Architekturansätze für KI und ML in mehrinstanzenfähigen Lösungen
Eine ständig wachsende Zahl von mehrinstanzenfähigen Lösungen basiert auf künstlicher Intelligenz (KI) und maschinellem Lernen (ML). Eine mehrinstanzenfähige KI-/ML-Lösung stellt ähnliche ML-basierte Funktionen für eine beliebige Anzahl von Mandanten bereit. Mandanten können die Daten eines anderen Mandanten in der Regel weder anzeigen noch teilen. In einigen Situationen verwenden Mandanten jedoch möglicherweise die gleichen Modelle wie andere Mandanten.
Bei mehrinstanzenfähigen KI-/ML-Architekturen müssen die Anforderungen an Daten und Modelle sowie die Computeressourcen bedacht werden, die zum Trainieren von Modellen und Ausführen von Rückschlüssen anhand von Modellen erforderlich sind. Sie müssen berücksichtigen, wie mehrinstanzenfähige KI-/ML-Modelle bereitgestellt, verteilt und orchestriert werden, und sicherstellen, dass Ihre Lösung genau, zuverlässig und skalierbar ist.
Technologien für generative KI, die sowohl von großen als auch kleinen Sprachmodellen unterstützt werden, werden immer beliebter. Daher ist es entscheidend, effektive betriebliche Verfahren und Strategien für die Verwaltung dieser Modelle in Produktionsumgebungen über die Einführung von Machine Learning Operations (MLOps) und GenAIOps (manchmal als LLMOps bezeichnet) zu etablieren.
Wesentliche Aspekte und Anforderungen
Wenn Sie mit KI und ML arbeiten, ist es wichtig, Ihre Anforderungen in Bezug auf Training und Rückschlüsse separat zu prüfen. Der Zweck des Trainings besteht darin, ein Vorhersagemodell zu erstellen, das auf einem Dataset basiert. Rückschlüsse führen Sie aus, wenn Sie das Modell verwenden, um Vorhersagen für Ihre Anwendung zu treffen. Für jeden dieser Prozesse gelten unterschiedliche Anforderungen. Bei einer mehrinstanzenfähigen Lösung müssen Sie berücksichtigen, wie sich Ihr Mandantenmodell auf die einzelnen Prozesse auswirkt. Indem Sie jede dieser Anforderungen prüfen, können Sie sicherstellen, dass Ihre Lösung genaue Ergebnisse liefert, unter Last die gewünschte Leistung bietet, kostengünstig ist und zur Unterstützung Ihres zukünftigen Wachstums skaliert werden kann.
Mandantenisolation
Stellen Sie sicher, dass Mandanten keinen nicht autorisierten oder unerwünschten Zugriff auf die Daten oder Modelle anderer Mandanten erhalten. Behandeln Sie Modelle ähnlich vertraulich wie die Rohdaten, mit denen sie trainiert wurden. Stellen Sie sicher, dass Ihre Mandanten verstehen, wie ihre Daten zum Trainieren von Modellen verwendet werden und wie mit den Daten anderer Mandanten trainierte Modelle zu Rückschlusszwecken für ihre Workloads verwendet werden können.
In mehrinstanzenfähigen Lösungen gibt es drei gängige Ansätze für die Arbeit mit ML-Modellen: mandantenspezifische Modelle, freigegebene Modelle und optimierte freigegebene Modelle.
