Grundlegendes zu Datenspeichermodellen
Moderne Geschäftssysteme verwalten immer größere Mengen heterogener Daten. Diese Heterogenität bedeutet, dass ein einzelner Datenspeicher in der Regel nicht der beste Ansatz ist. Stattdessen ist es häufig besser, unterschiedliche Datentypen in verschiedenen Datenspeichern zu speichern, die jeweils auf eine bestimmte Workload oder ein bestimmtes Verwendungsmuster ausgerichtet sind. Der Begriff Polyglot Persistence (automatisierte Verwendung verschiedener Datenbanksysteme) wird verwendet, um Lösungen zu beschreiben, die eine Mischung aus Datenspeichertechnologien nutzen. Daher ist es wichtig, die wichtigsten Speichermodelle und ihre Kompromisse zu verstehen.
Die Auswahl des richtigen Datenspeichers für Ihre Anforderungen ist eine wichtige Entwurfsentscheidung. Es gibt buchstäblich Hunderte von Implementierungen, aus denen Sie zwischen SQL- und NoSQL-Datenbanken wählen können. Datenspeicher werden häufig nach der Struktur von Daten und den unterstützten Arten von Vorgängen kategorisiert. In diesem Artikel werden einige der am häufigsten verwendeten Speichermodelle beschrieben. Beachten Sie, dass eine bestimmte Datenspeichertechnologie mehrere Speichermodelle unterstützen kann. Beispielsweise kann ein relationales Datenbankverwaltungssystem (RDBMS) auch Schlüssel-/Wert- oder Graphspeicher unterstützen. Tatsächlich gibt es einen allgemeinen Trend zur sogenannten Multimodell-Unterstützung, bei der ein einziges Datenbanksystem mehrere Modelle unterstützt. Aber es ist immer noch nützlich, die verschiedenen Modelle auf hoher Ebene zu verstehen.
Nicht alle Datenspeicher in einer bestimmten Kategorie bieten denselben Featuresatz. Die meisten Datenspeicher bieten serverseitige Funktionen zum Abfragen und Verarbeiten von Daten. Manchmal ist diese Funktionalität in das Datenspeichermodul integriert. In anderen Fällen sind die Datenspeicherungs- und Verarbeitungsfunktionen getrennt, und es gibt möglicherweise mehrere Optionen für die Verarbeitung und Analyse. Datenspeicher unterstützen auch verschiedene programmgesteuerte und Verwaltungsschnittstellen.
Im Allgemeinen sollten Sie überlegen, welches Speichermodell für Ihre Anforderungen am besten geeignet ist. Betrachten Sie dann einen bestimmten Datenspeicher innerhalb dieser Kategorie, aufgrund von Faktoren wie Funktionsumfang, Kosten und Benutzerfreundlichkeit.
Anmerkung
Erfahren Sie mehr darüber, wie Sie Ihre Anforderungen an Datendienste für die Cloudeinführung identifizieren und überprüfen können, im Microsoft Cloud Adoption Framework für Azure. Ebenso können Sie sich auch über die Auswahl von Speichertools und -diensten informieren.
Relationale Datenbankverwaltungssysteme
Relationale Datenbanken organisieren Daten als eine Reihe von zweidimensionalen Tabellen mit Zeilen und Spalten. Die meisten Anbieter bieten einen Dialekt der Structured Query Language (SQL) zum Abrufen und Verwalten von Daten. Ein RDBMS implementiert in der Regel einen transaktionskonsistenten Mechanismus, der dem ACID-Modell (Atomar, Konsistent, Isoliert, Dauerhaft) zum Aktualisieren von Informationen entspricht.
Ein RDBMS unterstützt in der Regel ein Schema-on-Write-Modell, bei dem die Datenstruktur vorab definiert ist, und alle Lese- oder Schreibvorgänge müssen das Schema verwenden.
Dieses Modell ist sehr nützlich, wenn starke Konsistenzgarantien wichtig sind – wenn alle Änderungen atomisch sind und Transaktionen die Daten immer in einem konsistenten Zustand belassen. Ein RDBMS kann jedoch im Allgemeinen nicht horizontal skaliert werden, ohne die Daten auf irgendeine Weise zu shardieren. Außerdem müssen die Daten in einem RDBMS normalisiert werden, was nicht für jede Datenmenge geeignet ist.
Azure-Dienste
- Azure SQL-Datenbank | (Sicherheitsbaseline)
- Azure-Datenbank für MySQL | (Security Baseline)
- Azure-Datenbank für PostgreSQL | (Sicherheitsgrundlinie)
- Azure Database for MariaDB | (Sicherheitsbaseline)
Arbeitsbelastung
- Datensätze werden häufig erstellt und aktualisiert.
- Mehrere Vorgänge müssen in einer einzigen Transaktion abgeschlossen werden.
- Beziehungen werden mithilfe von Datenbankbeschränkungen durchgesetzt.
- Indizes werden verwendet, um die Abfrageleistung zu optimieren.
Datentyp
- Daten werden stark normalisiert.
- Datenbankschemas sind erforderlich und werden erzwungen.
- Viele-zu-viele-Beziehungen zwischen Datenentitäten in der Datenbank.
- Einschränkungen werden im Schema definiert und für alle Daten in der Datenbank auferlegt.
- Daten erfordern eine hohe Integrität. Indizes und Beziehungen müssen sorgfältig gepflegt werden.
- Daten erfordern eine starke Konsistenz. Transaktionen werden so durchgeführt, dass sichergestellt wird, dass alle Daten für alle Benutzer und Prozesse 100 % konsistent sind.
- Die Größe einzelner Dateneinträge ist klein bis mittelgroß.
Beispiele
- Bestandsverwaltung
- Auftragsverwaltung
- Reporting-Datenbank
- Buchführung
Schlüssel-Wert-Speicher
Ein Schlüssel-/Wertspeicher ordnet jeden Datenwert einem eindeutigen Schlüssel zu. Die meisten Schlüssel-/Wertspeicher unterstützen nur einfache Abfrage-, Einfüge- und Löschvorgänge. Zum Ändern eines Werts (teilweise oder vollständig) muss eine Anwendung die vorhandenen Daten für den gesamten Wert überschreiben. In den meisten Implementierungen ist das Lesen oder Schreiben eines einzelnen Werts ein atomer Vorgang.
Eine Anwendung kann beliebige Daten als Wertesatz speichern. Alle Schemainformationen müssen von der Anwendung bereitgestellt werden. Der Schlüssel-Wert-Speicher ruft den Wert einfach ab oder speichert ihn mithilfe des Schlüssels.
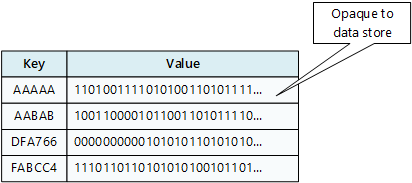
Schlüssel-/Wertspeicher sind stark optimiert für Anwendungen, die einfache Abfragen durchführen, eignen sich jedoch weniger, wenn Sie Daten in verschiedenen Schlüssel-/Wertspeichern abfragen müssen. Schlüssel-/Wertspeicher sind auch nicht für die Abfrage nach Wert optimiert.
Ein einzelner Schlüssel-/Wertspeicher kann extrem skalierbar sein, da der Datenspeicher Daten problemlos über mehrere Knoten auf separaten Computern verteilen kann.
Azure-Dienste
- Azure Cosmos DB for Table und Azure Cosmos DB for NoSQL | (Sicherheitsbaseline für Azure Cosmos DB)
- Azure-Cache für Redis | (Sicherheitsgrundlinie)
- Azure Table Storage | (Sicherheitsbaseline)
Arbeitsbelastung
- Auf Daten wird mithilfe eines einzelnen Schlüssels zugegriffen, z. B. mit einem Wörterbuch.
- Keine Verknüpfungen, Sperren oder Unions sind erforderlich.
- Es werden keine Aggregationsmechanismen verwendet.
- Sekundäre Indizes werden in der Regel nicht verwendet.
Datentyp
- Jeder Schlüssel ist einem einzelnen Wert zugeordnet.
