Tutorial: Durchführen der Vektorähnlichkeitssuche für Azure OpenAI-Einbettungen mit Azure Cache for Redis
In diesem Tutorial durchlaufen Sie einen einfachen Anwendungsfall für die Vektorähnlichkeitssuche. Sie verwenden Einbettungen, die von Azure OpenAI Service generiert werden, und die integrierten Vektorsuchfunktionen der Enterprise-Ebene von Azure Cache for Redis, um ein Dataset mit Filmen abzufragen, um die relevanteste Übereinstimmung zu finden.
Das Tutorial verwendet das Wikipedia Movie Plots-Dataset, das Inhaltsangaben von über 35.000 Filmen aus Wikipedia für die Jahre 1901 bis 2017 enthält. Das Dataset enthält eine Inhaltsangabe für die einzelnen Filme sowie Metadaten wie das Jahr, in dem der Film veröffentlicht wurde, die Regisseure, Hauptdarsteller und das Genre. Sie führen die Schritte des Tutorials aus, um Einbettungen basierend auf der Inhaltsangabe zu generieren und die anderen Metadaten zum Ausführen von Hybridabfragen zu verwenden.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen einer für die Vektorsuche konfigurierten Azure Cache for Redis-Instanz
- Installieren Sie Azure OpenAI und andere erforderliche Python-Bibliotheken.
- Laden Sie das Filmdataset herunter, und bereiten Sie es für die Analyse vor.
- Verwenden Sie das Modell text-embedding-ada-002 (Version 2), um Einbettungen zu generieren.
- Erstellen eines Vektorindex in Azure Cache for Redis
- Verwenden Sie Kosinusähnlichkeit, um die Suchergebnisse zu priorisieren.
- Verwenden Sie Hybridabfragefunktionen über RediSearch, um die Daten vorab zu filtern und die Vektorsuche noch leistungsfähiger zu machen.
Wichtig
In diesem Tutorial erfahren Sie, wie Sie eine Jupyter Notebook-Instanz erstellen. Sie können dieses Tutorial mit einer Python-Codedatei (PY-Datei) durchführen und ähnliche Ergebnisse erhalten. Sie müssen jedoch alle Codeblöcke in diesem Tutorial der Datei .py hinzufügen und einmal ausführen, um Ergebnisse anzuzeigen. Mit anderen Worten: Jupyter Notebook-Instanzen stellen beim Ausführen von Zellen Zwischenergebnisse bereit, dieses Verhalten sollten Sie jedoch nicht beim Arbeiten in einer Python-Codedatei erwarten.
Wichtig
Wenn Sie das Tutorial stattdessen mithilfe einer fertigen Jupyter Notebook-Instanz ausführen möchten, laden Sie die Jupyter Notebook-Datei mit dem Namen tutorial.ipynb herunter, und speichern Sie sie im neuen Ordner redis-vector.
Voraussetzungen
- Azure-Abonnement: Kostenloses Azure-Konto
- Zugriff auf Azure OpenAI im gewünschten Azure-Abonnement gewährt. Derzeit müssen Sie den Zugriff auf Azure OpenAI beantragen. Sie können den Zugriff auf Azure OpenAI beantragen, indem Sie das Formular unter https://aka.ms/oai/access ausfüllen.
- Python 3.8 oder eine höhere Version
- Jupyter Notebook-Instanzen (optional)
- Eine Azure OpenAI-Ressource mit dem implementierten Modell text-embedding-ada-002 (Version 2). Dieses Modell ist derzeit nur in bestimmten Regionen verfügbar. Anweisungen zum Bereitstellen des Modells finden Sie im Leitfaden zur Ressourcenbereitstellung.
Erstellen einer Azure Cache for Redis-Instanz
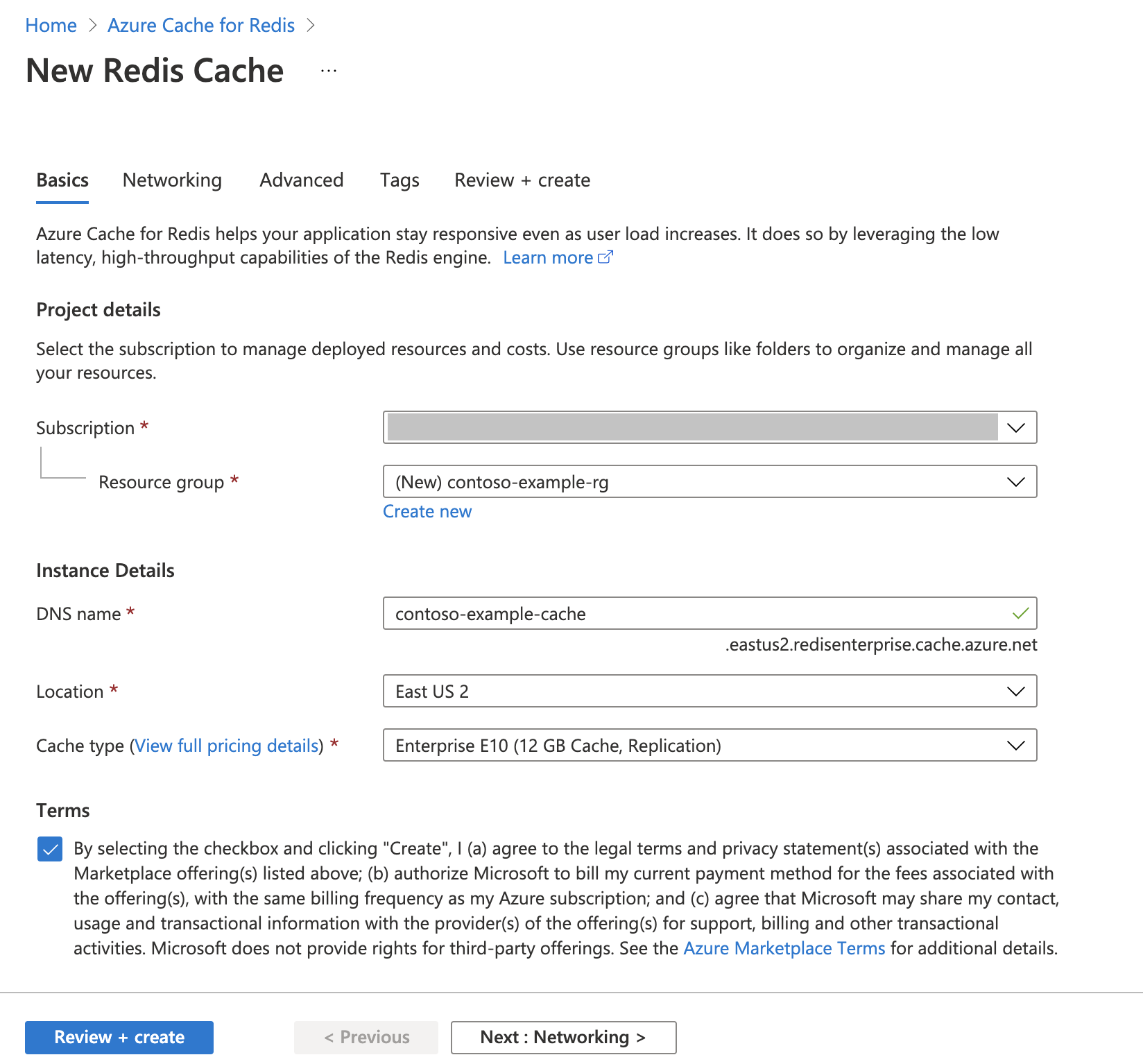
Befolgen Sie den Leitfaden unter Schnellstart: Erstellen einer Redis Cache-Instanz. Stellen Sie auf der Seite Erweitert sicher, dass Sie das Modul RediSearch hinzugefügt und die Enterprise-Clusterrichtlinie ausgewählt haben. Alle anderen Einstellungen können den in der Schnellstartanleitung beschriebenen Standardeinstellung entsprechen.
Das Erstellen des Cache dauert einige Minuten. In der Zwischenzeit können Sie mit dem nächsten Schritt fortfahren.
Einrichten der Entwicklungsumgebung
Erstellen Sie auf Ihrem lokalen Computer einen Ordner namens redis-vector an dem Speicherort, an dem Sie Ihre Projekte normalerweise speichern.
Erstellen Sie eine neue Python-Datei (tutorial.py) oder eine Jupyter Notebook-Instanz (tutorial.ipynb) im Ordner.
Installieren Sie die erforderlichen Python-Pakete:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Herunterladen des Datasets
Navigieren Sie hierzu in einem Webbrowser zu https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Melden Sie sich bei Kaggle an, oder registrieren Sie sich bei Kaggle. Zum Herunterladen der Datei ist eine Registrierung erforderlich.
Wählen Sie in Kaggle den Link Download aus, um die Datei archive.zip herunterzuladen.
Extrahieren Sie die Datei archive.zip, und verschieben Sie wiki_movie_plots_deduped.csv in den Ordner redis-vector.
Importieren von Bibliotheken und Einrichten von Verbindungsinformationen
Für erfolgreiche Azure OpenAI-Aufrufe benötigen Sie einen Endpunkt und einen Schlüssel. Sie benötigen außerdem einen Endpunkt und einen Schlüssel, um eine Verbindung mit Azure Cache for Redis herzustellen.
Wechseln Sie im Azure-Portal zu Ihrer Azure OpenAI-Ressource.
Suchen Sie die Werte für Endpunkt und Schlüssel im Abschnitt Ressourcenverwaltung. Kopieren Sie die Werte für Endpunkt und Zugriffsschlüssel, da Sie beide für die Authentifizierung Ihrer API-Aufrufe benötigen. Ein Beispielendpunkt ist
https://docs-test-001.openai.azure.com. Sie könnenKEY1oderKEY2verwenden.Navigieren Sie im Azure-Portal zur Seite Übersicht Ihrer Azure Cache for Redis-Ressource. Kopieren Sie Ihren Endpunkt.
Suchen Sie im Abschnitt Einstellungen nach Zugriffsschlüssel. Kopieren Sie Ihren Zugriffsschlüssel. Sie können
PrimaryoderSecondaryverwenden.Fügen Sie einer neuen Codezelle den folgenden Code hinzu:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Aktualisieren Sie den Wert von
API_KEYundRESOURCE_ENDPOINTmit den Schlüssel- und Endpunktwerten aus Ihrer Azure OpenAI-Bereitstellung.DEPLOYMENT_NAMEsollte mithilfe des Einbettungsmodellstext-embedding-ada-002 (Version 2)auf den Namen Ihrer Bereitstellung festgelegt werden, undMODEL_NAMEsollte das spezifische verwendete Einbettungsmodell sein.Aktualisieren Sie
REDIS_ENDPOINTundREDIS_PASSWORDmit dem Endpunkt- und dem Schlüsselwert aus der Azure Cache for Redis-Instanz.Wichtig
Es wird dringend empfohlen, Umgebungsvariablen oder einen Geheimnis-Manager wie Azure Key Vault zu verwenden, um den API-Schlüssel, den Endpunkt und den Bereitstellungsnamen zu übergeben. Diese Variablen werden hier der Einfachheit halber als Klartext festgelegt.
Führen Sie Codezelle 2 aus.
Importieren eines Datasets in Pandas und Verarbeiten von Daten
Als Nächstes lesen Sie die CSV-Datei in einen Pandas-Datenrahmen.
Fügen Sie einer neuen Codezelle den folgenden Code hinzu:
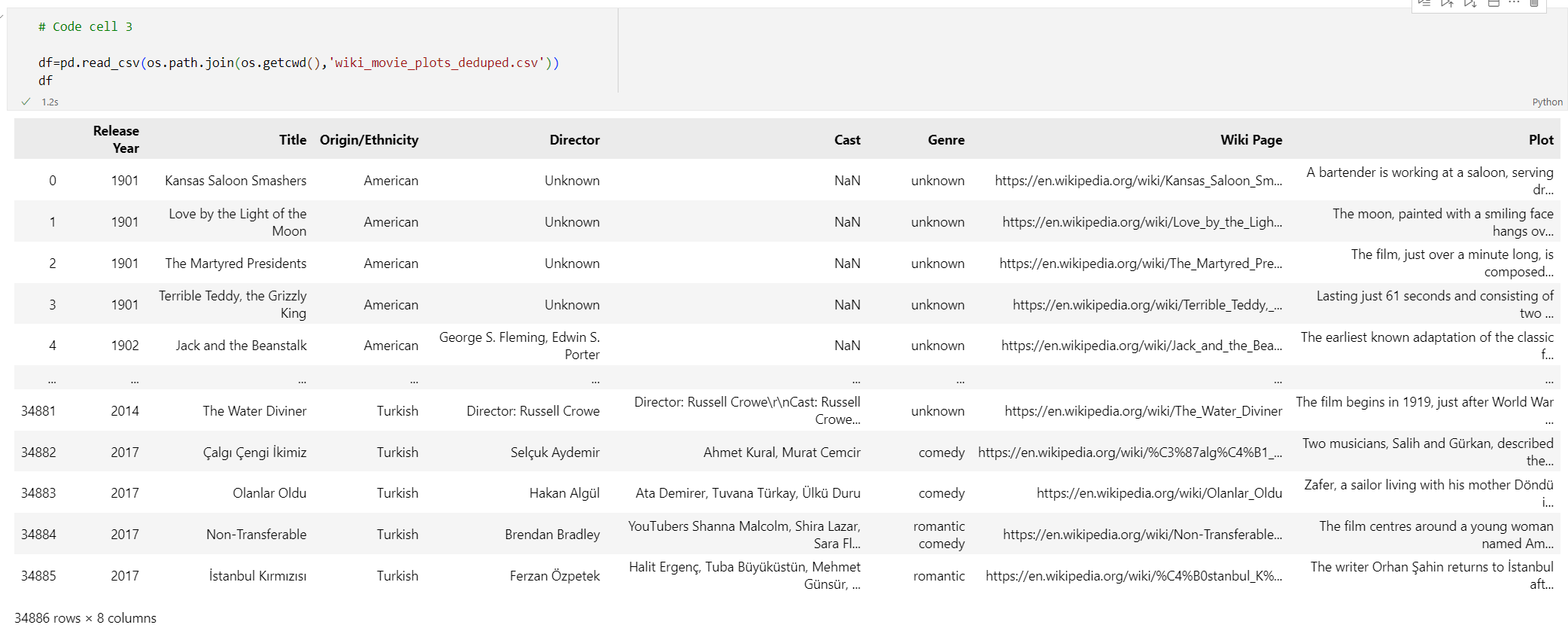
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfFühren Sie Codezelle 3 aus. Die folgende Ausgabe wird angezeigt.
Verarbeiten Sie als Nächstes die Daten, indem Sie einen
id-Index hinzufügen, Leerzeichen aus den Spaltentiteln entfernen und die Filme so filtern, dass nur Filme enthalten sind, die nach 1970 produziert wurden und aus englischsprachigen Ländern oder Regionen stammen. Durch diesen Filterschritt wird die Anzahl der Filme im Dataset reduziert. Dadurch werden die Kosten und die Zeit gesenkt, die zum Generieren von Einbettungen erforderlich sind. Sie können die Filterparameter je nach Ihren Einstellungen ändern oder entfernen.Fügen Sie zum Filtern der Daten den folgenden Code zu einer neuen Codezelle hinzu:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfFühren Sie Codezelle 4 aus. Die Ergebnisse sollten wie folgt aussehen:

Erstellen Sie eine Funktion, um die Daten zu bereinigen, indem Sie Leerzeichen und Interpunktionszeichen entfernen, und verwenden Sie sie dann für den Datenrahmen, der den Inhalt enthält.
Fügen Sie einer neuen Codezelle den folgenden Code hinzu, und führen Sie ihn aus:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Entfernen Sie schließlich alle Einträge, die Inhaltsangaben enthalten, die für das Einbettungsmodell zu lang sind. (Anders ausgedrückt: Sie erfordern mehr Token, als das Tokenlimit von 8.192 vorgibt.) Berechnen Sie dann die Anzahl der Token, die zum Generieren von Einbettungen erforderlich sind. Dies wirkt sich auch auf die Preise für die Einbettungsgenerierung aus.
Fügen Sie einer neuen Codezelle den folgenden Code hinzu:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Führen Sie Codezelle 6 aus. Die folgende Ausgabe sollte angezeigt werden:
Number of movies: 11125 Number of tokens required:7044844Wichtig
Weitere Informationen zum Berechnen der Kosten für das Generieren von Einbettungen basierend auf der Anzahl erforderlicher Token finden Sie unter Azure OpenAI Service – Preise.


Laden eines Datenrahmens in LangChain
Laden Sie den Datenrahmen mithilfe der DataFrameLoader-Klasse in LangChain. Sobald sich die Daten in LangChain-Dokumenten befinden, ist es viel einfacher, LangChain-Bibliotheken zu verwenden, um Einbettungen zu generieren und Ähnlichkeitssuchen durchzuführen. Legen Sie Plot für page_content_column fest, damit Einbettungen für diese Spalte generiert werden.
Fügen Sie einer neuen Codezelle den folgenden Code hinzu, und führen Sie ihn aus:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Generieren von Einbettungen und Laden in Redis
Nachdem die Daten gefiltert und in LangChain geladen wurden, erstellen Sie Einbettungen, damit Sie den Inhalt für jeden Film abfragen können. Der folgende Code konfiguriert Azure OpenAI, generiert Einbettungen und lädt die Einbettungsvektoren in Azure Cache for Redis.
Fügen Sie einer neuen Codezelle den folgenden Code hinzu:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Führen Sie Codezelle 8 aus. Dies kann mehr als 30 Minuten dauern. Es wird auch eine Datei vom Typ
redis_schema.yamlgeneriert. Diese Datei ist nützlich, wenn Sie eine Verbindung mit Ihrem Index in der Azure Cache for Redis-Instanz herstellen möchten, ohne Einbettungen neu zu generieren.
Wichtig
Die Geschwindigkeit, mit der Einbettungen generiert werden, hängt vom Kontingent ab, das für das Azure OpenAI-Modell verfügbar ist. Mit einem Kontingent von 240k-Token pro Minute dauert es etwa 30 Minuten, um die 7M-Token im Dataset zu verarbeiten.
Ausführen von Vektorsuchabfragen
Nachdem Ihr Dataset, die Azure OpenAI Service-API und die Redis-Instanz eingerichtet sind, können Sie mithilfe von Vektoren suchen. In diesem Beispiel werden die ersten 10 Ergebnisse für eine bestimmte Abfrage zurückgegeben.
Fügen Sie der Python-Codedatei den folgenden Code hinzu:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Führen Sie Codezelle 9 aus. Die folgende Ausgabe wird angezeigt:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Die Ähnlichkeitsbewertung wird zusammen mit der ordinalen Rangfolge von Filmen nach Ähnlichkeit zurückgegeben. Beachten Sie, dass bei spezifischeren Abfragen die Ähnlichkeitswerte in der Liste schneller abnehmen.
Hybridsuchvorgänge
Da RediSearch zusätzlich zur Vektorsuche auch umfangreiche Suchfunktionen bietet, ist es möglich, Ergebnisse nach den Metadaten im Dataset zu filtern, z. B. nach Filmgenre, Besetzung, Veröffentlichungsjahr oder Regisseur. Filtern Sie in diesem Fall basierend auf dem Genre
comedy.Fügen Sie einer neuen Codezelle den folgenden Code hinzu:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Führen Sie Codezelle 10 aus. Die folgende Ausgabe wird angezeigt:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Mit Azure Cache for Redis und Azure OpenAI Service können Sie Einbettungen und die Vektorsuche verwenden, um Ihrer Anwendung leistungsstarke Suchfunktionen hinzuzufügen.
Bereinigen von Ressourcen
Wenn Sie die in diesem Artikel erstellten Ressourcen weiterhin verwenden möchten, behalten Sie die Ressourcengruppe bei.
Wenn Sie die Ressourcen nicht mehr benötigen, können Sie die erstellte Azure-Ressourcengruppe ansonsten löschen, um Kosten zu vermeiden.
Wichtig
Das Löschen einer Ressourcengruppe kann nicht rückgängig gemacht werden. Beim Löschen einer Ressourcengruppe werden alle darin enthaltenen Ressourcen unwiderruflich gelöscht. Achten Sie daher darauf, dass Sie nicht versehentlich die falsche Ressourcengruppe oder die falschen Ressourcen löschen. Falls Sie die Ressourcen in einer vorhandenen Ressourcengruppe erstellt haben, die Ressourcen enthält, die Sie behalten wollen, können Sie jede Ressource einzeln löschen, statt die Ressourcengruppe zu löschen.
So löschen Sie eine Ressourcengruppe
Melden Sie sich beim Azure-Portal an, und wählen Sie anschließend Ressourcengruppen aus.
Wählen Sie die Ressourcengruppe aus, die Sie löschen möchten.
