Tutorial: Erkennen und Analysieren von Anomalien mit den KQL-Funktionen für maschinelles Lernen in Azure Monitor
Die Kusto-Abfragesprache (Kusto Query Language, KQL) umfasst Machine Learning-Operatoren, -Funktionen und Plug-Ins für Zeitreihenanalysen, Anomalieerkennung, Prognosen und Ursachenanalyse. Nutzen Sie diese KQL-Funktionen, um erweiterte Datenanalysen in Azure Monitor durchzuführen – ganz ohne den Aufwand, der mit dem Export von Daten in externe Tools für maschinelles Lernen verbunden ist.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen einer Zeitreihe
- Identifizieren von Anomalien in einer Zeitreihe
- Optimieren der Anomalieerkennungseinstellungen zum Verfeinern von Ergebnissen
- Analysieren der Grundursache von Anomalien
Hinweis
Dieses Tutorial enthält Links zu einer Log Analytics-Demo-Umgebung, in der Sie die KQL-Abfragebeispiele ausführen können. Die Daten in der Demoumgebung sind dynamisch, sodass die Abfrageergebnisse nicht mit den in diesem Artikel gezeigten Abfrageergebnissen übereinstimmen. Sie können jedoch dieselben KQL-Abfragen und Prinzipale in Ihrer eigenen Umgebung und alle Azure Monitor-Tools implementieren, die KQL verwenden.
Voraussetzungen
- Ein Azure-Konto mit einem aktiven Abonnement. Sie können kostenlos ein Konto erstellen.
- Ein Arbeitsbereich mit Protokolldaten.