- Keine Schemas werden erzwungen.
- Keine Beziehungen zwischen Entitäten.
Beispiele
- Zwischenspeichern von Daten
- Sitzungsverwaltung
- Benutzereinstellungs- und Benutzerprofilverwaltung
- Produktempfehlungen und Ad-Serving
Dokumentdatenbanken
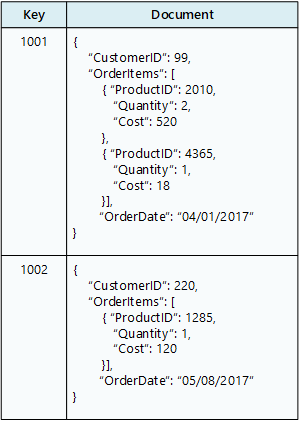
Eine Dokumentdatenbank speichert eine Sammlung von Dokumenten, wobei jedes Dokument aus benannten Feldern und Daten besteht. Bei den Daten kann es sich um einfache Werte oder komplexe Elemente wie Listen oder untergeordnete Sammlungen handeln. Dokumente werden mit eindeutigen Schlüsseln abgerufen.
In der Regel enthält ein Dokument die Daten für eine einzelne Entität, z. B. einen Kunden oder eine Bestellung. Ein Dokument kann Informationen enthalten, die über mehrere relationale Tabellen in einem RDBMS verteilt werden. Dokumente müssen nicht über dieselbe Struktur verfügen. Anwendungen können unterschiedliche Daten in Dokumenten speichern, da sich die Geschäftsanforderungen ändern.
Azure-Dienst
Arbeitsbelastung
- Einfüge- und Aktualisierungsvorgänge sind häufig.
- Keine objektrelationalen Impedanzabweichungen. Dokumente können besser mit den Objektstrukturen übereinstimmen, die im Anwendungscode verwendet werden.
- Einzelne Dokumente werden als einzelner Block abgerufen und geschrieben.
- Daten benötigen einen Index für mehrere Felder.
Datentyp
- Daten können auf nicht normalisierte Weise verwaltet werden.
- Die Größe einzelner Dokumentdaten ist relativ klein.
- Jeder Dokumenttyp kann ein eigenes Schema verwenden.
- Dokumente können optionale Felder enthalten.
- Dokumentdaten sind semistrukturiert, was bedeutet, dass Datentypen jedes Felds nicht streng definiert sind.
Beispiele
- Produktkatalog
- Inhaltsverwaltung
- Bestandsverwaltung
Graph-Datenbanken
In einer Diagrammdatenbank werden zwei Arten von Informationen, Knoten und Kanten gespeichert. Kanten geben Beziehungen zwischen Knoten an. Knoten und Kanten können Eigenschaften aufweisen, die Informationen zu diesem Knoten oder Rand bereitstellen, ähnlich wie Spalten in einer Tabelle. Ränder können auch eine Richtung aufweisen, die die Art der Beziehung angibt.
Graph-Datenbanken können Abfragen effizient über das Netzwerk von Knoten und Kanten hinweg ausführen und die Beziehungen zwischen Entitäten analysieren. Das folgende Diagramm zeigt die Personaldatenbank einer Organisation, die als Diagramm strukturiert ist. Die Entitäten sind Mitarbeiter und Abteilungen, und die Ränder geben Berichtsbeziehungen und die Abteilungen an, in denen Mitarbeiter arbeiten.

Diese Struktur erleichtert das Ausführen von Abfragen wie "Alle Mitarbeiter suchen, die direkt oder indirekt an Sarah berichten" oder "Wer arbeitet in derselben Abteilung wie John?" Bei großen Diagrammen mit vielen Entitäten und Beziehungen können Sie sehr komplexe Analysen sehr schnell durchführen. Viele Diagrammdatenbanken stellen eine Abfragesprache bereit, mit der Sie ein Netzwerk von Beziehungen effizient durchlaufen können.
Azure-Dienste
Arbeitsbelastung
- Komplexe Beziehungen zwischen Datenobjekten, die viele Zwischenschritte zwischen verwandten Datenobjekten erfordern.