Wenn viele Ressourcengruppen vorhanden sind, verwenden Sie das Feld Nach einem beliebigen Feld filtern..., und geben Sie den Namen Ihrer Ressourcengruppe ein, die Sie für diesen Artikel erstellt haben. Wählen Sie die Ressourcengruppe in der Ergebnisliste aus.
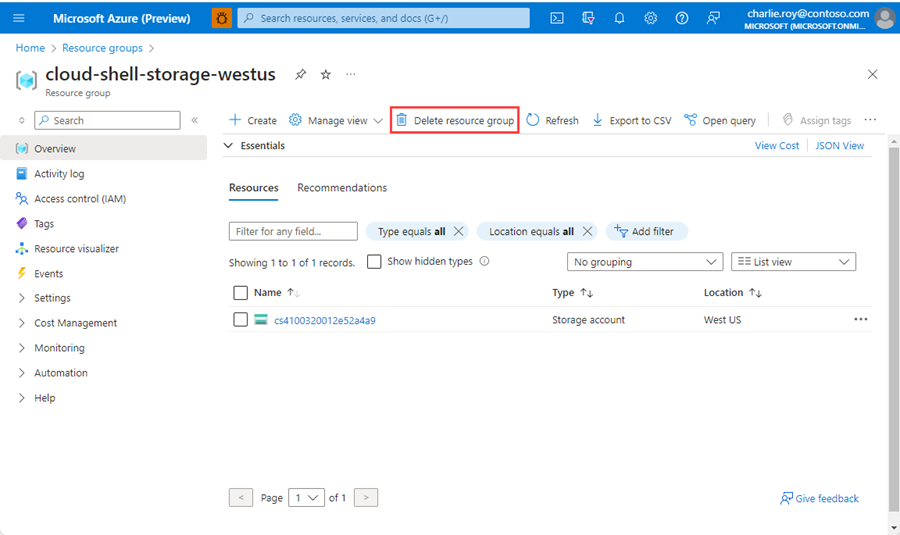
Wählen Sie die Option Ressourcengruppe löschen.
Sie werden aufgefordert, das Löschen der Ressourcengruppe zu bestätigen. Geben Sie den Namen Ihrer Ressourcengruppe ein, und wählen Sie Löschen aus.
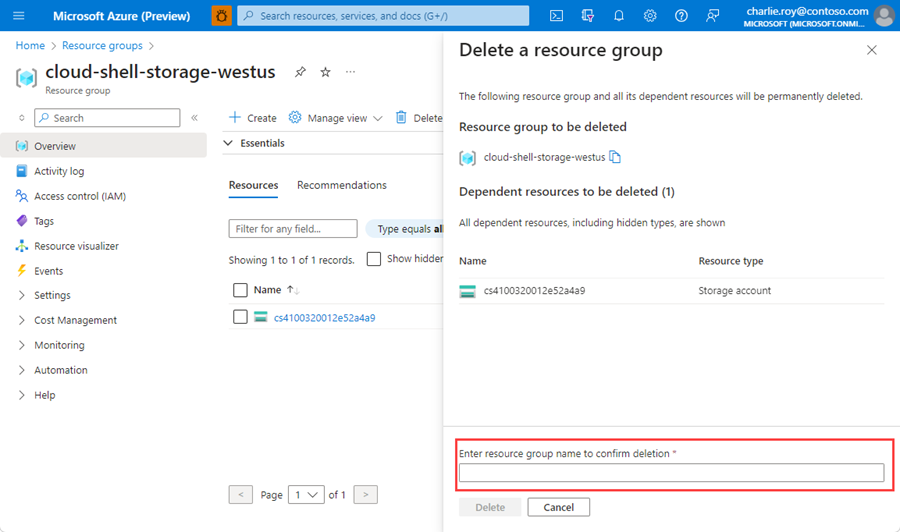
Daraufhin werden die Ressourcengruppe und alle darin enthaltenen Ressourcen gelöscht.
Verwandte Inhalte
- Weitere Informationen zu Azure Cache for Redis
- Weitere Informationen zu Azure Cache for Redis-Vektorsuchfunktionen finden Sie hier.
- Weitere Informationen zu von Azure OpenAI Service generierten Einbettungen
- Weitere Informationen zur Kosinusähnlichkeit
- Erfahren Sie, wie Sie eine KI-gestützte App mit OpenAI und Redis erstellen.
- Erstellen einer Q&A-App mit semantischen Antworten