Hochverfügbarkeit bei SQL Managed Instance mit Azure Arc-Unterstützung
Durch Azure Arc aktiviertes SQL Managed Instance wird in Kubernetes als containerisierte Anwendung bereitgestellt. Es verwendet Kubernetes-Konstrukte wie zustandsbehaftete Sätze und persistenten Speicher, um folgende integrierte Elemente bereitzustellen:
- Systemüberwachung
- Ausfallerkennung
- Automatisches Failover zum Erhalt der Dienststatus
Zur Verbesserung der Zuverlässigkeit können Sie auch eine durch Azure Arc aktivierte SQL Managed Instance-Instanz für die Bereitstellung mit zusätzlichen Replikaten in einer Hochverfügbarkeitskonfiguration konfigurieren. Der Arc Data Services-Datencontroller verwaltet Folgendes:
- Überwachung
- Ausfallerkennung
- Automatisches Failover
Der Datendienst mit Azure Arc-Unterstützung stellt diesen Dienst ohne Benutzerinteraktion bereit. Der Dienst:
- Richtet die Verfügbarkeitsgruppe ein
- Konfiguriert Endpunkte für die Datenbankspiegelung
- Fügt der Verfügbarkeitsgruppe Datenbanken hinzu
- Koordiniert Failover und Upgrade
In diesem Dokument werden beide Arten von Hochverfügbarkeit betrachtet.
Durch Azure Arc aktiviertes SQL Managed Instance bietet unterschiedliche Hochverfügbarkeitsstufen, je nachdem, ob SQL Managed Instance als Dienstebene Universell oder Unternehmenskritisch bereitgestellt wurde.
Hochverfügbarkeit auf der Dienstebene „Universell“
Auf der Ebene „Universell“ ist nur ein Replikat verfügbar, und die Hochverfügbarkeit wird über Kubernetes-Orchestrierung erreicht. Wenn z. B. ein Pod oder Knoten abstürzt, der das Containerimage einer verwalteten Instanz enthält, versucht Kubernetes, einen anderen Pod oder Knoten einzusetzen und an denselben persistenten Speicher anzufügen. Während dieser Zeit ist SQL Managed Instance für die Anwendungen nicht verfügbar. Die Anwendungen müssen die Verbindung wiederherstellen und die Transaktion erneut versuchen, wenn der neue Pod verfügbar ist. Wenn load balancer als Diensttyp verwendet wird, können sich Anwendungen erneut mit demselben primären Endpunkt verbinden, und Kubernetes leitet die Verbindung an den neuen primären Endpunkt weiter. Wenn nodeport als Diensttyp verwendet wird, müssen sich die Anwendungen erneut mit der neuen IP-Adresse verbinden.
Überprüfen der integrierten Hochverfügbarkeit
Um die von Kubernetes bereitgestellte Hochverfügbarkeit zu überprüfen, können Sie wie folgt vorgehen:
- Löschen des Pods einer vorhandenen verwalteten Instanz
- Überprüfen der Wiederherstellung von Kubernetes nach dieser Aktion
Während der Wiederherstellung startet Kubernetes einen anderen Pod und fügt den persistenten Speicher an.
Voraussetzungen
- Kubernetes-Cluster erfordern freigegebenen Remotespeicher.
- Durch Azure Arc aktiviertes SQL Managed Instance, bereitgestellt mit einem einzelnen Replikat (Standard)
Zeigen Sie die Pods an.
kubectl get pods -n <namespace of data controller>Löschen Sie den Pod der verwalteten Instanz.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Beispiel:
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedZeigen Sie die Pods an, um sich zu vergewissern, dass die verwaltete Instanz wiederhergestellt wird.
kubectl get pods -n <namespace of data controller>Zum Beispiel:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Nachdem alle Container im Pod wiederhergestellt wurden, können Sie eine Verbindung mit der verwalteten Instanz herstellen.
Hochverfügbarkeit auf der Dienstebene „Unternehmenskritisch“
Auf der Dienstebene „Unternehmenskritisch“ stellt Azure SQL Managed Instance zusätzlich zu dem, was die Kubernetes-Orchestrierung nativ bereitstellt, für Azure Arc eine enthaltene Verfügbarkeitsgruppe bereit. Die enthaltene Verfügbarkeitsgruppe basiert auf SQL Server AlwaysOn-Technologie. Sie bietet eine höheres Verfügbarkeitsniveau. Wenn durch Azure Arc aktiviertes SQL Managed Instance auf der Dienstebene Unternehmenskritisch bereitgestellt wird, kann es mit zwei oder drei Replikaten bereitgestellt werden. Diese Replikate werden stets miteinander synchronisiert.
Bei enthaltenen Verfügbarkeitsgruppen sind alle Podabstürze oder Knotenausfälle für die Anwendung transparent. Die enthaltene Verfügbarkeitsgruppe stellt mindestens einen weiteren Pod bereit, der alle Daten aus dem primären Pod enthält und für Verbindungen bereit ist.
Enthaltene Verfügbarkeitsgruppen
Eine Verfügbarkeitsgruppe bindet eine oder mehrere Benutzerdatenbanken in eine logische Gruppe ein, sodass bei einem Failover die gesamte Gruppe von Datenbanken als einzelne Einheit auf das sekundäre Replikat übergeht. Eine Verfügbarkeitsgruppe repliziert nur die Daten in den Benutzerdatenbanken, nicht aber die Daten in den Systemdatenbanken, z. B. Anmeldungen, Berechtigungen oder Agent-Aufträge. Eine enthaltene Verfügbarkeitsgruppe umfasst Metadaten aus Systemdatenbanken wie msdb- und master-Datenbanken. Wenn Anmeldungen im primären Replikat erstellt oder geändert werden, werden sie automatisch auch in den sekundären Replikaten erstellt. Wenn ein Auftrag im primären Replikat erstellt oder geändert wird, erhalten auch die sekundären Replikate diese Änderungen.
Durch Azure Arc aktiviertes SQL Managed Instance übernimmt dieses Konzept der enthaltenen Verfügbarkeitsgruppe und fügt einen Kubernetes-Operator hinzu, sodass diese im großen Stil bereitgestellt und verwaltet werden können.
Enthaltene Verfügbarkeitsgruppen ermöglichen Folgendes:
Bei der Bereitstellung mit mehreren Replikaten wird eine einzelne Verfügbarkeitsgruppe erstellt, die denselben Namen trägt wie die SQL Managed Instance mit Azure Arc-Unterstützung. Standardmäßig hat die enthaltene Verfügbarkeitsgruppe drei Replikate, einschließlich des primären Replikats. Alle CRUD-Vorgänge für die Verfügbarkeitsgruppe werden intern verwaltet – auch die Erstellung der Verfügbarkeitsgruppe oder die Verknüpfung von Replikaten mit der erstellten Verfügbarkeitsgruppe. Sie können in einer Instanz keine weiteren Verfügbarkeitsgruppen erstellen.
Alle Datenbanken werden automatisch zur Verfügbarkeitsgruppe hinzugefügt, einschließlich aller Benutzer- und Systemdatenbanken wie
masterundmsdb. Diese Funktion bietet eine Einzelsystemansicht zu den Replikaten der Verfügbarkeitsgruppen. Beachten die beiden Datenbankencontainedag_masterundcontainedag_msdb, wenn Sie eine direkte Verbindung mit der Instanz herstellen. Diecontainedag_*-Datenbanken repräsentieren die Elementemasterundmsdbinnerhalb der Verfügbarkeitsgruppe.Ein externer Endpunkt wird automatisch für die Verbindung mit Datenbanken innerhalb der Verfügbarkeitsgruppe bereitgestellt. Der Endpunkt
<managed_instance_name>-external-svcübernimmt die Rolle des Listeners der Verfügbarkeitsgruppe.
Bereitstellen von SQL Managed Instance mit Azure Arc-Unterstützung mit mehreren Replikaten über das Azure-Portal
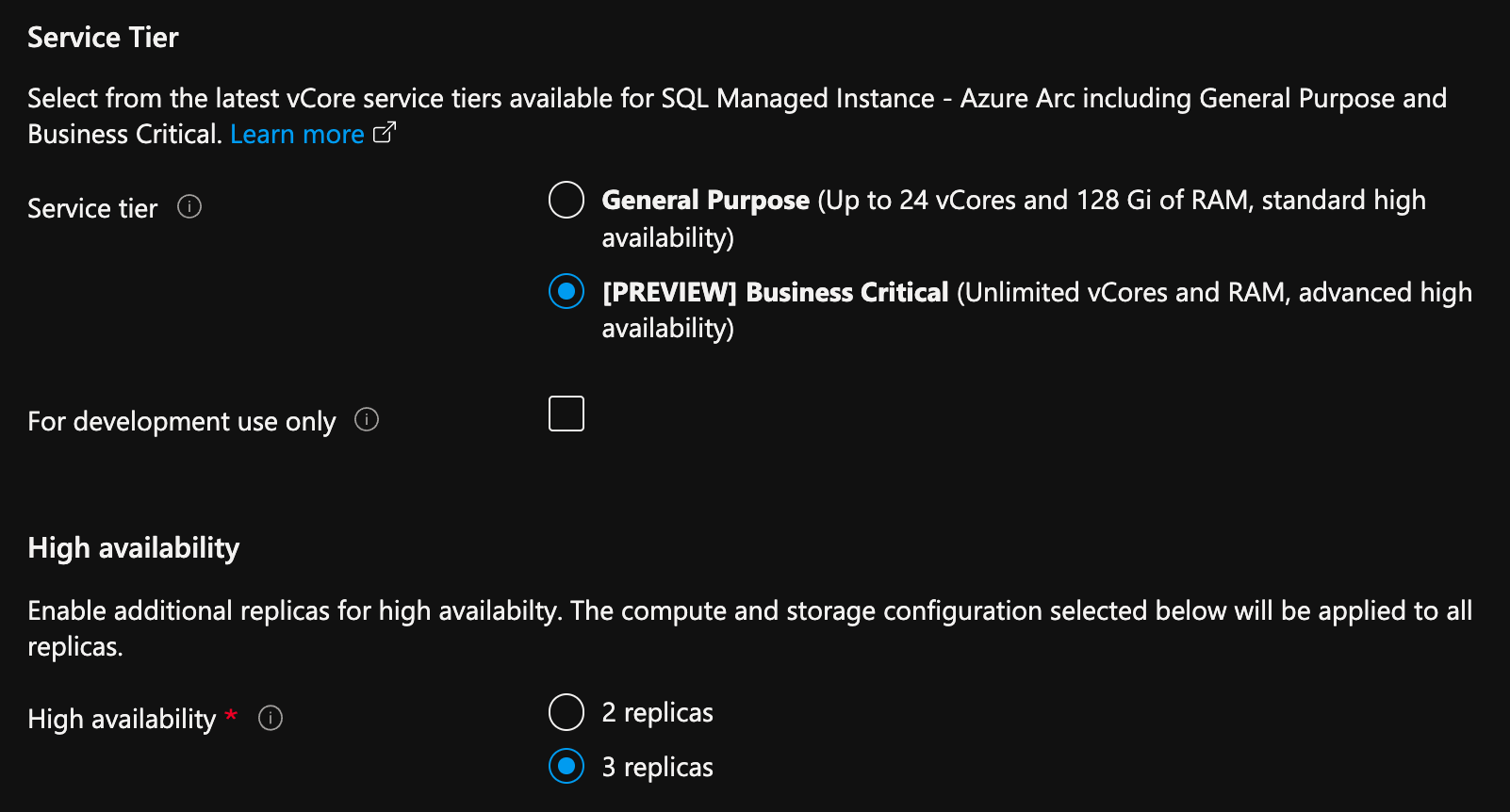
Gehen Sie im Azure-Portal auf der Seite für das Erstellen einer Instanz von SQL Managed Instance mit Azure Arc-Unterstützung wie folgt vor:
- Wählen Sie Compute- + Speicherressourcen konfigurieren unter „Compute + Speicher“ aus. Im Portal werden erweiterte Einstellungen angezeigt.
- Wählen Sie unter der Dienstebene die Option Unternehmenskritisch aus.
- Aktivieren Sie das Kontrollkästchen „Nur für die Entwicklung“, wenn Sie es für Entwicklungszwecke verwenden.
- Wählen Sie unter der Hochverfügbarkeit entweder 2 Replikate oder 3 Replikate aus.
Bereitstellen mit mehreren Replikaten mit der Azure-Befehlszeilenschnittstelle
Wenn eine Instanz von SQL Managed Instance mit Azure Arc-Unterstützung auf der Dienstebene „Unternehmenskritisch“ bereitgestellt wird, werden während der Bereitstellung mehrere Replikate erstellt. Die Einrichtung und Konfiguration der enthaltenen Verfügbarkeitsgruppen unter diesen Instanzen erfolgt automatisch während der Bereitstellung.
Der folgende Befehl erstellt z. B. eine verwaltete Instanz mit drei Replikaten.
Indirekter Verbindungsmodus:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Beispiel:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Direkter Verbindungsmodus:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Beispiel:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
Standardmäßig werden alle Replikate im synchronen Modus konfiguriert. Das bedeutet, dass alle Updates für die primäre Instanz synchron auf jede der sekundären Instanzen repliziert werden.
Anzeigen und Überwachen des Hochverfügbarkeitsstatus
Sobald die Bereitstellung abgeschlossen ist, stellen Sie eine Verbindung mit dem primären Endpunkt von SQL Server Management Studio her.
Überprüfen Sie den Endpunkt des primären Replikats, rufen Sie ihn ab und stellen Sie über SQL Server Management Studio eine Verbindung mit ihm her.
Wenn die SQL-Instanz beispielsweise mithilfe von service-type=loadbalancer bereitgestellt wurde, führen Sie den folgenden Befehl aus, um den Endpunkt abzurufen, mit dem eine Verbindung hergestellt werden soll:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
oder
kubectl get sqlmi -A
Abrufen des primären und sekundären Endpunkts und des Verfügbarkeitsgruppenstatus
Verwenden Sie die Befehle kubectl describe sqlmi oder az sql mi-arc show, um die primären und sekundären Endpunkte sowie den Hochverfügbarkeitsstatus anzuzeigen.
Beispiel:
kubectl describe sqlmi sqldemo -n my-namespace
oder
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Beispielausgabe:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
Sie können eine Verbindung mit dem primären Endpunkt mit SQL Server Management Studio herstellen und DMVs auf Folgendes überprüfen:
SELECT * FROM sys.dm_hadr_availability_replica_states
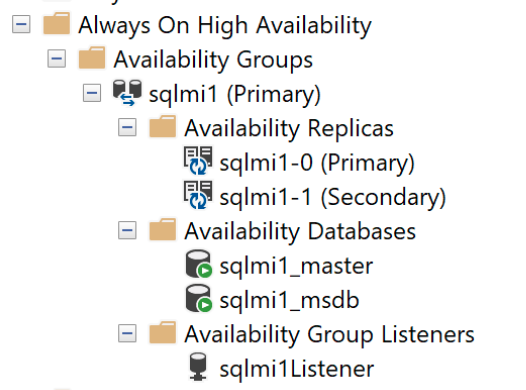
Und das Dashboard für die enthaltene Verfügbarkeit:
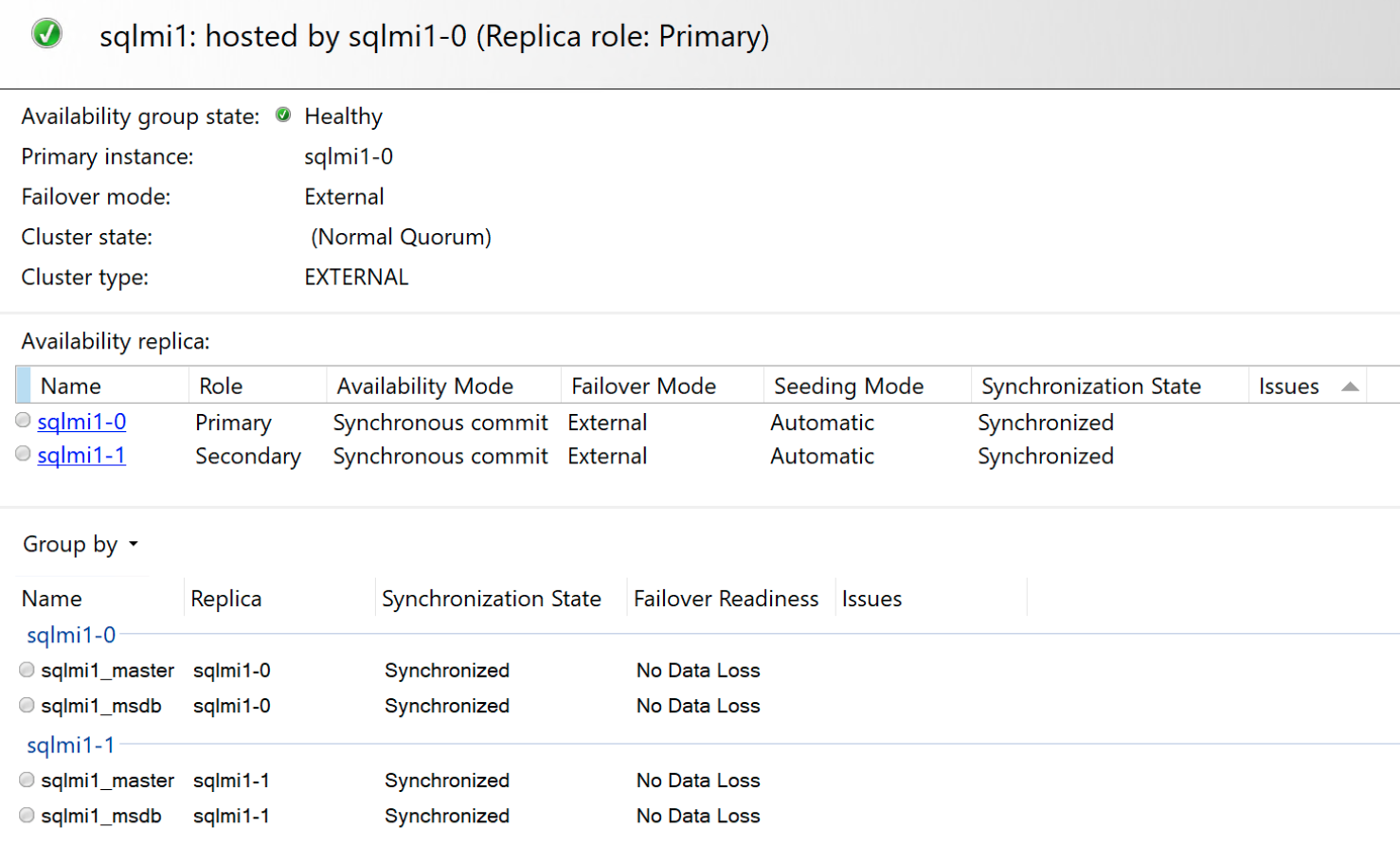
Failoverszenarien
Im Gegensatz zu SQL Server AlwaysOn-Verfügbarkeitsgruppen ist die enthaltene Verfügbarkeitsgruppe eine verwaltete Hochverfügbarkeitslösung. Daher sind die Failovermodi im Vergleich zu den typischen Modi, die mit SQL Server AlwaysOn-Verfügbarkeitsgruppen verfügbar sind, begrenzt.
Stellen Sie Dienstebene „Unternehmenskritisch“ für SQL Managed Instance in einer Konfiguration mit zwei oder drei Replikaten bereit. Die Auswirkungen von Ausfällen und die anschließende Wiederherstellbarkeit sind bei jeder Konfiguration unterschiedlich. Eine Instanz mit drei Replikaten bietet ein wesentlich höheres Maß an Verfügbarkeit und Wiederherstellbarkeit als eine Instanz mit zwei Replikaten.
In einer Konfiguration mit zwei Replikaten wird das sekundäre Replikat automatisch zum primären Replikat höher gestuft, wenn beide Knotenzustände SYNCHRONIZED sind und das primäre Replikat nicht mehr verfügbar ist. Wenn das ausgefallene Replikat verfügbar wird, wird es mit allen ausstehenden Änderungen aktualisiert. Wenn es Probleme mit der Konnektivität zwischen den Replikaten gibt, kann es sein, dass das primäre Replikat keine Transaktionen festlegt, da jede Transaktion auf beiden Replikaten festgelegt werden muss, bevor ein Erfolg auf dem primären zurückgegeben wird.
In einer Konfiguration mit drei Replikaten muss eine Transaktion mindestens zwei der drei Replikate committen, bevor eine Erfolgsmeldung an die Anwendung zurückgegeben wird. Im Falle eines Ausfalls wird eines der sekundären Replikate automatisch zum primären Replikat höher gestuft, während Kubernetes versucht, das ausgefallene Replikat wiederherzustellen. Wenn das Replikat verfügbar wird, wird es automatisch wieder mit der enthaltenen Verfügbarkeitsgruppe verbunden, und ausstehende Änderungen werden synchronisiert. Wenn es Verbindungsprobleme zwischen den Replikaten gibt und mehr als zwei Replikate nicht synchron sind, wird das primäre Replikat keine Transaktionen committen.
Hinweis
Es wird empfohlen, eine SQL Managed Instance mit der Dienstebene „Unternehmenskritisch“ in einer Konfiguration mit drei Replikaten statt mit zwei Replikaten bereitzustellen, um Datenverluste auf ein Minimum zu beschränken.