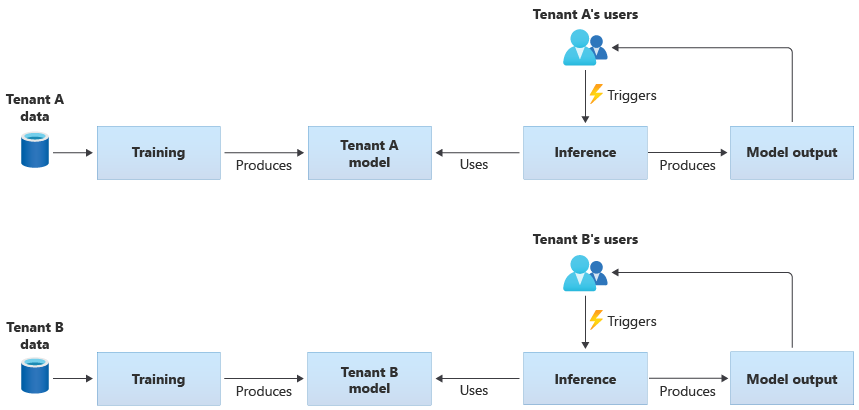
Mandantenspezifische Modelle
Mandantenspezifische Modelle werden nur mit den Daten für einen einzelnen Mandanten trainiert und anschließend auf diesen einen Mandanten angewendet. Mandantenspezifische Modelle eignen sich, wenn die Daten Ihrer Mandanten vertraulich sind oder wenn aus den von einem Mandanten bereitgestellten Daten wenig gelernt werden kann und Sie das Modell auf einen anderen Mandanten anwenden. Das folgende Diagramm zeigt, wie eine Lösung mit mandantenspezifischen Modellen für zwei Mandanten erstellt werden kann:
Modelle mit gemeinsamer Nutzung
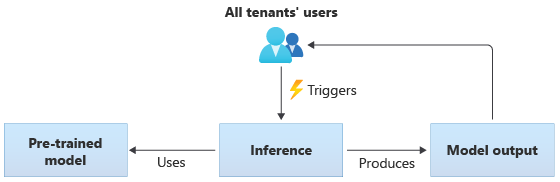
Bei Lösungen, die Modelle mit gemeinsamer Nutzung bzw. freigegebene Modelle verwenden, führen alle Mandanten Rückschlüsse basierend auf demselben freigegebenen Modell aus. Bei freigegebenen Modellen kann es sich um vortrainierte Modelle aus einer Communityquelle handeln. Das folgende Diagramm zeigt, wie ein einzelnes vortrainiertes Modell von allen Mandanten für Rückschlüsse verwendet werden kann:
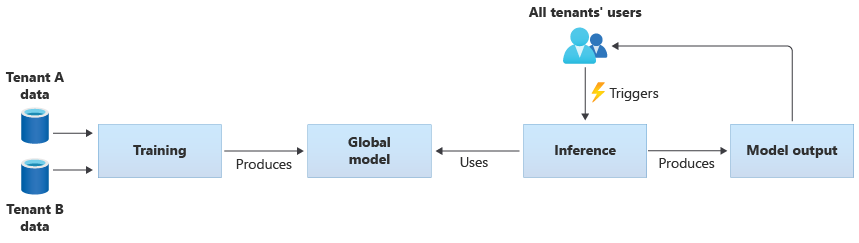
Sie können auch eigene freigegebene Modelle erstellen, die Sie mit den bereitgestellten Daten von allen Mandanten trainieren. Das folgende Diagramm zeigt ein einzelnes freigegebenes Modell, das mit Daten von allen Mandanten trainiert wird:
Wichtig
Wenn Sie ein freigegebenes Modell mit Daten Ihrer Mandanten trainieren, müssen diese verstehen, wie ihre Daten verwendet werden, und dieser Nutzung zustimmen. Stellen Sie sicher, dass personenbezogene oder identifizierende Informationen aus den Daten Ihrer Mandanten entfernt werden.
Überlegen Sie, wie Sie vorgehen, wenn ein Mandant es ablehnt, dass seine Daten zum Trainieren eines Modells genutzt werden, das auf einen anderen Mandanten angewendet wird. Wären Sie beispielsweise in der Lage, bestimmte Mandantendaten vom Trainingsdataset auszuschließen?
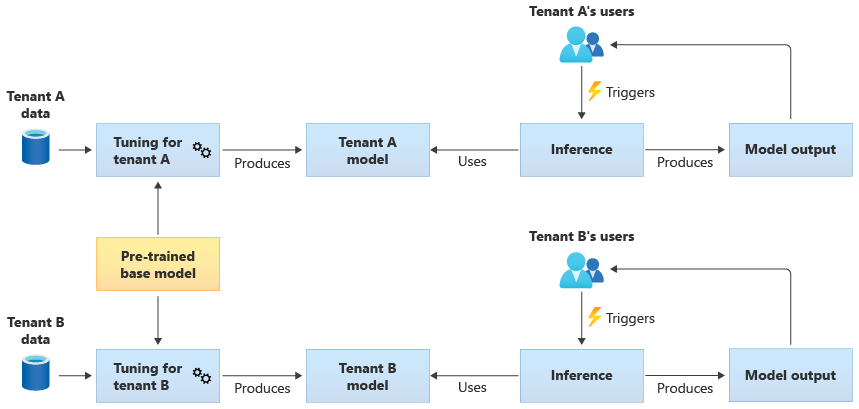
Optimierte freigegebene Modelle
Sie können auch ein vortrainiertes Basismodell kaufen und dann anhand ihrer eigenen Daten eine weitere Modelloptimierung durchführen, damit es auf jeden Ihrer Mandanten anwendbar ist. Das folgende Diagramm veranschaulicht diesen Ansatz:
Skalierbarkeit
Überlegen Sie, wie sich das Wachstum Ihrer Lösung auf die Verwendung von KI- und ML-Komponenten auswirkt. Wachstum kann sich in diesem Fall auf eine Zunahme der Anzahl von Mandanten, der für jeden Mandanten gespeicherten Datenmenge, der Anzahl von Benutzern oder der Anzahl von Anforderungen an Ihre Lösung beziehen.
Training: Es gibt mehrere Faktoren, die Auswirkungen auf die erforderlichen Ressourcen zum Trainieren Ihrer Modelle haben. Zu diesen Faktoren zählen die Anzahl von Modellen, die Sie trainieren müssen, die Datenmenge, mit der Sie die Modelle trainieren, und die Häufigkeit, mit der Sie Modelle trainieren oder erneut trainieren. Wenn Sie mandantenspezifische Modelle erstellen, steigt mit zunehmender Anzahl von Mandanten wahrscheinlich auch die Menge an Computeressourcen und Speicher, die Sie benötigen. Falls Sie freigegebene Modelle erstellen und diese mit Daten von all Ihren Mandanten trainieren, ist es weniger wahrscheinlich, dass die für das Training benötigte Ressourcenmenge mit dem gleichen Tempo zunimmt wie die Anzahl von Mandanten. Nimmt die Gesamtmenge an Trainingsdaten zu, wirkt sich dies jedoch auf die Ressourcen aus, die zum Trainieren der freigegebenen und mandantenspezifischen Modelle genutzt werden.
Rückschluss: Die für Rückschlüsse erforderlichen Ressourcen verhalten sich in der Regel proportional zur Anzahl von Anforderungen, die zum Ausführen von Rückschlüssen auf die Modelle zugreifen. Wenn die Anzahl von Mandanten zunimmt, steigt wahrscheinlich auch die Anzahl von Anforderungen.
Im Allgemeinen empfiehlt sich die Verwendung von Azure-Diensten, die sich gut skalieren lassen. Da KI-/ML-Workloads meist Container nutzen, werden für sie häufig Azure Kubernetes Service (AKS) und Azure Container Instances (ACI) verwendet. AKS ist in der Regel eine gute Wahl, wenn Sie eine hohe Skalierbarkeit erzielen und Ihre Computeressourcen je nach Bedarf dynamisch skalieren möchten. Für kleine Workloads kann sich dank der einfachen Konfiguration ACI als Computeplattform eignen. Dieser Dienst lässt sich jedoch nicht so problemlos skalieren wie AKS.
Leistung
Berücksichtigen Sie die Leistungsanforderungen für die KI-/ML-Komponenten Ihrer Lösung – sowohl für Training als auch für Rückschlüsse. Definieren Sie Ihre Anforderungen bezüglich der Wartezeit und Leistung für jeden Prozess, damit Sie Messungen durchführen und nach Bedarf Verbesserungen vornehmen können.
Training: Das Training wird häufig als Batchprozess ausgeführt und ist daher u. U. nicht so leistungsabhängig wie andere Teile Ihrer Workload. Sie müssen jedoch sicherstellen, dass Sie genügend Ressourcen bereitstellen, um das Modelltraining auch bei einer Skalierung effizient ausführen zu können.
Rückschluss: Das Rückschließen ist ein wartezeitempfindlicher Prozess, der oftmals schnelle Reaktionen oder sogar Antworten in Echtzeit erfordert. Auch wenn Sie keine Rückschlüsse in Echtzeit benötigen, müssen Sie die Leistung Ihrer Lösung überwachen und die entsprechenden Dienste zum Optimieren Ihrer Workload verwenden.
