
CAE-Dienste (Computer-Aided Engineering; computergestützte Entwicklung) in Azure
Stellen Sie eine SaaS-Plattform (Software-as-a-Service) für computergestützte Entwicklung (Computer-Aided Engineering) in Azure bereit.
Dieser Browser wird nicht mehr unterstützt.
Führen Sie ein Upgrade auf Microsoft Edge durch, um die neuesten Features, Sicherheitsupdates und den technischen Support zu nutzen.
High Performance Computing (HPC) wird auch als „Big Compute“ bezeichnet und nutzt eine große Anzahl von CPU- oder GPU-basierte Computern, um komplexe mathematische Aufgaben zu lösen.
HPC wird in vielen Branchen zur Lösung besonders anspruchsvoller Aufgabenstellungen eingesetzt. Beispiele für Workloads wären etwa:
Einer der Hauptunterschiede zwischen einem lokalen HPC-System und einem HPC-System in der Cloud besteht darin, dass Ressourcen dynamisch nach Bedarf hinzugefügt und entfernt werden können. Dank der dynamischen Skalierung ist die Computekapazität kein Engpass mehr, und Kunden können ihre Infrastruktur optimal auf die Anforderungen ihrer jeweiligen Aufgaben abstimmen.
Weitere Informationen zur dynamischen Skalierung finden Sie in den folgenden Artikeln:
Beschäftigen Sie sich zunächst mit folgenden Aspekten, bevor Sie Ihre eigene HPC-Lösung in Azure implementieren:
Es gibt viele Infrastrukturkomponenten, die zum Erstellen eines HPC-Systems erforderlich sind. Compute, Speicher und Netzwerk werden immer benötigt – ganz gleich, wie Sie Ihre HPC-Workloads verwalten möchten.
Es gibt zahlreiche Gestaltungs- und Implementierungsmöglichkeiten für Ihre HPC-Architektur in Azure. HPC-Anwendungen können auf tausende von Computekernen skaliert werden, lokale Cluster erweitern oder als vollständig cloudbasierte Lösung ausgeführt werden.
In den folgenden Szenarien werden einige gängige Ansätze für HPC-Lösungen beschrieben.
Stellen Sie eine SaaS-Plattform (Software-as-a-Service) für computergestützte Entwicklung (Computer-Aided Engineering) in Azure bereit.

Ausführen nativer HPC-Workloads in Azure mithilfe des Azure Batch-Diensts
Azure bietet eine Reihe von Größen, die sowohl für CPU- als auch für GPU-intensive Workloads optimiert sind.
Virtuelle Computer der N-Serie verfügen über NVIDIA-GPUs für rechen- oder grafikintensive Anwendungen wie KI-Lernen und Visualisierung.
Herkömmliche Clouddateisysteme sind den Anforderungen, die umfangreiche Batch- und HPC-Workloads in puncto Datenspeicherung und -zugriff haben, nicht gewachsen. Es gibt viele Lösungen, die sowohl die Geschwindigkeits- als auch die Kapazitätsanforderungen von HPC-Anwendungen in Azure erfüllen:
Weitere Informationen sowie einen Vergleich von Lustre, GlusterFS und BeeGFS in Azure finden Sie im E-Book Parallele Dateisysteme in Azure und im Blog Lustre in Azure.
Virtuelle Computer vom Typ „H16r“, „H16mr“, „A8“ und „A9“ können beispielsweise eine Verbindung mit einem Back-End-RDMA-Netzwerk mit hohem Durchsatz herstellen. Dieses Netzwerk kann die Leistung eng gekoppelter paralleler Anwendungen unter Microsoft Message Passing Interface (auch als MPI bekannt) oder Intel MPI verbessern.
Ein von Grund auf neu erstelltes HPC-System in Azure bietet zwar ein hohes Maß an Flexibilität, bringt aber häufig einen hohen Wartungsaufwand mit sich.
Falls Sie bereits über ein lokales HPC-System verfügen, das Sie mit Azure verknüpfen möchten, steht Ihnen mehrere Ressourcen zur Verfügung, die Sie bei den ersten Schritten unterstützen.
