Schnellere Veröffentlichungszyklen sind einer der wichtigsten Vorteile von Microservices-Architekturen. Aber ohne einen guten CI/CD-Prozess erreichen Sie nicht die Flexibilität, die Microservices versprechen. In diesem Artikel werden die Herausforderungen beschrieben und einige Ansätze für das Problem empfohlen.
Was ist CI/CD?
Wenn wir über CI/CD sprechen, sprechen wir wirklich über mehrere verwandte Prozesse: kontinuierliche Integration, kontinuierliche Bereitstellung und kontinuierliche Bereitstellung.
kontinuierliche Integration. Codeänderungen werden häufig mit der Hauptzweigung zusammengeführt. Automatisierte Build- und Testprozesse stellen sicher, dass Code in der Hauptverzweigung immer produktionsqualität ist.
Kontinuierliche Lieferung. Alle Codeänderungen, die den CI-Prozess übergeben, werden automatisch in einer produktionsähnlichen Umgebung veröffentlicht. Die Bereitstellung in der Liveproduktionsumgebung erfordert möglicherweise eine manuelle Genehmigung, ist aber andernfalls automatisiert. Ziel ist, dass Ihr Code immer bereit sein sollte, in der Produktion bereitzustellen.
kontinuierliche Bereitstellung. Codeänderungen, die die vorherigen beiden Schritte bestehen, werden automatisch in der Produktionbereitgestellt.
Hier sind einige Ziele eines robusten CI/CD-Prozesses für eine Microservices-Architektur:
Jedes Team kann die Dienste, die es besitzt, unabhängig erstellen und bereitstellen, ohne andere Teams zu beeinträchtigen oder zu stören.
Bevor eine neue Version eines Diensts in der Produktion bereitgestellt wird, wird er zur Überprüfung in Entwicklungs-/Test-/QA-Umgebungen bereitgestellt. Qualitätstore werden in jeder Phase durchgesetzt.
Eine neue Version eines Diensts kann nebeneinander mit der vorherigen Version bereitgestellt werden.
Ausreichende Zugriffssteuerungsrichtlinien sind vorhanden.
Bei containerisierten Workloads können Sie den Containerimages vertrauen, die für die Produktion bereitgestellt werden.
Warum eine robuste CI/CD-Pipeline wichtig ist
In einer herkömmlichen monolithischen Anwendung gibt es eine einzige Buildpipeline, deren Ausgabe die ausführbare Anwendung ist. Alle Entwicklungsarbeiten werden in diese Pipeline eingespeist. Wenn ein Fehler mit hoher Priorität gefunden wird, muss ein Fix integriert, getestet und veröffentlicht werden, wodurch die Veröffentlichung neuer Features verzögert werden kann. Sie können diese Probleme beheben, indem Sie gut formatierte Module verwenden und Featureverzweigungen verwenden, um die Auswirkungen von Codeänderungen zu minimieren. Aber wenn die Anwendung komplexer wird und mehr Features hinzugefügt werden, wird der Releaseprozess für einen Monolithen tendenziell spröd und wahrscheinlich zerbrechen.
Nach der Microservices-Philosophie sollte es nie einen langen Release-Zug geben, in dem jedes Team in die Linie kommen muss. Das Team, das dienst "A" erstellt, kann jederzeit ein Update freigeben, ohne auf Änderungen im Dienst "B" zu warten, um zusammengeführt, getestet und bereitgestellt zu werden.
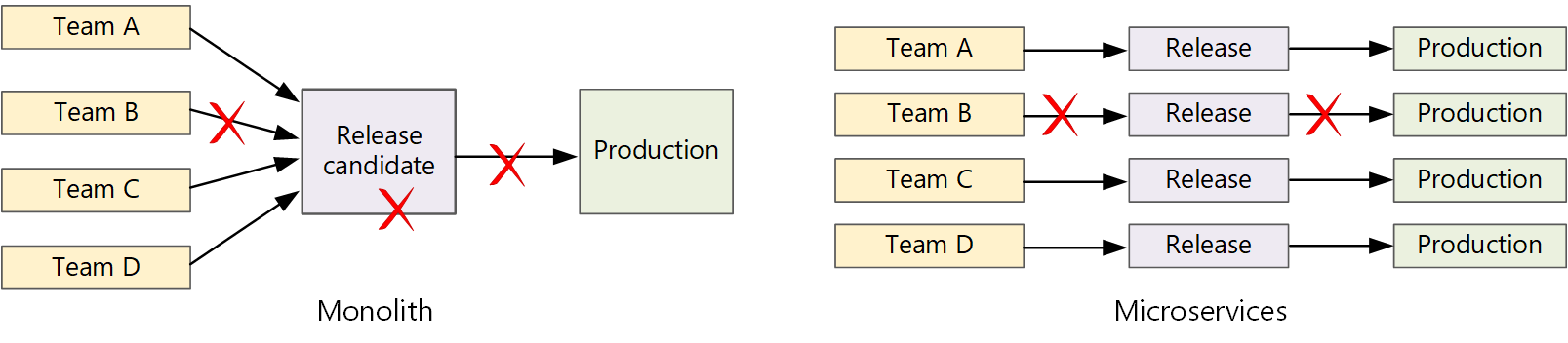
Um eine hohe Veröffentlichungsgeschwindigkeit zu erreichen, muss Ihre Veröffentlichungspipeline automatisiert und sehr zuverlässig sein, um risiken zu minimieren. Wenn Sie eine oder mehrere Male täglich in die Produktion freigeben, müssen Regressionen oder Dienstunterbrechungen selten sein. Wenn ein fehlerhaftes Update bereitgestellt wird, müssen Sie gleichzeitig eine zuverlässige Möglichkeit haben, einen schnellen Rollback oder einen Roll forward auf eine frühere Version eines Diensts zu erstellen.
Herausforderungen
Viele kleine unabhängige Codebasen. Jedes Team ist für die Erstellung eines eigenen Diensts mit eigener Buildpipeline verantwortlich. In einigen Organisationen verwenden Teams möglicherweise separate Coderepositorys. Separate Repositorys können zu einer Situation führen, in der das Wissen darüber, wie das System erstellt werden kann, auf Teams verteilt ist, und niemand in der Organisation weiß, wie die gesamte Anwendung bereitgestellt wird. Was geschieht beispielsweise in einem Notfallwiederherstellungsszenario, wenn Sie schnell in einem neuen Cluster bereitstellen müssen?
Entschärfung: Verfügen Sie über eine einheitliche und automatisierte Pipeline zum Erstellen und Bereitstellen von Diensten, sodass dieses Wissen nicht innerhalb jedes Teams "ausgeblendet" ist.
Mehrere Sprachen und Frameworks. Mit jedem Team, das eine eigene Mischung aus Technologien verwendet, kann es schwierig sein, einen einzelnen Buildprozess zu erstellen, der in der gesamten Organisation funktioniert. Der Buildprozess muss flexibel genug sein, damit jedes Team ihn für die jeweilige Sprache oder das Framework anpassen kann.
Entschärfung: Containern Sie den Buildprozess für jeden Dienst. Auf diese Weise muss das Buildsystem nur in der Lage sein, die Container auszuführen.
Integrations- und Auslastungstests. Wenn Teams Updates in ihrem eigenen Tempo veröffentlichen, kann es schwierig sein, robuste End-to-End-Tests zu entwerfen, insbesondere, wenn Dienste Abhängigkeiten von anderen Diensten haben. Darüber hinaus kann das Ausführen eines vollständigen Produktionsclusters teuer sein, sodass es unwahrscheinlich ist, dass jedes Team seinen eigenen vollständigen Cluster im Produktionsmaßstab ausführt, nur zum Testen.
Releaseverwaltung. Jedes Team sollte in der Lage sein, ein Update für die Produktion bereitzustellen. Das bedeutet nicht, dass jedes Teammitglied über Berechtigungen verfügt, um dies zu tun. Eine zentrale Release-Manager-Rolle kann jedoch die Geschwindigkeit von Bereitstellungen verringern.
Entschärfung: Je mehr ihr CI/CD-Prozess automatisiert und zuverlässig ist, desto weniger muss eine zentrale Behörde benötigt werden. Dies bedeutet, dass Sie möglicherweise unterschiedliche Richtlinien für die Veröffentlichung wichtiger Featureupdates im Vergleich zu kleineren Fehlerbehebungen haben. Dezentrales Handeln bedeutet keine Null-Governance.
Dienstupdates. Wenn Sie einen Dienst auf eine neue Version aktualisieren, sollte er andere Dienste, die davon abhängen, nicht unterbrechen.
Entschärfung: Verwenden Sie Bereitstellungstechniken wie Blaugrün oder Canary-Release für ungebrochene Änderungen. Um API-Änderungen zu unterbrechen, stellen Sie die neue Version nebeneinander mit der vorherigen Version bereit. Auf diese Weise können Dienste, die die vorherige API nutzen, für die neue API aktualisiert und getestet werden. Weitere Informationen finden Sie unter Aktualisieren von Dienstenunten.
Monorepo vs. Multi-Repository
Bevor Sie einen CI/CD-Workflow erstellen, müssen Sie wissen, wie die Codebasis strukturiert und verwaltet wird.
- Arbeiten Teams in separaten Repositorys oder in einem Monorepo (einzelnes Repository)?
- Was ist Ihre Verzweigungsstrategie?
- Wer kann Code in die Produktion übertragen? Gibt es eine Release-Manager-Rolle?
Der Monorepo-Ansatz hat sich favorisiert, aber es gibt Vor- und Nachteile für beide.
| Monorepo | Mehrere Repositorys | |
|---|---|---|
| Vorteile | Codefreigabe Einfacheres Standardisieren von Code und Tools Einfacher umgestalten von Code Auffindbarkeit – einzelne Ansicht des Codes |
Besitz pro Team löschen Potenziell weniger Zusammenführungskonflikte Hilft beim Erzwingen der Entkoppelung von Microservices |
| Herausforderungen | Änderungen an freigegebenem Code können sich auf mehrere Microservices auswirken Größeres Potenzial für Zusammenführungskonflikte Tools müssen auf eine große Codebasis skaliert werden. Zugriffskontrolle Komplexerer Bereitstellungsprozess |
Schwierigere Freigabe von Code Schwieriger zu erzwingen von Codierungsstandards Abhängigkeitsverwaltung Diffuse Codebasis, schlechte Auffindbarkeit Fehlende gemeinsame Infrastruktur |
Aktualisieren von Diensten
Es gibt verschiedene Strategien zum Aktualisieren eines Diensts, der bereits in der Produktion ausgeführt wird. Hier besprechen wir drei allgemeine Optionen: Rollupdate, blaugrüne Bereitstellung und Canary-Version.
Rollupdates
In einem rollierenden Update stellen Sie neue Instanzen eines Diensts bereit, und die neuen Instanzen empfangen sofort Anforderungen. Sobald die neuen Instanzen vorliegen, werden die vorherigen Instanzen entfernt.
Beispiel. In Kubernetes sind rollierende Updates das Standardverhalten, wenn Sie die Pod-Spezifikation für eine Deploymentaktualisieren. Der Bereitstellungscontroller erstellt ein neues ReplicaSet für die aktualisierten Pods. Anschließend wird das neue ReplicaSet skaliert, während die alte skaliert wird, um die gewünschte Replikatanzahl beizubehalten. Alte Pods werden erst gelöscht, wenn die neuen bereit sind. Kubernetes behält einen Verlauf des Updates bei, sodass Sie bei Bedarf ein Rollback für ein Update ausführen können.
Beispiel. Azure Service Fabric verwendet standardmäßig die rollierende Updatestrategie. Diese Strategie eignet sich am besten für die Bereitstellung einer Version eines Diensts mit neuen Features, ohne vorhandene APIs zu ändern. Service Fabric startet eine Upgradebereitstellung, indem der Anwendungstyp auf eine Teilmenge der Knoten oder eine Updatedomäne aktualisiert wird. Anschließend wird eine Rollweiterleitung zur nächsten Updatedomäne ausgeführt, bis alle Domänen aktualisiert werden. Wenn eine Upgradedomäne nicht aktualisiert werden kann, führt der Anwendungstyp einen Rollback auf die vorherige Version in allen Domänen durch. Beachten Sie, dass ein Anwendungstyp mit mehreren Diensten (und wenn alle Dienste als Teil einer Upgradebereitstellung aktualisiert werden) fehleranfällig ist. Wenn ein Dienst nicht aktualisiert werden kann, wird die gesamte Anwendung auf die vorherige Version zurückgesetzt, und die anderen Dienste werden nicht aktualisiert.
Eine Herausforderung beim Rollout von Updates besteht darin, dass während des Updateprozesses eine Mischung aus alten und neuen Versionen ausgeführt und Datenverkehr empfangen wird. Während dieses Zeitraums konnte jede Anforderung an eine der beiden Versionen weitergeleitet werden.
Zum Unterbrechen von API-Änderungen empfiehlt es sich, beide Versionen nebeneinander zu unterstützen, bis alle Clients der vorherigen Version aktualisiert werden. Siehe API-Versionsverwaltung.
Blaugrüne Bereitstellung
In einer blaugrünen Bereitstellung stellen Sie die neue Version zusammen mit der vorherigen Version bereit. Nachdem Sie die neue Version überprüft haben, wechseln Sie den gesamten Datenverkehr auf einmal von der vorherigen Version zur neuen Version. Nach dem Schalter überwachen Sie die Anwendung auf probleme. Wenn ein Fehler auftritt, können Sie wieder in die alte Version wechseln. Wenn es keine Probleme gibt, können Sie die alte Version löschen.
Mit einer herkömmlicheren monolithischen oder N-stufigen Anwendung bedeutete die blaugrüne Bereitstellung im Allgemeinen die Bereitstellung von zwei identischen Umgebungen. Sie würden die neue Version in einer Stagingumgebung bereitstellen und dann den Clientdatenverkehr an die Stagingumgebung umleiten, z. B. durch Austauschen von VIP-Adressen. In einer Microservices-Architektur erfolgen Updates auf Microservice-Ebene, sodass Sie das Update in der Regel in derselben Umgebung bereitstellen und einen Dienstermittlungsmechanismus zum Austauschen verwenden würden.
Beispiel. In Kubernetes müssen Sie keinen separaten Cluster bereitstellen, um blaugrüne Bereitstellungen durchzuführen. Stattdessen können Sie selektoren nutzen. Erstellen Sie eine neue Deployment-Ressource mit einer neuen Podspezifikation und einer anderen Gruppe von Bezeichnungen. Erstellen Sie diese Bereitstellung, ohne die vorherige Bereitstellung zu löschen oder den Dienst zu ändern, der darauf verweist. Sobald die neuen Pods ausgeführt werden, können Sie die Auswahl des Diensts so aktualisieren, dass sie mit der neuen Bereitstellung übereinstimmt.
Ein Nachteil der blaugrünen Bereitstellung ist, dass Sie während des Updates doppelt so viele Pods für den Dienst (aktuell und weiter) ausführen. Wenn die Pods viele CPU- oder Arbeitsspeicherressourcen benötigen, müssen Sie den Cluster möglicherweise vorübergehend skalieren, um den Ressourcenverbrauch zu bewältigen.
Canary-Version
In einer Canary-Version wird eine aktualisierte Version für eine kleine Anzahl von Clients eingeführt. Anschließend überwachen Sie das Verhalten des neuen Diensts, bevor Sie ihn für alle Clients bereitstellen. Auf diese Weise können Sie ein langsames Rollout auf kontrollierte Weise durchführen, echte Daten beobachten und Probleme erkennen, bevor alle Kunden betroffen sind.
Eine Canary-Version ist komplexer zu verwalten als blaugrün oder rollierendes Update, da Sie Anforderungen dynamisch an verschiedene Versionen des Diensts weiterleiten müssen.
Beispiel. In Kubernetes können Sie einen Service- so konfigurieren, dass es zwei Replikatgruppen (eine für jede Version) umfasst und die Replikatanzahl manuell anpasst. Dieser Ansatz ist jedoch eher grob gekörnt, da Kubernetes lastenausgleichsübergreifend über Pods hinweg erfolgt. Wenn Sie beispielsweise über insgesamt 10 Replikate verfügen, können Sie den Datenverkehr nur in 10% Schritten verschieben. Wenn Sie ein Dienstgitter verwenden, können Sie die Dienstgitterroutingregeln verwenden, um eine komplexere Canary-Releasestrategie zu implementieren.
Nächste Schritte
- Lernpfad: Definieren und Implementieren der kontinuierlichen Integration
- Schulung: Einführung in die kontinuierliche Lieferung
- Microservices-Architektur
- Warum verwenden Sie einen Microservices-Ansatz zum Erstellen von Anwendungen