Erwägen Sie, die High Performance Computing-Funktionen von Azure für Ihre KI- und ML-Workloads zu verwenden. Azure bietet viele unterschiedliche VM-Typen und andere Hardwareinstanzen. Überlegen Sie, ob Ihre Lösung von der Verwendung von CPUs, GPUs, FPGAs oder anderen hardwarebeschleunigten Umgebungen profitieren würde. Azure bietet auch Echtzeitrückschluss mit NVIDIA-GPUs, einschließlich NVIDIA Triton Inference Server. Erwägen Sie für Computeanforderungen mit niedriger Priorität die Verwendung von AKS-Spot-Knotenpools. Weitere Informationen zum Optimieren von Computediensten in einer mehrinstanzenfähigen Lösung finden Sie unter Architekturansätze für Compute in mehrinstanzenfähigen Lösungen.
Das Modelltraining erfordert in der Regel eine intensive Interaktion mit Ihren Datenspeichern. Daher ist es auch wichtig, Ihre Datenstrategie und die Leistung Ihrer Datenschicht zu berücksichtigen. Weitere Informationen zur Mehrinstanzenfähigkeit und zu Datendiensten finden Sie unter Architekturansätze für Speicherung und Daten in mehrinstanzenfähigen Lösungen.
Erwägen Sie die Profilerstellung für die Leistung Ihrer Lösung. Beispielsweise sind Profilerstellungsfunktionen in Azure Machine Learning verfügbar, die Sie beim Entwickeln und Instrumentieren Ihrer Lösung verwenden können.
Implementierungskomplexität
Beim Erstellen einer Lösung, die KI und ML verwendet, können Sie vordefinierte Komponenten nutzen oder benutzerdefinierte Komponenten erstellen. Zwei wichtige Entscheidungen müssen Sie dabei treffen. Die erste ist die Auswahl der Plattform oder des Diensts, die bzw. den Sie für KI und ML verwenden. Die zweite ist die Wahl zwischen der Verwendung vortrainierter Modelle und dem Erstellen eigener benutzerdefinierter Modelle.
Plattformen: Es gibt viele Azure-Dienste, die Sie für Ihre KI- und ML-Workloads verwenden können. Azure KI Services und Azure OpenAI Service stellen beispielsweise APIs bereit, mit denen Sie Rückschlüsse anhand vordefinierter Modelle ausführen können, während Microsoft die zugrunde liegenden Ressourcen verwaltet. Azure KI Services ermöglicht Ihnen die schnelle Bereitstellung einer neuen Lösung, bietet Ihnen jedoch weniger Kontrolle darüber, wie Training und Rückschlüsse ausgeführt werden, und eignet sich möglicherweise nicht für jeden Workloadtyp. Azure Machine Learning ist dagegen eine Plattform, bei der Sie Ihre eigenen ML-Modelle erstellen, trainieren und verwenden können. Azure Machine Learning bietet Kontrolle und Flexibilität, erhöht jedoch die Komplexität des Entwurfs und der Implementierung. Informieren Sie sich über die Microsoft-Produkte und -Technologien für maschinelles Lernen, damit Sie bei der Auswahl des Ansatzes eine fundierte Entscheidung treffen können.
Modelle: Auch wenn Sie kein vollständiges Modell verwenden, das von einem Dienst wie Azure KI Services bereitgestellt wird, können Sie die Entwicklung mithilfe eines vortrainierten Modells beschleunigen. Wenn kein vortrainiertes Modell Ihren genauen Anforderungen entspricht, können Sie erwägen, ein vortrainiertes Modell mithilfe einer als Lerntransfer oder Optimierung bezeichneten Technik zu erweitern. Der Lerntransfer ermöglicht es Ihnen, ein vorhandenes Modell zu erweitern und auf einen anderen Bereich anzuwenden. Wenn Sie z. B. einen mehrinstanzenfähigen Dienst für Musikempfehlungen erstellen, können Sie ein vortrainiertes Modell von Musikempfehlungen als Basis verwenden und es mittels Lerntransfer für die Musikvorlieben eines bestimmten Benutzers trainieren.
