und Speichergröße) auszuwählen. Beim vCore-basierten Kaufmodell erhalten Sie Flexibilität, Kontrolle und Transparenz in Bezug auf den individuellen Ressourcenverbrauch. Außerdem können Sie die lokalen Workloadanforderungen leicht auf die Cloud übertragen. Mit diesem Modell wird der Preis optimiert, und Sie können Compute-, Arbeitsspeicher- und Speicherressourcen entsprechend Ihren jeweiligen Workloadanforderungen auswählen.
Im vCore-basierten Kaufmodell hängen Ihre Kosten von der Auswahl und Verwendung der folgenden Elemente ab:
- Dienstebene
- Hardwarekonfiguration
- Computeressourcen (Anzahl von virtuellen Kernen und Arbeitsspeichermenge)
- Reservierter Datenbankspeicher
- Tatsächlicher Sicherungsspeicher
Wichtig
Computeressourcen, E/A sowie Daten- und Protokollspeicher werden pro Datenbank oder Pool für elastische Datenbanken berechnet. Sicherungsspeicher wird pro Datenbank berechnet. Ausführliche Informationen zu Preisen finden Sie auf der Preisseite für Azure SQL-Datenbank.
Vergleich der vCore- und DTU-basierten Kaufmodelle
Das von Azure SQL-Datenbank verwendete vCore-basierte Kaufmodell bietet gegenüber dem DTU-basierten Kaufmodell mehrere Vorteile:
- Höhere Grenzwerte für Compute, Arbeitsspeicher, E/A und Speicher
- Auswahl der Hardwarekonfiguration, um besser auf Compute- und Arbeitsspeicheranforderungen der Workload reagieren zu können
- Rabatte für Azure-Hybridvorteil (AHB).
- Mehr Transparenz bei den Hardwaredetails für das Computing zur besseren Planung von Migrationsvorgängen von lokalen Bereitstellungen
- Preise für reservierte Instanzen sind nur für das Kaufmodell für virtuelle Kerne verfügbar.
- Höhere Granularität mit mehreren Computegrößen verfügbar.
Unter vCore- und DTU-basierte Kaufmodelle von Azure SQL-Datenbank im Vergleich finden Sie Informationen, die Sie bei der Entscheidung zwischen dem Kaufmodell auf Basis virtueller Kerne und auf DTU-Basis unterstützen.
Compute
Das vCore-basierte Kaufmodell bietet eine bereitgestellte Computeebene und eine serverlose Computeebene. Auf der bereitgestellten Computeebene spiegeln die Computekosten die gesamte Computekapazität wider, die kontinuierlich für die Anwendung bereitgestellt wird (unabhängig von der Workloadaktivität). Wählen Sie die Ressourcenzuordnung aus, die Ihren geschäftlichen Anforderungen hinsichtlich virtuellen Kernen und Arbeitsspeicher am besten entspricht, und skalieren Sie Ressourcen dann nach Bedarf für Ihre Workload herauf oder herunter. Auf der serverlosen Computeebene für Azure SQL-Datenbank werden Computeressourcen automatisch basierend auf der Workloadkapazität skaliert und für die genutzte Computeleistung pro Sekunde in Rechnung gestellt.
Zusammenfassung:
- Während auf der bereitgestellten Computeebene unabhängig von der Workloadaktivität kontinuierlich eine bestimmte Menge an Computeressourcen bereitgestellt wird, erfolgt die Skalierung der Computeressourcen auf der serverlosen Computeebene automatisch basierend auf der Workloadaktivität.
- Bei der bereitgestellten Computeebene werden die bereitgestellten Computeressourcen zu einem Festpreis pro Stunde abgerechnet. Bei der serverlosen Computeebene wird die verwendete Menge an Computeressourcen sekundengenau abgerechnet.
Unabhängig von der Computeebene werden drei zusätzliche sekundäre Hochverfügbarkeitsreplikate automatisch auf der Dienstebene „Unternehmenskritisch“ zugeordnet, um hohe Resilienz bei Fehlern und schnelle Failover zu ermöglichen. Aufgrund dieser zusätzlichen Replikate sind die Kosten ca. 2,7-mal höher als auf der universellen Dienstebene. Entsprechend spiegeln die höheren Speicherkosten pro GB für die Dienstebene „Unternehmenskritisch“ die höheren E/A-Grenzwerte und die geringere Latenz des lokalen SSD-Speichers wider.
Auf der Dienstebene „Hyperscale“ steuern die Kund*innen die Anzahl zusätzlicher Hochverfügbarkeitsreplikate (zwischen 0 und 4), um die von ihren Anwendungen erforderliche Resilienz zu erreichen und gleichzeitig die Kosten zu kontrollieren.
Weitere Informationen zum Compute in Azure SQL-Datenbank finden Sie unter Computeressourcen (CPU und Arbeitsspeicher).
Ressourceneinschränkungen
Überprüfen Sie die verfügbaren Hardwarekonfigurationen für Ressourcengrenzwerte für virtuelle Kerne, und überprüfen Sie dann die Ressourcengrenzwerte für:
Daten- und Protokollspeicher
Die folgenden Faktoren wirken sich darauf aus, wie viel Speicherplatz für Daten- und Protokolldateien verwendet wird. Dies gilt für die Dienstebenen „Universell“ und „Unternehmenskritisch“.
