Verwenden Sie die vorausschauende automatische Skalierung zum Aufskalieren vor Lastanforderungen in VM-Skalierungsgruppen
Die vorhersagbare Autoskalierung nutzt maschinelles Lernen, um Azure-VM-Skalierungsgruppen mit zyklischen Workloadmustern zu verwalten und zu skalieren. Sie prognostiziert die CPU-Gesamtlast für Ihre VM-Skalierungsgruppe basierend auf Ihren bisherigen CPU-Auslastungsmustern. Durch Beobachtung und Lernen aus der bisherigen Verwendung wird die Gesamt-CPU-Auslastung vorhergesagt. Dieser Prozess stellt sicher, dass die horizontale Skalierung erfolgt, um die Nachfrage zu befriedigen.
Predictive Autoskalierung benötigt einen Verlauf von mindestens sieben Tagen, um Vorhersagen zu liefern. Der maximale Samplingzeitraum beträgt 15 Tage. Dies liefert die besten Vorhersagewerte. Verwenden Sie für monatliche oder jährliche Arbeitsauslastungsmuster zeitplanbasierte Autoskalierungs- oder metrikbasierte Autoskalierungskonfigurationen.
Die vorhersagbare Autoskalierung hält sich an die Skalierungsgrenzen, die Sie für Ihre VM-Skalierungsgruppe festgelegt haben. Wenn das System vorhersagt, dass die prozentuale CPU-Auslastung Ihrer VM-Skalierungsgruppe die Hochskalierungsgrenze überschreitet, werden neue Instanzen gemäß Ihren Spezifikationen hinzugefügt. Sie können auch konfigurieren, wie weit im Voraus neue Instanzen bereitgestellt werden sollen, bis zu 1 Stunde vor dem Auftreten der prognostizierten Arbeitslastspitze.
Mit der Prognose können Sie nur Ihre voraussichtliche CPU-Prognose einsehen, ohne die auf der Prognose basierende Skalierungsaktion auszulösen. Sie können dann die Vorhersage mit Ihren tatsächlichen Auslastungsmustern vergleichen, um Vertrauen in die Vorhersagemodelle zu schaffen, bevor Sie die Funktion für die Vorhersagbare Autoskalierung aktivieren.
Angebote für die vorausschauende automatische Skalierung
- Die vorhersagbare Autoskalierung ist für Workloads vorgesehen, die zyklische CPU-Auslastungsmuster aufweisen.
- Die Unterstützung ist nur für VM-Skalierungsgruppen verfügbar.
- Die Metrik CPU in Prozent mit dem Aggregationstyp Durchschnitt ist die einzige Metrik, die derzeit unterstützt wird.
- Die vorhersagbare Autoskalierung unterstützt nur die horizontale Skalierung. Konfigurieren Sie die Standardautoskalierung so, dass sie in Aktionen skaliert werden kann.
- Die vorhersagbare Autoskalierung ist nur für die kommerzielle Azure-Cloud verfügbar. Azure Government-Clouds werden momentan nicht unterstützt.
Aktivieren Sie die vorhersagbare Autoskalierung oder die Vorhersage nur über das Azure-Portal
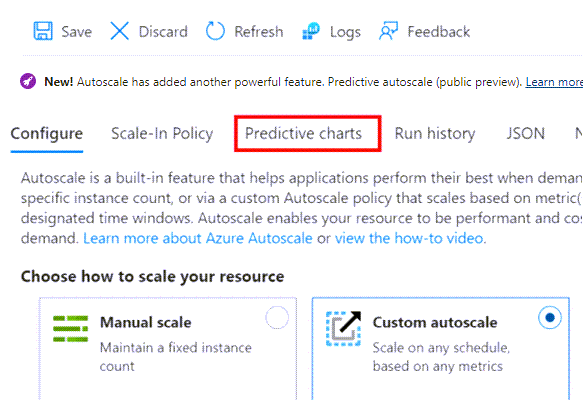
Gehen Sie zum Bildschirm der VM-Skalierungsgruppe, und wählen Sie Skalierung.
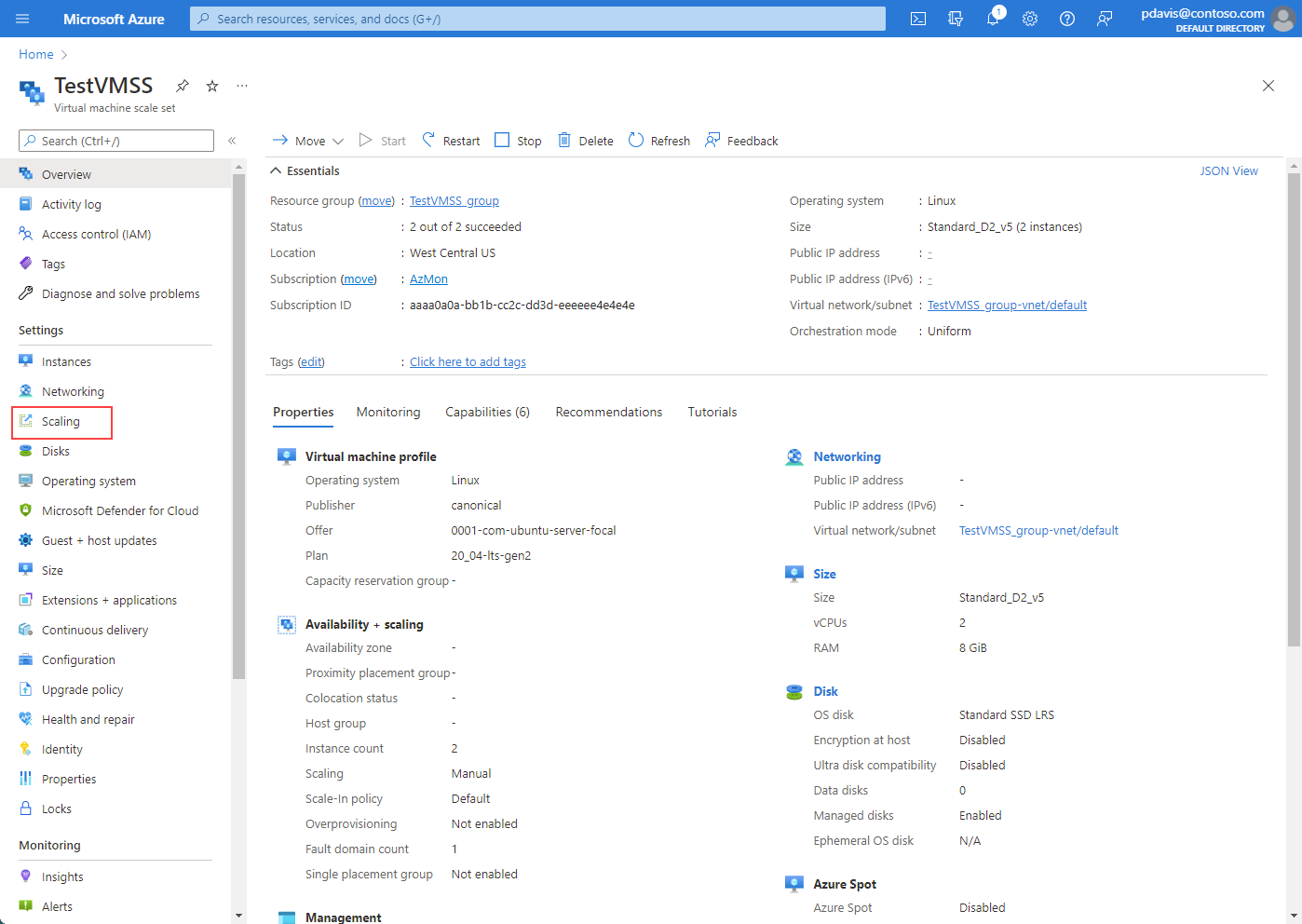
Unter dem Abschnitt benutzerdefinierte Autoskalierung wird die Option Vorhersagbare Autoskalierung angezeigt.
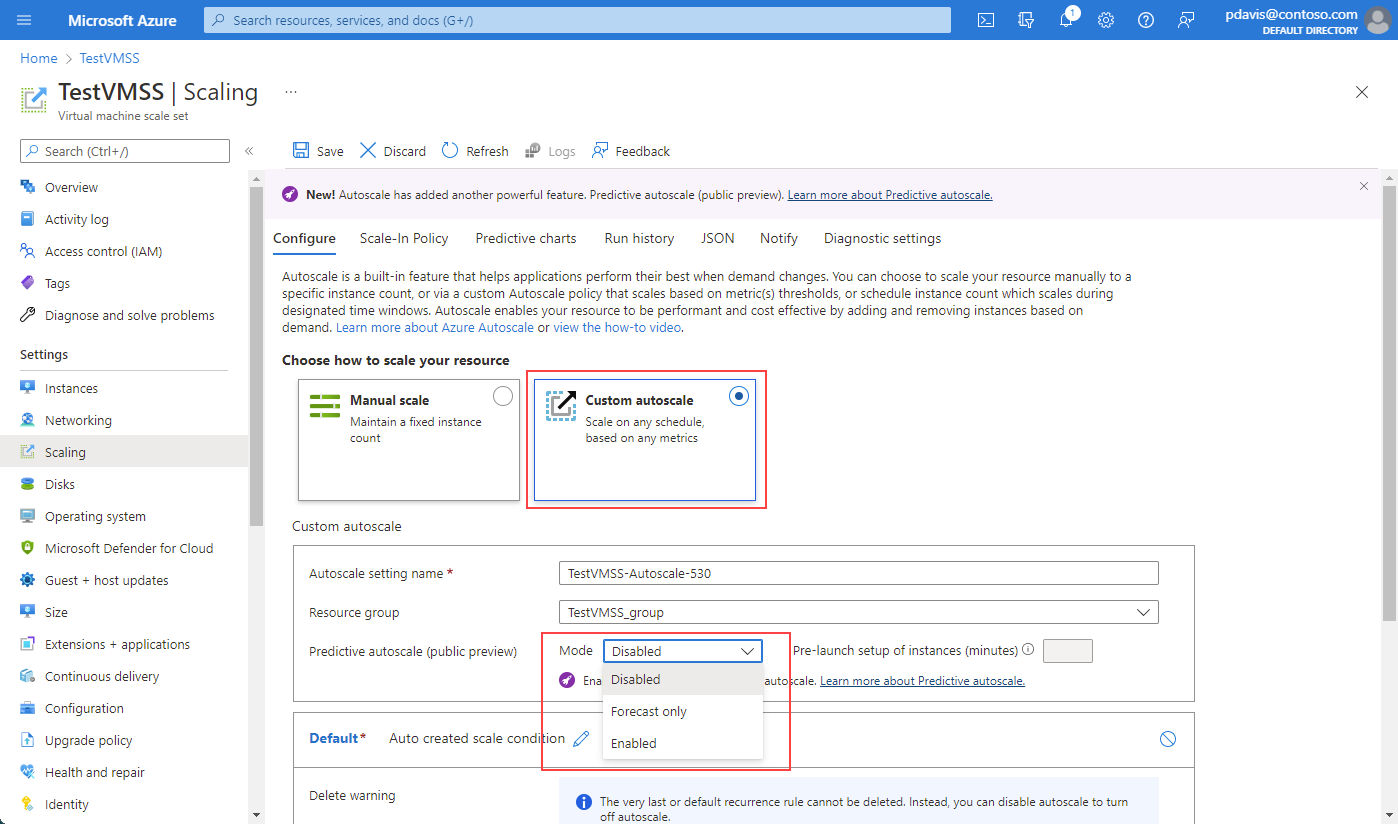
Mit der Dropdown-Auswahl können Sie:
- Deaktivieren Sie die Vorhersagbare Autoskalierung. Deaktivieren der vorhersagbaren Autoskalierung, wenn Sie die Seite für die vorhersagbare Autoskalierung zum ersten Mal öffnen.
- Aktivieren Sie den Modus „Nur Vorhersage“.
- Aktivieren Sie die vorhersagbaren Autoskalierung.
Hinweis
Bevor Sie die vorhersagbare Autoskalierung oder den Modus „Nur Vorhersage“ aktivieren können, müssen Sie die Standardbedingungen für die reaktive Autoskalierung einrichten.
Um den Modus „Nur Vorhersage“ zu aktivieren, wählen Sie ihn in der Dropdown-Liste aus. Definieren Sie einen Auslöser für die horizontale Skalierung, der auf dem Prozentsatz der CPU basiert. Klicken Sie dann auf Speichern. Die gleiche Vorgehensweise gilt für das Aktivieren der vorhersagbaren Autoskalierung. Zum Deaktivieren der vorhersagbaren Autoskalierung oder des Modus „Nur Vorhersage“ wählen Sie in der Dropdown-Liste die Option Deaktivieren.
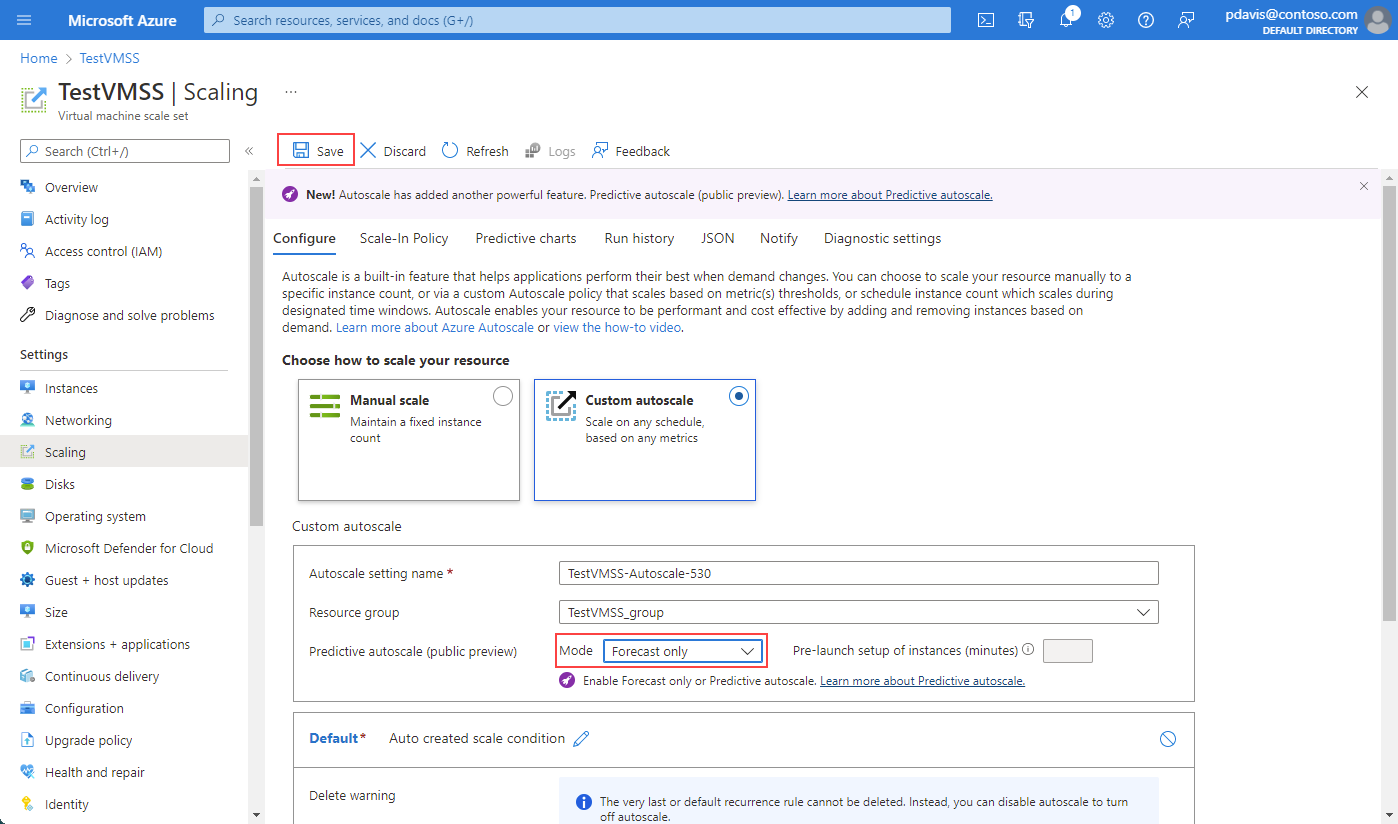
Geben Sie bei Bedarf eine Zeit vor dem Start an, damit die Instanzen vollständig ausgeführt werden, bevor sie benötigt werden. Sie können Instanzen zwischen 5 und 60 Minuten vor der benötigten Vorhersagezeit starten.
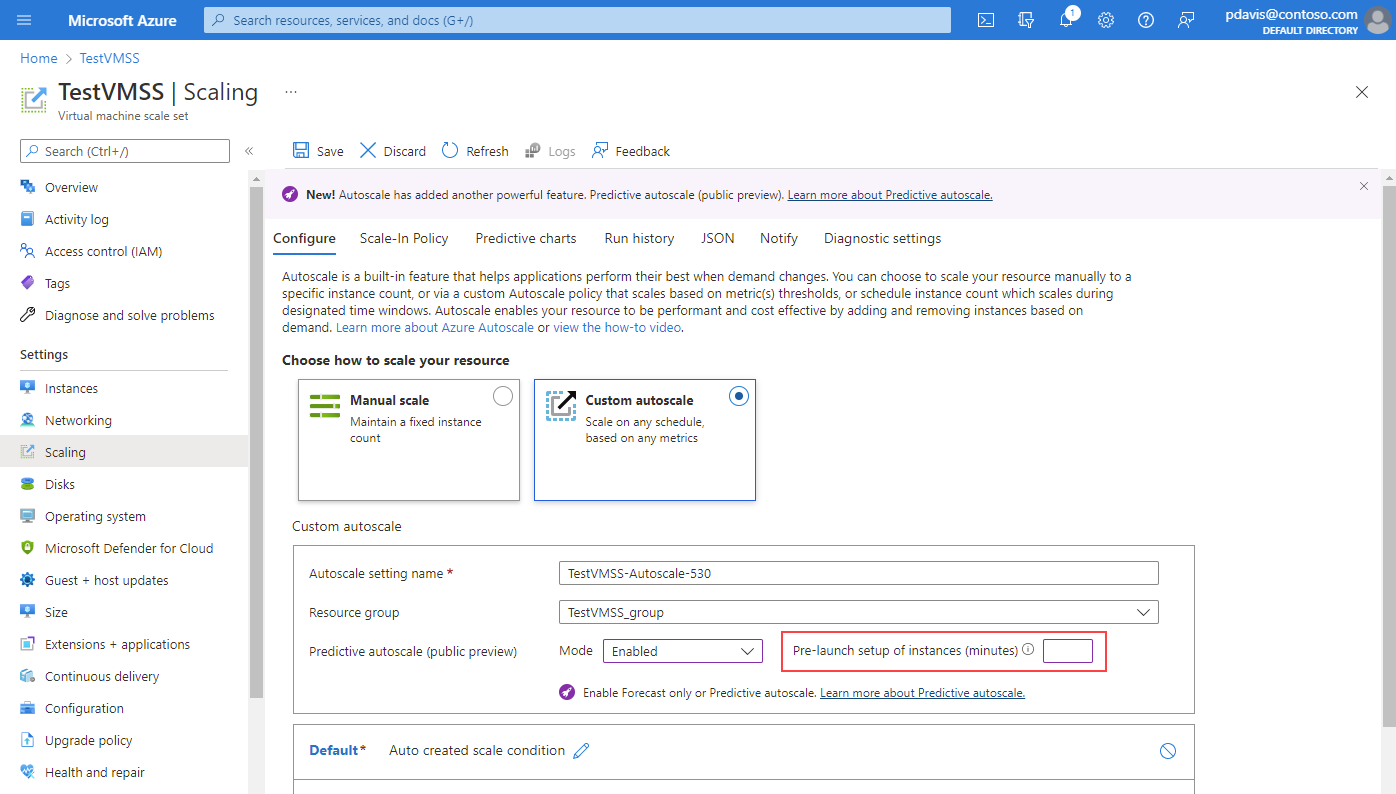
Nachdem Sie die vorhersagbare Autoskalierung oder den Modus „Nur Vorhersage“ aktiviert und gespeichert haben, wählen Sie Vorhersagbare Diagramm.
Es werden drei Diagramme angezeigt:

- Das obere Diagramm zeigt einen überlagerten Vergleich zwischen dem tatsächlichen und dem vorhergesagten Gesamt-CPU-Anteil. Die Zeitspanne des angezeigten Diagramms erstreckt sich von den letzten sieben Tagen bis zu den nächsten 24 Stunden.
- Das mittlere Diagramm zeigt die maximale Anzahl der Instanzen, die in den letzten sieben Tagen ausgeführt wurden.
- Das untere Diagramm zeigt die aktuelle durchschnittliche CPU-Auslastung der letzten sieben Tagen an.



Aktivieren mit einer Azure Resource Manager-Vorlage
Rufen Sie die Ressourcen-ID und die Ressourcengruppe Ihrer VM-Skalierungsgruppe ab. Beispiel: /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
Aktualisieren Sie die Datei autoscale_only_parameters mit der Ressourcen-ID der VM-Skalierungsgruppe und allen Parametern für die Autoskalierung.
Verwenden Sie einen PowerShell-Befehl, um die Vorlage bereitzustellen, welche die Einstellungen für die automatische Skalierung enthält. Zum Beispiel:
PS G:\works\kusto_onboard\test_arm_template> new-azurermresourcegroupdeployment -name binzAutoScaleDeploy -resourcegroupname cpatest2 -templatefile autoscale_only.json -templateparameterfile autoscale_only_parameters.json
PS C:\works\autoscale\predictive_autoscale\arm_template> new-azurermresourcegroupdeployment -name binzAutoScaleDeploy - resourcegroupname patest2 -templatefile autoscale_only_binz.json -templateparameterfile autoscale_only_parameters_binz.json
DeploymentName : binzAutoScaleDeploy
ResourceGroupName : patest2
ProvisioningState : Succeeded
Timestamp : 3/30/2021 10:11:02 PM
Mode : Incremental
TemplateLink
Parameters :
Name Type Value
================ ============================= ====================
targetVmssResourceld String /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
location String East US
minimumCapacity Int 1
maximumCapacity Int 4
defaultCapacity Int 4
metricThresholdToScaleOut Int 50
metricTimeWindowForScaleOut String PT5M
metricThresholdToScaleln Int 30
metricTimeWindowForScaleln String PT5M
changeCountScaleOut Int 1
changeCountScaleln Int 1
predictiveAutoscaleMode String Enabled
Outputs :
Name Type Value
================ ============================== ====================
targetVmssResourceld String /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
settingLocation String East US
predictiveAutoscaleMode String Enabled
DeloymentDebugLoglevel :
PS C:\works\autoscale\predictive_autoscale\arm_template>
autoscale_only.json
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"targetVmssResourceId": {
"type": "string"
},
"location": {
"type": "string"
},
"minimumCapacity": {
"type": "Int",
"defaultValue": 2,
"metadata": {
"description": "The minimum capacity. Autoscale engine will ensure the instance count is at least this value."
}
},
"maximumCapacity": {
"type": "Int",
"defaultValue": 5,
"metadata": {
"description": "The maximum capacity. Autoscale engine will ensure the instance count is not greater than this value."
}
},
"defaultCapacity": {
"type": "Int",
"defaultValue": 3,
"metadata": {
"description": "The default capacity. Autoscale engine will preventively set the instance count to be this value if it can not find any metric data."
}
},
"metricThresholdToScaleOut": {
"type": "Int",
"defaultValue": 30,
"metadata": {
"description": "The metric upper threshold. If the metric value is above this threshold then autoscale engine will initiate scale out action."
}
},
"metricTimeWindowForScaleOut": {
"type": "string",
"defaultValue": "PT5M",
"metadata": {
"description": "The metric look up time window."
}
},
"metricThresholdToScaleIn": {
"type": "Int",
"defaultValue": 20,
"metadata": {
"description": "The metric lower threshold. If the metric value is below this threshold then autoscale engine will initiate scale in action."
}
},
"metricTimeWindowForScaleIn": {
"type": "string",
"defaultValue": "PT5M",
"metadata": {
"description": "The metric look up time window."
}
},
"changeCountScaleOut": {
"type": "Int",
"defaultValue": 1,
"metadata": {
"description": "The instance count to increase when autoscale engine is initiating scale out action."
}
},
"changeCountScaleIn": {
"type": "Int",
"defaultValue": 1,
"metadata": {
"description": "The instance count to decrease the instance count when autoscale engine is initiating scale in action."
}
},
"predictiveAutoscaleMode": {
"type": "String",
"defaultValue": "ForecastOnly",
"metadata": {
"description": "The predictive Autoscale mode."
}
}
},
"variables": {
},
"resources": [{
"type": "Microsoft.Insights/autoscalesettings",
"name": "cpuPredictiveAutoscale",
"apiVersion": "2022-10-01",
"location": "[parameters('location')]",
"properties": {
"profiles": [{
"name": "DefaultAutoscaleProfile",
"capacity": {
"minimum": "[parameters('minimumCapacity')]",
"maximum": "[parameters('maximumCapacity')]",
"default": "[parameters('defaultCapacity')]"
},
"rules": [{
"metricTrigger": {
"metricName": "Percentage CPU",
"metricNamespace": "",
"metricResourceUri": "[parameters('targetVmssResourceId')]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "[parameters('metricTimeWindowForScaleOut')]",
"timeAggregation": "Average",
"operator": "GreaterThan",
"threshold": "[parameters('metricThresholdToScaleOut')]"
},
"scaleAction": {
"direction": "Increase",
"type": "ChangeCount",
"value": "[parameters('changeCountScaleOut')]",
"cooldown": "PT5M"
}
}, {
"metricTrigger": {
"metricName": "Percentage CPU",
"metricNamespace": "",
"metricResourceUri": "[parameters('targetVmssResourceId')]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "[parameters('metricTimeWindowForScaleIn')]",
"timeAggregation": "Average",
"operator": "LessThan",
"threshold": "[parameters('metricThresholdToScaleIn')]"
},
"scaleAction": {
"direction": "Decrease",
"type": "ChangeCount",
"value": "[parameters('changeCountScaleOut')]",
"cooldown": "PT5M"
}
}
]
}
],
"enabled": true,
"targetResourceUri": "[parameters('targetVmssResourceId')]",
"predictiveAutoscalePolicy": {
"scaleMode": "[parameters('predictiveAutoscaleMode')]"
}
}
}
],
"outputs": {
"targetVmssResourceId" : {
"type" : "string",
"value" : "[parameters('targetVmssResourceId')]"
},
"settingLocation" : {
"type" : "string",
"value" : "[parameters('location')]"
},
"predictiveAutoscaleMode" : {
"type" : "string",
"value" : "[parameters('predictiveAutoscaleMode')]"
}
}
}
autoscale_only_parameters.json
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"targetVmssResourceId": {
"value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2"
},
"location": {
"value": "East US"
},
"minimumCapacity": {
"value": 1
},
"maximumCapacity": {
"value": 4
},
"defaultCapacity": {
"value": 4
},
"metricThresholdToScaleOut": {
"value": 50
},
"metricTimeWindowForScaleOut": {
"value": "PT5M"
},
"metricThresholdToScaleIn": {
"value": 30
},
"metricTimeWindowForScaleIn": {
"value": "PT5M"
},
"changeCountScaleOut": {
"value": 1
},
"changeCountScaleIn": {
"value": 1
},
"predictiveAutoscaleMode": {
"value": "Enabled"
}
}
}
Weitere Informationen zu Azure Resource Manager-Vorlagen finden Sie in der Übersicht über Resource Manager-Vorlagen.
Häufig gestellte Fragen
In diesem Abschnitt werden häufig gestellte Fragen beantwortet.
Warum liegt der CPU-Prozentsatz in Vorhersagediagrammen über 100 Prozente?
Das Vorhersagediagramm zeigt die kumulative Last für alle Computer in der Skalierungsgruppe. Wenn Sie 5 VMs in einer Skalierungsgruppe haben, beträgt die maximale kumulative Last für alle VMs 500 %, d. h. das Fünffache der 100 % maximalen CPU-Last jeder VM.
Was geschieht im Laufe der Zeit, wenn Sie die vorhersagbare Autoskalierung für eine VM-Skalierungsgruppe aktivieren?
Die vorhersagbare Autoskalierung verwendet den Verlauf einer ausgeführten VM-Skalierungsgruppe. Wenn Ihre Skalierungsgruppe weniger als sieben Tage ausgeführt wurde, erhalten Sie eine Meldung, dass das Modell trainiert wird. Weitere Informationen finden Sie in der Meldung Keine Vorhersagedaten. Die Vorhersagen verbessern sich im Laufe der Zeit und erreichen 15 Tage nach der Erstellung der VM-Skalierungsgruppe die maximale Genauigkeit.
Wenn sich die Arbeitsbelastung ändert, aber periodisch bleibt, erkennt das Modell die Änderung und beginnt, die Prognose anzupassen. Die Vorhersage verbessert sich im Laufe der Zeit. Die maximale Genauigkeit wird 15 Tage nach der Änderung im Datenverkehrsmusters erreicht. Denken Sie daran, dass Ihre Standardregeln für die Autoskalierung weiterhin gelten. Wenn es zu einer neuen, unvorhergesehenen Zunahme des Datenverkehrs kommt, wird Ihre VM-Skalierungsgruppe weiterhin hochskaliert, um den Bedarf zu erfüllen.
Was ist, wenn das Modell für mich nicht gut funktioniert?
Die Modellierung funktioniert am besten bei Workloads, die periodisch auftreten. Wir empfehlen Ihnen, die Vorhersagen zunächst zu bewerten, indem Sie "Nur Vorhersage" aktivieren, wodurch die vorhergesagte CPU-Nutzung des Skalensets mit der tatsächlichen, beobachteten Nutzung überlagert wird. Nachdem Sie die Ergebnisse verglichen und ausgewertet haben, können Sie die Skalierung auf der Grundlage der vorhergesagten Metriken aktivieren, wenn die Modellvorhersagen für Ihr Szenario ausreichend gut sind.
Warum muss ich die Standard-Autoskalierung aktivieren, bevor ich die vorhersagbare Autoskalierung aktivieren kann?
Die standardmäßige Autoskalierung ist ein notwendiger Fallback, wenn das Vorhersagemodell für Ihr Szenario nicht gut funktioniert. Die Standard-Autoskalierung deckt unerwartete Lastspitzen ab, die nicht Teil Ihres typischen CPU-Auslastungsmusters sind. Sie bietet auch einen Fallback für den Fall, dass beim Abrufen der Vorhersagedaten ein Fehler auftritt.
Welche Regel tritt in Kraft, wenn sowohl Vorhersage- als auch Standardregeln für die Autoskalierung festgelegt sind?
Standardregeln für die Autoskalierung werden verwendet, wenn die CPU-Last unerwartet stark ansteigt oder beim Abrufen von Vorhersagedaten ein Fehler auftritt
Wir verwenden den in den Standardregeln für die Autoskalierung festgelegten Schwellenwert, um zu verstehen, wann und um wie viele Instanzen Sie aufskalieren möchten. Wenn Sie möchten, dass Ihre VM-Skalierungsgruppe aufskaliert wird, wenn die CPU-Auslastung 70 % überschreitet, und tatsächliche oder vorhergesagte Daten zeigen, dass die CPU-Auslastung über 70 % liegt oder liegen wird, erfolgt eine Aufskalierung.
Fehler und Warnungen
Dieser Abschnitt behandelt häufige Fehler und Warnungen.
Standardmäßige Autoskalierung wurde nicht aktiviert
Sie erhalten die folgende Fehlermeldung:
Um die vorausschauende automatische Skalierung zu aktivieren, erstellen Sie eine Aufskalierungsregel basierend auf der Metrik ‚CPU-Prozentsatz. Klicken Sie hier, um zur Registerkarte ‚Konfigurieren‘ zu gehen, um eine Autoscale Regel festzulegen.
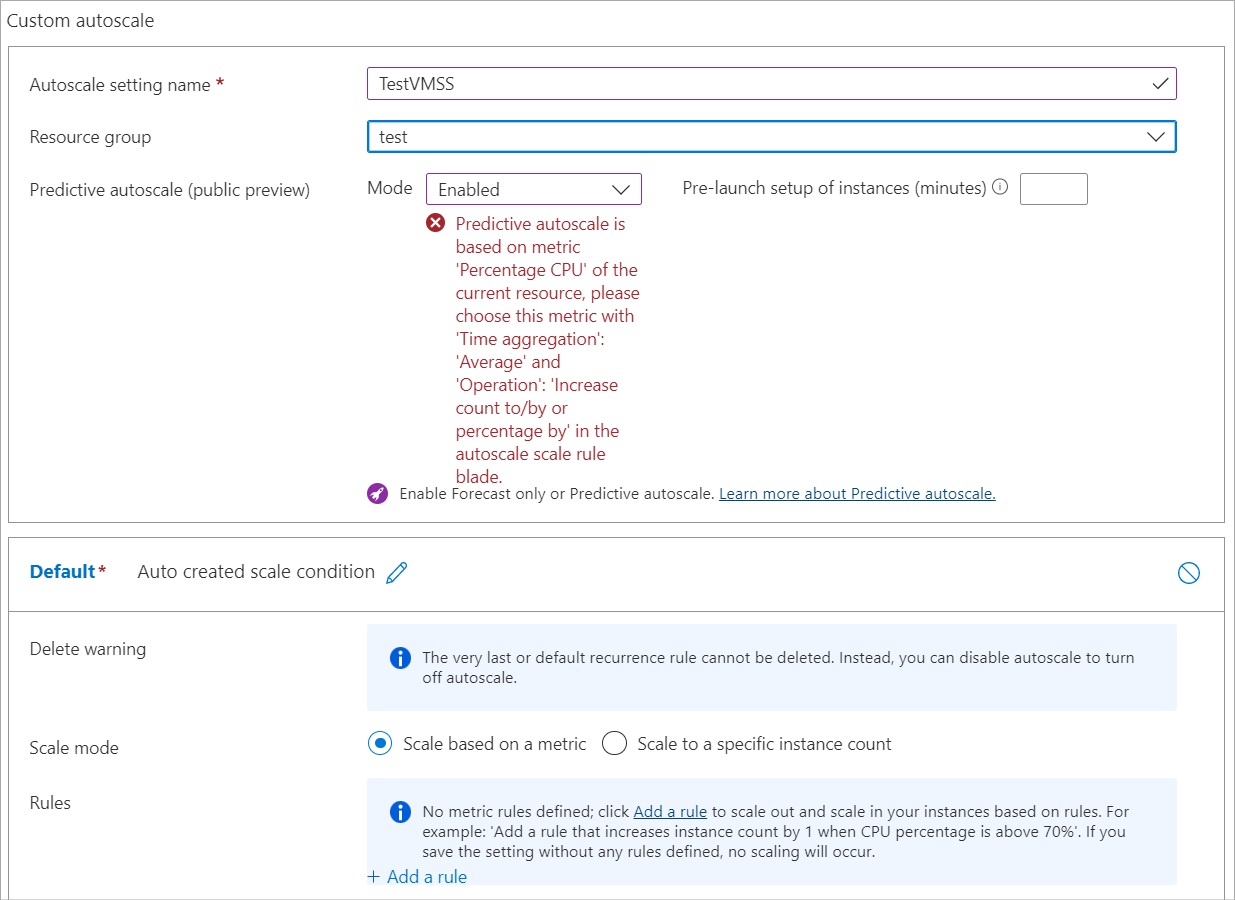
Diese Meldung bedeutet, dass Sie versucht haben, die vorhersagbare Autoskalierung zu aktivieren, bevor Sie die standardmäßige Autoskalierung aktiviert und für die Verwendung der Metrik CPU in Prozent mit dem Aggregationstyp Durchschnitt eingerichtet haben.
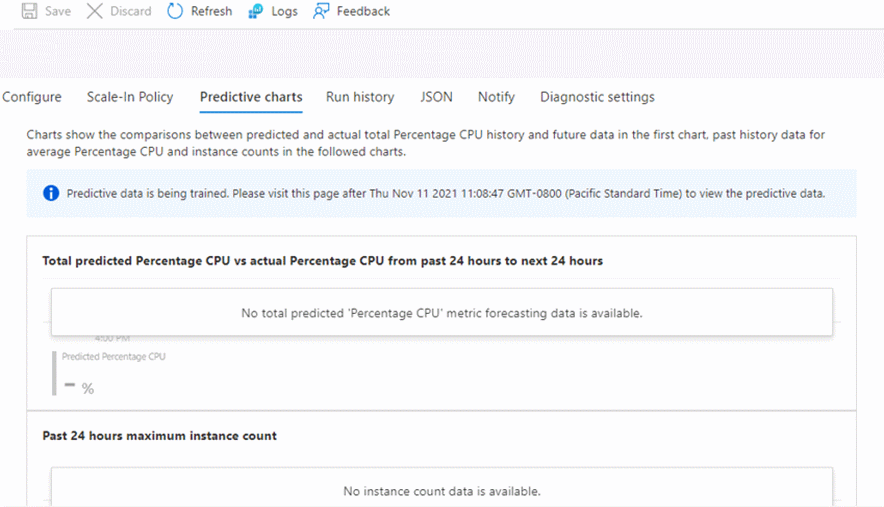
Keine Vorhersagedaten
Unter bestimmten Bedingungen werden keine Daten in den Vorhersagediagrammen angezeigt. Dieses Verhalten ist kein Fehler, sondern das beabsichtigte Verhalten.
Wenn die vorhersagbare Autoskalierung deaktiviert ist, erhalten Sie stattdessen eine Meldung, die mit „Keine Daten zum Anzeigen...“ beginnt. Sie erhalten dann Anweisungen, was Sie aktivieren müssen, damit Sie ein Vorhersagediagramm sehen können.

Wenn Sie zum ersten Mal eine VM-Skalierungsgruppe erstellen und den Modus „Nur Vorhersage“ aktivieren, erhalten Sie die Meldung „Vorhersagedaten werden gerade trainiert...“ Außerdem wird eine Zeit angegeben, zu der Sie zurückkehren müssen, um das Diagramm zu sehen.
Nächste Schritte
Weitere Informationen über Autoskalierung finden Sie in den folgenden Artikeln:
- Übersicht über die automatische Skalierung
- Allgemeine Metriken für die automatische Skalierung in Azure Monitor
- Best Practices für die automatische Skalierung in Azure Monitor
- Verwenden von automatischen Skalierungsvorgängen zum Senden von E-Mail- und Webhook-Warnbenachrichtigungen
- REST-API für die automatische Skalierung