- Die Beziehung zwischen Datenelementen ist dynamisch und ändert sich im Laufe der Zeit.
- Beziehungen zwischen Objekten sind bevorzugte Beziehungen, bei denen keine Fremdschlüssel und Verknüpfungen durchlaufen werden müssen.
Datentyp
- Knoten und Verbindungen.
- Knoten ähneln Tabellenzeilen oder JSON-Dokumenten.
- Beziehungen sind genauso wichtig wie Knoten und werden direkt in der Abfragesprache verfügbar gemacht.
- Zusammengesetzte Objekte, z.B. eine Person mit mehreren Telefonnummern, werden meist in separate kleinere Knoten unterteilt und mit durchlaufbaren Beziehungen kombiniert.
Beispiele
- Organigramme
- Soziale Graphen
- Betrugserkennung
- Empfehlungs-Engines
Datenanalyse
Datenanalysespeicher bieten massiv parallele Lösungen für die Erfassung, Speicherung und Analyse von Daten. Die Daten werden auf mehrere Server verteilt, um die Skalierbarkeit zu maximieren. Bei der Datenanalyse werden sehr oft Formate für große Datendateien wie z. B. Dateien mit Trennzeichen (CSV), Parquet- und ORC-Dateien verwendet. Historische Daten werden typischerweise in Datenspeichern wie Blob Storage oder Azure Data Lake Storage Gen2gespeichert, auf die dann von Azure Synapse, Databricks oder HDInsight als externe Tabellen zugegriffen wird. Ein typisches Szenario, bei dem Daten verwendet werden, die aus Leistungsgründen als Parquet-Dateien gespeichert werden, ist im Artikel Verwenden externer Tabellen mit Synapse SQL beschrieben.
Azure-Dienste
- Azure Synapse Analytics | (Sicherheitsbaseline)
- Azure Data Lake | (Sicherheitsbaseline)
- Azure Data Explorer | (Sicherheitsbasislinie)
- Azure Analysis Services
- HDInsight | (Sicherheitsbaseline)
- Azure Databricks | (Sicherheitsbaseline
Arbeitsbelastung
- Datenanalyse
- Enterprise BI
Datentyp
- Historische Daten aus mehreren Quellen.
- In der Regel denormalisiert in einem „Stern“- oder „Schneeflocken“-Schema, das aus Fakten- und Dimensionstabellen besteht.
- Wird normalerweise mit neuen Daten auf Basis eines Zeitplans geladen.
- Dimensionstabellen enthalten häufig mehrere Verlaufsversionen einer Entität, die als langsam veränderliche Dimension bezeichnet wird.
Beispiele
- Unternehmensdatenbank
Spaltenfamilien-Datenbanken
In einer Spaltenfamilien-Datenbank sind Daten in Zeilen und Spalten organisiert. In ihrer einfachsten Form kann eine Spaltenfamiliendatenbank zumindest konzeptionell einer relationalen Datenbank sehr ähnlich erscheinen. Die eigentliche Macht einer Spaltenfamiliendatenbank liegt in ihrem denormalisierten Ansatz zur Strukturierung von sparsamen Daten.
Sie können sich eine Spaltenfamiliendatenbank als eine Datenbank vorstellen, die tabellarische Daten in Zeilen und Spalten hält, wobei die Spalten in Gruppen unterteilt sind, die als Spaltenfamilienbezeichnet werden. Jede Spaltenfamilie enthält eine Reihe von Spalten, die logisch miteinander verknüpft sind und in der Regel als Einheit abgerufen oder bearbeitet werden. Andere Daten, auf die separat zugegriffen wird, können in separaten Spaltenfamilien gespeichert werden. Innerhalb einer Spaltenfamilie können neue Spalten dynamisch hinzugefügt werden, und Zeilen können sparsam sein (d. h. eine Zeile muss für jede Spalte keinen Wert haben).
Das folgende Diagramm zeigt ein Beispiel mit zwei Spaltenfamilien, Identity und Contact Info. Die Daten für eine einzelne Entität haben denselben Zeilenschlüssel in jeder Spaltenfamilie. Diese Struktur, bei der die Zeilen für jedes angegebene Objekt in einer Spaltenfamilie dynamisch variieren können, ist ein wichtiger Vorteil des Konzepts der Spaltenfamilie, wodurch diese Form des Datenspeichers für strukturierte, veränderliche Daten sehr geeignet ist.

Im Gegensatz zu einem Schlüssel-/Wertspeicher oder einer Dokumentdatenbank speichern die meisten Spaltenfamiliendatenbanken Daten in der Schlüsselreihenfolge, anstatt einen Hash zu berechnen. Mit vielen Implementierungen können Sie Indizes über bestimmte Spalten in einer Spaltenfamilie erstellen. Mit Indizes können Sie Daten nach Spaltenwert und nicht nach Zeilenschlüssel abrufen.
Lese- und Schreibvorgänge für eine Zeile sind in der Regel mit einer einzigen Spaltenfamilien atomisch, obwohl einige Implementierungen Atomarität über die gesamte Zeile bieten und mehrere Spaltenfamilien umfassen.
Azure-Dienste
- Azure Cosmos DB für Apache Cassandra | (Sicherheitsbasislinie)
- HBase in HDInsight | (Sicherheitsbaseline)
Arbeitsbelastung
- Die meisten Spaltenfamiliendatenbanken führen Schreibvorgänge extrem schnell aus.
- Aktualisierungs- und Löschvorgänge sind selten.
- Entwickelt, um hohen Durchsatz und Zugriff mit niedriger Latenz bereitzustellen.
- Unterstützt einfachen Abfragezugriff auf eine bestimmte Gruppe von Feldern innerhalb eines viel größeren Datensatzes.
- Massiv skalierbar.
Datentyp
- Daten werden in Tabellen gespeichert, die aus einer Schlüsselspalte und einer oder mehreren Spaltenfamilien bestehen.
- Bestimmte Spalten können nach einzelnen Zeilen variieren.
- Der Zugriff auf einzelne Zellen erfolgt über get- und put-Befehle.
- Mehrere Zeilen werden mithilfe eines Scanbefehls zurückgegeben.
Beispiele
- Empfehlungen
- Personalisierung
- Sensordaten
- Telemetrie
- Messaging
- Soziale Medien Analysen
- Webanalyse
- Aktivitätsüberwachung
- Wetter- und andere Zeitreihendaten
Suchmaschinendatenbanken
Mit einer Suchmaschinendatenbank können Anwendungen nach Informationen suchen, die in externen Datenspeichern gespeichert sind. Eine Suchmaschinendatenbank kann massive Datenmengen indizieren und nahezu echtzeitbasierten Zugriff auf diese Indizes bieten.
Indizes können mehrdimensional sein und Freitextsuchen über große Textmengen hinweg unterstützen. Die Indizierung kann mithilfe eines Pullmodells erfolgen, das von der Suchmaschinen-Datenbank ausgelöst wird, oder mithilfe eines Pushmodells, das von externem Anwendungscode initiiert wird.
Suchen können genau oder unscharf sein. Eine Fuzzysuche findet Dokumente, die einem Satz von Begriffen entsprechen, und berechnet, wie genau sie übereinstimmen. Einige Suchmaschinen unterstützen auch linguistische Analysen, die Treffer auf der Basis von Synonymen, Gattungserweiterungen (z.B. Abgleich von dogs mit pets) und Wortstammerkennung (Abgleich von Wörtern mit demselben Wortstamm) liefern können.
Azure-Dienst
Arbeitsbelastung
- Datenindizes aus mehreren Quellen und Diensten.
- Abfragen sind ad-hoc und können komplex sein.
- Die Volltextsuche ist erforderlich.
- Ad-hoc-Self-Service-Abfragen sind erforderlich.