- Jede Computegröße unterstützt eine konfigurierbare maximale Datengröße, die standardmäßig bei 32 GB liegt.
- Wenn Sie die maximale Datengröße konfigurieren, kommen automatisch 30 Prozent zusätzlicher kostenpflichtiger Speicher für die Protokolldatei hinzu.
- In der Dienstebene „Universell“ wird für
tempdblokaler SSD-Speicher verwendet, und diese Speicherkosten sind im V-Kern-Preis enthalten. - In der Dienstebene „Unternehmenskritisch“ wird für
tempdblokaler SSD-Speicher für Daten- und Protokolldateien gemeinsam genutzt, undtempdb-Speicherkosten sind im V-Kern-Preis enthalten. - Auf den Dienstebenen „Universell“ und „Unternehmenskritisch“ wird Ihnen die maximale Speichergröße in Rechnung gestellt, die für eine Datenbank oder einen Pool für elastische Datenbanken konfiguriert ist.
- Für SQL-Datenbank können Sie eine beliebige maximale Datengröße zwischen 1 GB und der unterstützten maximalen Speichergröße in Schritten von 1 GB auswählen.
Die folgenden Speicherüberlegungen sollten bei der Dienstebene „Hyperscale“ berücksichtigt werden:
- Die maximale Datenspeichergröße ist auf 128 TB festgelegt und nicht konfigurierbar.
- Ihnen wird aber nur der zugewiesene Datenspeicher berechnet, nicht der maximale Datenspeicher.
- Der Protokollspeicher wird nicht in Rechnung gestellt.
tempdbnutzt lokalen SSD-Speicher. Diese Speicherkosten sind im Preis für die virtuellen Kerne bereits enthalten. Wenn Sie die aktuell zugeordnete und verwendete Datenspeichergröße in SQL-Datenbank überwachen möchten, können Sie in Azure Monitor die Metrikallocated_data_storage bzw. storage verwenden.
Wenn Sie die aktuell zugeordnete und verwendete Speichergröße einzelner Daten- und Protokolldateien in einer Datenbank mit T-SQL überwachen möchten, verwenden Sie die Sicht sys.database_files und die Funktion FILEPROPERTY(... , 'SpaceUsed').
Tipp
Unter bestimmten Umständen müssen Sie ggf. eine Datenbank verkleinern, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Verwalten von Dateispeicherplatz in Azure SQL-Datenbank.
Sicherungsspeicher
Der Speicher für Datenbanksicherungen wird zugeordnet, um die Funktionen Zeitpunktwiederherstellung (Point in Time Restore, PITR) und Langzeitaufbewahrung (Long Term Retention, LTR) von SQL-Datenbank zu unterstützen. Dieser Speicher ist vom Daten- und Protokolldateispeicher getrennt und wird separat abgerechnet.
- PITR: Bei den Ebenen „Universell“ und „Unternehmenskritisch“ werden einzelne Datenbanksicherungen automatisch in Azure-Speicher kopiert. Die Speichergröße wird dynamisch erhöht, wenn neue Sicherungen erstellt werden. Der Speicher wird für vollständige, differenzielle und Transaktionsprotokollsicherungen verwendet. Der Speicherverbrauch richtet sich nach der Änderungsrate der Datenbank und nach dem für Sicherungen konfigurierten Aufbewahrungszeitraum. Sie können in SQL-Datenbank für jede Datenbank eine separate Aufbewahrungsdauer konfigurieren, die zwischen 1 und 35 Tagen liegen kann. Eine Sicherungsspeichermenge, die der konfigurierten maximalen Datengröße entspricht, wird ohne Zusatzkosten bereitgestellt.
- LTR: Sie können für vollständige Sicherungen eine Langzeitaufbewahrung von bis zu zehn Jahren konfigurieren. Wenn Sie eine LTR-Richtlinie einrichten, werden diese Sicherungen automatisch in Azure Blob Storage gespeichert. Sie können jedoch steuern, wie häufig die Sicherungen kopiert werden sollen. Zur Einhaltung unterschiedlicher Konformitätsanforderungen können Sie verschiedene Aufbewahrungszeiträume für wöchentliche, monatliche und/oder jährliche Sicherungen auswählen. Die Menge an Speicher, die für LTR-Sicherungen verwendet wird, richtet sich nach der ausgewählten Konfiguration. Weitere Informationen finden Sie unter Langfristiges Aufbewahren von Sicherungen.
Informationen zum Sicherungsspeicher auf der Dienstebene „Hyperscale“ finden Sie unter Automatisierte Sicherungen für Hyperscale-Datenbanken.
Dienstebenen
Im Kaufmodell für virtuelle Kerne stehen „Universell“, „Unternehmenskritisch“ und „Hyperscale“ als Dienstebenenoptionen zur Verfügung. Die Dienstebene bestimmt im Allgemeinen Speichertyp und -leistung, Optionen für Hochverfügbarkeit und Notfallwiederherstellung sowie die Verfügbarkeit bestimmter Features wie In-Memory OLTP.