Um für ein geplantes Ereignis einen Failover vom primären Replikat auf eines der sekundären Replikate durchzuführen, führen Sie den folgenden Befehl aus:
Wenn Sie eine Verbindung mit dem primären Replikat herstellen, können Sie das folgende T-SQL verwenden, um für die SQL-Instanz ein Failover auf eines der sekundären Replikate durchzuführen:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
Wenn Sie eine Verbindung mit dem sekundären Replikat herstellen, können Sie folgendes T-SQL verwenden, um das gewünschte sekundäre Replikat zum primären Replikat höherzustufen.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Bevorzugtes primäres Replikat
Sie können auch ein bestimmtes Replikat als primäres Replikat festlegen, indem Sie die Azure CLI wie folgt verwenden:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Beispiel:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Hinweis
Kubernetes wird versuchen, das bevorzugte Replikat festzulegen, was jedoch nicht garantiert werden kann.
Wiederherstellen einer Datenbank auf einer Instanz mit mehreren Replikaten
Für die Wiederherstellung einer Datenbank in einer Verfügbarkeitsgruppe müssen zusätzliche Schritte ausgeführt werden. Die folgenden Schritte zeigen, wie Sie eine Datenbank in einer verwalteten Instanz wiederherstellen und einer Verfügbarkeitsgruppe hinzufügen.
Machen Sie den externen Endpunkt der primären Instanz verfügbar, indem Sie einen neuen Kubernetes-Dienst erstellen.
Bestimmen Sie den Pod, der das primäre Replikat hostet. Stellen Sie eine Verbindung mit der verwalteten Instanz her, und führen Sie Folgendes aus:
SELECT @@SERVERNAMEDie Abfrage gibt den Pod zurück, der das primäre Replikat hostet.
Erstellen Sie den Kubernetes-Dienst auf der primären Instanz durch Ausführen des folgenden Befehls, falls von Ihrem Kubernetes-Cluster
NodePort-Dienste verwendet werden. Ersetzen Sie<podName>durch den Namen des im vorherigen Schritt zurückgegebenen Servers und<serviceName>durch den bevorzugten Namen für den erstellten Kubernetes-Dienst.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortFühren Sie für einen Lastenausgleichsdienst den gleichen Befehl aus. In diesem Fall wird jedoch ein Dienst vom Typ
LoadBalancererstellt. Beispiel:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerIm Anschluss finden Sie ein Beispiel für diesen Befehl, der für Azure Kubernetes Service ausgeführt wird, wobei
sql2-0der Pod ist, der das primäre Replikat hostet:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerRufen Sie die IP-Adresse des erstellten Kubernetes-Diensts ab:
kubectl get services -n <namespaceName>Stellen Sie die Datenbank am Endpunkt der primären Instanz wieder her.
Fügen Sie die Datenbanksicherungsdatei dem Container der primären Instanz hinzu.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Beispiel
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcFühren Sie den folgenden Befehl aus, um die Datenbanksicherungsdatei wiederherzustellen:
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOBeispiel
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOFügen Sie die Datenbank der Verfügbarkeitsgruppe hinzu.
Damit die Datenbank der Verfügbarkeitsgruppe hinzugefügt werden kann, muss sie im vollständigen Wiederherstellungsmodus ausgeführt werden, und es muss eine Protokollsicherung durchgeführt werden. Führen Sie die folgenden TSQL-Anweisungen aus, um die wiederhergestellte Datenbank der Verfügbarkeitsgruppe hinzuzufügen:
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>Im folgenden Beispiel wird die Datenbank
WideWorldImportershinzugefügt, die auf der Instanz wiederhergestellt wurde:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Wichtig
Als bewährte Methode sollten Sie den oben erstellten Kubernetes-Dienst löschen, indem Sie diesen Befehl ausführen:
kubectl delete svc sql2-0-p -n arc
Begrenzungen
Für durch Azure Arc aktivierte SQL Managed Instance-Verfügbarkeitsgruppen gelten die gleichen Einschränkungen wie für Verfügbarkeitsgruppen eines Big Data-Clusters. Weitere Informationen finden Sie unter Bereitstellen von Big Data-Clustern in SQL Server mit Hochverfügbarkeit.
Zugehöriger Inhalt
Weitere Informationen zu Features und Funktionen von durch Azure Arc aktiviertem SQL Managed Instance