Durch die Verwendung einer vordefinierten ML-Plattform wie Azure KI Services oder Azure OpenAI Service oder eines vortrainierten Modells können Sie Ihre Anfangskosten für die Forschung und Entwicklung erheblich reduzieren. Vordefinierte Plattformen können Ihnen viele Monate an Forschung ersparen und die Einstellung von hochqualifizierten wissenschaftlichen Fachkräften für Daten, die Modelle trainieren, entwerfen und optimieren, überflüssig machen.
Kostenoptimierung
Im Allgemeinen verursachen die für Modelltraining und Rückschlüsse erforderlichen Computeressourcen den Großteil der Kosten für KI- und ML-Workloads. Im Artikel Architekturansätze für Compute in mehrinstanzenfähigen Lösungen erfahren Sie, wie Sie die Kosten der Computeworkload für Ihre Anforderungen optimieren können.
Berücksichtigen Sie bei der Planung Ihrer KI- und ML-Kosten die folgenden Anforderungen:
- Bestimmen Sie die Compute-SKUs für das Training. Informationen hierzu finden Sie beispielsweise im Leitfaden für Azure Machine Learning.
- Bestimmen Sie die Compute-SKUs für das Rückschließen. Eine Beispielkostenschätzung für das Rückschließen finden Sie im Leitfaden für Azure Machine Learning.
- Überwachen Sie Ihre Ressourcenverwendung. Indem Sie die Verwendung Ihrer Computeressourcen beobachten, können Sie feststellen, ob Sie deren Kapazität durch Bereitstellen anderer SKUs verringern oder erhöhen sollten, oder die Computeressourcen skalieren, wenn sich Ihre Anforderungen ändern. Weitere Informationen finden Sie unter Überwachen von Azure Machine Learning.
- Optimieren Sie Ihre Computeclusterumgebung. Wenn Sie Computecluster verwenden, überwachen Sie die Clusterauslastung, oder konfigurieren Sie die automatische Skalierung, um Computeknoten herunterzuskalieren.
- Geben Sie Ihre Computeressourcen frei. Überlegen Sie, ob Sie die Kosten Ihrer Computeressourcen optimieren können, indem Sie sie für mehrere Mandanten freigeben.
- Berücksichtigen Sie Ihr Budget. Haben Sie ein festes Budget? Falls ja, überwachen Sie Ihren Verbrauch entsprechend. Sie können Budgets einrichten, um eine Budgetüberschreitung zu verhindern und Kontingente basierend auf der Mandantenpriorität zuzuweisen.
Zu berücksichtigende Ansätze und Muster
Azure bietet eine Reihe von Diensten, die KI- und ML-Workloads unterstützen. Es gibt mehrere gängige Architekturansätze, die in mehrinstanzenfähigen Lösungen zum Einsatz kommen: die Verwendung vordefinierter KI-/ML-Lösungen, das Erstellen einer benutzerdefinierten KI-/ML-Architektur mithilfe von Azure Machine Learning und die Verwendung einer der Azure-Analyseplattformen.
Verwenden vordefinierter KI-/ML-Dienste
Es empfiehlt sich, für alle Bereiche, in denen dies möglich ist, vordefinierte KI-/ML-Dienste zu verwenden. Vielleicht befasst sich Ihre Organisation erst seit Kurzem mit der Verwendung von KI/ML und möchte schnell einen zweckmäßigen Dienst integrieren. Oder Sie haben einfache Anforderungen, die weder ein benutzerdefiniertes ML-Modelltraining noch eine eigene Entwicklung erfordern. Vordefinierte ML-Dienste ermöglichen Ihnen das Ausführen von Rückschlüssen, ohne eigene Modelle zu erstellen und zu trainieren.
Azure bietet verschiedene Dienste, die KI- und ML-Technologie für eine Vielzahl von Bereichen bereitstellen, darunter Language Understanding, Spracherkennung, Wissen, Dokument- und Formularerkennung sowie maschinelles Sehen. Zu den vordefinierten KI-/ML-Diensten von Azure gehören Azure KI Services, Azure OpenAI Service, Azure KI-Suche und Azure KI Dokument Intelligenz. Jeder dieser Dienste bietet eine einfache Schnittstelle für die Integration sowie eine Sammlung vortrainierter und getesteter Modelle. Als verwaltete Dienste bieten sie Vereinbarungen zum Servicelevel, und der Aufwand für die Konfiguration oder fortlaufende Verwaltung ist gering. Sie müssen keine eigenen Modelle entwickeln oder testen, um diese Dienste verwenden zu können.