Erforderliche Berechtigungen
Sie müssen über Microsoft.OperationalInsights/workspaces/query/*/read-Berechtigungen für die Log Analytics-Arbeitsbereiche verfügen, die Sie abfragen, wie sie z. B. von der integrierten Log Analytics-Reader-Rolle bereitgestellt werden.
Erstellen einer Zeitreihe
Verwenden Sie den KQL-Operator make-series, um eine Zeitreihe zu erstellen.
Lassen Sie uns eine Zeitreihe erstellen, die auf Protokollen in der Tabelle Usage beruht. Diese Tabelle enthält Informationen darüber, wie viele Daten jede Tabelle in einem Arbeitsbereich pro Stunde erfasst, fakturierbare und nicht fakturierbare Daten eingeschlossen.
Diese Abfrage verwendet make-series, um die Gesamtmenge der fakturierbaren Daten darzustellen, die von jeder Tabelle im Arbeitsbereich in den letzten 21 Tagen täglich erfasst wurden:
Zum Ausführen der Abfrage klicken
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
Im resultierenden Diagramm sind deutlich einige Anomalien zu erkennen – zum Beispiel bei den Datentypen AzureDiagnostics und SecurityEvent:
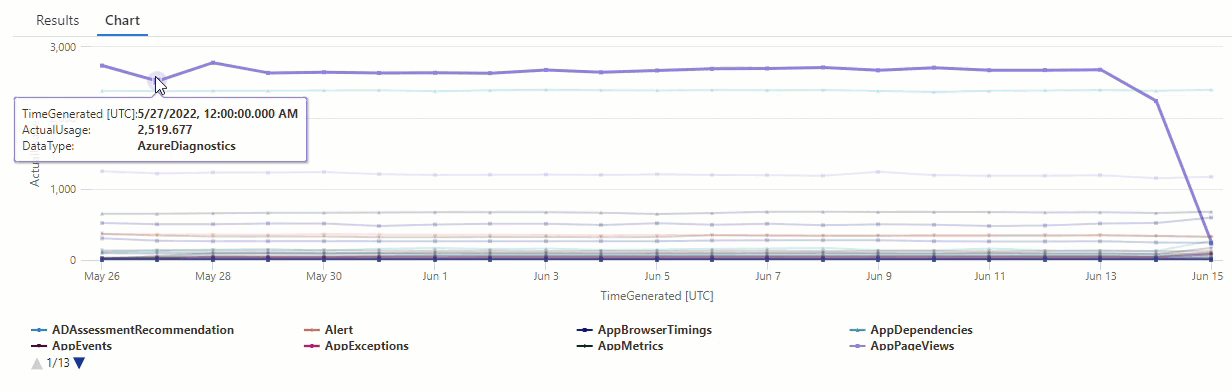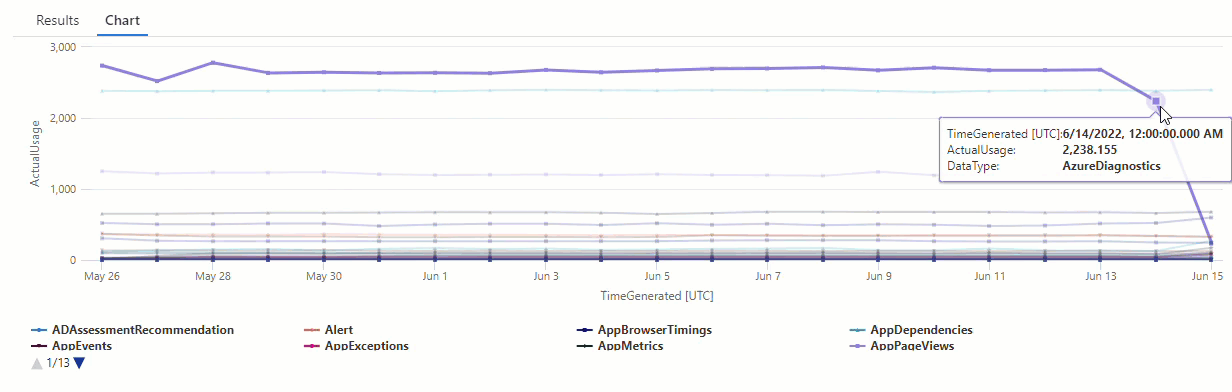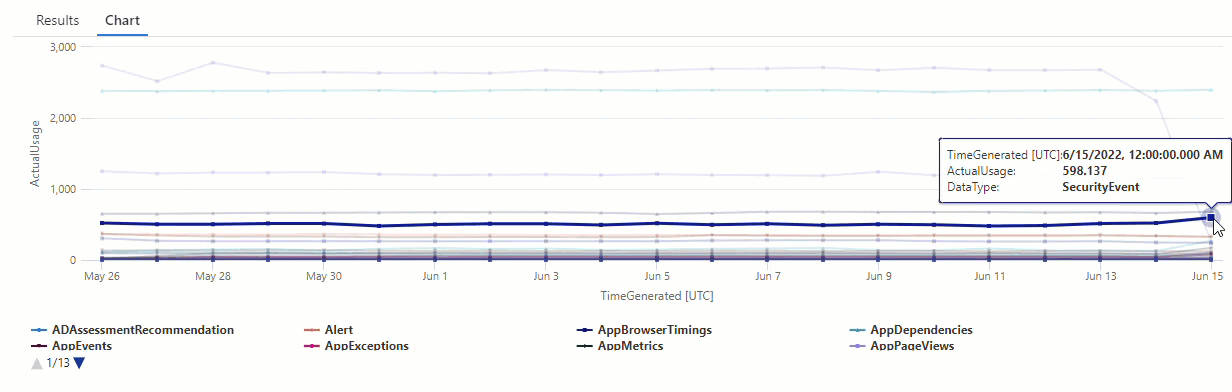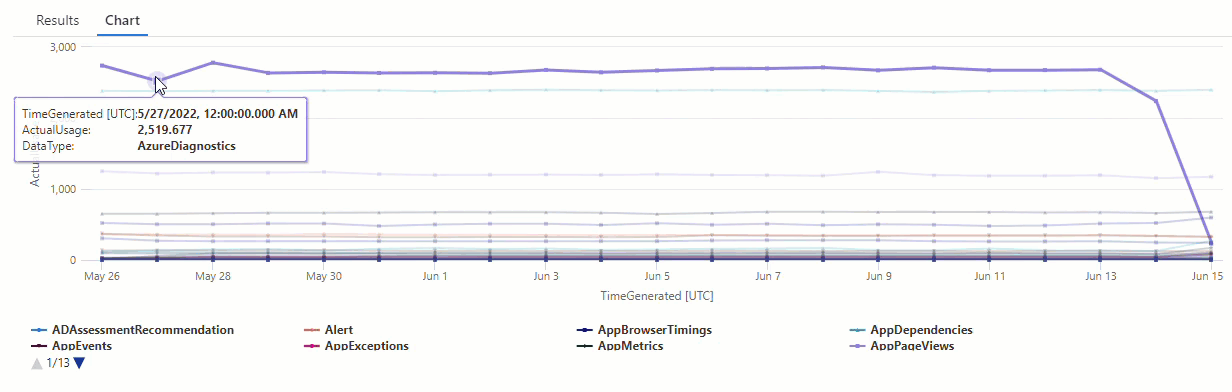
Als Nächstes listen wir mithilfe einer KQL-Funktion alle Anomalien in einer Zeitreihe auf.
Hinweis
Weitere Informationen zur Syntax und Verwendung von make-series finden Sie unter make-series-Operator.
Identifizieren von Anomalien in einer Zeitreihe
Die Funktion series_decompose_anomalies() akzeptiert eine Reihe von Werten als Eingabe und extrahiert Anomalien.
Geben wir das Resultset unserer Zeitreihenabfrage als Eingabe für die Funktion series_decompose_anomalies() ein:
Zum Ausführen der Abfrage klicken
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Diese Abfrage gibt alle Nutzungsanomalien für sämtliche Tabellen in den letzten drei Wochen zurück:

Anhand der Abfrageergebnisse können Sie sehen, dass die Funktion folgende Aufgaben ausführt:
- Berechnen einer erwarteten täglichen Nutzung für jede Tabelle
- Vergleich der tatsächlichen täglichen Nutzung mit der erwarteten Nutzung
- Zuweisen einer Anomaliebewertung zu jedem Datenpunkt, die den Grad der Abweichung der tatsächlichen Nutzung von der erwarteten Nutzung angibt
- Identifizieren positiver (
1) und negativer (-1) Anomalien in jeder Tabelle
Hinweis
Weitere Informationen zur Syntax und Verwendung von series_decompose_anomalies() finden Sie unter series_decompose_anomalies().
Optimieren der Anomalieerkennungseinstellungen zum Verfeinern von Ergebnissen
Es empfiehlt sich, die ersten Abfrageergebnisse zu überprüfen und die Abfrage bei Bedarf zu optimieren. Ausreißer in den Eingabedaten können das Lernverhalten der Funktion beeinflussen, und Sie müssen möglicherweise die Einstellungen für die Anomalieerkennung der Funktion anpassen, um genauere Ergebnisse zu erhalten.
Filtern Sie die Ergebnisse der Abfrage series_decompose_anomalies() nach Anomalien im Datentyp AzureDiagnostics:

Die Ergebnisse zeigen zwei Anomalien: am 14. und 15. Juni. Vergleichen Sie diese Ergebnisse mit dem Diagramm unserer ersten make-series-Abfrage, in der weitere Anomalien am 27. und 28. Mai zu sehen sind:

Die unterschiedlichen Ergebnisse sind darauf zurückzuführen, dass die Funktion series_decompose_anomalies() Anomalien relativ zum erwarteten Nutzungswert bewertet, den die Funktion basierend auf der gesamten Bandbreite der Werte in der als Eingabe verwendeten Zeitreihe berechnet.
Um mit der Funktion präzisere Ergebnisse zu erhalten, schließen Sie den Nutzungswert am 15. Juni – bei dem es sich im Vergleich zu den anderen Werten der Reihe um einen Ausreißer handelt – vom Lernprozess der Funktion aus.
Die Syntax der series_decompose_anomalies()-Funktion lautet wie folgt:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points gibt die Anzahl der Punkte am Ende der Reihe an, die nicht in den Lernprozess (Regression) einbezogen werden sollen.
Um den letzten Datenpunkt auszuschließen, legen Sie Test_points auf 1 fest:
Zum Ausführen der Abfrage klicken
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Filtert die Ergebnisse nach dem Datentyp AzureDiagnostics:

Jetzt werden im Resultset alle Anomalien aus dem Diagramm unserer ersten make-series-Abfrage angezeigt.
Analysieren der Grundursache von Anomalien
Durch einen Vergleich der erwarteten Werte mit den abweichenden Werten können Sie die Ursache für die Unterschiede zwischen den beiden Datasets nachvollziehen.
Das KQL-Plug-In diffpatterns() vergleicht zwei Datasets gleicher Struktur und ermittelt Muster, die Unterschiede zwischen den beiden Datasets charakterisieren.
Diese Abfrage vergleicht die AzureDiagnostics-Nutzung am 15. Juni, dem extremen Ausreißer in unserem Beispiel, mit der Tabellennutzung an anderen Tagen:
Zum Ausführen der Abfrage klicken
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
Die Abfrage identifiziert jeden Eintrag in der Tabelle, der am AnomalyDate (15. Juni) oder an OtherDates aufgetreten ist. Das Plug-In diffpatterns() teilt diese Datasets anschließend auf – in unserem Beispiel Dataset A (OtherDates) und Dataset B (AnomalyDate) – und gibt einige Muster zurück, die zu den Unterschieden in den beiden Datasets führen:

Bei Betrachtung der Abfrageergebnisse können Sie die folgenden Unterschiede feststellen:
- Es gibt 24.892.147 Erfassungen aus der Ressource CH1-GEARAMAAKS an allen anderen Tagen des Abfragezeitraums und keine Datenerfassung aus dieser Ressource am 15. Juni. Die Daten aus der Ressource CH1-GEARAMAAKS machen 73,36 % der gesamten Erfassung an anderen Tagen im Abfragezeitraum und 0 % der gesamten Erfassung am 15. Juni aus.
- Es gibt 2.168.448 Erfassungen aus der Ressource NSG-TESTSQLMI519 an allen anderen Tagen im Abfragezeitraum und 110.544 Erfassungen aus dieser Ressource am 15. Juni. Die Daten aus der Ressource NSG-TESTSQLMI519 machen 6,39 % der gesamten Erfassung an anderen Tagen im Abfragezeitraum und 25,61 % der gesamten Erfassung am 15. Juni aus.
Beachten Sie, dass es während der 20 Tage, die den Zeitraum andere Tage ausmachen, im Durchschnitt 108.422 Erfassungen aus der Ressource NSG-TESTSQLMI519 gibt (teilen Sie 2.168.448 durch 20). Daher unterscheidet sich die Erfassung aus der Ressource NSG-TESTSQLMI519 am 15. Juni nicht wesentlich von der Erfassung aus dieser Ressource an anderen Tagen. Da es jedoch am 15. Juni keine Datenerfassung aus der Ressource CH1-GEARAMAAKS gibt, macht die Datenerfassung aus NSG-TESTSQLMI519 an diesem Anomaliedatum einen deutlich größeren Prozentsatz an der gesamten Datenerfassung aus als an anderen Tagen.
Die Spalte PercentDiffAB zeigt den absoluten prozentualen Unterschied zwischen A und B (|PercentA – PercentB|), der die zentrale Kennzahl für den Unterschied zwischen den beiden Datasets ist. Standardmäßig gibt das Plug-In diffpatterns() eine Differenz von über 5 % zwischen den beiden Datasets zurück, aber Sie können diesen Schwellenwert anpassen. Wenn Sie zum Beispiel nur Unterschiede von 20 % oder mehr zwischen den beiden Datasets zurückgeben möchten, können Sie in der obigen Abfrage | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) festlegen. Die Abfrage gibt jetzt nur ein Ergebnis zurück:

Hinweis
Weitere Informationen zur Syntax und Verwendung von diffpatterns() finden Sie unter diffpatterns-Plug-In.
Nächste Schritte
Weitere Informationen: