Ressourcenverwaltung in Azure SQL-Datenbank
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Dieser Artikel bietet eine Übersicht über die Ressourcenverwaltung in Azure SQL-Datenbank. Es wird erläutert, was passiert, wenn Ressourcenlimits erreicht werden, und die zum Erzwingen dieser Grenzwerte verwendeten Mechanismen für die Ressourcengovernance werden beschrieben.
Spezifische Ressourcenbeschränkungen pro Preisniveau für einzelne Datenbanken finden Sie unter
- DTU-basierte Ressourcenbeschränkungen für Einzeldatenbanken
- Ressourcenbeschränkungen auf Basis virtueller Kerne für Einzeldatenbanken
Informationen zu flexiblen Ressourcenbeschränkungen für Pools für elastische Datenbanken finden Sie unter:
- DTU-basierte Ressourcenbeschränkungen für Pools für elastische Datenbanken
- Ressourcenbeschränkungen auf Basis virtueller Kerne für Pools für elastische Datenbanken
Kapazitätsgrenzen für dedizierten SQL-Pool in Azure Synapse Analytics:
Grenzwerte für virtuelle Kerne für Abonnements pro Region
Ab März 2024 gelten für Abonnements die folgenden Grenzwerte für virtuelle Kerne pro Region und Abonnement:
| Subscriptiontyp | Standardgrenzwerte für virtuelle Kerne |
|---|---|
| Enterprise Agreement (EA) | 2.000 |
| Kostenlose Testversionen | 10 |
| Microsoft für Startups | 100 |
| MSDN/MPN/Imagine/AzurePass/Azure for Students | 40 |
| Nutzungsbasierte Bezahlung (Pay-as-you-go, PAYG) | 150 |
Beachten Sie Folgendes:
- Diese Grenzwerte gelten für neue und vorhandene Abonnements.
- Datenbanken und Pools für elastische Datenbanken, die im Rahmen des DTU-Einkaufsmodells bereitgestellt werden, werden ebenfalls auf das Kontingent von virtuellen Kernen angerechnet und umgekehrt. Jeder verbrauchte virtuelle Kern wird als Äquivalent zu 100 verbrauchten DTUs für das Kontingent auf Serverebene betrachtet.
- Standardgrenzwerte umfassen sowohl die für bereitgestellte Compute-Datenbanken/Pools für elastische Datenbanken konfigurierten virtuellen Kerne als auch die für serverlose Datenbanken konfigurierten maximalen virtuellen Kerne.
- Sie können den REST-API-Aufruf Abonnementverwendungen verwenden, um Ihre aktuelle Nutzung virtueller Kerne für Ihr Abonnement zu ermitteln.
- Um ein höheres Kontingent virtueller Kerne als standardmäßig anzufordern, senden Sie eine neue Supportanfrage im Azure-Portal. Weitere Informationen finden Sie unter Anfordern von Kontingenterhöhungen für Azure SQL-Datenbank.
Grenzwerte für logische Server
| Resource | Begrenzung |
|---|---|
| Datenbanken pro logischem Server | 5.000 |
| Standardanzahl von logischen Servern pro Abonnement in einer Region | 250 |
| Maximale Anzahl von logischen Servern pro Abonnement in einer Region | 250 |
| Maximale Anzahl von Pools für elastische Datenbanken pro logischem Server | Begrenzt durch die Anzahl von DTUs oder virtuellen Kernen. Beispiel: Wenn jeder Pool 1.000 DTUs umfasst, kann ein Server 54 Pools unterstützen. |
Wichtig
Wenn sich die Anzahl der Datenbanken dem Grenzwert pro logischem Server nähert, kann Folgendes geschehen:
- Höhere Latenz bei der Ausführung von Abfragen, die die
master-Datenbank betreffen. Dies bezieht sich auch auf die Ansichten der Ressourcennutzungsstatistiken wie z. B.sys.resource_stats. - Höhere Latenz bei Verwaltungsvorgängen und dem Rendern von Portalblickpunkten. Dazu gehört auch das Aufzählen von Datenbanken auf dem Server.
Was geschieht, wenn Ressourcenlimits erreicht werden?
Compute (CPU)
Bei einer hohen Computenutzung (CPU-Auslastung) der Datenbank erhöht sich die Abfragelatenz – bis hin zu möglichen Abfragetimeouts. Unter diesen Bedingungen können Abfragen vom Dienst in die Warteschlange eingereiht werden, und dann werden Ressourcen für die Ausführung bereitgestellt, wenn Ressourcen frei werden.
Wenn Sie eine hohe Computenutzung feststellen, stehen folgende Optionen als Gegenmaßnahmen zur Verfügung:
- Erhöhen der Computegröße der Datenbank oder des Pools für elastische Datenbanken, um mehr Computeressourcen für die Datenbank bereitzustellen. Siehe Skalieren der Ressourcen für einzelne Datenbanken und Skalieren der Ressourcen für elastische Pools in Azure SQL-Datenbank.
- Optimieren von Abfragen, um die CPU-Ressourcennutzung der einzelnen Abfragen zu verringern. Weitere Informationen finden Sie unter Abfrageoptimierung/Abfragehinweise.
Storage
Wenn der verwendete Datenspeicherplatz die maximale Datengröße erreicht, entweder auf Datenbankebene oder auf Ebene des Pools für elastische Datenbanken, tritt bei Einfügungen und Updates, die die Datengröße erhöhen, ein Fehler auf, und Clients erhalten eine Fehlermeldung. SELECT- und DELETE-Anweisungen sind davon nicht betroffen.
Bei den Dienstebenen „Premium“ und „Unternehmenskritisch“ erhalten Clients auch eine Fehlermeldung, wenn der kombinierte Speicherverbrauch durch Daten, Transaktionsprotokoll und tempdb für ein Singleton oder einen Pool für elastische Datenbanken die maximale lokale Speichergröße überschreitet. Weitere Informationen finden Sie unter Speicherplatzgovernance.
Wenn Sie eine hohe Speicherplatzauslastung feststellen, stehen folgende Optionen als Gegenmaßnahmen zur Verfügung:
- Erhöhen Sie die maximale Datengröße der Datenbank oder des Pools für elastische Datenbanken, oder skalieren Sie auf ein Dienstziel mit einer höheren maximalen Datengröße hoch. Siehe Skalieren der Ressourcen für einzelne Datenbanken und Skalieren der Ressourcen für elastische Pools in Azure SQL-Datenbank.
- Wenn sich die Datenbank in einem Pool für elastische Datenbanken befindet, kann sie auch aus dem Pool heraus verschoben werden, damit ihr Speicherplatz nicht mit anderen Datenbanken geteilt wird.
- Verkleinern Sie eine Datenbank, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Verwalten von Dateispeicherplatz in Azure SQL-Datenbank.
- In Pools für elastische Datenbanken wird durch das Verkleinern einer Datenbank mehr Speicher für andere Datenbanken im Pool freigegeben.
- Überprüfen Sie, ob der Grund für die hohe Speicherplatznutzung eine Spitze bei der Größe des permanenten Versionsspeichers (PVS) ist. PVS ist ein Teil jeder Datenbank und wird zum Implementieren der beschleunigten Datenbankwiederherstellung verwendet. Informationen zum Ermitteln der aktuellen PVS-Größe finden Sie unter PVS-Problembehandlung. Ein häufiger Grund für eine große PVS-Größe ist eine Transaktion, die während eines langen Zeitraums (Stunden) geöffnet ist und so die Bereinigung älterer Datensatzversionen in PVS verhindert.
- Bei Datenbanken und elastischen Pools mit den Dienstebenen „Premium“ und „Unternehmenskritisch“, die große Mengen an Speicherplatz verbrauchen, erhalten Sie möglicherweise eine Fehler aufgrund unzureichenden Speicherplatzes, obwohl der in der Datenbank oder im Pool für elastische Datenbanken verwendete Speicherplatz unterhalb des maximalen Grenzwerts in Bezug auf die Datengröße liegt. Dies kann auftreten, wenn
tempdboder Transaktionsprotokolldateien sehr viel Speicherplatz bis fast zum maximalen lokalen Speichergrenzwert verbrauchen. Führen Sie ein Failover für die Datenbank oder den Pool für elastische Datenbanken aus, umtempdbauf die ursprüngliche, kleinere Größe zurückzusetzen, oder verkleinern Sie das Transaktionsprotokoll, um den lokalen Speicherverbrauch zu reduzieren.
Sitzungen, Mitarbeiter und Anfragen
Sitzungen, Arbeitskräfte und Anforderungen sind wie folgt definiert:
- Eine Sitzung stellt einen Prozess dar, der mit dem Datenbankmodul verbunden ist.
- Eine Anforderung ist die logische Darstellung einer Abfrage oder eines Batches. Eine Anforderung wird von einem Mit einer Sitzung verbundenen Client gesendet. Im Laufe der Zeit können mehrere Anfragen für dieselbe Sitzung ausgestellt werden.
- Ein Arbeitsthread, auch bekannt als Worker oder Thread, ist eine logische Darstellung eines Betriebssystemthreads. Eine Anforderung kann viele Worker haben, wenn sie mit einem parallelen Abfrageausführungsplan oder einem einzelnen Worker ausgeführt wird, wenn sie mit einem seriellen Ausführungsplan (Singlethreading) ausgeführt wird. Mitarbeiter müssen auch Aktivitäten außerhalb von Anforderungen unterstützen. Beispielsweise muss ein Mitarbeiter eine Anmeldeanforderung verarbeiten, während eine Sitzung verbunden wird.
Weitere Informationen zu diesen Konzepten finden Sie im Handbuch zur Thread- und Taskarchitektur.
Die maximale Anzahl von Workern wird durch die Dienstebene und Computegröße bestimmt. Neue Anforderungen werden abgelehnt, wenn Sitzung oder Worker Grenzwerte erreicht haben, und Clients erhalten eine Fehlermeldung. Während die Anzahl der Verbindungen von der Anwendung gesteuert werden kann, ist die Anzahl paralleler Worker oft schwieriger zu schätzen und zu steuern. Dies gilt insbesondere während der Spitzenlastzeiten, wenn Datenbankressourcenlimits erreicht werden und sich Worker aufgrund längerer Ausführungszeiten von Abfragen, langer Blockierungsketten oder einer übermäßigen Abfrageparallelität anhäufen.
Hinweis
Das anfängliche Angebot von Azure SQL-Datenbank nur Einzelthreadabfragen unterstützt. Zu diesem Zeitpunkt war die Anzahl der Anforderungen immer gleichbedeutend mit der Anzahl der Arbeitskräfte. Fehlermeldung 10928 in Azure SQL-Datenbank enthält den Wortlaut The request limit for the database is *N* and has been reached nur aus Gründen der Abwärtskompatibilität. Der Grenzwert ist tatsächlich die Anzahl der Arbeitskräfte.
Wenn Ihre Einstellung für den maximalen Grad von Parallelität (MAXDOP) gleich 0 oder größer als 1 ist, ist die Anzahl der Arbeitskräfte möglicherweise wesentlich höher als die Anzahl der Anforderungen, und der Grenzwert kann viel früher erreicht werden, als wenn MAXDOP gleich eins ist.
- Weitere Informationen zu Fehler 10928 finden Sie unter Ressourcen-Governance-Fehler.
- Erfahren Sie mehr über die Erschöpfung der Anforderungsgrenze in Fehlern 10928 und 10936.
Sie können verhindern, dass Mitarbeiter- oder Sitzungsgrenzwerte erreicht werden, indem Sie:
- Erhöhen der Dienstebene oder Computegröße der Datenbank oder des Pools für elastische Datenbanken. Siehe Skalieren der Ressourcen für einzelne Datenbanken und Skalieren der Ressourcen für elastische Pools in Azure SQL-Datenbank.
- Optimieren von Abfragen zur Verringerung der Ressourcenauslastung, wenn die Ursache für steigende Arbeitskräfte probleme bei Rechenressourcen sind. Weitere Informationen finden Sie unter Abfrageoptimierung/Abfragehinweise.
- Optimieren der Abfragearbeitsauslastung, um die Anzahl und Dauer von Abfrageblockierungen zu verringern. Weitere Informationen finden Sie unter Verstehen und Beheben von Problemen durch Blockierungen in Azure SQL.
- Verringern Sie gegebenfalls die MAXDOP-Einstellung.
Finden Sie Worker- und Sitzungsgrenzwerte für Azure SQL-Datenbank Dienstebene und Berechnungsgröße:
- Ressourcenlimits für Singletons mit dem auf virtuellen Kernen (V-Kernen) basierenden Kaufmodell
- Ressourcenlimits für Pools für elastische Datenbanken, die das V-Kern-Kaufmodell verwenden
- Ressourcenlimits für Einzeldatenbanken, die das DTU-Kaufmodell verwenden
- Grenzwerte für Ressourcen für Pools für elastische Datenbanken, die das DTU-Kaufmodell verwenden
Weitere Informationen zur Problembehandlung bestimmter Fehler für Sitzungs- oder Workergrenzwerte finden Sie unter Ressourcen-Governance-Fehler.
Externe Verbindungen
Die Anzahl gleichzeitiger Verbindungen mit externen Endpunkten, die über sp_invoke_external_rest_endpoint durchgeführt werden, sind auf 10 % der Arbeitsthreads begrenzt, wobei eine harte Obergrenze von max. 150 Mitarbeitern besteht.
Arbeitsspeicher
Im Gegensatz zu anderen Ressourcen (CPU, Worker, Speicher) wirkt sich das Erreichen des Arbeitsspeicherlimits nicht negativ auf die Abfrageleistung aus und führt nicht zu Fehlern und Ausfällen. Wie im Handbuch zur Architektur der Speicherverwaltung ausführlich beschrieben, wird von der Datenbank-Engine häufig absichtlich der gesamte verfügbare Arbeitsspeicher genutzt. Der Arbeitsspeicher wird hauptsächlich zum Zwischenspeichern von Daten verwendet, um langsamere Speicherzugriffe zu vermeiden. Daher führt eine höhere Arbeitsspeicherauslastung dank schnellerer Lesevorgänge aus dem Arbeitsspeicher (im Gegensatz zu langsameren Lesevorgängen aus dem Speicher) in der Regel zu einer besseren Abfrageleistung.
Wenn die Workload nach dem Start der Datenbank-Engine mit dem Lesen von Daten aus dem Speicher beginnt, werden Daten im Arbeitsspeicher dynamisch zwischengespeichert. Nach dieser anfänglichen Anlaufphase nähern sich in in sys.dm_db_resource_stats die Werte in den Spalten avg_memory_usage_percent und avg_instance_memory_percent häufig der 100-Prozent-Marke an oder erreichen diese sogar. Dies gilt insbesondere bei Datenbanken, die sich nicht im Leerlauf befinden und nicht vollständig in den Arbeitsspeicher passen.
Hinweis
Die sql_instance_memory_percent-Metrik spiegelt die Gesamtspeicherauslastung des Datenbankmoduls wider. Diese Metrik erreicht möglicherweise nicht 100 % auch dann, wenn Arbeitsauslastungen mit hoher Intensität ausgeführt werden. Dies liegt daran, dass ein kleiner Teil des verfügbaren Speichers für andere wichtige Speicherzuweisungen als den Datencache reserviert ist, z. B. Threadstapel und ausführbare Module.
Arbeitsspeicher wird aber nicht nur als Datencache, sondern auch in anderen Komponenten der Datenbank-Engine verwendet. Wenn Arbeitsspeicher benötigt wird und der gesamte verfügbare Arbeitsspeicher durch den Datencache beansprucht wurde, reduziert die Datenbank-Engine die Datencachegröße, um Arbeitsspeicher für andere Komponenten verfügbar zu machen. Der Datencache wird dynamisch vergrößert, wenn Arbeitsspeicher von anderen Komponenten freigegeben wird.
In seltenen Fällen kann eine besonders anspruchsvolle Workload dazu führen, dass nicht genügend Arbeitsspeicher zur Verfügung steht, was entsprechende Fehler zur Folge hat. Durch unzureichenden Arbeitsspeicher bedingte Fehler können bei jeder Speicherauslastung zwischen 0 % und 100 % auftreten. Durch unzureichenden Arbeitsspeicher bedingte Fehler entstehen tendenziell eher bei kleineren Computegrößen mit entsprechend niedrigerem Arbeitsspeicherlimit bzw. bei Workloads, bei denen mehr Arbeitsspeicher für die Abfrageverarbeitung beansprucht wird (beispielsweise in umfangreichen Pools für elastische Datenbanken).
Im Fall von Fehlern aufgrund von unzureichendem Arbeitsspeicher haben Sie unter anderem folgende Möglichkeiten:
- Überprüfen Sie die Details des OOM-Zustands in sys.dm_os_out_of_memory_events.
- Erhöhen der Dienstebene oder Computegröße der Datenbank oder des Pools für elastische Datenbanken. Siehe Skalieren der Ressourcen für einzelne Datenbanken und Skalieren der Ressourcen für elastische Pools in Azure SQL-Datenbank.
- Optimieren der Abfragen und der Konfiguration, um die Arbeitsspeicherauslastung zu verringern. Gängige Lösungen sind in der folgenden Tabelle beschrieben:
| Lösung | Beschreibung |
|---|---|
| Verkleinern von Speicherzuweisungen | Weitere Informationen zu Speicherzuweisungen finden Sie im Blogbeitrag Grundlegendes zu SQL Server-Speicherzuweisungen. Eine gängige Lösung zur Vermeidung übermäßig großer Speicherzuweisungen besteht darin, die Statistik auf dem neuesten Stand zu halten. Dies ermöglicht eine präzisere Schätzung der Arbeitsspeicherauslastung durch die Abfrage-Engine und die Vermeidung überdimensionierter Speicherzuweisungen. In Datenbanken mit Kompatibilitätsgrad 140 und höher kann die Datenbank-Engine standardmäßig die Speicherzuweisungsgröße unter Verwendung von Feedback zur Speicherzuweisung im Batchmodus automatisch anpassen. In Datenbanken mit Kompatibilitätsgrad 150 höher verwendet die Datenbank-Engine auf ähnliche Weise Feedback zur Speicherzuweisung im Zeilenmodus für gängigere Abfragen im Zeilenmodus. Diese integrierte Funktion trägt dazu bei, durch unzureichenden Arbeitsspeicher bedingte Fehler zu vermeiden, die auf überdimensionierte Speicherzuweisungen zurückzuführen sind. |
| Verkleinern des Abfrageplancaches | Von der Datenbank-Engine werden Abfragepläne im Arbeitsspeicher zwischengespeichert, um zu vermeiden, dass für jede Abfrageausführung ein Abfrageplan kompiliert wird. Um eine Überfrachtung des Cache für Abfragepläne zu vermeiden, die durch das Zwischenspeichern von Plänen verursacht wird, die nur einmal verwendet werden, sollten Sie parametrisierte Abfragen verwenden und die Aktivierung der datenbankübergreifenden Konfiguration OPTIMIZE_FOR_AD_HOC_WORKLOADS in Betracht ziehen. |
| Verkleinern des für Sperren beanspruchten Arbeitsspeichers | Von der Datenbank-Engine wird Arbeitsspeicher für Sperren verwendet. Vermeiden Sie nach Möglichkeit umfangreiche Transaktionen mit zahlreichen Sperren, die eine hohe Auslastung des für Sperren beanspruchten Arbeitsspeichers zur Folge haben. |
Ressourcenauslastung durch Benutzerarbeitsauslastungen und interne Prozesse
Azure SQL-Datenbank benötigt Computeressourcen zur Implementierung zentraler Dienstfeatures wie Hochverfügbarkeit und Notfallwiederherstellung, Datenbanksicherung und -wiederherstellung, Überwachung, Abfragespeicher, automatische Optimierung und Ähnliches. Ein gewisser Teil der Gesamtressourcen wird mithilfe von Mechanismen der Ressourcengovernance für diese internen Prozesse reserviert. Die übrigen Ressourcen stehen für Benutzerarbeitsauslastungen zur Verfügung. Wenn von internen Prozessen keine Computeressourcen beansprucht werden, werden die Ressourcen für Benutzerworkloads bereitgestellt.
Die Gesamtauslastung für CPU und Arbeitsspeicher durch Benutzerarbeitsauslastungen und interne Prozesse wird in den Spalten avg_instance_cpu_percent und avg_instance_memory_percent der Sichten sys.dm_db_resource_stats und sys.resource_stats gemeldet. Diese Daten werden auch über die Azure Monitor-Metriken sql_instance_cpu_percent und sql_instance_memory_percent gemeldet, und zwar für Einzeldatenbanken und für Pools für elastische Datenbanken auf Poolebene.
Hinweis
Die Azure Monitor-Metriken sql_instance_cpu_percent und sql_instance_memory_percent sind seit Juli 2023 verfügbar. Sie entsprechen vollständig den zuvor verfügbaren Metriken sqlserver_process_core_percent bzw. sqlserver_process_memory_percent. Die beiden letztgenannten Metriken sind weiterhin verfügbar, werden aber in Zukunft entfernt. Um eine Unterbrechung der Datenbanküberwachung zu vermeiden, sollten Sie die älteren Metriken nicht verwenden.
Diese Metriken sind für Datenbanken mit den Dienstzielen Basic, S1 und S2 nicht verfügbar. Dieselben Daten sind in den nachfolgenden dynamischen Verwaltungsansichten verfügbar.
Die CPU- und Arbeitsspeicherauslastung durch Benutzerarbeitsauslastungen in den einzelnen Datenbanken wird in den Spalten avg_cpu_percent und avg_memory_usage_percent der Sichten sys.dm_db_resource_stats und sys.resource_stats gemeldet. Für Pools für elastische Datenbanken wird der Ressourcenverbrauch auf Poolebene in der Ansicht sys.elastic_pool_resource_stats (für historische Berichtsszenarien) und in sys.dm_elastic_pool_resource_stats für die Echtzeitüberwachung gemeldet. Die CPU-Auslastung durch Benutzerarbeitsauslastungen wird auch über die Azure Monitor-Metrik cpu_percent gemeldet, und zwar für Einzeldatenbanken und für Pools für elastische Datenbanken auf Poolebene.
Eine detailliertere Aufschlüsselung der aktuellen Ressourcenauslastung durch Benutzerarbeitsauslastungen und interne Prozesse finden Sie in den Sichten sys.dm_resource_governor_resource_pools_history_ex und sys.dm_resource_governor_workload_groups_history_ex. Ausführliche Informationen zu Ressourcenpools und Arbeitsauslastungsgruppen, auf die in diesen Sichten verwiesen wird, finden Sie unter Ressourcengovernance. In diesen Sichten wird die Ressourcenverwendung durch Benutzerarbeitsauslastungen und bestimmte interne Prozesse in den zugeordneten Ressourcenpools und Arbeitsauslastungsgruppen gemeldet.
Tipp
Bei der Überwachung oder Problembehandlung der Workloadleistung muss sowohl die benutzerspezifische CPU-Auslastung (avg_cpu_percent, cpu_percent) als auch die CPU-Gesamtauslastung durch Benutzerworkloads und interne Prozesse (avg_instance_cpu_percent, sql_instance_cpu_percent) berücksichtigt werden. Die Leistung kann spürbar beeinträchtigt werden, wenn sich eine dieser Metriken im Bereich von 70 bis 100 % befindet.
Die benutzerspezifische CPU-Auslastung wird als Prozentsatz der Grenzwerte für Benutzerarbeitsauslastungen in den einzelnen Dienstzielen definiert. Ebenso ist die CPU-Gesamtauslastung als Prozentsatz der CPU-Grenzwerte für alle Workloads definiert. Da die beiden Schwellenwerte unterschiedlich sind, werden die benutzerspezifische und die gesamte CPU-Auslastung auf unterschiedlichen Skalen gemessen und sind nicht direkt vergleichbar.
Wenn die benutzerspezifische CPU-Auslastung 100 % erreicht, bedeutet dies, dass die Benutzerworkload die ihr im ausgewählten Dienstziel zur Verfügung stehende CPU-Kapazität vollständig nutzt, auch wenn die CPU-Gesamtauslastung unter 100 % bleibt.
Wenn sich der Gesamt-CPU-Verbrauch im Bereich von 70-100 % bewegt, kann es sein, dass der Durchsatz der Benutzerworkload abflacht und die Abfragelatenz steigt, auch wenn der CPU-Verbrauch des Benutzers deutlich unter 100 % bleibt. Dieses Verhalten wird durch die Verwendung kleinerer Dienstziele mit einer moderaten Zuordnung von Computeressourcen, aber relativ intensiven Benutzerarbeitsauslastungen (etwa in umfangreichen Pools für elastische Datenbanken) begünstigt. Es kann aber auch bei kleineren Dienstzielen auftreten, wenn interne Prozesse vorübergehend zusätzliche Ressourcen benötigen, etwa beim Erstellen eines neuen Replikats der Datenbank oder beim Sichern der Datenbank.
Wenn der CPU-Verbrauch des Benutzers den Bereich von 70-100 % erreicht, wird der Durchsatz des Benutzerworkloads flacher und die Abfragelatenz steigt, auch wenn der Gesamt-CPU-Verbrauch weit unter dem Grenzwert liegt.
Wenn entweder die benutzerspezifische CPU-Auslastung oder die Gesamt-CPU-Auslastung hoch ist, gibt es dieselben Abhilfemaßnahmen wie im Abschnitt Compute CPU beschrieben. Hierzu zählen unter anderem die Erhöhung des Dienstziels und/oder die Optimierung der Benutzerworkload.
Hinweis
Selbst bei einer vollständig inaktiven Datenbank oder einem inaktiven Pool für elastische Datenbanken liegt der CPU-Gesamtverbrauch aufgrund von Hintergrundaktivitäten der Datenbank-Engine nie bei Null. Abhängig von den spezifischen Hintergrundaktivitäten, der Computegröße und der vorherigen Benutzerworkload kann der Verbrauch großen Schwankungen unterliegen.
Ressourcengovernance
Zur Erzwingung von Ressourcenlimits verwendet Azure SQL-Datenbank eine auf SQL Server Resource Governor basierende Implementierung der Ressourcengovernance, die für die Ausführung in der Cloud modifiziert und erweitert wurde. In SQL-Datenbank stellen mehrere Ressourcenpools und Arbeitsauslastungsgruppen mit Ressourcenlimits, die auf Pool- und Gruppenebene festgelegt werden, eine ausgeglichene Database-as-a-Service-Lösung bereit. Die Benutzerarbeitsauslastung und interne Workloads werden in separate Ressourcenpools und Arbeitsauslastungsgruppen eingeteilt. Die Benutzerarbeitsauslastung auf den primären und lesbaren sekundären Replikaten, einschließlich Georeplikaten, wird in den Ressourcenpool SloSharedPool1 und in UserPrimaryGroup.DBId[N]-Arbeitsauslastungsgruppen eingeteilt, wobei [N] für den Datenbank-ID-Wert steht. Außerdem gibt es mehrere Ressourcenpools und Arbeitsauslastungsgruppen für verschiedene interne Workloads.
Zusätzlich zur Verwendung von Resource Governor zum Steuern von Ressourcen innerhalb der Datenbank-Engine verwendet Azure SQL-Datenbank auch Windows-Auftragsobjekte für die Ressourcengovernance auf Prozessebene und den Ressourcen-Manager für Dateiserver (File Server Resource Manager, FSRM) von Windows für die Verwaltung von Speicherkontingenten.
Die Azure SQL-Datenbank-Ressourcenkontrolle ist hierarchisch strukturiert. Grenzwerte werden von oben nach unten auf Betriebssystemebene und auf Speichervolumeebene mithilfe von Betriebssystem-Ressourcenkontrollmechanismen und Resource Governor, dann auf Ressourcenpoolebene mithilfe von Resource Governor und dann auf Arbeitsauslastungsgruppenebene mithilfe von Resource Governor erzwungen. Die für die aktuelle Datenbank oder den aktuellen Pool für elastische Datenbanken geltenden Grenzwerte der Ressourcengovernance werden in der Ansicht sys.dm_user_db_resource_governance angezeigt.
Daten-E/A-Kontrolle
In Azure SQL-Datenbank ist die Daten-E/A-Kontrolle ein Prozess zum Begrenzen der physischen E/A-Lese- und -Schreibvorgänge für Datendateien einer Datenbank. IOPS-Grenzwerte werden für jedes Servicelevel festgelegt, um den „Noisy Neighbor“-Effekt zu minimieren, eine gerechte Ressourcenzuordnung in einem mehrinstanzenfähigen Dienst zu gewährleisten und die Funktionen der zugrunde liegenden Hardware- und Speicherkomponenten zu unterstützen.
Bei Einzeldatenbanken gelten die Grenzwerte für Arbeitsauslastungsgruppen für alle Speicher-E/A-Vorgänge in der Datenbank. Bei Pools für elastische Datenbanken gelten die Grenzwerte für Arbeitsauslastungsgruppen für jede Datenbank im Pool. Darüber hinaus gilt der Grenzwert für den Ressourcenpool zusätzlich für die kumulativen E/A-Vorgänge des Pools für elastische Datenbanken. E/A-Vorgänge in tempdb unterliegen den Grenzwerten für Arbeitsauslastungsgruppen. Eine Ausnahme bilden die Dienstebenen Basic, Standard und Universell, für die höhere Grenzwerte für tempdb-E/A-Vorgänge gelten. Im Allgemeinen können die Grenzwerte für Ressourcenpools nicht von der Workload einer Datenbank (entweder einzeln oder in einem Pool) erreicht werden, weil die Grenzwerte für Arbeitsauslastungsgruppen niedriger sind als die Grenzwerte für Ressourcenpools und IOPS/den Durchsatz früher begrenzen. Poolgrenzwerte können jedoch von der kombinierten Workload mehrerer Datenbanken im selben Pool erreicht werden.
Beispiel: Wenn eine Abfrage 1000 IOPS ohne E/A-Ressourcenkontrolle generiert, der maximale IOPS-Grenzwert für die Arbeitsauslastungsgruppe aber auf 900 IOPS festgelegt ist, kann die Abfrage maximal 900 IOPS generieren. Wenn der maximale IOPS-Grenzwert für den Ressourcenpool jedoch auf 1500 IOPS festgelegt ist und die Gesamtanzahl der E/A-Vorgänge aller dem Ressourcenpool zugeordneten Arbeitsauslastungsgruppen 1500 IOPS überschreitet, kann die Anzahl der E/A-Vorgänge der gleichen Abfrage so reduziert werden, dass sie unter dem Grenzwert von 900 IOPS liegt.
Die von der Sicht sys.dm_user_db_resource_governance zurückgegebenen Höchstwerte für IOPS und Durchsatz gelten als Grenzwerte/Obergrenzen, nicht als Garantien. Darüber hinaus garantiert die Ressourcenkontrolle keine bestimmte Speicherlatenz. Die bestmöglichen erreichbaren Latenz-, IOPS- und Durchsatzwerte für eine bestimmte Benutzerarbeitsauslastung hängen nicht nur von den Grenzwerten der E/A-Ressourcenkontrolle, sondern auch von der Kombination aus verwendeten E/A-Größen und den Funktionen des zugrunde liegenden Speichers ab. Von SQL-Datenbank werden E/A-Vorgänge in Größenordnungen zwischen 512 Byte und 4 MB verwendet. Zur Erzwingung der IOPS-Grenzwerte wird jeder E/A-Vorgang unabhängig von seiner Größe berücksichtigt, mit Ausnahme von Datenbanken mit Datendateien in Azure Storage. In diesem Fall werden E/A-Vorgänge, die größer als 256 KB sind, als mehrere E/A-Vorgänge mit 256 KB berücksichtigt, um sie mit der E/A-Berücksichtigung von Azure Storage abzustimmen.
Bei Datenbanken vom Typ „Basic“, „Standard“ und „Universell“, die Datendateien in Azure Storage verwenden, kann der Wert primary_group_max_io möglicherweise nicht erreicht werden, wenn eine Datenbank nicht über genügend Datendateien verfügt, um diese Anzahl von IOPS kumulativ bereitzustellen, die Daten nicht gleichmäßig auf die Dateien verteilt sind oder die Leistungsstufe der zugrunde liegenden Blobs die IOPS bzw. den Durchsatz auf einen Wert begrenzt, der unter den Grenzwerten der Ressourcenkontrolle liegt. Ebenso kann der primary_max_log_rate-Wert bei kleinen Protokoll-E/A-Vorgängen, die durch häufige Transaktionscommits generiert werden, aufgrund des IOPS-Grenzwerts des zugrunde liegenden Azure Storage-Blobs möglicherweise nicht von einer Workload erreicht werden. Für Datenbanken, die Azure Storage Premium verwenden, verwendet Azure SQL-Datenbank ausreichend große Speicherblobs, um die benötigten IOPS bzw. den Durchsatz unabhängig von der Datenbankgröße zu erhalten. Bei größeren Datenbanken werden mehrere Datendateien erstellt, um die Kapazität für die gesamten IOPS bzw. den Durchsatz zu erhöhen.
In den Ansichten sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats und sys.elastic_pool_resource_stats erfasste Ressourcennutzungswerte wie avg_data_io_percent und avg_log_write_percent werden als Prozentsätze der maximalen Grenzwerte der Ressourcenkontrolle berechnet. Wenn andere Faktoren als die Ressourcenkontrolle die IOPS/den Durchsatz einschränken, kann es daher bei zunehmender Arbeitsauslastung zu einer Abflachung der IOPS/des Durchsatzes sowie zu höheren Latenzen kommen, auch wenn die gemeldete Ressourcenauslastung unter 100 Prozent bleibt.
Wenn Sie Werte für Lese- und Schreib-IOPS, Durchsatz und Latenz pro Datenbankdatei überwachen möchten, verwenden Sie die sys.dm_io_virtual_file_stats()-Funktion. Diese Funktion zeigt alle E/A-Vorgänge für die Datenbank – einschließlich E/A-Vorgänge im Hintergrund, die nicht für avg_data_io_percent berücksichtigt werden, aber IOPS und Durchsatz des zugrunde liegenden Speichers beanspruchen und sich auf die Speicherlatenz auswirken können. Die Funktion meldet eine zusätzliche Latenz, die möglicherweise durch die E/A-Ressourcenkontrolle für Lese- und Schreibvorgänge in den Spalten io_stall_queued_read_ms bzw. io_stall_queued_write_ms entsteht.
Transaktionsprotokollratengovernance
Als Transaktionsprotokollratengovernance wird der Prozess in Azure SQL-Datenbank bezeichnet, der verwendet wird, um hohe Datenerfassungsraten für Workloads zu begrenzen, z. B. für Masseneinfügung (BULK INSERT), SELECT INTO und für die Indizierung. Diese Grenzwerte werden für die Rate, in der Protokolleinträge generiert werden, in Sekundenbruchteilen verfolgt und erzwungen. Dadurch wird der Durchsatz unabhängig von den E/A-Größen der Datendateien eingeschränkt. Die Raten für die Generierung von Transaktionsprotokollen skalieren derzeit linear bis zu einem Punkt, der von der Hardware und der Dienstebene abhängt.
Protokollraten werden so festgelegt, dass sie in einer Vielzahl von Szenarios erreicht und erhalten werden können, während das gesamte System seine Funktionalität mit minimalen Einbußen bei der Benutzerauslastung beibehalten kann. Die Protokollratengovernance sorgt dafür, dass sich Transaktionsprotokollsicherungen innerhalb veröffentlichter Vereinbarungen zum Servicelevel für die Wiederherstellbarkeit bewegen. Diese Governance verhindert auch ein übermäßiges Backlog bei sekundären Replikaten, das andernfalls bei Failovern zu längeren Ausfallzeiten als erwartet führen könnte.
Die tatsächlichen physischen E/A-Größen für Transaktionsprotokolldateien sind nicht gesteuert oder beschränkt. Während die Protokolleinträge generiert werden, wird jeder Vorgang ausgewertet und es wird eingeschätzt, ob er verzögert werden soll, um eine maximal erwünschte Protokollrate aufrechtzuerhalten (MB/s). Die Verzögerungen werden nicht hinzugefügt, wenn die Protokolleinträge in den Speicher geleert werden. Vielmehr wird die Protokollratengovernance während der Generierung der Protokollrate selbst angewendet.
Die tatsächlichen Protokollgenerierungsraten, die während der Laufzeit durchgesetzt werden, werden auch von Feedbackmechanismen beeinflusst. Dadurch wird die zulässige Protokollrate zeitweise reduziert, damit sich das System stabilisieren kann. Die Speicherplatzverwaltung für die Protokolldatei, mit der vermieden wird, dass nicht mehr genug Protokollspeicherplatz und Datenreplikationsmechanismen vorhanden sind, kann zeitweise zu einer Verringerung der gesamten Begrenzungen für das System führen.
Die Datenverkehrsmodellierung der Protokollratenbegrenzung erfolgt über die folgenden Wartetypen (über die Sichten sys.dm_exec_requests und sys.dm_os_wait_stats bereitgestellt):
| Wartetyp | Hinweise |
|---|---|
LOG_RATE_GOVERNOR |
Datenbankbegrenzung |
POOL_LOG_RATE_GOVERNOR |
Poolbegrenzung |
INSTANCE_LOG_RATE_GOVERNOR |
Instanzebenenbegrenzung |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Feedbackkontrolle; physische Replikation von Verfügbarkeitsgruppen in den Tarifen „Premium“/„Unternehmenskritisch“ zu langsam |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Feedbacksteuerung; Raten werden beschränkt, um eine Situation zu vermeiden, in der der Speicherplatz für Protokolle ausgeht |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Feedbacksteuerung für Georeplikation, Begrenzen der Protokollrate, um hohe Datenlatenz und Nichtverfügbarkeit von sekundären Georeplikaten zu vermeiden. |
Wenn es zu einer Begrenzung der Protokollrate zu kommen droht, die die gewünschte Skalierbarkeit beeinträchtigt, können Sie die folgenden Optionen in Erwägung ziehen:
- Skalieren Sie auf ein höheres Servicelevel, um die maximale Protokollrate der Dienstebene zu erhalten, oder wechseln Sie zu einer anderen Dienstebene. Die Dienstebene Hyperscale bietet eine Protokollrate von 100 MB/s pro Datenbank und 125 MB/s pro Pool für elastische Datenbanken, unabhängig vom gewählten Servicelevel. Protokollgenerierungsrate von 150 MB/s ist als Opt-In-Previewfunktion verfügbar. Weitere Informationen und die Möglichkeit, sich für 150 MB/s zu entscheiden, finden Sie im Blog: Hyperscale-Erweiterungen im November 2024.
- Wenn die Daten, die geladen werden, kurzlebig sind, wie z. B. Stagingdaten in einem ETL-Prozess, können sie in eine
tempdbgeladen werden (für die nur die minimal notwendigen Protokolle erstellt werden). - In Analyseszenarien laden Sie die Daten in eine geclusterte columnstore-Tabelle oder eine Tabelle, deren Indizes Datenkomprimierung verwenden. Dadurch reduziert sich die benötigte Protokollrate. Dieses Vorgehen erhöht jedoch die CPU-Auslastung und eignet sich nur für Datasets, die von gruppierten columnstore-Indizes oder Datenkomprimierung profitieren.
Speicherplatzgovernance
Bei den Dienstebenen „Premium“ und „Unternehmenskritisch“ werden Kundendaten wie Datendateien, Transaktionsprotokolldateien und tempdb-Dateien im lokalen SSD-Speicher des Computers gespeichert, der die Datenbank oder den Pool für elastische Datenbanken hostet. Der lokale SSD-Speicher bietet hohe IOPS-und Durchsatzwerte sowie eine niedrige E/A-Latenz. Zusätzlich zu den Kundendaten wird der lokale Speicher für das Betriebssystem, die Verwaltungssoftware, Überwachungsdaten und Protokolle sowie andere Dateien verwendet, die für den Systembetrieb erforderlich sind.
Die Größe des lokalen Speichers ist begrenzt und hängt von Hardwarefunktionen ab, die den maximalen lokalen Speichergrenzwert bestimmen, oder von lokalem Speicher, der für Kundendaten reserviert ist. Dieser Grenzwert wird festgelegt, um den Speicherplatz für Kundendaten zu maximieren und gleichzeitig einen sicheren und zuverlässigen Systembetrieb sicherzustellen. Den Wert für den maximalen lokalen Speicher für jedes Dienstziel finden Sie in der Dokumentation zu Ressourcenlimits für Einzeldatenbanken und Pools für elastische Datenbanken.
Sie können diesen Wert und die Menge des lokalen Speichers, der derzeit von einer bestimmten Datenbank oder einem bestimmten Pool für elastische Datenbanken verwendet wird, auch mithilfe der folgenden Abfrage ermitteln:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Spalte | Beschreibung |
|---|---|
server_name |
Name des logischen Servers |
database_name |
Datenbankname |
slo_name |
Name des Dienstziels, einschließlich Hardwaregeneration |
user_data_directory_space_quota_mb |
Maximaler lokaler Speicher in MB |
user_data_directory_space_usage_mb |
Aktueller lokaler Speicherverbrauch durch Datendateien, Transaktionsprotokolldateien und tempdb-Dateien in MB. Wird alle fünf Minuten aktualisiert. |
Diese Abfrage sollte in der Benutzerdatenbank und nicht in der master-Datenbank ausgeführt werden. Bei Pools für elastische Datenbanken kann die Abfrage in einer beliebigen Datenbank im Pool ausgeführt werden. Die zurückgegebenen Werte gelten für den gesamten Pool.
Wichtig
Wenn die Workload in den Dienstebenen „Premium“ und „Unternehmenskritisch“ versucht, den kombinierten lokalen Speicherverbrauch durch Datendateien, Transaktionsprotokolldateien und tempdb-Dateien über den maximalen lokalen Speichergrenzwert zu erhöhen, tritt ein Fehler aufgrund von unzureichendem Speicherplatz auf. Dies geschieht auch dann, wenn der belegte Speicherplatz in einer Datenbankdatei nicht die maximale Größe der Datei erreicht hat.
Lokaler SSD-Speicher wird auch von Datenbanken in anderen Dienstebenen als Premium und Unternehmenskritisch für die tempdb-Datenbank und den Hyperscale-RBPEX-Cache verwendet. Wenn Datenbanken erstellt oder gelöscht werden und ihr Speicherplatzverbrauch erhöht bzw. verringert wird, schwankt die lokale insgesamte Speicherplatzbelegung auf einem Computer im Lauf der Zeit. Wenn das System erkennt, dass der verfügbare freie Speicherplatz auf einem Computer gering ist und eine Datenbank oder ein Pool für elastische Datenbanken nicht mehr über genügend Speicherplatz verfügt, wird die Datenbank oder der Pool für elastische Datenbanken auf einen anderen Computer mit ausreichend freiem lokalem Speicherplatz verschoben.
Wie bei einem Datenbankskalierungsvorgang erfolgt diese Verschiebung online und hat eine ähnliche Auswirkung (kurzes Failover von mehreren Sekunden am Ende des Vorgangs). Dieses Failover beendet offene Verbindungen und führt ein Rollback für Transaktionen durch, die sich potenziell auf Anwendungen auswirken, die zu diesem Zeitpunkt die Datenbank verwenden.
Da alle Daten auf lokale Speichervolumes auf verschiedenen Computern kopiert werden, kann es möglicherweise lange dauern, größere Datenbanken in den Dienstebenen „Premium“ und „Unternehmenskritisch“ zu verschieben. Wenn der lokale Speicherplatz während dieser Zeit von einer Datenbank oder einem Pool für elastische Datenbanken beansprucht wird oder die tempdb-Datenbank schnell wächst, steigt das Risiko, dass der gesamte Speicherplatz aufgebraucht ist. Das System initiiert die Datenbankverschiebung auf eine ausgeglichene Weise, um Fehler aufgrund von nicht genügend Speicherplatz und unnötige Failover zu vermeiden.
tempdb-Größen
Größenbeschränkungen für tempdb in Azure SQL-Datenbank sind vom Kauf- und Bereitstellungsmodell abhängig.
Sehen Sie sich die Größenbeschränkungen für tempdb für folgende Modelle an, um mehr zu erfahren:
- vCore-Kaufmodell: Einzeldatenbanken, Pooldatenbanken
- DTU-Kaufmodell: Einzeldatenbanken, Pooldatenbanken
Zuvor verfügbare Hardware
Dieser Abschnitt enthält Details zu zuvor verfügbarer Hardware.
- Gen4-Hardware wurde eingestellt und steht für Bereitstellung sowie Hoch- oder Herunterskalierung nicht zur Verfügung. Migrieren Sie Ihre Datenbank zu einer unterstützten Hardwaregeneration, um eine größere Bandbreite bei der Skalierbarkeit von virtuellen Kernen und Arbeitsspeicher, beschleunigten Netzwerkbetrieb, optimale E/A-Leistung und minimale Latenz zu erzielen. Weitere Informationen finden Sie unter Einstellung des Supports für Gen4-Hardware in Azure SQL-Datenbank.
Sie können Azure Resource Graph Explorer verwenden, um alle Azure SQL-Datenbank-Ressourcen zu identifizieren, die derzeit Gen4-Hardware verwenden, oder Sie können die von Ressourcen verwendete Hardware für einen bestimmten logischen Server im Azure-Portal überprüfen.
Sie benötigen mindestens read-Berechtigungen für das Azure-Objekt oder die Azure-Objektgruppe, um Ergebnisse in Azure Resource Graph Explorer anzuzeigen.
Führen Sie die folgenden Schritte aus, um Resource Graph Explorer zum Identifizieren von Azure SQL-Ressourcen zu verwenden, die noch Gen4-Hardware verwenden:
Öffnen Sie das Azure-Portal.
Suchen Sie über das Suchfeld nach
Resource graph, und wählen Sie in den Suchergebnissen den Dienst Resource Graph Explorer aus.Geben Sie im Abfragefenster die folgende Abfrage ein, und wählen Sie dann Abfrage ausführen aus:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"Im Bereich Ergebnisse werden alle derzeit in Azure bereitgestellten Ressourcen angezeigt, die Gen4-Hardware verwenden.
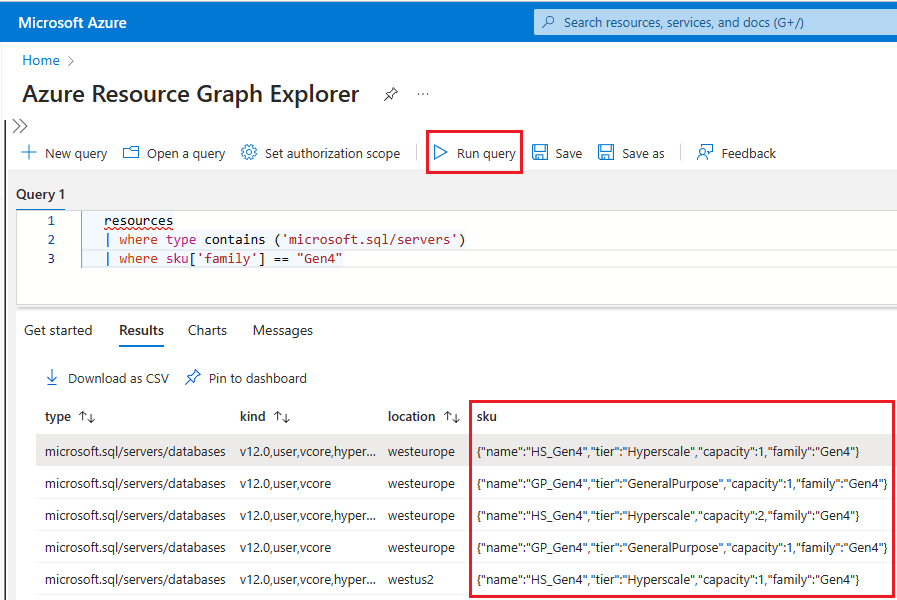
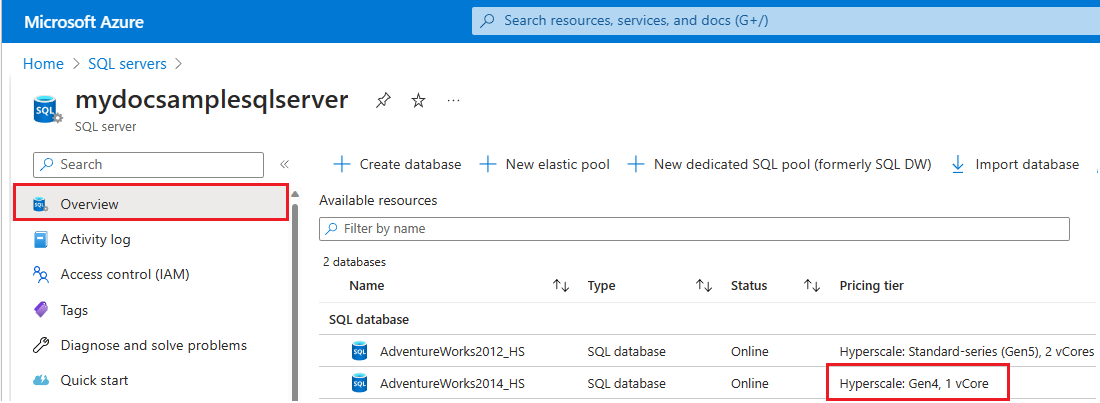
Führen Sie die folgenden Schritte aus, um die von Ressourcen verwendete Hardware für einen bestimmten logischen Server in Azure zu überprüfen:
- Öffnen Sie das Azure-Portal.
- Suchen Sie über das Suchfeld nach
SQL servers, und wählen Sie in den Suchergebnissen SQL Server-Instanzen aus, um die Seite SQL Server-Instanzen zu öffnen und alle Server für die ausgewählten Abonnements anzuzeigen. - Wählen Sie den gewünschten Server aus, um die Seite Übersicht für den Server zu öffnen.
- Scrollen Sie nach unten zu den verfügbaren Ressourcen, und überprüfen Sie die Spalte Tarif für Ressourcen, die Gen4-Hardware verwenden.
Informationen zum Migrieren von Ressourcen zu Hardware der Standardserie finden Sie unter Auswählen der Hardwarekonfiguration.
Zugehöriger Inhalt
- Informationen zu allgemeinen Azure-Einschränkungen finden Sie unter Einschränkungen für Azure-Abonnements und Dienste, Kontingente und Einschränkungen.
- Informationen zu DTUs und eDTUs finden Sie unter Datenbanktransaktionseinheiten (DTUs) und elastische Datenbanktransaktionseinheiten (eDTUs).
- Informationen zu Größenbeschränkungen für
tempdbfinden Sie unter Ressourcenlimits für Singletons mit dem auf virtuellen Kernen (V-Kernen) basierenden Kaufmodell, Ressourcenlimits für Pools für elastische Datenbanken, die das V-Kern-Kaufmodell verwenden, Ressourcengrenzwerte für Einzeldatenbanken, die das DTU-Kaufmodell verwenden: Azure SQL-Datenbank und Grenzwerte für Ressourcen für Pools für elastische Datenbanken, die das DTU-Kaufmodell verwenden.