Architektur von Azure Managed Redis (Vorschau)
Azure Managed Redis (Vorschau) wird im Redis Enterprise-Stapel ausgeführt, der gegenüber der Community-Edition von Redis erhebliche Vorteile bietet. Im Folgenden finden Sie ausführlichere Informationen zur Architektur von Azure Managed Redis, die auch für Power-Benutzer nützlich sein können.
Wichtig
Azure Managed Redis befindet sich derzeit in der VORSCHAUPHASE. Die zusätzlichen Nutzungsbestimmungen für Microsoft Azure-Vorschauen enthalten rechtliche Bedingungen. Sie gelten für diejenigen Azure-Features, die sich in der Beta- oder Vorschauversion befinden oder aber anderweitig noch nicht zur allgemeinen Verfügbarkeit freigegeben sind.
Vergleich mit Azure Cache for Redis
Die Stufen „Basic“, „Standard“ und „Premium“ von Azure Cache for Redis wurden basierend auf der Community-Edition von Redis erstellt. Diese Version von Redis hat mehrere erhebliche Einschränkungen, u. a. das Singlethread-Design. Dies reduziert die Leistung deutlich und macht die Skalierung weniger effizient, da vCPUs nicht vollständig vom Dienst genutzt werden. Eine typische Azure Cache for Redis-Instanz verwendet eine Architektur wie die folgende:
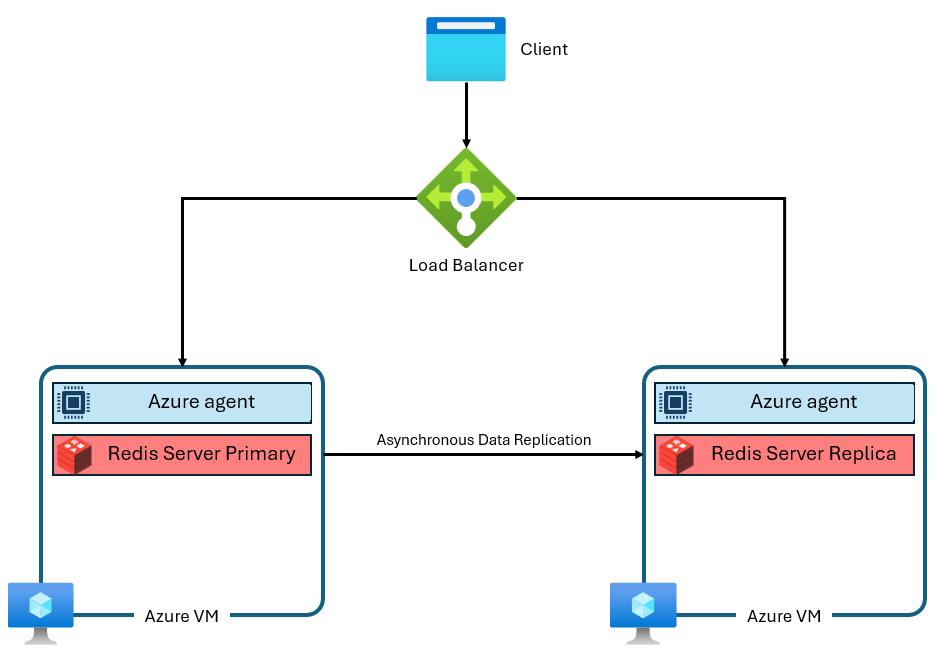
Beachten Sie, dass zwei virtuelle Computer verwendet werden – ein primärer und ein Replikat. Diese virtuellen Computer werden auch als „Knoten“ bezeichnet. Der primäre Knoten enthält den Redis-Hauptprozess und akzeptiert alle Schreibvorgänge. Die Replikation wird asynchron auf den Replikatknoten durchgeführt, um während Wartung, Skalierung oder unerwarteten Ausfällen eine Sicherungskopie bereitzustellen. Jeder Knoten kann aufgrund des Singlethread-Designs der Community-Version von Redis nur einen einzelnen Redis-Serverprozess ausführen.
