Dieses Beispielszenario ist für alle Branchen relevant, in denen robuste Anwendungen mit mehreren Ebenen bereitgestellt werden müssen, die für Hochverfügbarkeit und Notfallwiederherstellung konzipiert sind. Die Anwendung in diesem Szenario umfasst drei Ebenen.
- Webebene: Die oberste Ebene, die auch die Benutzeroberfläche enthält. Diese Ebene analysiert Benutzerinteraktionen und übergibt die Aktionen zur Verarbeitung an die nächste Ebene.
- Geschäftsebene: Verarbeitet die Benutzerinteraktionen und trifft logische Entscheidungen hinsichtlich der nächsten Schritte. Diese Ebene verbindet die Webebene mit der Datenebene.
- Datenebene: Speichert die Anwendungsdaten. Hierzu wird In der Regel eine Datenbank, ein Objektspeicher oder ein Dateispeicher verwendet.
Zu den gängigen Anwendungsszenarien zählen unter anderem unternehmenskritische Anwendungen unter Windows oder Linux. Hierbei kann es sich um Standardanwendungen wie SAP und SharePoint oder um eine spezielle Branchenanwendung handeln.
Mögliche Anwendungsfälle
Zu den weiteren relevanten Anwendungsfällen zählen:
- Bereitstellen von Anwendungen mit hoher Resilienz wie SAP und SharePoint
- Entwerfen eines BCDR-Plans (Business Continuity & Disaster Recovery) für Branchenanwendungen
- Konfigurieren der Notfallwiederherstellung und Ausführen entsprechender Übungen zu Compliancezwecken
Aufbau
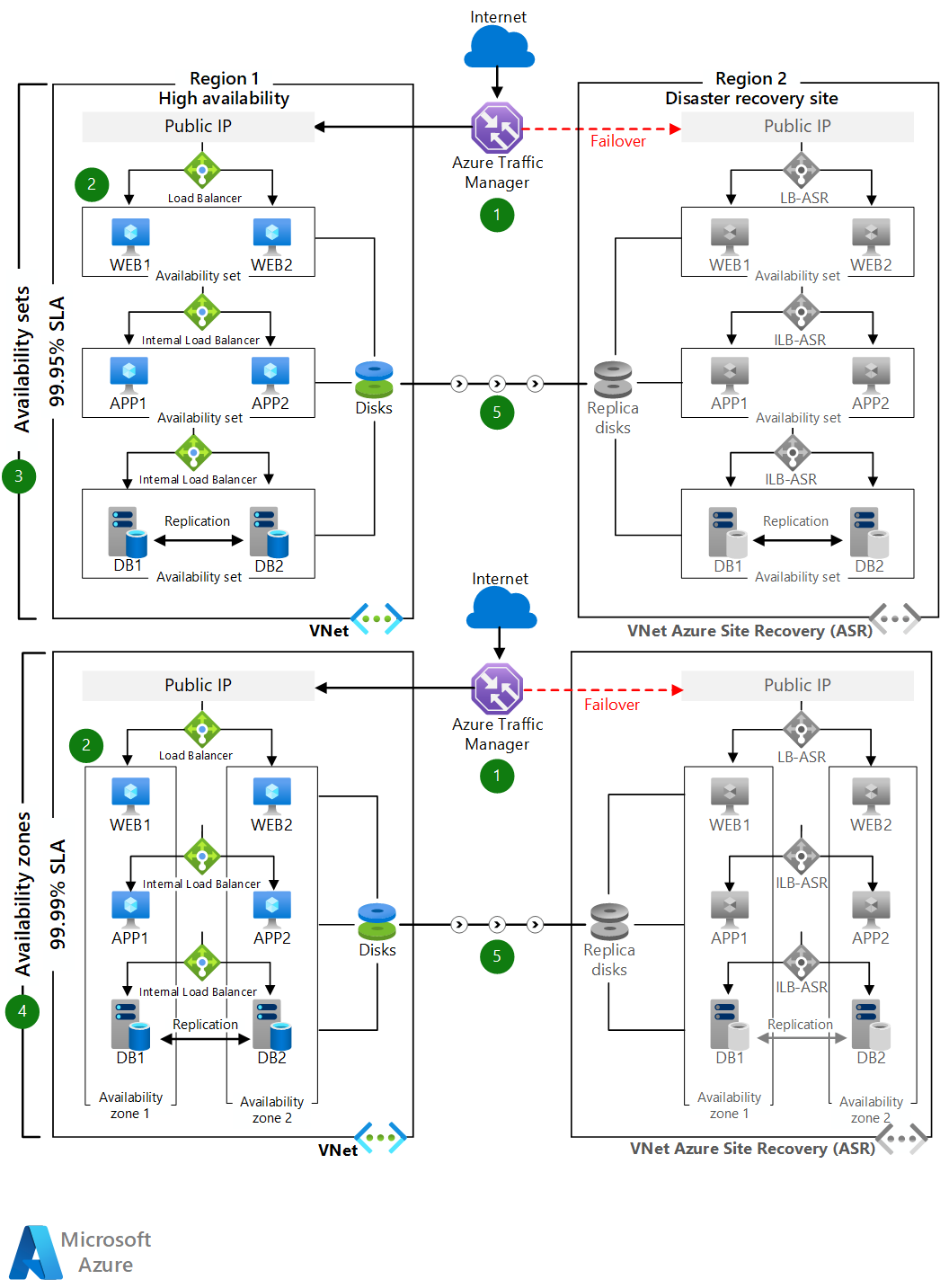
Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
- Verteilen Sie in Regionen, die Zonen unterstützen, die virtuellen Computer der einzelnen Ebenen auf zwei Verfügbarkeitszonen. Stellen Sie in anderen Regionen die virtuellen Computer der einzelnen Ebenen in einer einzelnen Verfügbarkeitsgruppe bereit.
- Die Datenbankebene kann so konfiguriert werden, dass Always On-Verfügbarkeitsgruppen konfiguriert werden. Mit dieser SQL Server-Konfiguration wird ein primäres Lese-/Schreibreplikat innerhalb einer Verfügbarkeitsgruppe mit bis zu acht sekundären schreibgeschützten Replikaten konfiguriert. Wenn ein Problem mit dem primären Replikat auftritt, führt die Verfügbarkeitsgruppe ein Failover für die primäre Lese-/Schreibaktivität auf eines der sekundären Replikate durch, sodass die Anwendung verfügbar bleibt. Weitere Informationen finden Sie unter Übersicht über Always On-Verfügbarkeitsgruppen für SQL Server.
- In Notfallwiederherstellungsszenarien können Sie eine asynchrone native SQL AlwaysOn-Replikation in der für die Notfallwiederherstellung verwendeten Zielregion konfigurieren. Sie können auch eine Azure Site Recovery-Replikation in der Zielregion konfigurieren, sofern die Datenänderungsrate innerhalb der unterstützten Grenzwerte von Azure Site Recovery liegt.
- Benutzer greifen über den Traffic Manager-Endpunkt auf die Front-End-ASP.NET-Webebene zu.
- Der Traffic Manager leitet Datenverkehr an den primären öffentlichen IP-Endpunkt in der primären Quellregion weiter.
- Die öffentliche IP-Adresse leitet den Aufruf über einen öffentlichen Load Balancer an eine der VM-Instanzen der Webebene weiter. Alle VM-Instanzen der Webebene befinden sich im gleichen Subnetz.
- Von dem virtuellen Computer auf der Webebene wird jeder Aufruf über einen internen Load Balancer zur Verarbeitung an eine der VM-Instanzen auf der Geschäftsebene weitergeleitet. Alle virtuellen Computer auf der Geschäftsebene befinden sich in einem separaten Subnetz.
- Der Vorgang wird auf der Geschäftsebene verarbeitet, und die ASP.NET-Anwendung stellt über einen internen Azure Load Balancer eine Verbindung mit dem Microsoft SQL Server-Cluster auf einer Back-End-Ebene her. Diese SQL Server-Back-End-Instanzen befinden sich in einem separaten Subnetz.
- Der sekundäre Endpunkt des Traffic Managers wird als öffentliche IP-Adresse in der für die Notfallwiederherstellung verwendeten Zielregion konfiguriert.
- Im Falle einer Störung der primären Region rufen Sie ein Azure Site Recovery-Failover auf, und die Anwendung wird in der Zielregion aktiv.
- Der Traffic Manager-Endpunkt leitet den Clientdatenverkehr automatisch an die öffentliche IP-Adresse in der Zielregion um.
Komponenten
- Verfügbarkeitsgruppen sorgen dafür, dass die von Ihnen in Azure bereitgestellten virtuellen Computer auf mehrere isolierte Hardwareknoten in einem Cluster verteilt werden. Dadurch wirken sich Hardware- oder Softwarefehler in Azure nur auf einen Teil Ihrer virtuellen Computer aus, und Ihre Lösung bleibt insgesamt verfügbar und betriebsbereit.
- Verfügbarkeitszonen schützen Ihre Anwendungen und Daten vor Datencenterausfällen. Bei Verfügbarkeitszonen handelt es sich um separate physische Standorte in einer Azure-Region. Jede Zone besteht aus mindestens einem Datencenter mit eigener Stromversorgung, Kühlung und Netzwerk.
- Mit Azure Site Recovery können Sie virtuelle Computer in einer anderen Azure-Region replizieren, um Ihre BCDR-Anforderungen (Business Continuity & Disaster Recovery) zu erfüllen. Sie können regelmäßige Notfallwiederherstellungsübungen ausführen, um die Einhaltung von Complianceanforderungen zu gewährleisten. Der virtuelle Computer wird mit den angegebenen Einstellungen in der ausgewählten Region repliziert, sodass Sie Ihre Anwendungen bei Ausfällen in der Quellregion wiederherstellen können.
- Azure Traffic Manager ist ein DNS-basierter Lastenausgleich, der Datenverkehr optimal auf Dienste in den globalen Azure-Regionen verteilt und gleichzeitig für Hochverfügbarkeit und kurze Reaktionszeiten sorgt.
- Azure Load Balancer verteilt eingehenden Datenverkehr auf der Grundlage von definierten Regeln und Integritätstests. Ein Load Balancer sorgt für kurze Wartezeiten und hohen Durchsatz und kann auf Millionen von Flows für alle TCP- und UDP-Anwendungen skalieren. In diesem Szenario wird ein öffentlicher Load Balancer verwendet, um eingehenden Clientdatenverkehr auf der Webebene zu verteilen. Außerdem wird in diesem Szenario ein interner Lastenausgleich verwendet, um Datenverkehr von der Geschäftsebene auf den Back-End-SQL Server-Cluster zu verteilen.
Alternativen
- Windows kann durch verschiedene andere Betriebssysteme ersetzt werden, da die Infrastruktur nicht vom Betriebssystem abhängig ist.
- SQL Server für Linux kann den Back-End-Datenspeicher ersetzen.
- Die Datenbank kann durch eine beliebige Standard-Datenbankanwendung ersetzt werden.
Szenariodetails
In diesem Szenario wird eine Anwendung mit mehreren Ebenen gezeigt, die ASP.NET und Microsoft SQL Server verwendet. In Azure-Regionen, die Verfügbarkeitszonen unterstützen, können Sie Ihre virtuellen Computer (Virtual Machines, VMs) in einer Quellregion über Verfügbarkeitszonen hinweg bereitstellen und die virtuellen Computer in der für die Notfallwiederherstellung verwendeten Zielregion replizieren. In Azure-Regionen, die keine Verfügbarkeitszonen unterstützen, können Sie Ihre VMs innerhalb einer Verfügbarkeitsgruppe bereitstellen und die VMs in der Zielregion replizieren.
Um Datenverkehr zwischen Regionen weiterzuleiten, benötigen Sie einen globalen Lastenausgleich. Zwei Azure-Hauptangebote sind dafür verfügbar:
- Azure Front Door
- Azure Traffic Manager
Berücksichtigen Sie bei der Auswahl des Lastenausgleichs Ihre Anforderungen und den Funktionsumfang der beiden Angebote. Wie schnell möchten Sie ein Failover durchführen? Ist der Mehraufwand für die TLS-Verwaltung für Sie akzeptabel? Gibt es Einschränkungen bezüglich der Kosten für die Organisation?
Front Door bietet Layer 7-Funktionen (z. B. SSL-Auslagerung, pfadbasiertes Routing, schnelles Failover, Zwischenspeicherung usw.), mit denen Sie die Leistung und Hochverfügbarkeit Ihrer Anwendungen verbessern können. Möglicherweise stellen Sie schnellere Paketübertragungszeiten fest, weil die Infrastruktur früher in das Azure-Netzwerk integriert wird.
Da Front Door einen neuen Hop hinzufügt, gibt es zusätzliche Sicherheitsvorgänge. Wenn die Architektur den gesetzlichen Anforderungen entspricht, gelten möglicherweise Einschränkungen hinsichtlich des zusätzlichen TLS-Beendigungspunkts für Datenverkehr. Die von Front Door ausgewählten TLS-Verschlüsselungssammlungen müssen die Sicherheitsanforderungen Ihrer Organisation erfüllen. Außerdem erwartet Front Door, dass die Back-End-Dienste von Microsoft verwendete Zertifikate nutzen.
Ein weiterer Aspekt sind die Kosten. Um die zusätzlichen Kosten zu rechtfertigen, sollten die umfangreichen Funktionen (nicht nur das Failover) in der Architektur genutzt werden.
Azure Traffic Manager ist ein DNS-basierter Lastenausgleichsdienst. Er führt den Lastenausgleich und das Failover nur auf der DNS-Ebene aus. Aus diesem Grund kann ein Failover nicht so schnell wie von Front Door durchgeführt werden, da das DNS-Zwischenspeichern und Systeme, die keine DNS-TTLS berücksichtigen, häufig Probleme verursachen.
Sie können bei Bedarf beide Lastenausgleiche kombinieren, z. B. wenn Sie das DNS-basierte Failover verwenden, aber vor dieser Infrastruktur mit verwaltetem Datenverkehr eine POP-Funktion hinzufügen möchten.
Diese Architektur verwendet aufgrund der Einfachheit des Lastenausgleichs Traffic Manager. Zur Veranschaulichung ist das Failovertiming ausreichend.
Überlegungen
Skalierbarkeit
Sie können auf jeder Ebene virtuelle Computer hinzufügen oder entfernen, um Ihre Skalierungsanforderungen zu erfüllen. Da in diesem Szenario Load Balancer verwendet werden, können Sie einer Ebene weitere virtuelle Computer hinzufügen, ohne dass dies Auswirkungen auf die Anwendungsbetriebszeit hat.
Weitere Skalierbarkeitsthemen finden Sie im Azure Architecture Center in der Prüfliste zur Leistungseffizienz.
Sicherheit
Der gesamte Datenverkehr des virtuellen Netzwerks an die Front-End-Anwendungsebene wird durch Netzwerksicherheitsgruppen geschützt. Anhand von Regeln wird der Datenverkehrsfluss eingeschränkt, sodass nur die VM-Instanzen der Front-End-Anwendungsebene auf die Back-End-Datenbankebene zugreifen können. Auf der Geschäfts- oder Datenbankebene ist kein ausgehender Internetdatenverkehr zulässig. Es werden keine Ports für die direkte Remoteverwaltung geöffnet, um die Angriffsfläche zu reduzieren. Weitere Informationen finden Sie unter Azure-Netzwerksicherheitsgruppen.
Allgemeine Informationen zur Entwicklung sicherer Szenarien finden Sie in der Dokumentation zur Azure-Sicherheit.
Preise
Wenn Sie die Notfallwiederherstellung für virtuelle Azure-Computer mit Azure Site Recovery konfigurieren, fallen regelmäßig folgende Gebühren an:
- Azure Site Recovery-Lizenzierungskosten pro virtuellem Computer.
- Kosten für ausgehenden Netzwerkdatenverkehr, um Datenänderungen auf den Datenträgern virtueller Quellcomputer in einer anderen Azure-Region zu replizieren. Azure Site Recovery verwendet eine integrierte Komprimierung, um den Datenübertragungsbedarf um etwa 50 Prozent zu verringern.
- Speicherkosten am Wiederherstellungsstandort. Diese entsprechen in der Regel dem Quellregionsspeicher plus dem Speicher, der ggf. zusätzlich benötigt wird, um die Wiederherstellungspunkte als Momentaufnahmen für die Wiederherstellung zu verwalten.
Wir haben einen Beispielkostenrechner für die Konfiguration der Notfallwiederherstellung für eine Anwendung mit drei Ebenen und sechs virtuellen Computern bereitgestellt. In dem Kostenrechner sind bereits alle Dienste vorkonfiguriert. Wenn Sie wissen möchten, welche Kosten für Ihren spezifischen Anwendungsfall entstehen, können Sie die entsprechenden Variablen anpassen, um eine Kostenschätzung zu erhalten.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Sujay Talasila | Principal Product Lead
Nächste Schritte
- Bereitstellen von Traffic Manager in Azure
- Set up disaster recovery for Azure VMs (Einrichten der Notfallwiederherstellung für Azure-VMs)
Zugehörige Ressourcen
Weitere Referenzarchitekturen für Hochverfügbarkeit und Notfallwiederherstellung finden Sie unter: