Notfallwiederherstellung und geografische Verteilung in Azure Durable Functions
Microsoft möcht sicherstellen, dass Azure-Dienste immer verfügbar sind. Es kann jedoch zu ungeplanten Dienstausfällen kommen. Wenn die Anwendung Resilienz erfordert, empfiehlt Microsoft Ihnen, Ihre App für die Georedundanz zu konfigurieren. Darüber hinaus müssen Kunden einen Notfallwiederherstellungsplan haben, um einen regionalen Dienstausfall handhaben zu können. Ein wichtiger Teil eines Notfallwiederherstellungsplans ist die Vorbereitung auf das Failover des sekundären Replikats Ihrer App und Ihres Speichers, falls das primäre Replikat nicht mehr verfügbar ist.
In Durable Functions werden sämtliche Zustände in Azure Storage standardmäßig persistent gespeichert. Ein Aufgabenhub ist ein logischer Container für Azure Storage-Ressourcen, die für Orchestrierungen und Entitäten verwendet werden. Orchestrator-, Aktivitäts- und Entitätsfunktionen können nur miteinander interagieren, wenn sie zum selben Aufgabenhub gehören. Dieses Dokument bezieht sich auf Aufgabenhubs, wenn Szenarios beschrieben werden, die dazu dienen, diese Azure Storage-Ressourcen hoch verfügbar zu halten.
Hinweis
Die Anleitungen in diesem Artikel gehen davon aus, dass Sie den standardmäßigen Azure Storage-Anbieter zum Speichern des Durable Functions-Laufzeitstatus verwenden. Es ist jedoch möglich, alternative Speicheranbieter zu konfigurieren, die den Zustand an anderer Stelle speichern, z. B. eine SQL Server-Datenbank. Für die alternativen Speicheranbieter können unterschiedliche Notfallwiederherstellungs- und geografische Verteilungsstrategien erforderlich sein. Weitere Informationen zu den alternativen Speicheranbietern finden Sie in der Dokumentation zu Durable Functions-Speicheranbietern.
Orchestrierungen und Entitäten können mithilfe von Clientfunktionen ausgelöst werden, die selbst über HTTP oder einen der anderen unterstützten Azure Functions-Triggertypen ausgelöst werden. Sie können auch mit integrierten HTTP-APIs ausgelöst werden. Der Einfachheit halber konzentriert sich dieser Artikel auf Szenarios, in denen Azure Storage- und HTTP-basierte Funktionstrigger verwendet werden, sowie Optionen zum Erhöhen der Verfügbarkeit und Minimieren der Ausfallzeiten bei Aktivitäten zur Notfallwiederherstellung. Andere Triggertypen wie Service Bus- oder Azure Cosmos DB-Trigger werden nicht explizit abgedeckt.
Die folgenden Szenarien basieren auf Aktiv/Passiv-Konfigurationen, da sie von der Verwendung von Azure Storage gesteuert werden. Dieses Muster besteht aus der Bereitstellung einer (passiven) Sicherungsfunktionen-App in einer anderen Region. Der Traffic Manager überwacht die primäre (aktive) Funktionen-App zur Sicherstellung der HTTP-Verfügbarkeit. Fällt die primäre App aus, wird ein Failover zur Sicherungsfunktionen-App durchgeführt. Weitere Informationen finden Sie im Artikel zur Prioritätsmethode für das Datenverkehrsrouting des Azure Traffic Managers.
Hinweis
- Die vorgeschlagene Aktiv/Passiv-Konfiguration stellt sicher, dass ein Client stets neue Orchestrierungen über HTTP auslösen kann. Da zwei Funktionen-Apps verwendet werden, die den gleichen Aufgabenhub im Speicher nutzen, werden einige Speichertransaktionen im Hintergrund zwischen diesen aufgeteilt. Bei dieser Konfiguration fallen darum Kosten für zusätzlichen ausgehenden Datenverkehr bei der sekundären Funktionen-App an.
- Das zugrunde liegende Speicherkonto und der Aufgabenhub werden in der primären Region erstellt und für beide Funktionen-Apps freigegeben.
- Alle Funktionen-Apps, die redundant bereitgestellt werden, müssen die gleichen Funktionszugriffsschlüssel verwenden, für den Fall, dass sie über HTTP aktiviert werden. Die Functions Runtime macht eine Verwaltungs-API verfügbar, die Consumern das programmgesteuerte Hinzufügen, Löschen und Aktualisieren von Funktionstasten ermöglicht. Die Schlüsselverwaltung ist auch mit Azure Resource Manager-APIs möglich.
Szenario 1 – Lastenausgleich von Computekapazitäten mit freigegebenem Speicher
Fällt die Computeinfrastruktur in Azure aus, ist die Funktionen-App eventuell nicht verfügbar. Um die Wahrscheinlichkeit solcher Ausfallzeiten zu minimieren, werden in diesem Szenario zwei Funktionen-Apps verwendet, die in unterschiedlichen Regionen bereitgestellt werden. Der Traffic Manager ist für die Erkennung von Problemen in der primären Funktionen-App konfiguriert und leitet Datenverkehr automatisch an die Funktionen-App in der sekundären Region um. Diese Funktionen-App verwendet das gleiche Azure Storage-Konto und den gleichen Aufgabenhub. Daher geht der Zustand der Funktionen-Apps nicht verloren und die Ausführung kann wie gewohnt fortgesetzt werden. Sobald die Integrität in der primären Region wiederhergestellt wurde, startet der Azure Traffic Manager automatisch die Weiterleitung von Anforderungen an diese Funktionen-App.
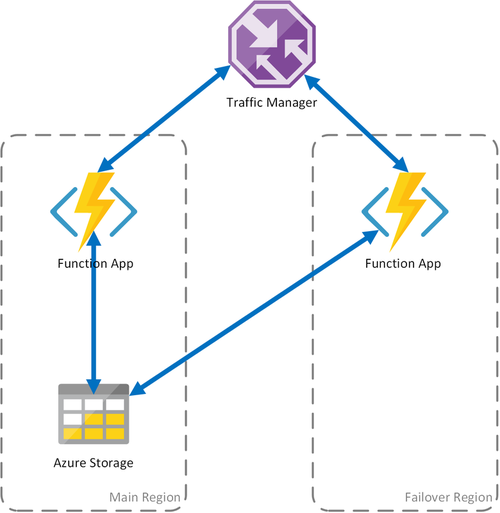
Dieses Bereitstellungsszenario bietet mehrere Vorteile:
- Fällt die Computeinfrastruktur aus, kann der Betrieb in der Failoverregion ohne Datenverlust fortgesetzt werden.
- Der Traffic Manager übernimmt automatisch das Failover für die fehlerfreie Funktionen-App.
- Der Traffic Manager leitet automatisch wieder Datenverkehr an die primäre Funktionen-App weiter, nachdem der Ausfall behoben wurde.
Bei diesem Szenario sollten Sie jedoch Folgendes berücksichtigen:
- Wenn die Funktionen-App mit einem dedizierten App Service-Plan bereitgestellt wird, treibt eine Replikation der Computeinfrastruktur im Rechenzentrum, für das das Failover durchgeführt wird, die Kosten in die Höhe.
- Dieses Szenario deckt zwar Ausfälle in der Computeinfrastruktur ab, doch das Speicherkonto ist weiterhin der Single Point of Failure für die Funktionen-App. Ein Ausfall von Storage zieht einen Ausfall der Anwendung nach sich.
- Wenn ein Failover für die Funktionen-App ausgeführt wird, kommt es zu längeren Latenzen, da diese auf das Speicherkonto in verschiedenen Regionen zugreift.
- Der Zugriff auf den Speicherdienst von einer anderen Region als der Region, in der sich der Dienst befindet, führt aufgrund des ausgehenden Netzwerkdatenverkehrs zu erhöhten Kosten.
- Dieses Szenario basiert auf dem Traffic Manager. Angesichts der Funktionsweise des Traffic Managers kann es eine Weile dauern, bis eine Clientanwendung, die Durable Functions nutzt, erneut die Adresse der Funktionen-App des Traffic Managers abrufen muss.
Hinweis
Ab v2.3.0 der Durable Functions-Erweiterung können zwei Funktionen-Apps sicher gleichzeitig mit demselben Speicherkonto und derselben Aufgabenhubkonfiguration ausgeführt werden. Die zuerst startende App ruft eine Bloblease auf Anwendungsebene ab, die verhindert, dass andere Apps Nachrichten aus den Aufgabenhub-Warteschlangen stehlen. Wenn diese erste App nicht mehr ausgeführt wird, läuft die Lease ab und kann von einer zweiten App abgerufen werden, die dann die Verarbeitung von Aufgabenhubnachrichten fortsetzt.
Funktionen-Apps vor v2.3.0, die für die Verwendung desselben Speicherkontos konfiguriert sind, verarbeiten Nachrichten und aktualisieren Speicherartefakte gleichzeitig, was zu wesentlich höheren Gesamtwartezeiten und Ausgangskosten führt. Wenn für die primäre und die Replikat-App ein anderer Code bereitgestellt wird, auch temporär, könnten Orchestrierungen möglicherweise auch nicht ordnungsgemäß ausgeführt werden, da in beiden Apps Inkonsistenzen der Orchestratorfunktion auftreten. Daher sollten alle Apps, für die zur Notfallwiederherstellung eine geografische Verteilung erforderlich ist, v2.3.0 oder höher der Durable Functions-Erweiterung verwenden.
Szenario 2 – Lastenausgleich von Computekapazitäten mit regionalem Speicher
In dem oben beschriebenen Szenario wird lediglich ein Ausfall in der Computeinfrastruktur behandelt. Fällt der Speicherdienst aus, so hat dies den Ausfall der Funktionen-App zur Folge. Um einen kontinuierlichen Betrieb von Durable Functions sicherzustellen, wird in diesem Szenario ein lokales Speicherkonto für jede Region verwendet, in der die Funktionen-Apps bereitgestellt werden.
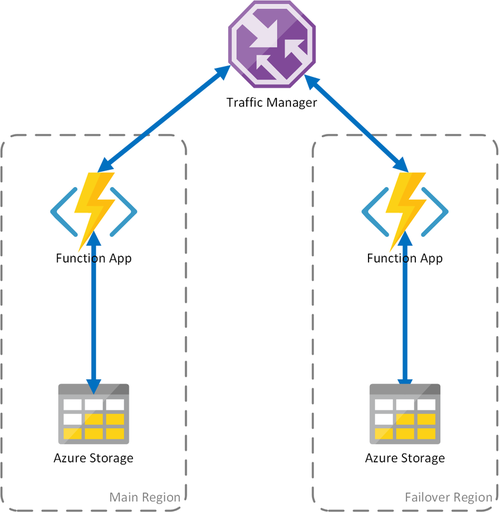
Bei dieser Vorgehensweise werden Verbesserungen gegenüber dem vorherigen Szenario vorgenommen:
- Fällt die Funktionen-App aus, übernimmt der Traffic Manager das Failover zur sekundären Region. Da die Funktionen-App jedoch ein eigenes Speicherkonto benötigt, wird weiterhin Durable Functions ausgeführt.
- Bei einem Failover kommt es nicht zu weiteren Latenzen in der Failoverregion, da sich die Funktionen-App und das Speicherkonto in derselben Region befinden.
- Ausfälle auf Speicherebene führen zu Ausfällen von Durable Functions, wodurch wiederum eine Umleitung zur Failoverregion ausgelöst wird. Da die Funktionen-App und der Speicher nach Region isoliert sind, ist Durable Functions weiterhin funktionsfähig.
Wichtige Hinweise zu diesem Szenario:
- Wenn die Funktionen-App mit einem dedizierten App Service-Plan bereitgestellt wird, treibt eine Replikation der Computeinfrastruktur im Rechenzentrum, für das das Failover durchgeführt wird, die Kosten in die Höhe.
- Für den aktuellen Status wird kein Failover ausgeführt. Dies impliziert, dass vorhandene Orchestrierungen und Entitäten effektiv angehalten werden und nicht verfügbar sind, bis die primäre Region wiederhergestellt wird.
Zusammenfassend gilt: Der Kompromiss zwischen dem ersten und dem zweiten Szenario besteht darin, dass die Latenzzeit beibehalten und Ausgangskosten minimiert werden, aber vorhandene Orchestrierungen und Entitäten während der Ausfallzeit nicht verfügbar sind. Ob diese Kompromisse akzeptabel sind, hängt von den Anforderungen der Anwendung ab.
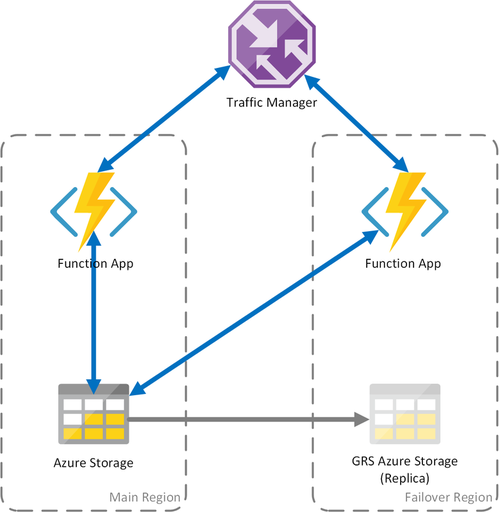
Szenario 3 – Lastenausgleich von Computekapazitäten mit freigegebenem GRS
Dieses Szenario stellt eine Abwandlung des ersten Szenarios dar, bei der ein freigegebenes Speicherkonto implementiert wird. Der wesentliche Unterschied ist, dass das Speicherkonto mit aktivierter Georeplikation erstellt wird. Funktionell bietet dieses Szenario dieselben Vorteile wie Szenario 1, jedoch darüber hinaus zusätzlich Vorteile im Hinblick auf die Datenwiederherstellung:
- Georedundante Speicher (GRS) und georedundante Speicher mit Lesezugriff (RA-GRS) maximieren die Verfügbarkeit Ihres Speicherkontos.
- Bei einem regionalen Ausfall des Speicherdiensts können Sie manuell ein Failover zum sekundären Replikat auslösen. In extremen Fällen, wenn eine Region durch eine schwerwiegenden Notfall verloren geht, kann Microsoft ein regionales Failover initiieren. In diesem Fall ist keine weitere Aktion erforderlich.
- Wenn ein Failover auftritt, wird der Zustand von Durable Functions bis zur letzten Replikation des Speicherkontos persistent gespeichert, und zwar in der Regel alle paar Minuten.
Wie bei den anderen Szenarien sind auch hier wichtige Aspekte zu berücksichtigen:
- Ein Failover auf das Replikat kann einige Zeit in Anspruch nehmen. Bis das Failover abgeschlossen ist und Azure Storage DNS-Einträge aktualisiert wurden, fällt die Funktionen-App aus.
- Der Einsatz von geografisch replizierten Speicherkonten führt zum Kostenanstieg.
- Die GRS-Replikation kopiert Ihre Daten asynchron. Einige der letzten Transaktionen könnten aufgrund von Latenzen seitens des Replikationsvorgangs verloren gehen.
Hinweis
Wie in Szenario 1 beschrieben, wird dringend empfohlen, dass mit dieser Strategie bereitgestellte Funktionen-Apps v2.3.0 oder höher der Durable Functions Erweiterung verwenden.
Weitere Informationen finden Sie in der Dokumentation Notfallwiederherstellung und Speicherkontofailover.