Datentyp
- Halbstrukturierter oder unstrukturierter Text
- Text mit Bezug auf strukturierte Daten
Beispiele
- Produktkataloge
- Websitesuche
- Logging
Zeitreihendatenbanken
Zeitreihendaten sind eine Gruppe von Werten, die nach Zeit organisiert sind. Zeitreihendatenbanken sammeln in der Regel große Datenmengen in Echtzeit aus einer großen Anzahl von Quellen. Aktualisierungen sind selten, und Löschvorgänge werden häufig als Massenvorgänge ausgeführt. Obwohl die in eine Zeitreihendatenbank geschriebenen Datensätze im Allgemeinen klein sind, gibt es häufig eine große Anzahl von Datensätzen, und die Gesamtdatengröße kann schnell wachsen.
Azure-Dienst
Arbeitsbelastung
- Datensätze werden in der Regel sequenziell in der Zeitreihenfolge angefügt.
- Der überwiegende Anteil der Vorgänge sind Schreibvorgänge (95 bis 99%).
- Updates sind selten.
- Löschvorgänge erfolgen in Massen und werden an zusammenhängenden Blöcken oder Datensätzen vorgenommen.
- Daten werden sequenziell in aufsteigender oder absteigender Zeitreihenfolge gelesen, häufig parallel.
Datentyp
- Ein Zeitstempel wird als Primärschlüssel und Sortiermechanismus verwendet.
- Tags können zusätzliche Informationen zu Typ, Ursprung und anderen Informationen zum Eintrag definieren.
Beispiele
- Überwachung und Ereignistelemetrie.
- Sensor- oder andere IoT-Daten.
Objektspeicher
Der Objektspeicher ist für das Speichern und Abrufen großer binärer Objekte (Bilder, Dateien, Video- und Audiodatenströme, große Anwendungsdatenobjekte und Dokumente, Datenträgerimages virtueller Computer) optimiert. In diesem Modell werden außerdem vielfach große Datendateien verwendet, z. B. Dateien mit Trennzeichen (CSV), Parquet- und ORC-Dateien. Objektspeicher können extrem große Mengen unstrukturierter Daten verwalten.
Azure-Dienst
Arbeitsbelastung
- Identifizierung erfolgt nach Schlüssel.
- Inhalt ist in der Regel ein Objekt, z. B. ein Trennzeichen, ein Bild oder eine Videodatei.
- Der Inhalt muss dauerhaft und außerhalb jeder Anwendungsebene sein.
Datentyp
- Die Datengröße ist groß.
- Wert ist nicht transparent.
Beispiele
- Bilder, Videos, Office-Dokumente, PDF-Dateien
- Statisches HTML, JSON, CSS
- Protokoll- und Prüfungsdateien
- Datenbanksicherungen
Freigegebene Dateien
Manchmal kann die Verwendung einfacher Flatfiles das effektivste Mittel zum Speichern und Abrufen von Informationen sein. Der Einsatz von Dateifreigaben ermöglicht den Zugriff auf Dateien über ein Netzwerk. Angesichts geeigneter Sicherheits- und gleichzeitiger Zugriffssteuerungsmechanismen kann das Freigeben von Daten auf diese Weise verteilte Dienste ermöglichen, hoch skalierbaren Datenzugriff für grundlegende Vorgänge auf niedriger Ebene wie einfache Lese- und Schreibanforderungen bereitzustellen.
Azure-Dienst
Arbeitsbelastung
- Migration von vorhandenen Apps, die mit dem Dateisystem interagieren.
- Erfordert eine SMB-Schnittstelle.
Datentyp
- Dateien in einer hierarchischen Gruppe von Ordnern.
- Zugänglich über E/A-Standardbibliotheken.
Beispiele
- Legacydateien
- Freigegebener Inhalt zugänglich innerhalb verschiedener virtueller Computer oder App-Instanzen
Bei diesem Verständnis verschiedener Datenspeichermodelle besteht der nächste Schritt darin, Ihre Arbeitsauslastung und Anwendung auszuwerten und zu entscheiden, welcher Datenspeicher Ihren spezifischen Anforderungen entspricht. Verwenden Sie den Datenspeicher-Entscheidungsbaum, um diesen Prozess zu erleichtern.
Nächste Schritte
- Azure Cloud Storage Solutions and Services
- Überprüfen der Speicheroptionen
- Einführung in Azure Storage
- Einführung in Azure Data Explorer