Architekturverbesserungen von Azure Managed Redis
Azure Managed Redis verwendet eine komplexere Architektur, die ungefähr wie folgt aussieht:
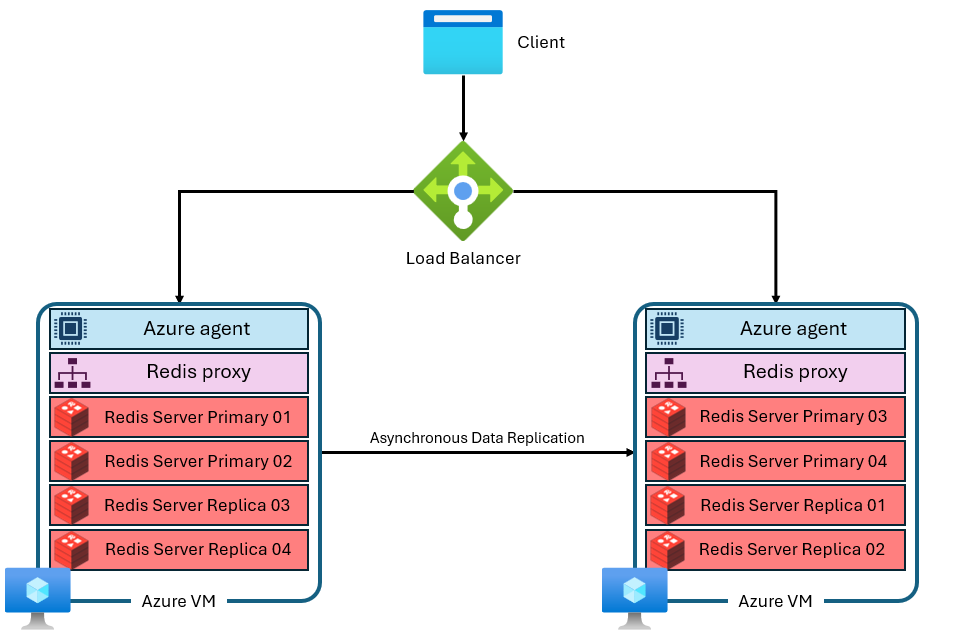
Es gibt mehrere Unterschiede:
- Jeder virtuelle Computer (oder „Knoten“) führt mehrere Redis-Serverprozesse (sogenannte „Shards“) parallel aus. Mehrere Shards ermöglichen eine effizientere Nutzung von vCPUs auf jedem virtuellen Computer und eine höhere Leistung.
- Nicht alle primären Redis-Shards befinden sich auf demselben virtuellen Computer/Knoten. Stattdessen werden primäre und Replikatshards über beide Knoten verteilt. Da primäre Shards mehr CPU-Ressourcen als Replikatshards verwenden, ermöglicht dieser Ansatz die parallele Ausführung von mehr primären Shards.
- Jeder Knoten verfügt über einen leistungsstarken Proxy-Prozess, um die Shards zu verwalten, die Verbindungsverwaltung auszuführen und Self-healing auszulösen.
Diese Architektur ermöglicht sowohl eine höhere Leistung als auch erweiterte Features wie aktive Georeplikation.
Clustering
Da Redis Enterprise mehrere Shards pro Knoten verwenden kann, ist jede Azure Managed Redis-Instanz intern für die Verwendung von Clustering auf allen Ebenen und SKUs konfiguriert. Dazu gehören kleinere Instanzen, die nur für die Verwendung eines einzelnen Shards eingerichtet sind. Clustering ist eine Möglichkeit, die Daten in der Redis-Instanz über mehrere Redis-Prozesse aufzuteilen, auch als „Sharding“ bezeichnet. Azure Managed Redis bietet zwei Clusterrichtlinien, die bestimmen, welches Protokoll für Redis-Clients für die Verbindung mit der Cache-Instanz verfügbar ist.
Clusterrichtlinien
Azure Managed Redis bieten zwei Optionen für die Clusteringrichtlinie: OSS und Enterprise. Die Clusteringrichtlinie OSS wird für die meisten Anwendungen empfohlen, da sie einen höheren maximalen Durchsatz unterstützt. Jede Version hat aber gewisse Vor- und Nachteile.
Die OSS-Clusteringrichtlinie implementiert die gleiche Redis Cluster-API wie die Community-Version von Redis. Die Redis Cluster-API ermöglicht dem Redis-Client, eine direkte Verbindung mit Shards auf jedem Redis-Knoten herzustellen, wodurch die Latenz minimiert und der Netzwerkdurchsatz optimiert wird. So kann der Durchsatz nahezu linear skaliert werden, wenn die Anzahl der Shards und vCPUs zunimmt. Die OSS-Clusteringrichtlinie bietet in der Regel die beste Latenz- und Durchsatzleistung. Die OSS-Clusterrichtlinie erfordert jedoch, dass Ihre Clientbibliothek die Redis Cluster-API unterstützt. Heute unterstützen fast alle Redis-Clients die Redis Cluster-API, aber die Kompatibilität kann ein Problem für ältere Clientversionen oder spezielle Bibliotheken sein. Außerdem kann die OSS-Clusteringrichtlinie nicht mit dem RediSearch-Modul verwendet werden.
Die Enterprise-Clusteringrichtlinie ist eine einfachere Konfiguration, die einen einzelnen Endpunkt für alle Clientverbindungen nutzt. Bei Verwendung der Enterprise-Clusteringrichtlinie werden alle Anforderungen an einen einzelnen Redis-Knoten weitergeleitet, der dann als Proxy fungiert und Anforderungen intern an den richtigen Knoten im Cluster weiterleitet. Der Vorteil dieses Ansatzes besteht darin, dass Azure Managed Redis für Benutzer nicht geclustert aussieht. Das bedeutet, dass Redis-Clientbibliotheken Redis-Clustering nicht unterstützen müssen, um einige der Leistungsvorteile von Redis Enterprise zu erzielen. Dies steigert die Abwärtskompatibilität und vereinfacht die Verbindung. Der Nachteil ist, dass ein einzelner Knoten als Proxy einen Engpass darstellen kann (entweder bei der Computeauslastung oder beim Netzwerkdurchsatz). Die Enterprise-Clusteringrichtlinie ist die einzige Richtlinie, die mit dem RediSearch-Modul verwendet werden kann. Während die Enterprise-Clusterrichtlinie eine Azure Managed Redis-Instanz für Benutzer als nicht geclustert erscheinen lässt, hat sie dennoch einige Einschränkungen bei Befehlen mit mehreren Schlüsseln.
Aufskalieren oder Hinzufügen von Knoten
Die Core Redis Enterprise-Software kann entweder hochskaliert werden (mithilfe größerer VMs) oder aufskaliert werden (durch Hinzufügen weiterer Knoten/VMs). Letztendlich erreicht jede Skalierungsaktion dasselbe, indem mehr Arbeitsspeicher, mehr vCPUs und mehr Shards hinzugefügt werden. Aufgrund dieser Redundanz bietet Azure Managed Redis nicht die Möglichkeit, die spezifische Anzahl der in jeder Konfiguration verwendeten Knoten zu steuern. Dieses Implementierungsdetail wird für den Benutzer abstrahiert, um Verwirrung, Komplexität und suboptimale Konfigurationen zu vermeiden. Stattdessen wurde jede SKU mit einer Knotenkonfiguration entwickelt, um vCPUs und Arbeitsspeicher zu maximieren. Einige SKUs von Azure Managed Redis verwenden nur zwei Knoten, während einige mehr verwenden.
Befehle mit mehreren Schlüsseln
Da Azure Managed Redis-Instanzen eine Clusterkonfiguration verwenden, werden für Befehle, die auf mehreren Schlüsseln basieren, möglicherweise Ausnahmen vom Typ CROSSSLOT angezeigt. Das Verhalten variiert je nach verwendeter Clusteringrichtlinie. Wenn Sie die OSS-Clusteringrichtlinie verwenden, müssen bei Befehlen mit mehreren Schlüsseln alle Schlüssel dem gleichen Hashslot zugeordnet werden.
Bei Verwendung der Enterprise-Clusteringrichtlinie treten ggf. auch Fehler vom Typ CROSSSLOT auf. Beim Enterprise-Clustering können nur folgende Befehle mit mehreren Schlüsseln slotübergreifend verwendet werden: DEL, MSET, MGET, EXISTS, UNLINK und TOUCH.
In Active-Active Datenbanken können Schreibbefehle mit mehreren Schlüsseln (DEL, MSET, UNLINK) nur für Schlüssel ausgeführt werden, die sich im selben Slot befinden. Die folgenden Befehle mit mehreren Schlüsseln sind jedoch slotsübergreifend in Active-Active Datenbanken zulässig: MGET, EXISTSund TOUCH. Weitere Informationen finden Sie im Artikel zum Datenbankclustering unter Multi-key operations (Vorgänge mit mehreren Schlüsseln).
Shardingkonfiguration
Jede SKU von Azure Managed Redis ist so konfiguriert, dass eine bestimmte Anzahl von Redis-Serverprozessen ausgeführt wird, parallele Shards. Die Beziehung zwischen der Durchsatzleistung, der Anzahl der Shards und der Anzahl der für jede Instanz verfügbaren vCPUs ist kompliziert. Das Hinzufügen von Shards erhöht in der Regel die Leistung, da Redis-Vorgänge parallel ausgeführt werden können. Wenn Shards jedoch nicht in der Lage sind, Befehle auszuführen, da keine vCPUs zum Ausführen von Befehlen verfügbar sind, kann die Leistung tatsächlich fallen. Die folgende Tabelle zeigt die Shardingkonfiguration für jede Azure Managed Redis-SKU. Diese Shards werden zugeordnet, um die Verwendung jeder vCPU zu optimieren, während vCPU-Zyklen für Redis Enterprise-Proxy-, Verwaltungs-, und Betriebssystemaufgaben reserviert werden, die sich auch auf die Leistung auswirken.
Hinweis
Die Anzahl der Shards und vCPUs, die für jede SKU verwendet werden, kann sich im Laufe der Zeit ändern, da die Leistung vom Azure Managed Redis-Team optimiert wird.
| Ebenen | Flash-optimiert | Arbeitsspeicheroptimiert | Balanced | Berechnungsoptimiert |
|---|---|---|---|---|
| Größe (GB) | vCPUs/primäre Shards | vCPUs/primäre Shards | vCPUs/primäre Shards | vCPUs/primäre Shards |
| 0,5 | - | - | 2/2 | - |
| 1 | - | - | 2/2 | - |
| 3 | - | - | 2/2 | 4/2 |
| 6 | - | - | 2/2 | 4/2 |
| 12 | - | 2/2 | 4/2 | 8/6 |
| 24 | - | 4/2 | 8/6 | 16/12 |
| 60 | - | 8/6 | 16/12 | 32/24 |
| 120 | - | 16/12 | 32/24 | 64/48 |
| 180 | - | 24/24 | 48/48 | 96/96 |
| 240 | 8/6 | 32/24 | 64/48 | 128/96 |
| 360 | - | 48/48 | 96/96 | 192/192 |
| 480 | 16/12 | 64/48 | 128/96 | 256/192 |
| 720 | 24/24 | 96/96 | 192/192 | 384/384 |
| 960 | 32/24 | 128/192 | 256/192 | - |
| 1440 | 48/48 | 192/192 | - | - |
| 1920 | 64/48 | 256/192 | - | - |
| 4500 | 144/96 | - | - | - |
Ausführung ohne aktivierten Hochverfügbarkeitsmodus
Eine Ausführung ohne aktivierten HA-Modus (High Availability, Hochverfügbarkeit) ist möglich. Dies bedeutet, dass für Ihre Redis-Instanz keine Replikation aktiviert ist und sie keinen Zugriff auf das Verfügbarkeits-SLA hat. Die Ausführung im Nicht-HA-Modus wird außerhalb von Entwicklungs-/Testszenarien nicht empfohlen. Sie können die Hochverfügbarkeit in einer bereits erstellten Instanz nicht deaktivieren. Sie können die Hochverfügbarkeit aber in einer Instanz aktivieren, die noch nicht darüber verfügt. Da eine Instanz, die ohne hohe Verfügbarkeit ausgeführt wird, weniger VMs/Knoten verwendet, können vCPUs nicht so effizient genutzt werden, sodass die Leistung möglicherweise niedriger ist.
Reservierter Arbeitsspeicher
Bei jeder Azure Managed Redis-Instanz werden etwa 20 % des verfügbaren Speichers als Puffer für Nicht-Cachevorgänge reserviert, z. B. Replikation während des Failovers und Puffer für die aktive Georeplikation. Dieser Puffer trägt dazu bei, die Cacheleistung zu verbessern und einen Mangel an Arbeitsspeicher zu verhindern.
Herunterskalieren
Das Herunterskalieren wird derzeit in Azure Managed Redis nicht unterstützt. Weitere Informationen finden Sie in den Voraussetzungen/Einschränkungen bei der Skalierung von Azure Managed Redis.
Ebene „Flash-optimiert“
Die Ebene „Flash-optimiert“ verwendet sowohl NVMe-Flashspeicher als auch RAM. Da Flashspeicher kostengünstiger ist, können Sie mit der Dienstebene „Flash-optimiert“ einen Kompromiss zwischen Leistung und Preiseffizienz erzielen.
Bei Flash-optimierten Instanzen befinden sich 20 % des Cachespeichers im RAM, während für die anderen 80 % Flashspeicher verwendet wird. Alle Schlüssel werden im RAM gespeichert, während die Werte entweder im Flashspeicher oder im RAM gespeichert werden können. Die Redis-Software bestimmt den Speicherort der Werte auf intelligente Weise. Heiße Werte, auf die häufig zugegriffen wird, werden im RAM gespeichert, während kalte Werte, die weniger häufig verwendet werden, im Flashspeicher gespeichert werden. Bevor Daten gelesen oder geschrieben werden, müssen sie in den RAM verschoben werden, wodurch sie zu heißen Daten werden.
Redis optimiert die Speichernutzung, um die bestmögliche Leistung zu erzielen. Daher belegt die Instanz zuerst den verfügbaren RAM, bevor Elemente dem Flashspeicher hinzugefügt werden. Das anfängliche Auffüllen des RAM hat einige Auswirkungen auf die Leistung:
- Beim Testen mit geringer Speichernutzung können eine bessere Leistung und kürzere Wartezeiten auftreten. Tests mit einer vollständigen Cache-Instanz können zu einer geringeren Leistung führen, da nur RAM in der Testphase mit geringer Arbeitsspeicherauslastung verwendet wird.
- Wenn Sie mehr Daten in den Cache schreiben, verringert sich der Anteil der Daten im RAM im Vergleich zum Flashspeicher, was in der Regel zu einer Abnahme der Wartezeit- und Durchsatzleistung führt.
Für die Dienstebene „Flash-optimiert“ geeignete Workloads
Workloads, die sich voraussichtlich gut für die Ausführung mit der Dienstebene „Flash-optimiert“ eignen, weisen oft die folgenden Merkmale auf:
- Leseintensiv mit einem hohen Anteil von Lesebefehlen gegenüber Schreibbefehlen
- Der Zugriff liegt schwerpunktmäßig auf einer Teilmenge von Schlüsseln, die deutlich häufiger verwendet werden als der Rest des Datasets.
- Relativ große Werte im Vergleich zu den Schlüsselnamen (Da Schlüsselnamen immer im RAM gespeichert werden, können große Werte einen Engpass für die Arbeitsspeichervergrößerung verursachen.)
Für die Dienstebene „Flash-optimiert“ nicht geeignete Workloads
Einige Workloads verfügen über Zugriffseigenschaften, die für das Design der Flash-optimierten Ebene weniger gut geeignet sind:
- Schreibintensiv
- Zufällige oder einheitliche Datenzugriffsmuster im Großteil des Datasets.
- Lange Schlüsselnamen mit relativ kleinen Werten