Lesen Sie zunächst den Artikel Auswählen einer Lösung zum Herstellen einer Verbindung zwischen einem lokalen Netzwerk und Azure in der Dokumentation. Von dort aus finden Sie weitere Informationen zu diesen Konnektivitätsoptionen:
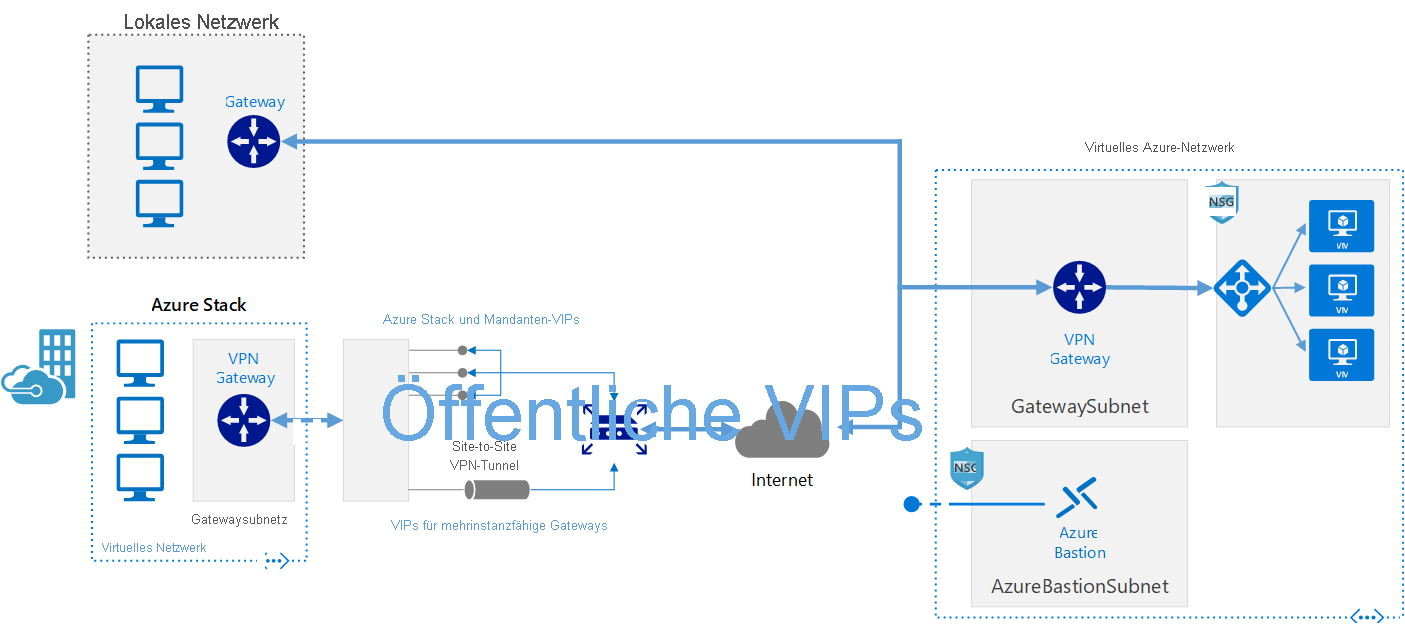
Diese Referenzarchitektur zeigt, wie Sie ein lokales Netzwerk auf Azure ausdehnen, indem Sie ein VPN (virtuelles privates Netzwerk) zwischen Standorten verwenden.
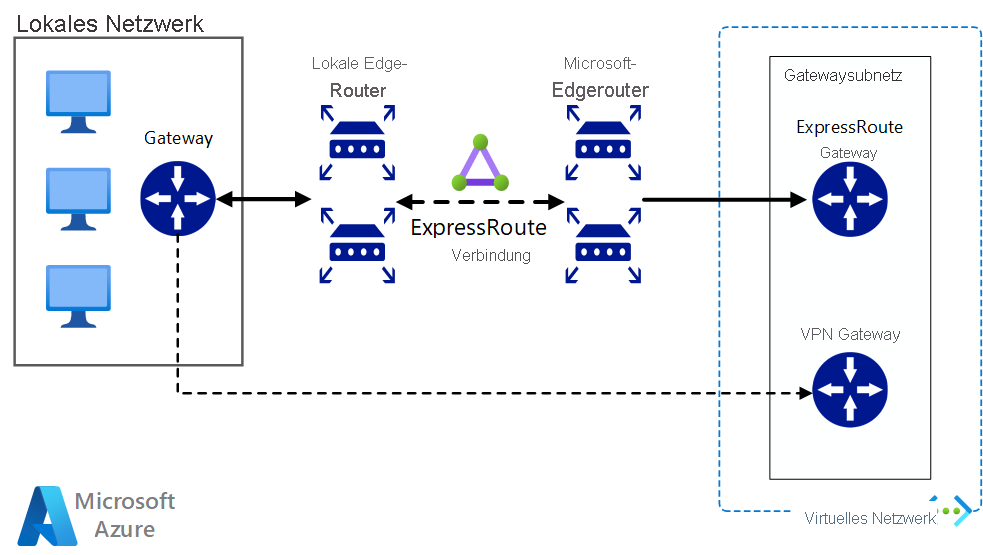
Implementieren Sie eine hochverfügbare und sichere Site-to-Site-Netzwerkarchitektur, die ein virtuelles Azure-Netzwerk und ein lokales Netzwerk mit ExpressRoute-Verbindung und VPN-Gatewayfailover umfasst.
Nachdem Sie eine zuverlässige Netzwerkverbindung hergestellt haben, können Sie mit den Burstfunktionen Ihres bereits vorhandenen Workload-Managers mit der bedarfsabhängigen Nutzung von Cloud Computing-Ressourcen beginnen.
Im Azure Marketplace sind viele Workload-Manager erhältlich.
Bei Azure Batch handelt es sich um einen Plattformdienst zur effizienten Ausführung umfangreicher paralleler und HPC-Anwendungen in der Cloud. Azure Batch plant die Ausführung rechenintensiver Aufgaben mit einem verwalteten Pool virtueller Computer und kann Computeressourcen automatisch skalieren, um den Anforderungen Ihrer Aufträge gerecht zu werden.
SaaS-Anbieter oder Entwickler können die Batch-SDKs und -Tools verwenden, um HPC-Anwendungen oder Containerworkloads in Azure zu integrieren, Daten in Azure bereitzustellen und Pipelines für die Auftragsausführung zu erstellen.
In Azure Batch werden alle Dienste in der Cloud ausgeführt werden. Die folgende Abbildung zeigt, wie die Architektur mit Azure Batch aussieht. Die Konfigurationen für Skalierbarkeit und Auftragszeitpläne werden in der Cloud ausgeführt, während die Ergebnisse und Berichte an Ihre lokale Umgebung gesendet werden können.

Azure CycleCloud ist die einfachste Möglichkeit, HPC-Workloads mit einem beliebigen Planer (etwa Slurm, Grid Engine, HPC Pack, HTCondor, LSF, PBS Pro oder Symphony) in Azure zu verwalten.
CycleCloud ermöglicht Folgendes:
In diesem Beispieldiagramm für eine Hybridlösung können wir genau sehen, wie diese Dienste zwischen der Cloud und der lokalen Umgebung verteilt sind. Es besteht die Möglichkeit, Aufträge in beiden Workloads auszuführen.

Das folgende Beispieldiagramm des cloudnativen Modells zeigt, wie die Workload in der Cloud die gesamte Verarbeitung übernimmt, während die Verbindung mit der lokalen Umgebung beibehalten wird.

