Um zu überprüfen, ob Anwendungen und Dienste ordnungsgemäß ausgeführt werden, können Sie das Muster für die Überwachung der Integrität von Endpunkten verwenden. Dieses Muster gibt die Verwendung von Funktionsüberprüfungen in einer Anwendung an. Externe Tools können in regelmäßigen Abständen über verfügbar gemachte Endpunkte auf diese Überprüfungen zugreifen.
Kontext und Problem
Es empfiehlt sich, Webanwendungen und Back-End-Dienste zu überwachen. Die Überwachung trägt dazu bei, sicherzustellen, dass Anwendungen und Dienste verfügbar sind und ordnungsgemäß ausgeführt werden. Geschäftliche Anforderungen umfassen häufig eine Überwachung.
Es ist manchmal schwieriger, Clouddienste zu überwachen als lokale Dienste. Ein Grund dafür ist, dass Sie keine vollständige Kontrolle über die Hostingumgebung haben. Ein anderer Grund ist, dass die Dienste in der Regel von anderen Diensten abhängen, die von Plattformanbietern und anderen Anbietern bereitgestellt werden.
Es gibt viele Faktoren, die sich auf in der Cloud gehostete Anwendungen auswirken. Dazu gehören beispielsweise die Netzwerklatenz, die Leistung und Verfügbarkeit der zugrunde liegenden Compute- und Speichersysteme und die Netzwerkbandbreite zwischen diesen. Jeder dieser Faktoren kann zu einem Dienstausfall führen. Um das erforderliche Maß an Verfügbarkeit sicherzustellen, müssen Sie in regelmäßigen Abständen überprüfen, ob Ihr Dienst ordnungsgemäß ausgeführt wird. Ihre Vereinbarung zum Servicelevel (Service Level Agreement, SLA) kann das Maß an Verfügbarkeit angeben, das Sie erfüllen müssen.
Lösung
Implementieren Sie die Integritätsüberwachung, indem Sie Anforderungen an einen Endpunkt Ihrer Anwendung senden. Die Anwendung muss die notwendigen Überprüfungen durchführen und dann eine Statusangabe zurückgeben.
Eine Überwachungsprüfung der Integrität kombiniert typischerweise zwei Faktoren:
- Die Überprüfungen (falls vorhanden), die von der Anwendung oder dem Dienst als Reaktion auf die Anforderung zur Überprüfung der Endpunktintegrität ausgeführt werden
- Die Analyse der Ergebnisse durch das Tool oder Framework, das die Integritätsüberprüfung durchführt
Der Antwortcode gibt den Status der Anwendung an. Optional kann der Antwortcode auch den Status von Komponenten und Diensten angeben, die von der App verwendet werden. Das Überwachungstool oder -framework führt die Überprüfung der Latenz bzw. Antwortzeit aus.
Die folgende Abbildung zeigt eine Übersicht über das Muster.
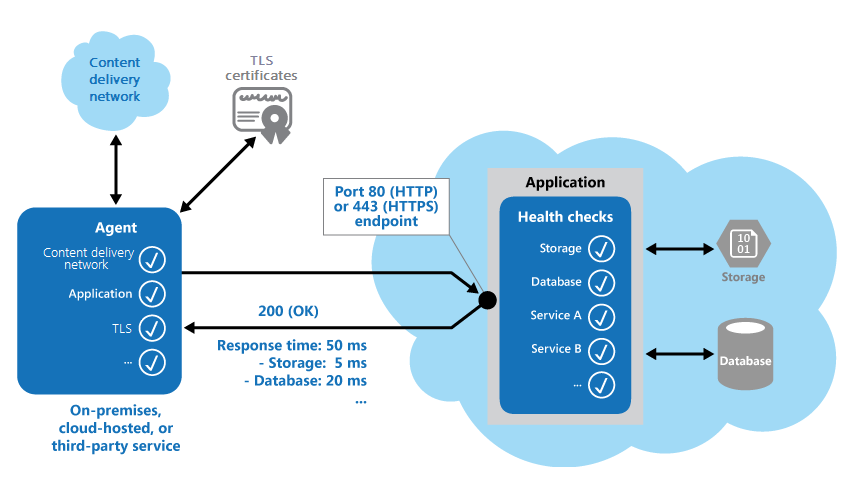
Der Code für die Integritätsüberwachung in der Anwendung kann auch andere Überprüfungen ausführen, um Folgendes zu ermitteln:
- Verfügbarkeit und Antwortzeit eines Cloudspeichers oder einer Datenbank.
- Status anderer Ressourcen oder Dienste, die von der Anwendung verwendet werden. Diese Ressourcen und Dienste können sich innerhalb oder außerhalb der Anwendung befinden.
Es stehen Dienste und Tools zur Verfügung, die Webanwendungen überwachen, indem sie eine Anforderung an einen konfigurierbaren Satz von Endpunkten senden. Dann werten diese Dienste und Tools die Ergebnisse anhand einer Reihe konfigurierbarer Regeln aus. Es ist relativ einfach, einen Dienstendpunkt zu erstellen, dessen einziger Zweck es ist, Funktionstests in einem System auszuführen.
Überwachungstools führen häufig solche typischen Überprüfungen aus:
- Validieren des Antwortcodes. Die HTTP-Antwort 200 (OK) gibt beispielsweise an, dass die Anwendung fehlerfrei antwortet. Das Überwachungssystem kann auch auf andere Antwortcodes prüfen, um umfassendere Ergebnisse zu liefern.
- Überprüfung des Antwortinhalts, um Fehler zu erkennen, auch wenn der Statuscode „200 (OK)“ lautet. Durch Überprüfen des Inhalts können Sie Fehler erkennen, die nur einen Teil der zurückgegebenen Antwort der Webseite oder des Diensts betreffen. Sie können z. B. den Titel einer Seite überprüfen oder nach einer bestimmten Wortgruppe suchen, die darauf hinweist, dass die App die richtige Seite zurückgegeben hat.
- Messung der Antwortzeit. Der Wert enthält die Netzwerklatenz und die Zeit, die die Anwendung zum Ausgeben der Anforderung benötigt hat. Ein steigender Wert kann auf ein auftauchendes Problem mit der Anwendung oder dem Netzwerk hinweisen.
- Überprüfung von Ressourcen oder Diensten außerhalb der Anwendung. Ein Beispiel hierfür ist ein Content Delivery Network, das von der Anwendung verwendet wird, um Inhalte aus globalen Caches bereitzustellen.
- Überprüfung des Ablaufs von TLS-Zertifikaten.
- Messung der Antwortzeit eines DNS-Lookups nach der URL der Anwendung. Diese Überprüfung misst DNS-Latenz und DNS-Fehler.
- Validierung der vom DNS-Lookup zurückgegebenen URL. Durch diese Validierung können Sie sicherstellen, dass die Einträge richtig sind. Damit lassen sich auch böswillige Anforderungsumleitungen verhindern, die nach einem erfolgreichen Angriff auf Ihren DNS-Server auftreten können.
Sofern möglich, ist es auch nützlich, diese Überprüfungen an verschiedenen lokalen oder gehosteten Standorten durchzuführen und dann die Antwortzeiten zu messen und zu vergleichen. Idealerweise sollten Sie Anwendungen von Standorten aus überwachen, die sich in der Nähe von Kunden befinden. So erhalten Sie genaue Einblicke in die Leistung jedes Standorts. Diese Vorgehensweise stellt einen stabileren Überprüfungsmechanismus bereit. Die Ergebnisse können Ihnen auch bei folgenden Entscheidungen helfen:
- Wo soll Ihre Anwendung bereitgestellt werden?
- Soll sie in mehreren Rechenzentren bereitgestellt werden?
Um sicherzustellen, dass Ihre Anwendung für alle Kunden ordnungsgemäß funktioniert, führen Sie Tests für alle Dienstinstanzen aus, die von Kunden verwendet werden. Wenn beispielsweise der Kundenspeicher auf mehrere Speicherkonten verteilt ist, sollte der Überwachungsprozess jedes einzelne dieser Konten überprüfen.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei Ihrer Entscheidung, wie dieses Muster implementiert werden soll:
Überlegen Sie, wie die Antwort überprüft werden soll. Entscheiden Sie z. B., ob die Angabe des Statuscodes „200 (OK)“ ausreicht, um zu bestätigen, dass die Anwendung ordnungsgemäß funktioniert. Die Überprüfung des Statuscodes ist die Minimalimplementierung dieses Musters. Ein Statuscode stellt eine grundlegende Kennzahl für die Verfügbarkeit einer Anwendung bereit. Ein solcher Code liefert allerdings wenig Informationen über Vorgänge, Trends und potenzielle Probleme in der Anwendung.
Bestimmen Sie die Anzahl der Endpunkte, die für eine Anwendung verfügbar gemacht werden sollen. Ein Ansatz sieht vor, dass mindestens ein Endpunkt für die von der Anwendung verwendeten Kerndienste und ein weiterer Endpunkt für Dienste mit geringerer Priorität verfügbar gemacht wird. Auf diese Weise können Sie den Überwachungsergebnissen unterschiedliche Wichtigkeitsstufen zuweisen. Erwägen Sie außerdem, weitere Endpunkte verfügbar zu machen. Sie können einen Endpunkt für jeden Kerndienst verfügbar machen, um die Granularität der Überwachung zu erhöhen. Beispielsweise kann eine Integritätsüberprüfung die Datenbank, den Speicher und einen externen Geocodierungsdienst einer Anwendung überprüfen. Jede dieser Komponente erfordert ein anderes Maß an Verfügbarkeit und Antwortzeit. Möglicherweise ist der Geocodierungsdienst oder eine andere Hintergrundaufgabe für einige Minuten nicht verfügbar. Die Anwendung kann jedoch immer noch fehlerfrei funktionieren.
Entscheiden Sie, ob für die Überwachung und für den allgemeinen Zugriff ein und derselbe Endpunkt verwendet werden soll. Sie können für beides denselben Endpunkt verwenden – richten Sie dann aber einen bestimmten Pfad für die Integritätsüberprüfungen ein. Dafür können Sie beispielsweise /health auf dem Endpunkt für den allgemeinen Zugriff verwenden. Mit diesem Ansatz können Überwachungstools einige Funktionstests in der Anwendung ausführen. Beispiele hierfür sind das Registrieren neuer Benutzer*innen, deren Anmeldung und das Erteilen eines Testauftrags. Gleichzeitig können Sie auch überprüfen, ob der allgemeine Zugriffsendpunkt verfügbar ist.
Legen Sie fest, welche Art von Informationen im Dienst als Reaktion auf Überwachungsanforderungen gesammelt werden sollen. Sie müssen auch bestimmen, wie diese Informationen zurückgegeben werden sollen. Die meisten vorhandenen Tools und Frameworks untersuchen nur den HTTP-Statuscode, den der Endpunkt zurückgibt. Um zusätzliche Informationen zurückzugeben und zu überprüfen, müssen Sie möglicherweise ein Überwachungshilfsprogramm oder einen Dienst selbst erstellen.
Ermitteln Sie, wie viele Informationen gesammelt werden sollen. Übermäßig viele Verarbeitungsvorgänge während der Überprüfung können die Anwendung überlasten und andere Benutzer*innen beeinträchtigen. Die Verarbeitungszeit kann auch das Timeout des Überwachungssystems überschreiten. Das kann dazu führen, dass das System die Anwendung als nicht verfügbar kennzeichnet. Die meisten Anwendungen enthalten eine Form der Instrumentierung, z. B. Fehlerhandler und Leistungsindikatoren. Diese Tools können Leistungs- und detaillierte Fehlerinformationen protokollieren, was möglicherweise ausreichend ist. Erwägen Sie die Verwendung dieser Daten anstelle der Rückgabe von zusätzlichen Informationen aus einer Integritätsüberprüfung.
Erwägen Sie die Zwischenspeicherung des Endpunktstatus. Eine häufige Ausführung der Integritätsüberprüfung kann ressourcenintensiv sein. Wenn der Integritätsstatus beispielsweise über ein Dashboard gemeldet wird, ist es nicht wünschenswert, dass jede Anforderung an das Dashboard eine Integritätsüberprüfung auslöst. Lassen Sie stattdessen den Systemstatus regelmäßig überprüfen und den Status zwischenspeichern. Machen Sie einen Endpunkt verfügbar, der den Status aus dem Cache zurückgibt.
Planen Sie, wie die Sicherheit für die Überwachungsendpunkte konfiguriert wird. Durch Konfigurieren der Sicherheit können Sie die Endpunkte vor öffentlichem Zugriff schützen, der zu Folgendem führen kann:
- Die Anwendung kann Angriffen ausgesetzt sein.
- Vertrauliche Informationen können offengelegt werden.
- Denial-of-Service-Angriffe (DoS) können angelockt werden.
In der Regel konfigurieren Sie die Sicherheit in der Anwendungskonfiguration. So können Sie die Einstellungen problemlos aktualisieren, ohne die Anwendung neu zu starten. Erwägen Sie eine oder mehrere der folgenden Vorgehensweisen:
Schützen Sie den Endpunkt, indem eine Authentifizierung angefordert wird. Wenn der Überwachungsdienst oder das Überwachungstool die Authentifizierung unterstützt, können Sie einen Authentifizierungssicherheitsschlüssel im Anforderungsheader verwenden. Sie können auch Anmeldeinformationen mit der Anforderung übergeben. Wenn Sie die Authentifizierung verwenden, überlegen Sie, wie der Zugriff auf die Endpunkte für die Integritätsüberprüfung erfolgen soll. Beispielsweise lässt sich Integritätsprüfung von Azure App Service in die Authentifizierungs- und Autorisierungsfeatures von App Service einbeziehen.
Verwenden Sie einen verborgenen oder ausgeblendeten Endpunkt. Machen Sie z. B. den Endpunkt an einer anderen IP-Adresse verfügbar als der, die von der standardmäßigen Anwendungs-URL verwendet wird. Konfigurieren Sie den Endpunkt an einem nicht standardmäßigen HTTP-Port. Sie können auch die Verwendung eines komplexen Pfads zu Ihrer Testseite in Erwägung ziehen. In der Regel können Sie in der Anwendungskonfiguration zusätzliche Endpunktadressen und -ports angeben. Bei Bedarf können Sie dem DNS-Server Einträge für diese Endpunkte hinzufügen. So vermeiden Sie eine direkte Angabe der IP-Adresse.
Machen Sie eine Methode auf einem Endpunkt verfügbar, die einen Parameter wie einen Schlüsselwert oder einen Wert für die Betriebsart akzeptiert. Wenn eine Anforderung eintrifft, kann der Code bestimmte Tests ausführen, die vom Wert des Parameters abhängen. Der Code kann den Fehler „404 (Nicht gefunden)“ zurückgeben, wenn der Parameterwert nicht erkannt wird. Ermöglichen Sie das Definieren von Parameterwerten in der Anwendungskonfiguration.
Verwenden Sie einen separaten Endpunkt, der grundlegende Funktionstests durchführt, ohne den Betrieb der Anwendung insgesamt zu beeinträchtigen. Mit diesem Ansatz können Sie die Auswirkungen eines DoS-Angriffs verringern. Vermeiden Sie im Idealfall Tests, die vertrauliche Informationen preisgeben. Manchmal müssen Informationen zurückgegeben werden, die für einen Angreifer nützlich sein könnten. Überlegen Sie in diesem Fall, wie Sie den Endpunkt und die Daten vor nicht autorisiertem Zugriff schützen können. Es reicht nicht aus, sich nur auf Verschleierung zu verlassen. Erwägen Sie auch die Verwendung einer HTTPS-Verbindung und die Verschlüsselung vertraulicher Daten, obwohl dies die Verarbeitungslast auf dem Server erhöht.
Entscheiden Sie, wie Sie sicherstellen, dass der Überwachungs-Agent richtig funktioniert. Eine Möglichkeit hierbei ist, einen Endpunkt verfügbar zu machen, der einen Wert aus der Anwendungskonfiguration oder einen Zufallswert zurückgibt, den Sie zum Testen des Agents verwenden können. Stellen Sie außerdem sicher, dass sich das Überwachungssystem selbst überprüft. Sie können Selbsttests oder integrierte Tests verwenden, um zu verhindern, dass das Überwachungssystem falsch positive Ergebnisse ausgibt.
Verwendung dieses Musters
Dieses Muster ist hilfreich:
- Überwachung von Websites und Webanwendungen auf Verfügbarkeit.
- Überwachung von Websites und Webanwendungen auf ordnungsgemäßen Betrieb.
- Die Überwachung von Diensten auf mittlerer Ebene oder gemeinsam genutzten Diensten, um Fehler zu erkennen und zu isolieren, kann zu Störungen bei anderen Anwendungen führen.
- Ergänzen Sie die vorhandene Instrumentierung in der Anwendung, z.B. Leistungsindikatoren und Fehlerhandler. Die Integritätsüberprüfung ist kein Ersatz für Anwendungsanforderungen im Hinblick auf Protokollierung und Überwachung. Die Instrumentierung kann nützliche Informationen für ein bestehendes Framework liefern, das Leistungsindikatoren und Fehlerprotokolle überwacht, um Fehlfunktionen oder andere Probleme zu erkennen. Die Instrumentierung kann jedoch keine Informationen liefern, wenn eine Anwendung nicht verfügbar ist.
Workloadentwurf
Ein Architekt sollte evaluieren, wie das Health Endpoint Monitoring-Pattern im Design seines Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Säulen des Azure Well-Architected Framework behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Diese Endpunkte unterstützen die Bemühungen um Zuverlässigkeitswarnungen und Dashboarding eines Workloads. Sie können auch als Signal für eine selbstreparierende Sanierung verwendet werden. - RE:07 Selbstheilung und Selbsterhaltung - RE:10 Überwachungs- und Alarmierungsstrategie |
| Operational Excellence unterstützt die Workloadqualität durch standardisierte Prozesse und Teamzusammenhalt. | Wenn Sie standardisieren, welche Zustandsendpunkte offengelegt werden sollen und wie detailliert die Ergebnisse sind, können Sie Probleme leichter einordnen. - OE:07 Überwachungssystem |
| Die Leistungseffizienz hilft Ihrer Workload, Anforderungen effizient durch Optimierungen in Skalierung, Daten und Code zu erfüllen. | Gesundheitsendpunkte verbessern die Lastausgleichslogik, indem sie den Datenverkehr nur an Knoten weiterleiten, die als gesund eingestuft sind. Mit zusätzlicher Konfiguration können Sie auch Metriken zur verfügbaren Knotenkapazität erhalten. - PE:05 Skalierung und Partitionierung |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
Sie können die Middleware und die Bibliotheken für ASP.NET-Integritätsüberprüfungen verwenden, um die Integrität von Komponenten der App-Infrastruktur zu melden. Dieses Framework ermöglicht eine konsistente Berichterstattung für Integritätsüberprüfungen. Es implementiert viele der diesem Artikel beschriebenen Methoden. Beispielsweise umfassen die ASP.NET-Integritätsüberprüfungen externe Überprüfungen wie die Datenbankkonnektivität sowie spezifische Konzepte wie Live- und Bereitschaftstests.
Auf GitHub sind verschiedene Beispielimplementierungen mit ASP.NET-Integritätsüberprüfungen verfügbar.
Überwachen von Endpunkten in von Azure gehosteten Anwendungen
Dies sind einige Optionen für die Überwachung von Endpunkten in Azure-Anwendungen:
- Verwenden Sie die integrierten Überwachungsfeatures von Azure, wie z. B. Azure Monitor.
- Verwenden Sie einen Drittanbieterdienst oder ein Framework wie beispielsweise Microsoft System Center Operations Manager.
- Erstellen Sie selbst ein benutzerdefiniertes Hilfsprogramm oder einen Dienst, das bzw. der auf Ihrem eigenen oder einem gehosteten Server ausgeführt wird.
Auch wenn Azure umfassende Überwachungsoptionen bietet, können Sie zusätzliche Dienste und Tools nutzen, um weitere Informationen bereitzustellen. Application Insights, ein Feature von Monitor, wurde für speziell Entwicklungsteams entwickelt. Dieses Feature hilft Ihnen dabei, die Leistung und Verwendung Ihrer App nachzuvollziehen. Application Insights überwacht Anforderungsraten, Antwortzeiten, Fehlerraten und Abhängigkeitsraten. Es kann Ihnen dabei helfen, herauszufinden, ob externe Dienste Sie ausbremsen.
Welche Bedingungen Sie überwachen können, hängt von dem Hostingmechanismus ab, den Sie für Ihre Anwendung auswählen. Alle Optionen in diesem Abschnitt unterstützen Warnungsregeln. Eine Warnungsregel verwendet einen Webendpunkt, den Sie in den Einstellungen für Ihren Dienst angeben. Dieser Endpunkt muss rechtzeitig reagieren, damit das Warnsystem erkennen kann, dass die Anwendung ordnungsgemäß funktioniert. Weitere Informationen finden Sie unter Erstellen einer neuen Warnungsregel.
Bei einem größeren Ausfall sollte der Clientdatenverkehr an eine Anwendungsbereitstellung weitergeleitet werden können, die in anderen Regionen oder Zonen verfügbar ist. Diese Situation ist ein gutes Beispiel für standortübergreifende Konnektivität und globalen Lastenausgleich. Die Auswahl einer sinnvollen Lösung richtet sich hierbei danach, ob die Anwendung intern oder extern ausgerichtet ist. Dienste wie Azure Front Door, Azure Traffic Manager oder Content Delivery Networks können Datenverkehr basierend auf von Integritätstests bereitgestellten Daten regionsübergreifend weiterleiten.
Traffic Manager ist ein Routing- und Lastenausgleichsdienst. Er kann eine Reihe von Regeln und Einstellungen verwenden, um Anforderungen an bestimmte Instanzen Ihrer Anwendung zu verteilen. Neben der Weiterleitung von Anforderungen kann Traffic Manager regelmäßig eine URL, einen Port und einen relativen Pfad pingen. Sie geben die Pingziele an, um zu ermitteln, welche Instanzen Ihrer Anwendung aktiv sind und auf Anforderungen reagieren. Wenn Traffic Manager den Statuscode „200 (OK)“ ermittelt, wird die Anwendung als verfügbar gekennzeichnet. Alle anderen Statuscodes bewirken, dass Traffic Manager die Anwendung als offline markiert. Die Traffic Manager-Konsole zeigt den Status der einzelnen Anwendungen an. Sie können jede Regel so konfigurieren, dass Anforderungen an andere, reagierende Instanzen der Anwendung umgeleitet werden.
Traffic Manager wartet eine bestimmte Zeit lang auf eine Antwort von der Überwachungs-URL. Stellen Sie sicher, dass Ihr Integritätsüberprüfungscode in diesem Zeitraum ausgeführt wird. Planen Sie für den Roundtrip von Traffic Manager zu Ihrer Anwendung und zurück die Netzwerklatenz ein.
Nächste Schritte
Die folgenden Artikel enthalten hilfreiche Informationen zur Implementierung dieses Musters:
- Leitfaden zur Integritätsüberwachung in auf Microservices basierenden Anwendungen
- Überwachen der Anwendungsintegrität auf Zuverlässigkeit, Teil des Azure Well-Architected Framework
- Erstellen einer neuen Warnungsregel