| Anwendungsfall | Allgemeiner Zweck | Unternehmenskritisch | Hyperscale |
|---|---|---|---|
| Am besten geeignet für | Die meisten geschäftlichen Workloads. Bietet budgetorientierte, ausgewogene und skalierbare Compute- und Speicheroptionen. | Bietet Geschäftsanwendungen die höchste Resilienz gegenüber Fehlern durch die Verwendung mehrerer sekundärer Hochverfügbarkeitsreplikate sowie die höchste E/A-Leistung | Die größte Vielfalt an Workloads, einschließlich Workloads mit Anforderungen an hochgradig skalierbaren Speicher und Leseskalierung. Höhere Ausfallsicherheit durch die Möglichkeit, mehrere sekundäre Hochverfügbarkeitsreplikate zu konfigurieren |
| Computegröße | 2 bis 128 virtuelle Kerne | 2 bis 128 virtuelle Kerne | 2 bis 128 virtuelle Kerne |
| Speichertyp | Storage Premium (remote, pro Instanz) | Äußerst schneller lokaler SSD-Speicher (pro Instanz) | Entkoppelter Speicher mit lokalem SSD-Cache (pro Computereplikat) |
| Speichergröße | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 128 TB |
| IOPS | 320 IOPS pro virtuellem Kern mit maximal 16.000 IOPS | 4.000 IOPS pro virtuellem Kern mit maximal 327.680 IOPS | 327.680 IOPS mit max. lokaler SSD Hyperscale ist eine mehrstufige Architektur mit Caching auf mehreren Ebenen. Die tatsächlichen IOPS-Werte hängen von der Workload ab. |
| Arbeitsspeicher/virtuelle Kerne | 5,1 GB | 5,1 GB | 5,1 GB oder 10,2 GB |
| Sicherungen | Wahl zwischen georedundantem, zonenredundantem oder lokal redundantem Sicherungsspeicher mit einer Aufbewahrungsdauer von 1 bis 35 Tagen (Standardeinstellung: 7 Tage) Langzeitaufbewahrung für bis zu 10 Jahre |
Wahl zwischen georedundantem, zonenredundantem oder lokal redundantem Sicherungsspeicher mit einer Aufbewahrungsdauer von 1 bis 35 Tagen (Standardeinstellung: 7 Tage) Langzeitaufbewahrung für bis zu 10 Jahre |
Auswahl zwischen lokal redundantem Speicher (LRS), zonenredundantem Speicher (ZRS) oder georedundantem Speicher (GRS) Aufbewahrungsdauer von 1 bis 35 Tagen (standardmäßig 7 Tage) mit bis zu 10 Jahren Langzeitaufbewahrung |
| Verfügbarkeit | Ein Replikat, keine Replikate mit Leseskalierung, zonenredundante Hochverfügbarkeit (High Availability, HA) |
drei Replikate, ein Replikat mit Leseskalierung, zonenredundante Hochverfügbarkeit (High Availability, HA) |
zonenredundante Hochverfügbarkeit (High Availability, HA) |
| Preise/Abrechnung | Virtueller Kern, reservierter Speicher und Sicherungsspeicher werden in Rechnung gestellt. IOPS werden nicht in Rechnung gestellt. |
Virtueller Kern, reservierter Speicher und Sicherungsspeicher werden in Rechnung gestellt. IOPS werden nicht in Rechnung gestellt. |
Virtueller Kern für jedes Replikat und den verwendeten Speicher wird in Rechnung gestellt. IOPS werden nicht in Rechnung gestellt. |
| Rabattmodelle | Reservierte Instanzen Azure-Hybridvorteil (nicht verfügbar für Dev/Test-Subscriptions) Enterprise- und Dev/Test Pay-As-You-Go-Subscriptions |
Reservierte Instanzen Azure-Hybridvorteil (nicht verfügbar für Dev/Test-Subscriptions) Enterprise- und Dev/Test Pay-As-You-Go-Subscriptions |
Azure-Hybridvorteil (nicht verfügbar für Dev/Test-Abonnements) 1 Enterprise- und Dev/Test Pay-As-You-Go-Subscriptions |
| In-Memory-OLTP-Tabellen | No | Ja | Nein |
1 Vereinfachte Preise für SQL-Datenbank Hyperscale in Kürze verfügbar. Ausführlichere Informationen dazu finden Sie im Hyperscale-Preisblog.
Ausführlichere Informationen finden Sie in den Ressourcenlimits für logische Server, Einzeldatenbanken und Pooldatenbanken.
Hinweis
Weitere Informationen zur Vereinbarung zum Servicelevel (Service Level Agreement, SLA) finden Sie unter SLA für Azure SQL-Datenbank.
Universell
Das Architekturmodell für die Dienstebene „Universell“ basiert auf der Trennung von Compute- und Speicherebene. Dieses Architekturmodell beruht auf der Hochverfügbarkeit und Zuverlässigkeit von Azure Blob Storage mit transparenter Replikation von Datenbankdateien und garantiert, dass bei einem Ausfall der zugrunde liegenden Infrastruktur keine Datenverluste auftreten.
In der folgenden Abbildung sind vier Knoten im Architekturmodell des Typs „Standard“ mit getrennter Compute- und Speicherebene dargestellt.
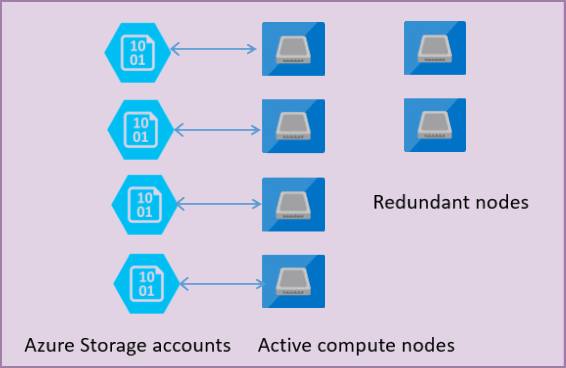
Das Architekturmodell für die Dienstebene „Universell“ umfasst zwei Ebenen:
- Eine zustandslose Computeebene, auf der der Prozess
sqlservr.exeausgeführt wird und die nur temporäre und zwischengespeicherte Daten (z. B. Plancache, Pufferpool, Spaltenspeicherpool) enthält. Dieser zustandslose Knoten wird von der Azure Service Fabric-Plattform gesteuert, die Prozesse initialisiert, die Integrität des Knotens überprüft und bei Bedarf ein Failover an einen anderen Ort durchführt. - Eine zustandsbehaftete Datenebene mit Datenbankdateien (MDF- und LDF-Dateien), die in Azure Blob Storage gespeichert sind. Azure Blob Storage garantiert, dass bei keinem in Datenbankdateien platzierten Datensatz Datenverluste entstehen. Azure Storage bietet integrierte Datenverfügbarkeit und -redundanz, um sicherzustellen, dass jeder Datensatz in einer Protokolldatei und jede Seite in einer Datendatei erhalten bleibt, auch wenn der Prozess abstürzt.
Bei einem Upgrade der Datenbank-Engine oder des Betriebssystems, einem Ausfall eines Teils der zugrunde liegenden Infrastruktur oder wenn im sqlservr.exe-Prozess ein schwerwiegendes Problem erkannt wird, verschiebt Azure Service Fabric den zustandslosen Prozess auf einen anderen zustandslosen Serverknoten. Es sind mehrere Reserveknoten vorhanden, auf denen im Fall eines Failovers des primären Knotens ein neuer Computedienst ausgeführt werden kann, um die Failoverzeit zu minimieren. Daten auf der Azure Storage-Ebene sind nicht betroffen, und Daten- und Protokolldateien werden an den neu initialisierten Prozess angefügt. Dieser Prozess garantiert standardmäßig 99,99 % Verfügbarkeit und 99,995 % Verfügbarkeit, wenn Zonenredundanz aktiviert ist. Aufgrund der Übergangszeit und der Tatsache, dass der neue Knoten mit einem kalten Cache startet, kann es zu Leistungseinbußen bei großen Workloads kommen, die aktuell ausgeführt werden.
Wann sollte diese Dienstebene gewählt werden?
Die Dienstebene „Universell“ ist die Standarddienstebene in Azure SQL-Datenbank, die für die meisten generischen Workloads konzipiert ist. Wenn Sie eine vollständig verwaltete Datenbank-Engine mit einer Standard-SLA und Speicherlatenz zwischen 5 ms und 10 ms benötigen, ist die Ebene „Universell“ die für Sie geeignete Option.
Unternehmenskritisch
Das Dienstebenenmodell des Typs „Unternehmenskritisch“ basiert auf einem Cluster von Datenbank-Engine-Prozessen. Dieses Architekturmodell beruht auf einem Quorum verfügbarer Datenbank-Engine-Knoten, und selbst bei Wartungsarbeiten wird die Leistung Ihrer Workloads nur minimal beeinträchtigt. Das zugrunde liegende Betriebssystem, Treiber und die Datenbank-Engine werden transparent mit minimaler Ausfallzeit für Endbenutzer*innen aktualisiert und gepatcht.
Im unternehmenskritischen Modell sind die Berechnung und der Speicher für jeden Knoten integriert. Hochverfügbarkeit wird durch Replikation von Daten zwischen Datenbankmodulprozessen auf jedem Knoten eines Vier-Knoten-Clusters erreicht, wobei jeder Knoten lokal angefügte SSD-Datenträger als Datenspeicher verwendet. Das folgende Diagramm zeigt, wie die unternehmenskritische Dienstebene einen Cluster von Datenbank-Engine-Knoten in Verfügbarkeitsgruppenreplikaten organisiert.

Der Datenbank-Engine-Prozess sowie die zugrunde liegenden MDF- und LDF-Dateien werden mit lokal angefügtem SSD-Speicher auf demselben Knoten platziert und bieten niedrige Latenz für die Workload. Hochverfügbarkeit wird anhand einer ähnlichen Technologie wie AlwaysOn-Verfügbarkeitsgruppen in SQL Server implementiert. Jede Datenbank ist ein Cluster von Datenbankknoten mit einem primären Replikat, das für Kundenworkloads zugänglich ist, und drei sekundären Replikaten, die Kopien der Daten enthalten. Das primäre Replikat überträgt die Änderungen kontinuierlich an die sekundären Replikate, um sicherzustellen, dass die Daten in den sekundären Replikaten verfügbar sind, wenn das primäre Replikat aus bestimmten Gründen ausfällt. Ein Failover wird von Service Fabric und der Datenbank-Engine verarbeitet: Ein sekundäres Replikat wird zum primären Replikat, und ein neues sekundäres Replikat wird erstellt, um sicherzustellen, dass ausreichend Knoten im Cluster vorhanden sind. Die Workload wird automatisch zum neuen primären Replikat umgeleitet.
Darüber hinaus umfasst der Cluster des Typs „Unternehmenskritisch“ eine integrierte Funktion Horizontale Leseskalierung, die ein gebührenfreies, integriertes und schreibgeschütztes Replikat bereitstellt, das zum Ausführen von schreibgeschützten Abfragen (z. B. Berichten) verwendet werden kann, die die Leistung des primären Replikats nicht beeinträchtigen.
Wann sollte diese Dienstebene gewählt werden?
Die Dienstebene „Unternehmenskritisch“ ist für Anwendungen gedacht, die Antworten mit geringer Latenz vom zugrunde liegenden SSD-Speicher (durchschnittlich 1 bis 2 ms), schnellere Wiederherstellung bei einem Fehler der zugrunde liegenden Infrastruktur oder das Auslagern von Berichten, Analysen und schreibgeschützten Abfragen an das kostenlose lesbare sekundäre Replikat der primären Datenbank erfordern.
Die wichtigsten Gründe dafür, dass Sie die Dienstebene „Unternehmenskritisch“ anstelle der Ebene „Universell“ wählen sollten, sind folgende:
- Niedrige E/A-Latenzanforderungen: Für Workloads, die eine dauerhaft schnelle Reaktion der Speicherebene (durchschnittlich 1–2 Millisekunden) erfordern, sollte die Dienstebene „Unternehmenskritisch“ verwendet werden.
- Workloads mit Berichterstellungs- und Analyseabfragen eignen sich, wenn ein kostenloses sekundäres schreibgeschütztes Replikat ausreicht.
- Höhere Resilienz und schnellere Wiederherstellung nach Fehlern. Bei einem Systemausfall wird die Datenbank auf der primären Instanz deaktiviert, und eines der sekundären Replikate wird sofort zur neuen primären Datenbank mit Lese-/Schreibzugriff und kann direkt Abfragen verarbeiten.
- Erweiterter Schutz vor Datenbeschädigung: Da die Dienstebene „Unternehmenskritisch“ im Hintergrund Datenbankreplikate verwendet, nutzt der Dienst die automatische Seitenreparatur, die mit Spiegelung und Verfügbarkeitsgruppen verfügbar ist, um Datenbeschädigungen zu minimieren. Falls ein Replikat eine Seite aufgrund eines Datenintegritätsproblems nicht lesen kann, wird eine neue Kopie der Seite von einem anderen Replikat abgerufen, die die nicht lesbare Seite ohne Datenverluste oder Ausfallzeiten für die Kundschaft ersetzt. Diese Funktionalität ist auf der Dienstebene „Universell“ verfügbar, wenn die Datenbank über ein georedundantes Replikat verfügt.
- Höhere Verfügbarkeit: Die Dienstebene „Unternehmenskritisch“ bietet in der Konfiguration mit mehreren Verfügbarkeitszonen Resilienz gegenüber Zonenausfällen und eine SLA mit höherer Verfügbarkeit.
- Schnelle geografische Wiederherstellung: Wenn die aktive Georeplikation konfiguriert ist, weist die Ebene „Unternehmenskritisch“ einen garantierten RPO-Wert (Recovery Point Objective) von fünf Sekunden und einen RTO-Wert (Recovery Time Objective) von 30 Sekunden für 100 % der bereitgestellten Stunden auf.
Hyperscale
Die Dienstebene „Hyperscale“ ist für alle Workloadtypen geeignet. Die cloudnative Architektur bietet unabhängig skalierbare Compute- und Speicherressourcen, um die verschiedensten traditionellen und modernen Anwendungen zu unterstützen. Auf der Dienstebene „Hyperscale“ sind mehr Compute- und Speicherressourcen als auf den Dienstebenen „Universell“ oder „Unternehmenskritisch“ verfügbar.
Weitere Informationen finden Sie unter Dienstebene „Hyperscale“ für Azure SQL-Datenbank.
Wann sollte diese Dienstebene gewählt werden?
Die Dienstebene „Hyperscale“ beseitigt viele praktische Einschränkungen, die normalerweise für Clouddatenbanken gelten. Während die meisten anderen Datenbanken durch die auf einem einzelnen Knoten verfügbaren Ressourcen eingeschränkt werden, gelten in der Dienstebene „Hyperscale“ keine solchen Limits. Mit ihrer flexiblen Speicherarchitektur kann eine Hyperscale-Datenbank nach Bedarf wachsen, während Ihnen nur die verbrauchte Speicherkapazität in Rechnung gestellt wird.
Neben ihren erweiterten Skalierungsfunktionen stellt die Dienstebene „Hyperscale“ nicht nur für große Datenbanken eine hervorragende Option dar, sondern auch für Workloads. Mit Hyperscale haben Sie folgende Möglichkeiten:
- Erzielen Sie hohe Resilienz und schnelle Wiederherstellung nach Fehlern bei gleichzeitiger Kostenkontrolle, indem Sie eine Anzahl von Hochverfügbarkeitsreplikate zwischen 0 und 4 auswählen.
- Verbessern Sie die Hochverfügbarkeit, indem Sie Zonenredundanz für Compute und Speicher aktivieren.
- Erzielen Sie eine niedrige E/A-Latenz (durchschnittlich 1–2 Millisekunden) für den häufig verwendeten Teil Ihrer Datenbank. Bei kleineren Datenbanken kann dies die gesamte Datenbank einschließen.
- Implementieren Sie mit benannten Replikaten eine Vielzahl von Szenarien für die horizontale Leseskalierung.
- Nutzen Sie die Vorteile der schnellen Skalierung, da Sie nicht darauf warten müssen, dass Daten in den lokalen Speicher auf neuen Knoten kopiert werden.
- Profitieren Sie von einer dauerhaften Datenbanksicherung ohne Auswirkungen und der schnellen Wiederherstellung.
- Unterstützen Sie Ihre Anforderungen an die Geschäftskontinuität mithilfe von Failovergruppen und Georeplikation.
Hardwarekonfiguration
Zu den allgemeinen Optionen für die Hardwarekonfigurationen im Modell für virtuelle Kerne gehören die Standard-Serie (Gen5), die Fsv2-Serie und die DC-Serie. Hyperscale bietet auch eine Option für (arbeitsspeicheroptimierte) Hardware der Premium-Serie. Die Hardwarekonfiguration definiert Compute- und Arbeitsspeichergrenzwerte und andere Merkmale, die sich auf die Workloadleistung auswirken.
Bestimmte Hardwarekonfigurationen wie Standard-Serie (Gen5) können mehr als einen Prozessortyp (CPU) verwenden, wie in Computeressourcen (CPU und Arbeitsspeicher) beschrieben. Während eine bestimmte Datenbank oder ein bestimmter Pool für elastische Datenbanken tendenziell lange auf der Hardware mit demselben CPU-Typ bleibt (häufig für mehrere Monate), gibt es bestimmte Ereignisse, die dazu führen können, dass eine Datenbank oder ein Pool auf Hardware verschoben wird, die einen anderen CPU-Typ verwendet.
Eine Datenbank oder ein Pool kann für eine Vielzahl von Szenarien verschoben werden, einschließlich, aber nicht beschränkt auf folgendes:
- Das Dienstziel wird geändert
- Die aktuelle Infrastruktur in einem Rechenzentrum nähert sich den Kapazitätsgrenzen
- Die aktuell verwendete Hardware wird aufgrund des Endes der Lebensdauer außer Betrieb genommen
- Die zonenredundante Konfiguration ist aktiviert und wechselt aufgrund der verfügbaren Kapazität zu einer anderen Hardware
Bei einigen Workloads kann ein Wechsel zu einem anderen CPU-Typ die Leistung verändern. SQL-Datenbank konfiguriert Hardware mit dem Ziel, vorhersehbare Workloadleistung bereitzustellen, auch wenn sich der CPU-Typ ändert, um Leistungsschwankungen innerhalb eines Schmalbands zu halten. Aufgrund des vielfältigen Spektrums an Kundenworkloads, die in SQL-Datenbank ausgeführt werden, und da immer neue CPU-Typen auf den Markt kommen, ist es jedoch möglich, dass gelegentlich deutlichere Änderungen bei der Leistung festzustellen sind, wenn für eine Datenbank oder ein Pool ein anderer CPU-Typ eingesetzt wird.
Unabhängig vom verwendeten CPU-Typ bleiben Ressourcenbeschränkungen für eine Datenbank oder einen Pool für elastische Datenbanken (z. B. Anzahl der Kerne, Arbeitsspeicher, maximaler Daten-IOPS-Wert, maximale Protokollrate und maximale Anzahl gleichzeitiger Worker) unverändert, solange die Datenbank im selben Dienstziel bleibt.
Computeressourcen (CPU und Arbeitsspeicher)
Die folgende Tabelle enthält einen Vergleich der Computeressourcen der verschiedenen Hardwarekonfigurationen und Computeebenen:
| Hardwarekonfiguration | CPU | Arbeitsspeicher |
|---|---|---|
| Standard-Serie (Gen5) | Bereitgestelltes Computing – Prozessoren: Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)* und AMD EPYC 7763v (Milan) – Bereitstellung von bis zu 128 virtuellen Kernen (mit Hyperthreading) Serverloses Computing: – Prozessoren: Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)* und AMD EPYC 7763v (Milan) - Autoskalierung auf bis zu 80 virtuelle Kerne (mit Hyperthreading) – Das Verhältnis von Arbeitsspeicher zu virtuellen Kernen passt sich je nach Workloadbedarf dynamisch an die Arbeitsspeicher- und CPU-Auslastung an und kann bis zu 24 GB pro virtuellem Kern betragen. Beispielsweise kann ein Workload zu einem bestimmten Zeitpunkt 240 GB Arbeitsspeicher und nur 10 virtuelle Kerne verwenden, was entsprechend in Rechnung gestellt wird. |
Bereitgestelltes Computing - 5,1 GB pro virtuellem Kern – Bereitstellung von bis zu 625 GB Serverloses Computing: - Autoskalierung auf bis zu 24 GB pro virtuellem Kern - Autoskalierung auf bis zu 240 GB |
| Fsv2-Serie | – Intel® 8168-Prozessoren (Skylake) - Kontinuierliche Turbo-Taktfrequenz von 3,4 GHz für alle Kerne und maximale Turbo-Taktfrequenz für Einzelkerne von 3,7 GHz – Bereitstellung von bis zu 72 virtuellen Kernen (mit Hyperthreading) |
- 1,9 GB pro virtuellem Kern – Bereitstellung von bis zu 136 GB |
| DC-Serie | – Intel® Xeon® E-2288G-Prozessoren - Inklusive Intel Software Guard Extensions (Intel SGX) – Bereitstellung von bis zu 8 virtuellen Kernen (physisch) |
– 4,5 GB pro virtuellem Kern |
* In der dynamischen Verwaltungssicht sys.dm_user_db_resource_governance wird die Hardwaregeneration für Datenbanken mit Intel® SP-8160-Prozessoren (Skylake) als „Gen6“ angezeigt. Die Hardwaregeneration für Datenbanken mit Intel® 8272CL-Prozessoren (Cascade Lake) wird als „Gen7“ angezeigt. Und die Hardwaregeneration für Datenbanken mit Intel® Xeon® Platinum 8370C (Ice Lake) oder AMD® EPYC® 7763v (Milan) wird als „Gen8“ angezeigt. Bei einer bestimmten Computegröße und Hardwarekonfiguration sind die Ressourcengrenzwerte unabhängig vom CPU-Typ (Intel Broadwell, Skylake, Ice Lake, Cascade Lake oder AMD Milan) identisch.
Informationen finden Sie unter den Ressourcengrenzwerten für Singletons und Pools für elastische Datenbanken.
Informationen zu Computeressourcen und Spezifikationen für Hyperscale-Datenbanken finden Sie unter Hyperscale-Computeressourcen.
Standard-Serie (Gen5)
- Hardware der Standard-Serie (Gen5) bietet ausgewogene Compute- und Speicherressourcen und eignet sich für die meisten Datenbankworkloads.
Hardware der Standard-Serie (Gen5) ist weltweit in allen öffentlichen Regionen verfügbar.
Hyperscale-Premium-Serie
- Bei den Hardwareoptionen der Premium-Serie kommt die neueste CPU- und Speichertechnologie von Intel und AMD zum Einsatz. Die Premium-Serie bietet eine höhere Computeleistung als Hardware der Standard-Serie.
- Die Optionen der Premium-Serie bieten höhere CPU-Geschwindigkeiten im Vergleich zur Standard-Serie und eine höhere maximale Anzahl von virtuellen Kernen.
- Die arbeitsspeicheroptimierte Option der Premium-Serie bietet die doppelte Menge Arbeitsspeicher im Vergleich zu Standard-Serien.
- Standard-Serien, Premium-Serien- und speicheroptimierte Premium-Serien sind für Hyperscale-Pools für elastische Datenbanken verfügbar.
Weitere Informationen finden Sie im Blogbeitrag mit der Ankündigung der Hyperscale-Premium-Serie.
Informationen zu den verfügbaren Regionen finden Sie unter Verfügbarkeit der Hyperscale-Premium-Serie.
Fsv2-Serie
- Die Fsv2-Serie ist eine für Compute optimierte Hardwarekonfiguration, die eine niedrige CPU-Latenz und eine hohe Taktfrequenz für die meisten Workloads mit hohen CPU-Anforderungen bereitstellt. Ähnlich wie bei Hardwarekonfigurationen der Hyperscale Premium-Serie kommt in der Fsv2-Serie die neueste CPU- und Arbeitsspeichertechnologie von Intel und AMD zum Einsatz – so können Kunden von der neuesten Hardware profitieren und gleichzeitig Datenbanken und Pools für elastische Datenbanken auf der universellen Dienstebene nutzen.
- Abhängig von der Workload kann die Fsv2-Serie eine höhere CPU-Leistung pro virtuellem Kern erzielen als andere Hardwaretypen. Mit der Fsv2-Computegröße mit 72 virtuellen Kernen erhalten Sie mehr CPU-Leistung für weniger Kosten als mit 80 virtuellen Kernen bei der Standard-Serie (Gen5).
- Fsv2 bietet weniger Arbeitsspeicher und
tempdbpro virtuellem Kern als andere Hardware, sodass für Workloads, für die diese Grenzwerte wichtig sind, mit der Standard-Serie (Gen5) unter Umständen eine bessere Leistung erzielt werden kann.
Fsv2-series wird von der Dienstebene „Universell“ nicht unterstützt. Weitere Informationen zu Regionen, in denen die Fsv2-Serie verfügbar ist, finden Sie unter Verfügbarkeit der Fsv2-Serie.
DC-Serie
- In Hardware der DC-Serie werden Intel-Prozessoren mit Software Guard Extensions-Technologie (Intel SGX) verwendet.
- Die DC-Serie ist für Always Encrypted mit sicheren Enklaven-Workloads erforderlich, die, verglichen mit virtualisierungsbasierten Sicherheits(VBS)-Enklaven, einen stärkeren Sicherheitsschutz für Hardware-Enklaven erfordern.
- Die DC-Serie ist für Workloads konzipiert, durch die vertrauliche Daten verarbeitet werden und die Funktionen für die vertrauliche Abfrageverarbeitung erfordern, die von Always Encrypted mit Secure Enclaves bereitgestellt werden.
- Hardware der DC-Serie bietet ausgewogene Compute- und Speicherressourcen.
Die DC-Serie wird nur für bereitgestellte Computeressourcen (und nicht für „serverlos“) unterstützt. Außerdem unterstützt sie keine Zonenredundanz. Die Regionen, in denen die DC-Serie verfügbar ist, finden Sie unter Verfügbarkeit der DC-Serie.
Von der DC-Serie unterstützte Azure-Angebotstypen
Zum Erstellen von Datenbanken oder Pools für elastische Datenbanken auf Hardware der DC-Serie muss das Abonnement ein kostenpflichtiger Angebotstyp sein, einschließlich nutzungsbasierter Bezahlung oder Enterprise Agreement (EA). Eine vollständige Liste mit den von der DC-Serie unterstützten Azure-Angebotstypen finden Sie unter Aktuelle Angebote ohne Ausgabenlimits.