| Funktion | Azure Batch | Azure CycleCloud |
|---|---|---|
| Scheduler | Batch-APIs und -Tools sowie Befehlszeilenskripts im Azure-Portal (cloudnativ). | Verwenden Sie HPC-Standardplaner wie Slurm, PBS Pro, LSF, Grid Engine und HTCondor, oder erweitern Sie CycleCloud-Plug-Ins für die automatische Skalierung, um mit Ihrem eigenen Planer zu arbeiten. |
| Computeressourcen | Software-as-a-Service-Knoten – Platform-as-a-Service | Platform-as-a-Service-Software – Platform-as-a-Service |
| Überwachungstools | Azure Monitor | Azure Monitor, Grafana |
| Anpassung | Benutzerdefinierte Imagepools, Images von Drittanbietern, Batch-API-Zugriff. | Verwenden Sie die umfassende RESTful-API zum Anpassen und Erweitern der Funktionalität, stellen Sie einen eigenen Planer bereit, und unterstützen Sie vorhandene Workload-Manager. |
| Integration | Synapse-Pipelines, Azure Data Factory, Azure CLI | Integrierte CLI für Windows und Linux |
| Benutzertyp | Entwickler | Klassische HPC-Administrator*innen und -Benutzer*innen |
| Arbeitstyp | Batch, Workflows | Eng gekoppelt (Message Passing Interface/MPI). |
| Windows-Unterstützung | Ja | Variiert je nach Planerauswahl |
Unten sind Beispiele für Cluster- und Workload-Manager angegeben, die in der Azure-Infrastruktur ausgeführt werden können. Erstellen Sie eigenständige Cluster auf Azure-VMs, oder führen Sie aus einem lokalen Cluster einen Burst-Vorgang auf Azure-VMs durch.
Einige HPC-Workloads können auch mithilfe von Containern verwaltet werden. Mit Diensten wie Azure Kubernetes Service (AKS) können Sie ganz einfach einen verwalteten Kubernetes-Cluster in Azure bereitstellen.
Für die Verwaltung Ihrer HPC-Kosten in Azure gibt es mehrere Möglichkeiten. Ermitteln Sie anhand der Azure-Kaufoptionen die Methode, die am besten für Ihre Organisation geeignet ist.
Eine Übersicht über bewährte Sicherheitsmethoden in Azure finden Sie in der Dokumentation zur Azure-Sicherheit.