Viele verwaltete ML-Dienste erfordern weder Modelltraining noch Daten, sodass die Isolation von Mandantendaten in der Regel kein Problem darstellt. Wenn Sie KI-Suche in einer mehrinstanzenfähigen Lösung verwenden, sollten Sie jedoch den Artikel zu den Entwurfsmustern für mehrinstanzenfähige SaaS-Anwendungen und Azure KI-Suche lesen.
Berücksichtigen Sie die Skalierungsanforderungen der Komponenten Ihrer Lösung. Viele der APIs in Azure KI Services unterstützen beispielsweise nur eine maximale Anzahl von Anforderungen pro Sekunde. Wenn Sie eine einzelne KI Services-Ressource bereitstellen, die Sie für Ihre Mandanten freigeben, müssen Sie mit zunehmender Anzahl von Mandanten möglicherweise auf mehrere Ressourcen skalieren.
Hinweis
Einige verwaltete Dienste ermöglichen es Ihnen, Ihre eigenen Daten zum Trainieren zu verwenden. Dazu zählen der Custom Vision-Dienst, die Gesichtserkennungs-API, benutzerdefinierte Dokument Intelligenz-Modelle und einige OpenAI-Modelle, die Anpassung und Optimierung unterstützen. Wenn Sie mit diesen Diensten arbeiten, ist es wichtig, die Isolationsanforderungen für die Daten Ihrer Mandanten zu berücksichtigen.
Benutzerdefinierte KI-/ML-Architektur
Wenn Ihre Lösung benutzerdefinierte Modelle erfordert oder Sie in einem Bereich tätig sind, der nicht von einem verwalteten ML-Dienst abgedeckt wird, sollten Sie erwägen, eine eigene KI-/ML-Architektur zu erstellen. Azure Machine Learning bietet eine Reihe von Funktionen zum Orchestrieren des Trainings und Bereitstellen von ML-Modellen. Azure Machine Learning unterstützt viele Open-Source-Bibliotheken für maschinelles Lernen, darunter PyTorch, Tensorflow, Scikit und Keras. Sie können die Leistungsmetriken von Modellen fortlaufend überwachen, Datendrifts erkennen und ein erneutes Training auslösen, um die Modellleistung zu verbessern. Während des gesamten Lebenszyklus Ihrer ML-Modelle bietet Azure Machine Learning Überwachbarkeit und Governance mit integrierter Nachverfolgung und Anzeige der Datenherkunft für all Ihre ML-Artefakte.
Bei einer mehrinstanzenfähigen Lösung ist es wichtig, die Isolationsanforderungen Ihrer Mandanten sowohl während der Trainings- als auch der Rückschlussphase zu berücksichtigen. Zudem müssen Sie Ihren Modelltrainings- und Bereitstellungsprozess definieren. Azure Machine Learning bietet eine Pipeline für das Trainieren von Modellen und deren Bereitstellung in einer Umgebung, in der sie für Rückschlüsse verwendet werden können. Überlegen Sie bei einer mehrinstanzenfähigen Lösung, ob Modelle in freigegebenen Computeressourcen bereitgestellt werden sollen oder jeder Mandant über dedizierte Ressourcen verfügen soll. Entwerfen Sie Ihre Pipelines für die Modellimplementierung auf Grundlage Ihres Isolationsmodells und Ihres Prozesses für die Mandantenbereitstellung.
Wenn Sie Open-Source-Modelle verwenden, müssen Sie diese Modelle möglicherweise mittels Lerntransfer oder Optimierung erneut trainieren. Überlegen Sie, wie Sie die verschiedenen Modelle und Trainingsdaten für jeden Mandanten sowie die Versionen des Modells verwalten.
Das folgende Diagramm zeigt eine Beispielarchitektur mit Azure Machine Learning. Im Beispiel wird der Isolationsansatz der mandantenspezifischen Modelle verwendet.
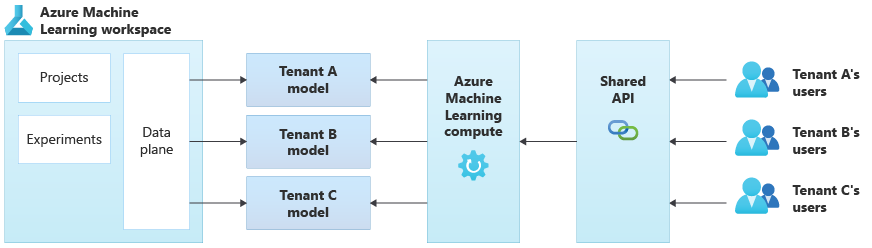
Integrierte KI-/ML-Lösungen
Azure bietet mehrere leistungsstarke Analyseplattformen, die für verschiedenste Zwecke verwendet werden können. Zu diesen Plattformen zählen Azure Synapse Analytics, Databricks und Apache Spark.
Sie können diese Plattformen für KI/ML verwenden, wenn Sie Ihre ML-Funktionen auf eine sehr große Anzahl von Mandanten skalieren müssen und Compute und Orchestrierung in großem Umfang benötigen. Wenn Sie eine umfassende Analyseplattform für andere Teile Ihrer Lösung benötigen (z. B. für die Datenanalyse und die Integration mit der Berichterstellung über Microsoft Power BI), können Sie die Verwendung dieser Plattformen für KI/ML ebenfalls erwägen. Sie können eine einzelne Plattform bereitstellen, die all Ihre Anforderungen in Bezug auf Analysen und KI/ML abdeckt. Wenn Sie Datenplattformen in einer mehrinstanzenfähigen Lösung implementieren, lesen Sie Architekturansätze für Speicherung und Daten in mehrinstanzenfähigen Lösungen.
ML-Betriebsmodell
Bei der Einführung von KI und maschinellem Lernen, einschließlich Praktiken mit generativer KI, empfiehlt es sich, Ihre Organisationsfunktionen bei der Verwaltung kontinuierlich zu verbessern und zu bewerten. Die Einführung von MLOps und GenAIOps bietet objektiv einen Rahmen, um die Fähigkeiten Ihrer KI- und ML-Praktiken in Ihrer Organisation kontinuierlich zu erweitern. Weitere Informationen finden Sie in den Dokumenten MLOps-Reifegradmodell und LLMOps-Reifegradmodell.
Zu vermeide Antimuster
- Nichtberücksichtigung der Isolationsanforderungen. Überlegen Sie sorgfältig, wie Sie die Daten und Modelle von Mandanten isolieren – sowohl für das Training als auch für Rückschlüsse. Andernfalls können gesetzliche oder vertragliche Anforderungen verletzt werden. Zudem kann es die Genauigkeit Ihrer Modelle beeinträchtigen, wenn Sie Daten mehrerer Mandanten zum Trainieren verwenden und sich die Daten erheblich unterscheiden.
- Noisy Neighbors (Beeinträchtigung durch andere Mandanten). Prüfen Sie, ob auf Ihre Trainings- oder Rückschlussprozesse das Noisy Neighbor-Problem zutreffen könnte. Wenn Sie beispielsweise mehrere große Mandanten und einen einzelnen kleinen Mandanten haben, müssen Sie sicherstellen, dass durch das Modelltraining für die großen Mandanten nicht unbeabsichtigt alle Computeressourcen verbraucht und dadurch die Ressourcen für den kleineren Mandanten blockiert werden. Nutzen Sie die Ressourcengovernance und -überwachung, um zu verhindern, dass die Computeworkload eines Mandanten durch die Aktivität anderer Mandanten beeinträchtigt wird.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Kevin Ashley | Senior Customer Engineer, FastTrack for Azure
Andere Mitwirkende:
- Paul Burpo | Principal Customer Engineer, FastTrack for Azure
- John Downs | Principal Software Engineer
- Daniel Scott-Raynsford | Partner Technology Strategist
- Arsen Vladimirskiy | Principal Customer Engineer, FastTrack for Azure
- Vic Perdana | ISV Partner Solution Architect
Nächste Schritte
- Lesen Sie Architekturansätze für Compute in mehrinstanzenfähigen Lösungen.
- Weitere Informationen zum Entwerfen von Azure Machine Learning-Pipelines zur Unterstützung mehrerer Mandanten finden Sie unter Eine Lösung für ML-Pipelines im Mehrinstanzenmodus.