Hardwarekonfiguration auswählen
Sie können die Hardwarekonfiguration für eine Datenbank oder einen Pool für elastische Datenbanken in SQL-Datenbank zum Zeitpunkt der Erstellung auswählen. Sie können die Hardwarekonfiguration einer vorhandenen Datenbank oder eines Pools für elastische Datenbanken auch ändern.
So wählen Sie eine Hardwarekonfiguration beim Erstellen einer SQL-Datenbank oder eines Pools aus
Ausführliche Informationen finden Sie unter Erstellen einer SQL-Datenbank-Instanz.
Wählen Sie auf der Registerkarte Grundlagen im Abschnitt Compute + Speicher den Link Datenbank konfigurieren und dann den Link Konfiguration ändern aus:

Wählen Sie die gewünschte Hardwarekonfiguration aus:

So ändern Sie die Hardwarekonfiguration einer vorhandenen SQL-Datenbank oder eines Pools
Wählen Sie für eine Datenbank auf der Seite „Übersicht“ den Link Tarif aus:

Wählen Sie für einen Pool auf der Seite Übersicht die Option Konfigurieren aus.
Führen Sie die Schritte zum Ändern der Konfiguration aus, und wählen Sie die Hardwarekonfiguration wie in den vorherigen Schritten beschrieben aus.
Hardwareverfügbarkeit
Informationen zu Hardware vorheriger Generationen finden Sie unter Verfügbarkeit der Hardware vorheriger Generationen.
Standard-Serie (Gen5)
Hardware der Standard-Serie (Gen5) ist weltweit in allen öffentlichen Regionen verfügbar.
Hyperscale-Premium-Serie
Die Hyperscale-Dienstebene für die Premium-Serie und die arbeitsspeicheroptimierte Premium-Serie ist für einzelne Datenbanken und Pools für elastische Datenbanken in den folgenden Regionen verfügbar:
- Australien, Osten **
- Australien, Südosten
- Brasilien, Süden **,*
- Kanada, Mitte **
- Kanada, Osten
- Asien, Osten
- Europa, Norden **
- Europa, Westen **
- Frankreich, Mitte
- Deutschland, Westen-Mitte
- Indien, Mitte
- Indien, Süden
- Japan, Osten **
- Japan, Westen
- Asien, Südosten **
- Schweiz, Norden
- Schweden, Mitte **,*
- UK, Süden **
- UK, Westen *
- USA, Mitte **
- USA, Osten **
- USA, Osten 2 **
- USA, Norden-Mitte
- USA, Süden-Mitte
- USA, Westen-Mitte
- USA, Westen 1
- USA, Westen 2 **
- USA, Westen 3 **
* Arbeitsspeicheroptimierte Hardware der Premium-Serie ist derzeit nicht verfügbar.
** Umfasst Unterstützung für Zonenredundanz.
Fsv2-Serie
Die Fsv2-Serie ist in den folgenden Regionen verfügbar:
- Australien, Mitte
- Australien, Mitte 2
- Australien (Osten)
- Australien, Südosten
- Brasilien Süd
- Kanada, Mitte
- Asien, Osten
- Europa, Norden
- Europa, Westen
- Frankreich, Mitte
- Indien, Mitte
- Korea, Mitte
- Korea, Süden
- Südafrika, Norden
- Asien, Südosten
- UK, Süden
- UK, Westen
- USA, Osten
- USA, Westen 2
DC-Serie
Die DC-Serie ist in den folgenden Regionen verfügbar:
- Kanada, Mitte
- Europa, Westen
- Europa, Norden
- Asien, Südosten
- UK, Süden
- USA, Westen
- USA, Osten
Wenn Sie die DC-Serie in einer derzeit nicht unterstützten Region benötigen, reichen Sie eine Supportanfrage ein. Geben Sie unter Grundlagen die Folgendes an:
- Wählen Sie als Problemtyp die Option Technisch aus.
- Geben Sie das gewünschte Abonnement für die Hardware an. Klicken Sie auf Weiter.
- Wählen Sie für Diensttyp den Eintrag SQL-Datenbank aus.
- Wählen Sie unter Ressource die Option Allgemeine Frage aus.
- Geben Sie als Zusammenfassung die gewünschte Hardwareverfügbarkeit und Region an.
- Wählen Sie für Problemtyp den Eintrag Sicherheit, privat und Compliance aus.
- Wählen Sie für Problemuntertyp die Option Always Encrypted aus.

Hardware der vorherigen Generation
Gen4
Gen4-Hardware wurde eingestellt und steht für Bereitstellung sowie Hoch- oder Herunterskalierung nicht zur Verfügung. Migrieren Sie Ihre Datenbank zu einer unterstützten Hardwaregeneration, um eine größere Bandbreite bei der Skalierbarkeit von virtuellen Kernen und Arbeitsspeicher, beschleunigten Netzwerkbetrieb, optimale E/A-Leistung und minimale Latenz zu erzielen. Überprüfen Sie die Hardwareoptionen für Singletons und die Hardwareoptionen für Pools für elastische Datenbanken. Weitere Informationen finden Sie unter Einstellung des Supports für Gen4-Hardware in Azure SQL-Datenbank.