Neben den im Cloudbursting-Abschnitt verfügbaren Netzwerkkonfigurationen können Sie bei Bedarf auch eine Hub-and-Spoke-Konfiguration implementieren, um Ihre Computeressourcen zu isolieren:

Bei einem Hub handelt es sich um ein virtuelles Netzwerk (VNET) in Azure, das als zentraler Konnektivitätspunkt für Ihr lokales Netzwerk fungiert. Bei Speichen handelt es sich um VNETs, die eine Peerverbindung mit dem Hub herstellen und zur Isolierung von Workloads verwendet werden können.
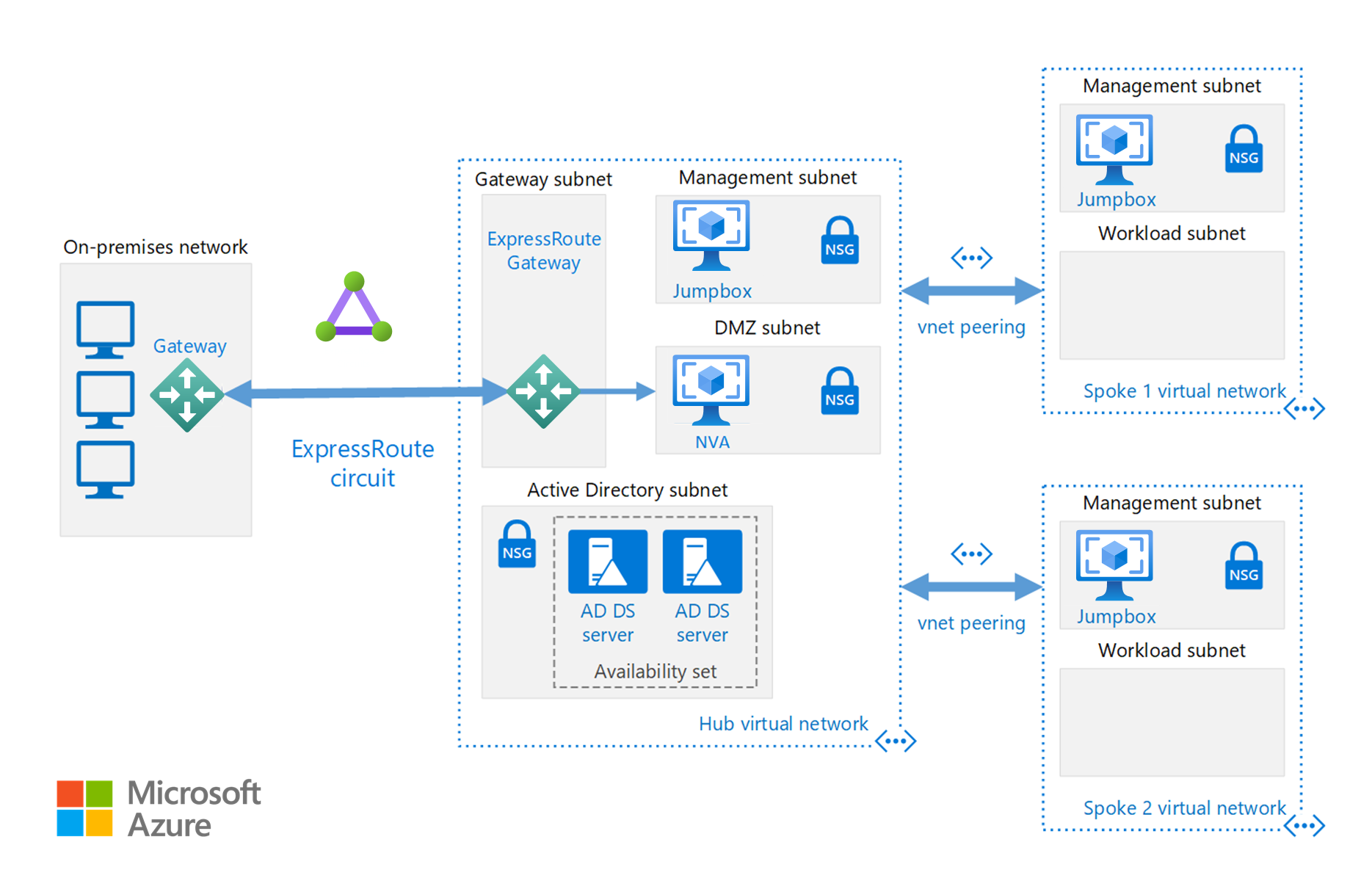
Diese Referenzarchitektur basiert auf der Hub-Spoke-Referenzarchitektur, um gemeinsame Dienste in den Hub einzubinden, die von allen Spokes genutzt werden können.
Führen Sie benutzerdefinierte oder kommerzielle HPC-Anwendungen in Azure aus. Für mehrere Beispiele in diesem Abschnitt wurden Benchmarks erstellt, um eine effiziente Skalierung mit zusätzlichen virtuellen Computern oder Computekernen zu ermöglichen. Besuchen Sie den Azure Marketplace, um auf Lösungen zuzugreifen, die sofort bereitgestellt werden können.
Hinweis
Informieren Sie sich bei Verwendung kommerzieller Anwendungen beim jeweiligen Hersteller über lizenzbedingte oder anderweitige Einschränkungen für die Ausführung in der Cloud. Nicht alle Hersteller bieten ein nutzungsbasiertes Lizenzmodell an. Unter Umständen benötigen Sie für Ihre Lösung einen Lizenzserver in der Cloud oder eine Verbindung mit einem lokalen Lizenzserver.
Führen Sie GPU-basierte virtuelle Computer in Azure in der gleichen Region aus wie die HPC-Ausgabe, um eine möglichst geringe Wartezeit sowie Zugriff zu erhalten und die Remotevisualisierung über Azure Virtual Desktop zu ermöglichen.
Azure wird bereits von zahlreichen Kund*innen mit großem Erfolg für HPC-Workloads verwendet. Im Anschluss finden Sie einige Kundenreferenzen:
Die neuesten Ankündigungen finden Sie in den folgenden Ressourcen:
Die folgenden Tutorials enthalten ausführliche Informationen zum Ausführen von Anwendungen in Microsoft-Batch:
